人们为什么写书?当您排除创造力的乐趣,对语法和标点的某种喜爱,以及偶尔的自恋时,您基本上会渴望捕捉到一个短暂的想法,以便将来可以重新使用它。 。在很高的层次上,我只是激励并解释了数据处理管道中的持久状态。
从字面上看,持久状态是我们在第6章中讨论过的表,另外还要求将表牢固地存储在相对不易丢失的介质中。只要您不询问站点可靠性工程师,就可以存储在本地磁盘上。存储在复制的磁盘集上更好。最好将其存储在不同物理位置的一组复制磁盘上。一次存储在内存中绝对不算数。使用UPS备用电源和发电机在现场存储在多台机器的复制内存中。您得到图片。
在本章中,我们的目标是执行以下操作:
- 激发对管道内持久状态的需求
- 查看通常在管道中发现的两种形式的隐式状态
- 考虑一个真实的用例(广告转换归因),该用例很不适合隐性状态,用它来激发持久状态管理的一般,显式形式的显着特征
- 探索一种这样的状态API的具体体现,如Apache Beam所示
动机
首先,让我们更精确地激发持久状态。 从第6章我们知道分组是为我们提供表格的原因。 我在本章开始时假设的核心是正确的:持久保存这些表的目的是捕获其中包含的其他临时数据。 但是为什么有必要呢?
失败的必然性
在处理无界输入数据的情况下,最清楚地看到了该问题的答案,因此我们从这里开始。主要问题是,处理无限制数据的管道实际上打算永远运行。但是,与这些管道通常在其中执行的环境相比,永远运行是一个更为苛刻的服务级别目标。由于机器故障,计划内的维护,代码更改以及偶而配置不当的命令会占用整个生产管道集群,因此,长时间运行的管道不可避免地会出现中断。为了确保它们可以在发生此类情况时从中断的地方恢复,长时间运行的管道需要对中断之前的位置进行某种持久的恢复。这就是持久状态的出现。
让我们在无限数据之外进一步扩展这个想法。这仅在无限制的情况下相关吗?批处理管道是否使用持久状态,为什么或为什么不这样做?就像我们遇到的几乎所有其他批处理与流传输问题一样,答案与批处理和流传输系统本身的性质关系不大(考虑到我们在第6章中学到的知识,这也许不足为奇),而与历史上一直用于处理的数据集类型。
本质上,有界数据集的大小是有限的。因此,已针对该用例量身定制了处理绑定数据的系统(历史上为批处理系统)。他们通常认为输入在发生故障时可以全部重新处理。换句话说,如果某条处理流水线发生故障并且输入数据仍然可用,我们可以简单地重新启动相应的处理流水线,然后让它再次读取相同的输入。这称为重新处理输入。
他们还可能会认为故障很少发生,因此可以通过尽可能少地保留故障来接受常见故障的优化,并接受故障时重新计算的额外费用。对于特别昂贵的多阶段管道,可能存在某种每阶段全局检查点,可以更有效地恢复执行(通常作为改组的一部分),但这不是严格的要求,因此可能不存在于许多系统中。
