
索引的本质
本文实战使用Mysql 8
摘自MySql官网:
索引用于快速查找具有特定列值的行
没有索引,MySQL必须从第一行开始,然后再通读整个表以找到相关的行,表越大,消耗越多。
如果表中有相关列的索引,MySQL可以快速确定要在数据文件中查找的位置,而不必查看所有数据。这比顺序读取每一行要快得多。
索引其实就是**帮助Mysql高效获取数据的排好序的数据结构 **
**
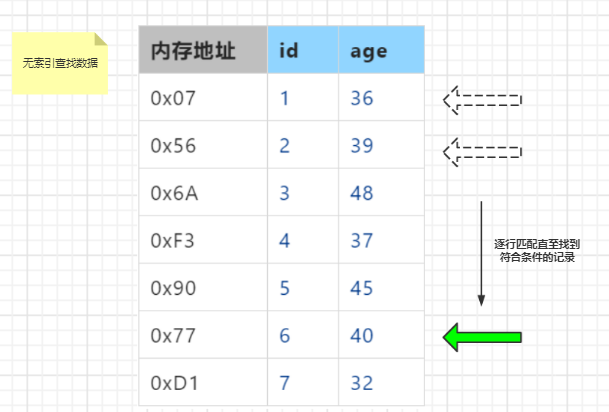
如上图示例【并非实际原理,仅作演示】,如果以age为查询条件
当没有索引的时候,我们需要根据条件对数据库表进行逐一匹配,直到找到符合条件的记录,表数据非常多的时候,这种查询很耗时,如查询age=32的记录,需要进行7次匹配
当为age创建索引之后,会以age为key,内存地址为value,形成一个排好序的数据结构【此处以二叉树为示例】,此时再去查找目标记录,不需要再进行逐一匹配,以二叉树的规则去匹配即可,根据找到的树节点可以快速找到目标记录所在内存地址。如查询age=32的记录,仅需要进行1次匹配。
索引的数据结构
常见的数据结构有二叉树、红黑树、Hash、BTree和B+Tree等,Mysql使用B+Tree作为索引的数据结构,我们对这些结构进行逐一分析
为什么不是二叉树?
二叉树特性:比父节点大的节点放在左边,比父节点大的节点放在右边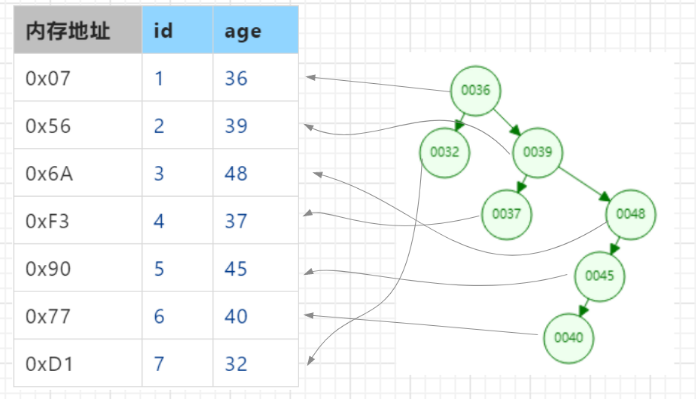
弊端:递增索引导致结构失效,单边增长形成链表,故不选取
如把id作为索引,得出的二叉树如下,这时的二叉树变成了链表,如果要匹配id=7的记录,需要7次匹配,与无索引无异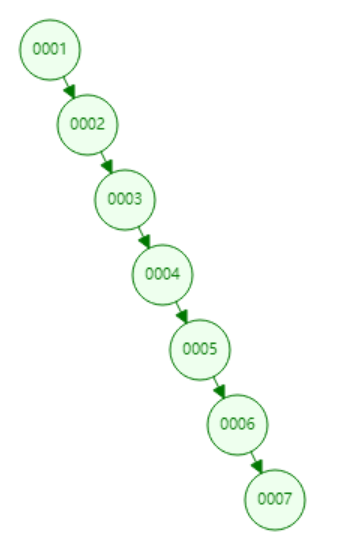
**
为什么不是红黑树?
