几个重要的时间
采集周期 scrape_interval 5s
计算周期 evaluation_interval 10s
分组参数 group_by
分组等待时间 group_wait 5s
分组尝试再次发送告警的时间间隔 group_interval 5m
分组内发送相同告警的时间间隔 repeat_interval 60m
第一节 监控采集、计算和告警
Prometheus以scrape_interval(默认为1m)规则周期,从监控目标上采集数据。其中scrape_interval可以基于全局或基于单个metric定义;然后将监控信息持久存储在其本地存储上。
Prometheus以evaluation_interval(默认为1m)另一个独立的规则周期,对告警规则做定期计算。其中evaluation_interval只有全局值;然后更新告警状态。
其中包含三种告警状态:
- inactive:没有触发阈值
- pending:已触发阈值但未满足告警持续时间
- firing:已触发阈值且满足告警持续时间
举一个例子,阈值告警的配置如下: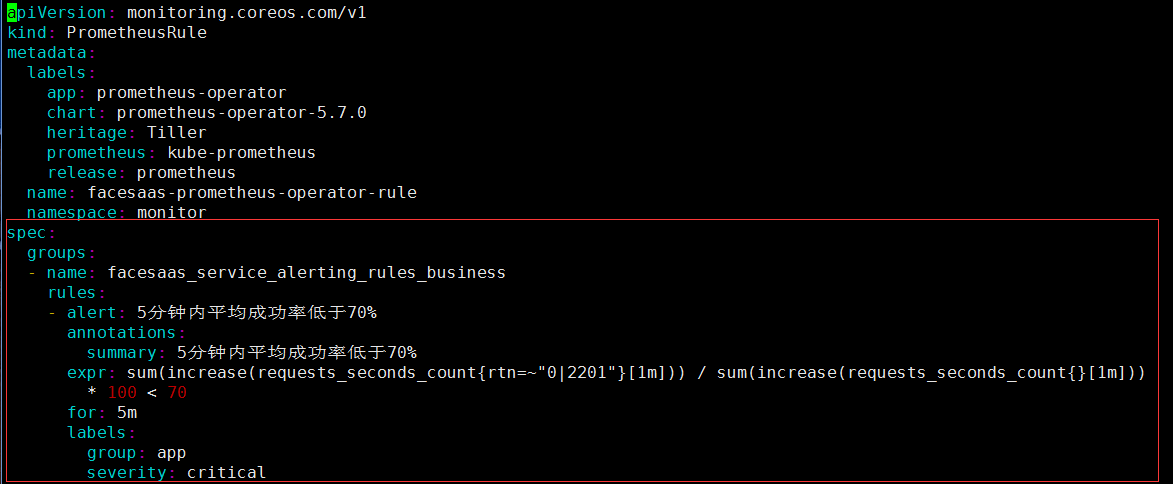
- 当5分钟内平均成功率低于70%,告警状态为inactive
- 当5分钟内平均成功率低于70%,且持续时间小于5分钟,告警状态为pending
- 当5分钟内平均成功率低于70%,且持续时间大于5分钟,告警状态为firing
注意:配置中的for语法就是用来设置告警持续时间的;如果配置中不设置for或者设置为0,那么pending状态会被直接跳过
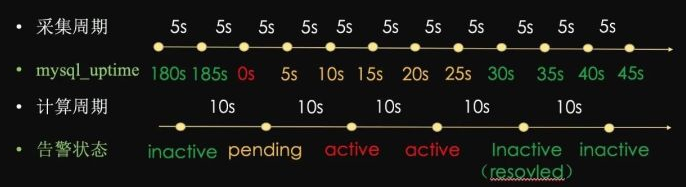
如上图所示:
- Prometheus以5s(scrape_interval)一个采集周期采集状态;
- 然后根据采集到状态按照10s(evaluation_interval)一个计算周期,计算表达式;
- 表达式为真,告警状态切换到pending;
- 下个计算周期,表达式仍为真,且符合for持续10s,告警状态变更为active,并将告警从Prometheus发送给Altermanger;
- 下个计算周期,表达式仍为真,且符合for持续10s,持续告警给Altermanger;
- 直到某个计算周期,表达式为假,告警状态变更为inactive,发送一个resolve给Altermanger,说明此告警已解决。
第二节 告警分组、抑制、静默
第一节我们成功的把一条mysql_uptime的告警发送给了Altermanger;但是Altermanger并不是把一条从Prometheus接收到的告警简简单单的直接发送出去;直接发送出去会导致告警信息过多,运维人员会被告警淹没;所以Altermanger需要对告警做合理的收敛。
告警分组
告警分组的作用
- 同类告警的聚合帮助运维排查问题
- 通过告警邮件的合并,减少告警数量
举例来说:我们按照mysql的实例id对告警分组;如下图所示,告警信息会被拆分成两组。
- mysql-A
- mysql_cpu_high
- mysql-B
- mysql_uptime
- mysql_slave_sql_thread_down
- mysql_slave_io_thread_down
实例A分组下的告警会合并成一个告警邮件发送;
实例B分组下的告警会合并成一个告警邮件发送;
通过分组合并,能帮助运维降低告警数量,同时能有效聚合告警信息,帮助问题分析。