另一方面,必须假定无边界数据集具有无限大小。 结果,已经建立了处理无限数据的系统(历史上为流系统)来匹配。 他们从不认为所有数据都可用于重新处理,只是其中一些已知子集。 为了提供至少一次或完全一次的语义,必须在持久检查点中考虑不再可用于重新处理的任何数据。 而且,如果您只需要最多一次,就不需要检查点。
归根结底,持久性没有任何批次或流特定的内容。 在两种情况下,状态都是有用的。 处理无限数据时,它恰好很关键,因此您会发现流系统通常为持久状态提供更复杂的支持。
正确性和效率
鉴于失败的必然性和应对失败的需要,持久状态可以看作提供了两件事:
临时输入的正确性基础。在处理有界数据时,通常可以假定输入永远存在; 1对于无界数据,这种假设通常不符合实际。持久状态使您可以保留必要的中间信息,以便在不可避免的情况下继续处理,即使在输入源继续前进并忘记了之前提供给您的记录之后也是如此。
作为减少故障的一部分,可以最大程度地减少重复工作和保留数据的方法。无论您的输入是否短暂,当管道遇到机器故障时,必须重做故障机器上未经过检查点的任何工作。根据管道及其输入的性质,这可能会在两个方面造成高昂的代价:在重新处理期间执行的工作量以及为支持重新处理而存储的输入数据量。
尽量减少重复的工作是相对简单的。通过检查流水线中的部分进度(计算中间结果以及输入检查点时的输入中的当前位置),可以极大地减少发生故障时重复进行的工作量,因为不会进行任何操作在需要从持久性输入中重播检查点之前。最常见的是,这涉及静态数据(即表),这就是为什么我们通常在表和分组的上下文中引用持久状态。但是也有持续的流形式(例如,Kafka及其亲戚)可以为该功能服务。
最大限度地减少持久化数据量是一个更大的讨论,该讨论将占用本章的大部分内容。到目前为止,至少可以说,对于许多实际用例而言,与其记住管道中任何给定阶段的检查点内的所有原始输入,不如记住一些局部的,中间的形式,这通常是可行的。正在进行的计算所占用的空间比所有原始输入要少(例如,在计算平均值时,总和和所看到的值的计数比构成该总和和计数的值的完整列表要紧凑得多) )。对这些中间数据进行检查不仅可以极大地减少管道中任何给定点上您需要记住的数据量,而且还可以相应地减少该特定阶段从故障中恢复所需的重新处理量。
此外,通过智能地垃圾收集不再需要的持久状态位(即,已知已经由管道完全处理的记录的状态),可以将持久状态下存储的数据量即使输入在技术上是无限的,给定的管道也可以随着时间的推移保持在可管理的大小。这样,处理无边界数据的管道可以继续永久有效地运行,同时仍提供强大的一致性保证,但无需完全调用管道的原始输入。