红黑树特性:自平衡特性,通过算法自动调整节点位置,避免二叉树单边增长形成链表的问题。
上述id索引红黑树结构如下: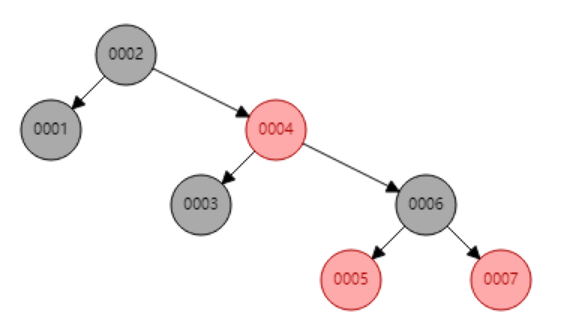
弊端:数据量大的时候,树层级也逐渐增大,每一层只能是2的n次方节点,存放数据有限,对数据的匹配依旧要进行深度查找,速度不够快**【比如某个id在最后的叶子节点处】
如id索引的红黑树有20层,则当目标id在最后的叶子节点处,则至少进行20次i/o,**查询速度不够**
为什么不是Hash?
哈希特性:通过哈希算法根据传入的条件直接计算出目标位置,这种计算是很快的
**弊端:对于等条件匹配很适用,但是对于范围查询不适用【如查找id>5的记录,Hash索引发挥不了作用了】
但是Mysql还是留下了Hash的选择,对于基本不参与范围查询的字段,可以使用Hash索引,这种方式是比较快的
**
还不是BTree?
BTree(或B-Tree) ——-即B树,是一个多叉平衡查找树,单个节点可以存放多个数据,每个内结点有多个分支,即多叉
BTree特性:
1、引入度(Degree)的概念:限定BTree每个节点最多可以横向存放多少个数据【数据=索引值:索引对应数据记录】
2、每个节点中的key左至右递增排列
3、通过对度的掌控,可以控制整个树的高度层级,优化查询速度
可以看到,通过设置度,id到达7的时候比红黑树的层级要小得多,更别说更多数据了
弊端:既然通过度可以控制树的层级,减少查询时间,是否可以无限放大“度”来优化性能呢?
答案是不可以的,我们知道,Mysql将索引和数据都放到了磁盘中,当和CPU进行交互时,会先从磁盘中读取数据交给内存,再由CPU从内存中读取数据【这个过程是很快的】交给mysql
内存与磁盘之间的数据交换单位为页【大小为4k】,一次交换数据【即磁盘I/O】为页的整数倍,也就是有大小限制的,假如要查找的数据在某个节点中,而由于B树的“度”设置的非常庞大,导致这个节点存放数据很多,占用空间很大[如10M],不可能一下全拿出来给内存,只能多次I/O获取数据,而这就导致I/O消耗非常大
也就是说,度不是无限的,需要根据计算机硬件设备进行设置。Mysql一般会将节点的大小控制在4k即一页以内,保证内存能够一次性从磁盘获取一个节点的全部信息,这将会导致**一个节点可存放的数据非常有限**。
那么,当存放单个数据非常小的时候,是不是意味着一个节点可以存放更多的数据?
为什么是B+Tree?