告警抑制
首先在prometheus 告警规则添加标签:inhibit_instance(名字随便取的):
1、在 NodeExporter 告警规则中添加 inhibit_instance: ‘{{$labels.instance}}’ 其中 instance 格式为 ip:8888
2、在 LVS探测告警规则上添加:inhibit_instance: ‘{{$labels.remote_address}}:8888’,因为lvs 探测是在lvs前端机器上面所以机器的instance 与nodeexporter 的instance 并不一致,需要使用后端机器的 remote_address 作为问题机器的告警目标机器这样我们就获得了问题机器的ip,加上固定端口8888 就跟NodeExporter中的instance保持一致了
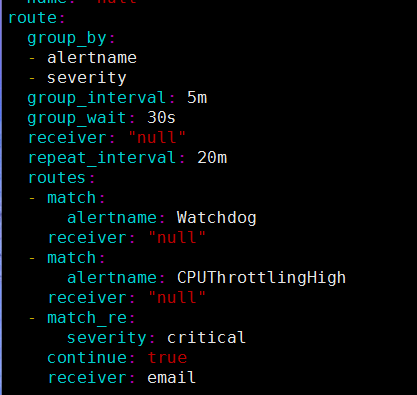
3、在 alertmanager 的规则中添加抑制规则,使用NodeExporterUnavailable抑制lvs通用连通性告警,自此同一台后端机器宕机只会在告警里面报 nodexporter 挂掉而不会报 lvs 不通了,但是lvs 不通exporter没有挂掉的情况则依然会报出来,这对于运维中告警抑制收敛很有用:
# 抑制规则测试inhibit_rules:- source_match:altername: 'Lvs不通'severity: 'critical'target_match:severity: 'warning'equal: ['alertname', 'instance']
告警抑制的作用
- 消除冗余的告警
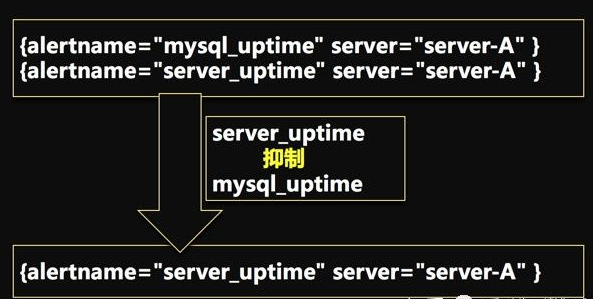
举例来说:同一台server-A的告警,如果有如下两条告警,并且配置了抑制规则。
- mysql_uptime
- server_uptime
最后只会收到一条server_uptime的告警。
A机器挂了,势必导致A服务器上的mysql也挂了;如配置了抑制规则,通过服务器down来抑制这台服务器上的其他告警;这样就能消除冗余的告警,帮助运维第一时间掌握最核心的告警信息。
告警静默
告警静默的作用
- 阻止发送可预期的告警
举例来说:夜间跑批时间,批量任务会导致实例A压力升高;我们配置了对实例A的静默规则。
- mysql-A
- qps_more_than_3000
- tps_more_than_2000
- thread_running_over_200
- mysql-B
- thread_running_over_200
最后我们只会收到一条实例B的告警。
A压力高是可预期的,周期性的告警会影响运维判断;这种场景下,运维需要聚焦处理实例B的问题即可。

第三节 告警延时
第二节我们提到了分组的概念,分组势必会带来延时;合理的配置延时,才能避免告警不及时的问题,同时帮助我们避免告警轰炸的问题。
我们先来看告警延时的几个重要参数:
group_by:分组参数,第二节已经介绍,比如按照[mysql-id]分组
group_wait:分组等待时间,比如:5s
group_interval:分组尝试再次发送告警的时间间隔,比如:5m
Repeat_interval: 分组内发送相同告警的时间间隔,比如:60m
延时的三个参数
我们还是举例来说,假设如下:
- 配置了延时参数:
- group_wait:5s
- group_interval:5m
- repeat_interval: 60m
- 有同组告警集A,如下:
- a1
- a2
- a3
- 有同组告警集B,如下:
- b1
- b2
场景一:
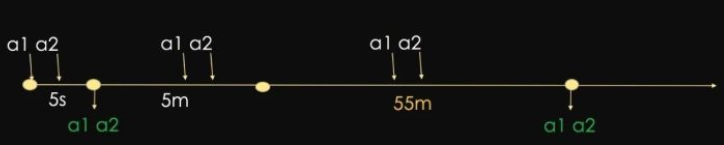
- a1先到达告警系统,此时在group_wait:5s的作用下,a1不会立刻告出来,a1等待5s,下一刻a2在5s内也触发,a1,a2会在5s后合并为一个分组,通过一个告警消息发出来;
- a1,a2持续未解决,它们会在repeat_interval: 60m的作用下,每隔一小时发送告警消息。
场景二:
- a1,a2持续未解决,中间又有新的同组告警a3出现,此时在group_interval:5m的作用下,由于同组的状态发生变化,a1,a2,a3会在5min中内快速的告知运维,不会被收敛60min(repeat_interval)的时间;
- a1,a2,a3如持续无变化,它们会在repeat_interval: 60m的作用下,再次每隔一小时发送告警消息。

延时小结
通过三个延时参数,告警实现了分组等待的合并发送(group_wait),未解决告警的重复提醒(repeat_interval),分组变化后快速提醒(group_interval)。

若有收获,就点个赞吧
0 人点赞