归根结底,持久状态实际上只是在数据处理管道中提供正确性和有效的容错能力的一种手段。 在这两个维度中的任何一个方面所需的支持量在很大程度上取决于流水线输入的性质和所执行的操作。 与有界输入相比,无界输入往往需要更多的正确性支持。 计算上昂贵的操作往往比计算上便宜的操作需要更多的效率支持。
隐含状态
现在让我们开始讨论持久状态的实用性。在大多数情况下,这基本上可以归结为在始终坚持每件事(有益于一致性,不利于效率)和永不坚持任何事情(不利于一致性,有益于效率)之间找到正确的平衡。我们将从始终存在的所有方面开始,然后朝另一个方向努力,寻找在不牺牲一致性的情况下权衡实现复杂性以提高效率的方法(因为通过从未持久化任何东西来破坏一致性很容易对于一致性无关紧要的情况,请选择“出路”,否则请选择“非选项”)。和以前一样,我们使用Apache Beam API来具体讨论,但是我们讨论的概念适用于当今存在的大多数系统。
另外,由于您没有什么办法可以减少原始输入的大小,而没有压缩数据的余地,因此我们的讨论集中于在中间状态表中保留数据的方式,这些中间状态表是作为分组操作的一部分而创建的。管道。将多个记录组合为某种组合的固有本质将为我们提供机会,以提高实现效率为代价来提高效率。
原始分组
我们探索的第一步,就是在频谱的始终存在的尽头,是管道中分组的最直接实现:输入的原始分组。 在这种情况下,分组操作通常类似于列表追加:每当新元素到达组中时,都会将其追加到对该组可见的元素列表中。
在Beam中,这正是将GroupByKey转换应用于PCollection时所获得的。 表示运动中的PCollection的流按键分组,以生成一个静止的表,其中包含来自该流的记录2,这些记录被分组为具有相同键的值的列表。 这显示在GroupByKey的PTransform签名中,该签名将输入声明为K / V对的PCollection,将输出声明为K / Iterable
class GroupByKey<K, V> extends PTransform< PCollection<KV<K, V>>, PCollection<KV<K, Iterable<V>>>>>
每次为该表中的键+窗口触发触发器时,它将为该键+窗口发射一个新窗格,其值为我们在前面的签名中看到的Iterable
让我们看一下示例7-1中的示例。 我们将使用例6-5中的求和管道(具有固定窗口和早期/按时间/延迟触发器的求和管道),并将其转换为使用原始分组而不是增量组合(我们将在本章稍后讨论) 。 为此,我们首先将GroupByKey转换应用于已解析的用户/得分键/值对。 GroupByKey操作执行原始分组,产生具有用户键/值对和分数Iterable
示例7-1 通过早期/及时/后期API提前触发,按时触发和延迟触发