B+Tree——-B+树,是BTree的变种
B+Tree特性:
1、非叶子只保存索引值而不存放数据记录,这就使得单个数据更小,单个节点可以存放更多的数据
2、数据记录由叶子节点保存
3、增加顺序访问指针,提高区间访问的性能
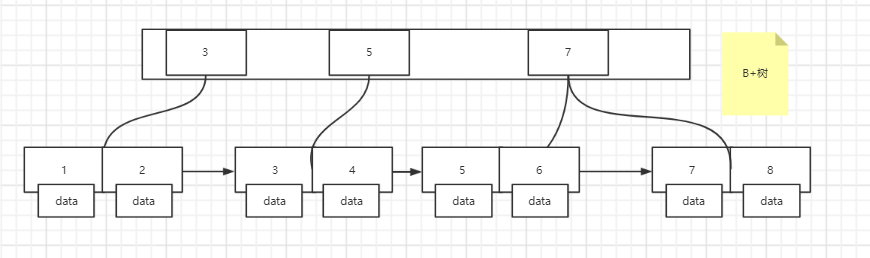
可以看到,在非叶子节点中,仅存放了索引而没有存放数据【data】,数据仅存放在叶子节点,这使得非叶子节点可存放的数据会更多,从而可以将度设置的更大,使单个节点空间逼近一个页【4k】,让内存一次性能够获取到更多信息。
叶子节点间建立了顺序指针,当在前一个叶子节点没有找到相关数据,可以直接通过指针找到附近的数据,而不需要回到上一步节点继续查找,这使得查找速度得到优化
B+Tree的性能:
一般使用磁盘I/O次数评价索引结构的性能优劣**
1、预读:磁盘一般会顺序向后读取一定长度的数据(页的整数倍)放入内存
2、局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用
3、B+Tree节点的大小设为等于一个页,每次新建节点直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,就实现了一个节点的载入只需一次I/O
4、B+Tree的度一般会超过100,因此树的高度非常小(一般为3到5之间)
不同存储引擎下的索引
数据库存储引擎【又称为表类型,作用于表】是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据。
不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以 获得特定的功能
也就是说,存储引擎限定了数据库表的存储机制和索引等信息
Mysql主要支持八种存储引擎:InnoDB、MyISAM、ARCHIVE(不支持索引)、BLACKHOLE、CSV、MEMORY、MRG_MYISAM、PERFORMANCE_SCHEMA
其中MyISAM是mysql最早提供的存储引擎,而InnoDB则可以看作是对MyISAM的进一步更新产品,我们比较一下两种存储引擎对索引的支持与区别。
MyISAM引擎下的索引
MyISAM引擎(表类型)采用的是非聚集型索引**,即索引文件与数据文件分离,叶子节点保存索引及目标数据记录的文件地址
且对于MyISAM存储引擎而言,主键索引及非主键索引完全一致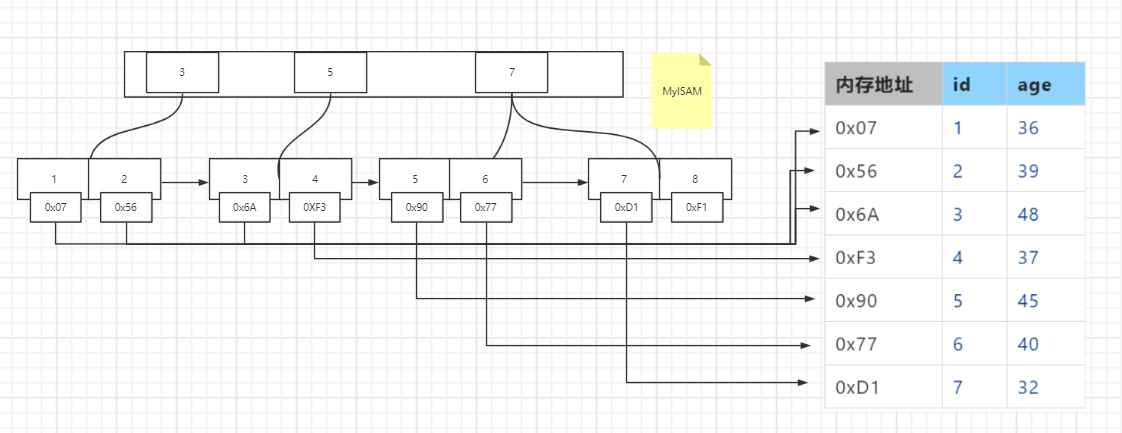
证实
我们将数据库中的某张表格(sys_user)存储引擎设置为MyISAM
并创建某个索引:
对应保存的数据文件和索引文件如下【证明索引文件和数据文件是分离的**】:
如果不知道数据文件存在哪里,可以在mysql执行如下命令:
show global variables like “%datadir%”;
InnoDB引擎下的索引
InnoDB引擎(表类型)使用聚集型索引,,即**索引文件与数据文件不分离**,叶子节点保存索引及目标数据记录
InnoDB引擎对于主键索引和非主键索引的设计结构并不一致
InnoDB引擎主键索引结构如下,**叶子节点存放索引和数据记录【以id为主键】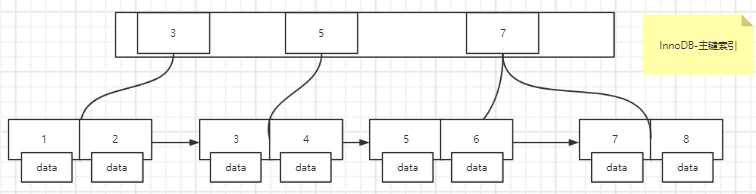
InnoDB引擎**非主键索引结构如下,叶子节点存放索引和**主键值(这就是为什么InnoDB要求表格一定要有主键)【以age为索引】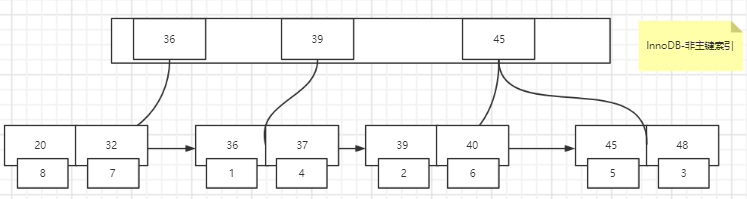
InnoDB引擎索引文件和数据文件不分离证明:
**
将表格(sys_user)设置为InnoDB引擎:
为age创建索引:
此时关于sys_user的文件仅剩下.ibd文件【证明索引文件与数据文件是不分离的】
联合索引结构
上面我们学习的都是单个字段作为索引的情况,而Mysql还支持多字段联合索引,那么联合索引的结构是不是一样的呢?