PCollection<String> raw = IO.read(...);PCollection<KV<Team, Integer>> input = raw.apply(new ParseFn()); PCollection<KV<Team, Integer>> groupedScores = input.apply(Window.into(FixedWindows.of(TWO_MINUTES)) .triggering(AfterWatermark() .withEarlyFirings(AlignedDelay(ONE_MINUTE)) .withLateFirings(AfterCount(1)))).apply(GroupBy.<String, Integer>create()); PCollection<KV<Team, Integer>> totals = input.apply(MapElements.via((KV<String, Iterable<Integer>> kv) -> StreamSupport.intStream(kv.getValue().spliterator(), false).sum()));
观察实际运行中的管道,我们将看到类似于图7-1所示的内容。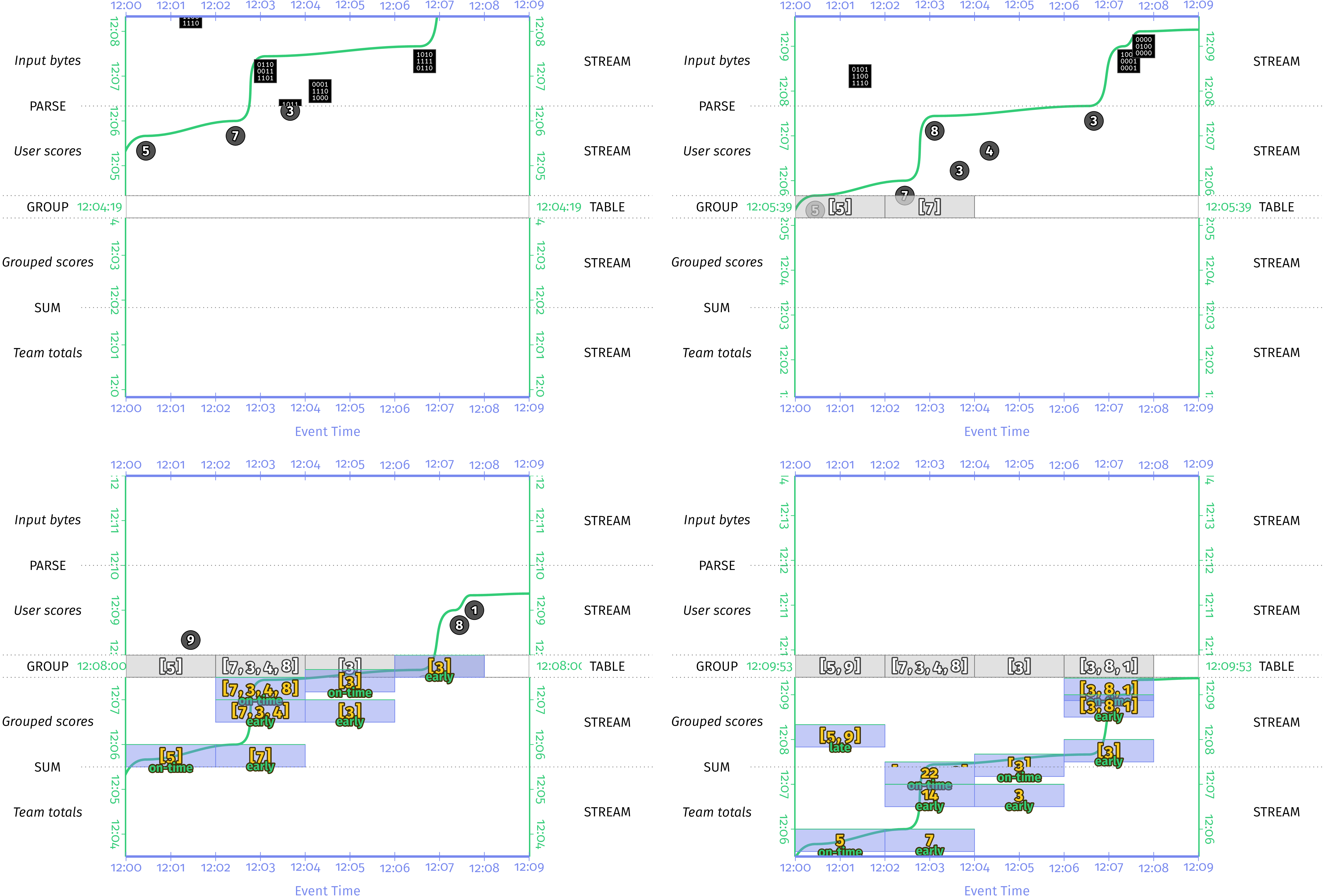
图7-1 通过带有窗口和早期/准时/延迟触发的原始输入分组求和。 原始输入被分组在一起,并通过GroupByKey转换存储在表中。 触发后,MapElements lambda将单个窗格内的原始输入求和在一起以得出每个团队的分数。
将其与图6-10(使用增量合并,稍后将进行讨论)进行比较,显然可以看出情况要差得多。 首先,我们要存储更多数据:我们现在不再存储每个窗口一个整数,而是存储该窗口的所有输入。 其次,如果我们有多个触发器触发,我们将通过重新汇总已经为先前的触发器触发加在一起的输入来进行重复工作。 最后,如果分组操作是将状态检查为永久存储的点,则在计算机发生故障时,我们必须再次重新计算表的任何重新触发的总和。 那是很多重复的数据和计算。 最好是增量计算并检查实际的总和,这是增量合并的一个示例。
增量组合
为实现效率而交易实现复杂性的第一步是逐步组合。 这个概念通过CombineFn类在Beam API中得到体现。 简而言之,增量合并是一种基于用户定义的关联和可交换合并运算符的自动状态形式(如果您不确定这两个术语的含义,我会在稍后对其进行更精确地定义)。 尽管对于随后的讨论不是严格必需的,但是CombineFn API的重要部分类似于示例7-2。
示例7-2 Apache Beam的缩写CombineFn API
class CombineFn<InputT, AccumT, OutputT> {// Returns an accumulator representing the empty value. AccumT createAccumulator();// Adds the given input value into the given accumulatorAccumT addInput(AccumT accumulator, InputT input);// Merges the given accumulators into a new, combined accumulatorAccumT mergeAccumulators(Iterable<AccumT> accumulators);// Returns the output value for the given accumulatorOutputT extractOutput(AccumT accumulator);}
CombineFn接受InputT类型的输入,这些输入可以组合在一起成为AccumT类型的部分集合,称为累积器。这些蓄电池本身也可以组合成新的蓄电池。最后,可以将一个累加器转换为OutputT类型的输出值。对于类似平均值的输入,输入可能是整数,累加器是整数对(即Pair <输入总和,输入计数>),而输出则是代表组合输入平均值的单个浮点值。
但是所有这些结构给我们带来了什么?从概念上讲,增量组合的基本思想是许多类型的聚合(求和,均值等)具有以下属性:
- 增量聚合具有一种中间形式,该形式可以捕获将一组N个输入组合起来比部分输入本身完整的列表(即CombineFn中的AccumT类型)更为紧凑的部分进度。如前所述,平均而言,这是一个总和/计数对。基本求和甚至更简单,用一个数字作为累加器。直方图将具有由存储桶组成的相对复杂的累加器,其中每个存储桶都包含一个在特定范围内看到的值的数量的计数。但是,在所有这三种情况下,代表N个元素聚合的累加器所消耗的空间量仍然明显小于原始N个元素本身所消耗的空间量,尤其是当N的大小增加时。
增量聚合对于跨两个维度的排序无关紧要:
各个元素,表示:
COMBINE(a,b)== COMBINE(b,a)
元素分组,表示:
COMBINE(COMBINE(a,b),c)== COMBINE(a,COMBINE(b,c))
这些性质分别称为可交换性和缔合性。一致地3,它们实际上意味着我们可以自由地以任意顺序和任意子组来组合元素和部分集合。这使我们可以通过两种方式优化聚合:
增量化
因为各个输入的顺序无关紧要,所以我们不需要提前缓冲所有输入,然后以某种严格的顺序处理它们(例如,按照事件时间的顺序;但是请注意,这仍然是独立的)在汇总之前,按事件时间将元素改组到适当的事件时间窗口中);我们可以在到达时简单地将它们一一合并。这不仅大大减少了必须缓冲的数据量(由于我们的操作的第一个属性,该属性表示中间形式比局部输入本身更紧凑地表示了部分聚合),而且还分散了计算量随时间平均分配(相对于整个输入集被缓冲后立即一次汇总一连串的输入)。