联合索引设置,为name,age,sex三个字段创建联合索引:
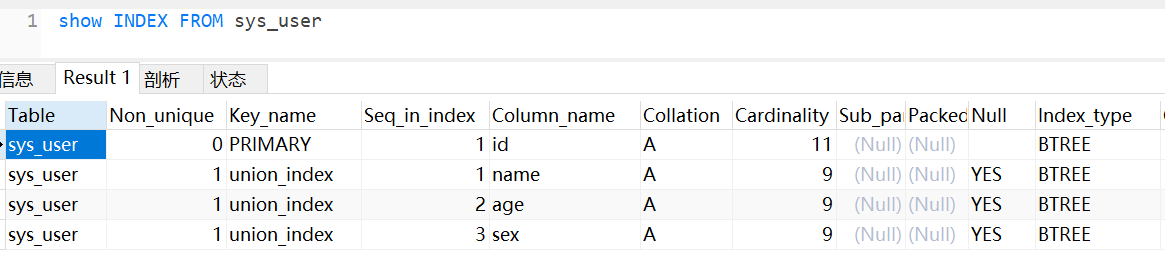
对应联合索引结构如下: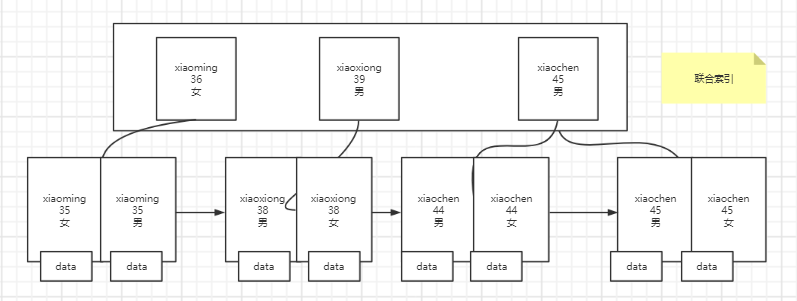
联合索引简单理解就是将索引字段放到一起作为一个整体的索引,比如需要匹配下列语句
select * from sys_user where name = 'xiaoming' and age = 35 and sex = '男'
由于将三个字段作为联合索引,当查询上述语句的时候
首先匹配name,即查找name位xiaoming的索引,就会匹配到上图非叶子节点中的{xiaoming 36 女}这一节点,则不需要往右进行匹配
接着当子节点name相同,往下查找进行age的匹配,最后匹配sex
也就是说,联合索引按照设定索引的时候的字段顺序进行匹配
索引最左前缀原理
索引最左前缀原则:如果索引为多列联合索引,查询**从索引的最左列开始并且不跳过索引中的列**,索引才会生效
也就是说,如上述联合索引(name,age,sex),只有当where条件里为name,name&age,name&age&sex这三种情况,联合索引才会生效,当然,与在where里面写的顺序无关**
比如说下面三个语句都是走了索引【顺序从左往右没有跳过任何一列】,我们可以看一下相应的Explain结果分析
explain select * from sys_user where name = 'xiaoming'explain select * from sys_user where name = 'xiaoming' and age = 35explain select * from sys_user where name = 'xiaoming' and age = 35 and sex = '男'explain select * from sys_user where age = 35 and name = 'xiaoming' and sex = '男' # 走索引,与上一句没有区别
而如下示例三种不会走联合索引:
explain select * from sys_user where sex = '男' # 不走索引,因为跳过了列explain select * from sys_user where age = 35 # 不走索引,因为跳过了列explain select * from sys_user where name = 'xiaoming' and sex='男' # name走索引,sex不走索引,因为跳过了列explain select * from sys_user where age = 20 and sex = '男' # 都不走索引,因为跳过了列
为什么跳过了列和顺序不对会导致索引失效呢?【为什么要遵循最左前缀原理】
因为上述所说的联合索引数据结构,查找遵循索引字段顺序,所以越过字段会导致无法寻找对应值的问题,就无法使用索引。
索引类型
Mysql目前主要支持以下几种类型索引:普通索引(NORMAL),唯一索引(UNIQUE),主键索引(PRIMARY KEY),联合索引、全文索引(FULLTEXT)和空间索引(SPATIAL)
一、单列索引
1.1、普通索引—-NORMAL
最基本的索引,对字段没有什么限制
创建普通索引
# 建表的同时为name字段创建索引【length代表索引长度,只有字符串类型字段才可以设置索引长度】CREATE TABLE `sys_user` (`id` int(11) NOT NULL AUTO_INCREMENT ,`name` char(255) CHARACTER NOT NULL ,`age` int(11) NULL,`sex` int(10) NULL DEFAULT NULL ,PRIMARY KEY (`id`),INDEX normal_index (name(length)))# 修改表结构的时候为name字段创建索引ALTER TABLE sys_user ADD INDEX normal_index ON (name(length))# 直接为name字段创建索引CREATE INDEX normal_index ON sys_user(name(length))
删除索引