并行化
由于输入的部分子组的合并顺序无关紧要,因此我们可以随意分配这些子组的计算量。更具体地说,我们可以自由地将这些子组的计算分布在多台计算机上。这项优化是MapReduce合并器(Beam的CombineFn的起源)的核心。
MapReduce的Combiner优化对于解决热键问题至关重要,在热键问题中,对输入流执行某种分组计算,而该输入流太大而无法由单个物理机进行合理处理。一个典型的例子是在相对较少的维度范围内(例如,按网络浏览器系列:Chrome,Firefox,Safari等)分解大容量的分析数据(例如,流行网站的网络流量)。对于流量特别大的网站,即使是唯一的一台计算机,通常很难在一台计算机上计算单个Web浏览器系列的统计信息;太多的流量无法跟上。但是通过求和之类的关联和可交换运算,可以将初始聚合分布在多台计算机上,每台计算机都计算出部分聚合。然后可以将这些机器生成的部分集合的集合(其大小现在比原始输入小许多个数量级)在单个机器上进一步组合在一起,以产生最终的集合结果。
顺便说一句,这种并行化功能还带来了另一个好处:聚合操作与合并窗口自然兼容。当两个窗口合并时,它们的值也必须以某种方式合并。对于原始分组,这意味着将两个完整的缓冲值列表合并在一起,这将花费O(N)。但是使用CombineFn,它是两个部分聚合的简单组合,通常是O(1)运算。
为了完整起见,请再次考虑示例7-3中所示的示例6-5,该示例使用增量组合实现求和管线。
示例7-3 如示例6-5所示,通过增量组合进行分组和求和
PCollection<String> raw = IO.read(...);PCollection<KV<Team, Integer>> input = raw.apply(new ParseFn()); PCollection<KV<Team, Integer>> totals = input.apply(Window.into(FixedWindows.of(TWO_MINUTES)) .triggering(AfterWatermark() .withEarlyFirings(AlignedDelay(ONE_MINUTE)) .withLateFirings(AfterCount(1)))).apply(Sum.integersPerKey());
执行后,我们得到的是图6-10(图7-2所示)。 与图7-1相比,这显然是一个很大的改进,在存储的数据量和执行的计算量方面效率更高。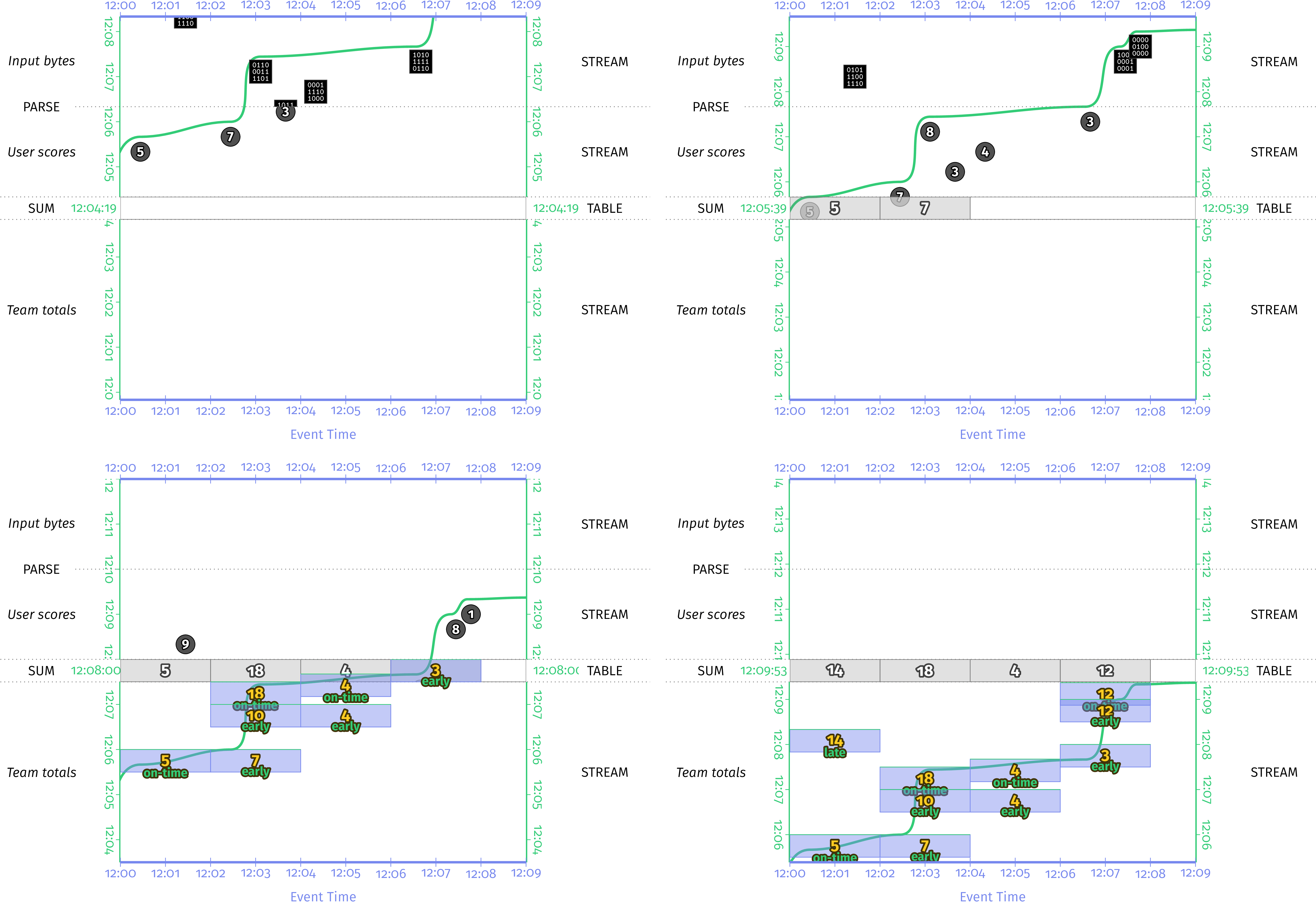
图7-2 通过增量组合进行分组和求和。 在此版本中,增量和被计算并存储在表中,而不是输入列表,后者必须在以后独立地求和。
通过为分组操作提供更紧凑的中间表示,以及放宽对订购的要求(在元素和子组级别上),Beam的CombineFn权衡了一定的实现复杂性,以换取效率的提高。 这样,它可以为热键问题提供一个干净的解决方案,并且可以很好地与合并窗口的概念配合使用。
但是,缺点之一是您的分组操作必须符合相对受限的结构。 这对于总和,手段等等都是一件好事,但在现实世界中有很多用例,其中需要一种更通用的方法,该方法可以精确控制复杂性和效率之间的折衷。 接下来,我们将探讨这种通用方法的含义。
广义状态
尽管到目前为止,我们所研究的两种隐式方法都有其优点,但它们都在一个维度上缺乏灵活性:灵活性。原始分组方法要求您在处理整个分组之前始终将原始输入缓冲到分组操作中,因此无法一路处理部分数据。全部或全无。增量合并方法特别允许进行部分处理,但有一个局限性,即所涉及的处理是可交换和关联的,并且随着记录一一到达而发生。
如果我们想支持更通用的流持久状态方法,我们需要更灵活的方法。具体来说,我们需要三个方面的灵活性:
- 数据结构的灵活性;也就是说,能够以最适合当前任务的方式来构造我们读写的数据。原始分组本质上提供了一个可追加列表,增量组合本质上提供了一个始终完整写入和读取的单个值。但是,我们可能还需要采用多种其他方式来构造持久性数据,每种方式都具有不同类型的访问模式和相关成本:地图,树,图形,集合等。支持各种持久性数据类型对于提高效率至关重要。
Beam通过允许单个DoFn声明多个状态字段(每个特定类型)来支持数据类型的灵活性。这样,逻辑上独立的状态(例如,访问和印象)可以分别存储,并且语义上不同的状态类型(例如,地图和列表)可以根据给定其访问模式的类型以自然的方式进行访问。
- 读写粒度的灵活性;也就是说,可以在任何给定的时间调整写入或读取的数据量和类型,以实现最佳效率。这归结为在任何给定时间点精确地写入和读取必要数量的数据的能力:不多,不少(并且尽可能并行)。
鉴于专用数据类型允许集中访问模式类型(例如,设置成员操作可以使用诸如布隆过滤器之类的东西在后台进行编程,以最大程度地减少读取的数据量),因此这与上一点是并行的某些情况下)。但是它也超越了它。例如,允许并行(例如,通过期货)分派多个大型读取。
在Beam中,可通过提供细粒度访问功能的特定于数据类型的API来灵活地进行细粒度的写入和读取,并结合异步I / O机制,该机制允许将写入和读取一起批处理以提高效率。