DROP INDEX index_name ON table
1.2、唯一索引—-UNIQUE
表示唯一的,不允许重复的索引
**
约束唯一标识数据库表中的每一条记录,即在单表中不能用每条记录是唯一的(例如身份证就是唯一的)
创建唯一索引
# 建表的同时为name字段创建索引【length代表索引长度,只有字符串类型字段才可以设置索引长度】CREATE TABLE `sys_user` (`id` int(11) NOT NULL AUTO_INCREMENT ,`name` char(255) CHARACTER NOT NULL ,`age` int(11) NULL,`sex` int(10) NULL DEFAULT NULL ,PRIMARY KEY (`id`),UNIQUE normal_index (name(length)))# 修改表结构的时候为name字段创建索引ALTER TABLE sys_user ADD UNIQUE unique_index ON (name(length))# 直接为name字段创建索引CREATE UNIQUE INDEX unique_index ON sys_user(name(length))
1.3、主键索引—-PRIMARY KEY
特殊的唯一索引,一个表只能由一个主键,且主键不能为空。
一般在建表时创建主键索引
# 建表的同时为id字段创建主键索引CREATE TABLE `sys_user` (`id` int(11) NOT NULL AUTO_INCREMENT ,`name` char(255) CHARACTER NOT NULL ,`age` int(11) NULL,`sex` int(10) NULL DEFAULT NULL ,PRIMARY KEY (`id`))
二、联合索引
指多个字段上创建的索引,遵循索引最左前缀原理【不算是一种类型,而是一种结构】
创建联合索引【可以指定索引类型】
# 建表的同时为name,age,sex字段创建索引CREATE TABLE `sys_user` (`id` int(11) NOT NULL AUTO_INCREMENT ,`name` char(255) CHARACTER NOT NULL ,`age` int(11) NULL,`sex` int(10) NULL DEFAULT NULL ,PRIMARY KEY (`id`),INDEX union_index (name,age,sex))# 修改表结构的时候为name,age,sex字段创建索引ALTER TABLE sys_user ADD INDEX union_index ON (name,age,sex)# 直接为name,age,sex字段创建索引CREATE INDEX union_index ON sys_user(name,age,sex)# 为name,age,sex字段创建唯一索引,需全部匹配完整CREATE UNIQUE INDEX union_index ON sys_user(name,age,sex)
三、全文索引—-FULLTEXT
主要用来查找文本中的关键字,而不是直接与索引中的值相比较。【仅能正在char、varchar,text 列上创建】
FULLTEXT索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。
FULLTEXT索引配合match against操作使用,而不是一般的where语句加like。
创建全文索引语句:
# 建表的同时为name字段创建索引【length代表索引长度,只有字符串类型字段才可以设置索引长度】CREATE TABLE `sys_user` (`id` int(11) NOT NULL AUTO_INCREMENT ,`name` char(255) CHARACTER NOT NULL ,`age` int(11) NULL,`sex` int(10) NULL DEFAULT NULL ,PRIMARY KEY (`id`),FULLTEXT fulltext_index (name(length)))# 修改表结构的时候为name字段创建索引ALTER TABLE sys_user ADD FULLTEXT fulltext_index ON (name(length))# 直接为name字段创建索引CREATE FULLTEXT INDEX fulltext_index ON sys_user(name(length))
使用实例:
# MATCH 指定目标匹配字段# AGAINST 指定全文检索的关键字# IN BOOLEAN MODE 表示包含即可,而不理会是否在开头select * from sys_user where MATCH (`name`) AGAINST ('xiao' IN BOOLEAN MODE);
四、空间索引—-SPATIAL
Mysql在5.7之后支持OpenGIS几何数据模型,同时还支持空间索引。空间索引通过R树【即多维的B树】实现,仅支持两个维度的数据,且仅能应用在空间数据上。
创建空间索引语句:
# 建表的同时为box字段创建索引CREATE TABLE `gim` (`path` varchar(512) NOT NULL,`box` geometry NOT NULL,PRIMARY KEY (`path`),SPATIAL KEY `spatail_index` (`box`)) ;# 修改表结构的时候为box字段创建索引ALTER TABLE sys_user ADD SPATIAL spatail_index ON (`box`)# 直接为box字段创建索引CREATE SPATIAL INDEX spatail_index ON sys_user(`box`)
具体因为没有怎么用过,不好随便写
索引失效情况
学完前面的内容,我们知道了索引的创建和数据结构,日常应用中,我们很容易就会遇见索引失效导致慢查询的问题,什么情况下,索引才会失效?
Mysql是否使用索引并不一定依据索引规则,会考量匹配条件的数据量与数据总量比例决定是否走索引【数据量极少的时候不用索引可能更快】
1、or查询需全都有索引
or查询的时候,要求**必须全部字段都有索引**,否则失效
注意,or查询时,联合索引不生效,即便遵循最左前缀原则
union_index 为联合索引 {age,sex}
是否走索引可以看explain执行计划的key字段【有关[_Explain关键字的说明](https://www.yuque.com/keep_zero/vowly4/vwn0qk)_】_
2、未遵循最左前缀原则,联合索引失效
3、like查询以%开头
BTree匹配规则

这种情况可以使用索引覆盖查询字段**来解决
4、需要进行类型转换


5、where中索引列有运算


6、where中索引列使用了函数
索引仅跟索引列本身有关,而不应该变更索引列的值

7、where中索引列使用了不等于(!= 或 <>)
索引数据结构BTree以等于为规则去查找节点

8、存储引擎不能使用索引中范围条件右边的列
当联合索引的其中一个列使用了范围比较,则联合索引后面的列都走不了索引


记忆口诀
全值匹配我最爱,最左前缀要遵守;
带头大哥不能死,中间兄弟不能断;
索引列上少计算,范围之后全失效;
LIKE百分写最右,覆盖索引不写星;
不等空值还有or,索引失效要少用。

若有收获,就点个赞吧
0 人点赞