- 处理时间表的灵活性;也就是说,在我们关注的两个时域中的任何一个时域中,将发生特定类型的处理的时间绑定到时间进度的能力:事件时间完整性和处理时间。触发器在此处提供了一组受限的灵活性,完整性触发器提供了一种将处理绑定到通过窗口末端的水印的方式,重复更新触发器提供了一种将处理绑定到处理时域中的周期性进度的方式。但是对于某些用例(例如,某些类型的联接,您不必关心整个窗口的输入完整性,仅在联接中特定记录的事件时间之前的输入完整性),触发器是不够的灵活的。因此,我们需要更通用的解决方案。
在Beam中,通过计时器提供了灵活的处理调度。4计时器是一种特殊的状态类型,它通过在某个时间点(事件时间或处理时间)中某个特定的时间点绑定特定的时间点来绑定该时间点。时间到了。这样,可以将特定的处理位延迟到将来的更合适的时间。
这三个特征之间的共同点是灵活性。 相对灵活的原始分组或增量组合方法可以很好地满足用例的特定子集。 但是,当在他们相对狭窄的专业知识范围之外解决任何问题时,这些选择通常会不足。 发生这种情况时,您需要完全通用状态API的功能和灵活性,以使您能够最佳地调整持久状态的利用率。
换句话说,原始分组和增量组合是相对高级的抽象,它们使管道的精巧表达具有(至少在组合器的情况下)具有一些自动优化的良好属性。 但是有时候您需要低调一些才能获得所需的行为或性能。 这就是广义状态允许您执行的操作。
案例研究:转化归因
为了了解这一点,现在让我们看一下原始分组和增量组合均不能很好地满足使用需求的用例:转化归因。 这是一种在广告界广泛使用的技术,可以提供有关广告效果的具体反馈。 尽管相对容易理解,但到目前为止我们已经考虑过的两种隐式状态中的任何一组,都无法很好地满足要求。
想象一下,您有一个分析管道,该管道可以监视网站访问量,并与将访问量定向到该网站的广告印象结合起来。 目标是向用户显示特定广告的归属,以实现网站本身的某些目标(通常可能需要超出初始广告目标页面的许多步骤),例如注册邮件列表 或购买物品。
图7-3显示了一组网站访问,目标和广告展示的示例,其中一个归因转化以红色突出显示。 要建立无序,无序的数据流的转化归因,需要跟踪到目前为止的印象,访问和目标。 这就是持久状态的出现。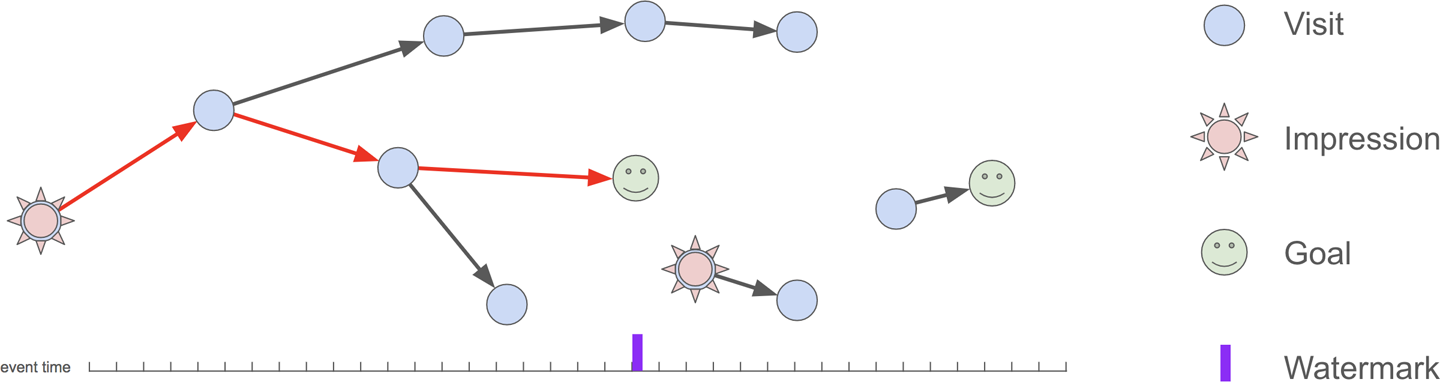
图7-3 转化归因示例
在此图中,用户对网站上各个页面的遍历表示为图形。 印象是向用户显示并单击的广告,导致用户访问网站上的页面。 造访代表在网站上浏览过的一个页面。 目标是特定的访问页面,这些页面已被确定为用户所需的目的地(例如,完成购买或注册邮件列表)。 转化归因的目的是确定导致用户在网站上实现某些目标的广告展示次数。 在此图中,以红色高亮显示了这样一种转换。 请注意,事件可能会无序到达,因此图中的事件时间轴和水印参考点指示了认为输入正确之前的时间。
建立健壮的大规模归因管道有很多工作要做,但是有几个方面值得明确指出。 我们尝试构建的任何此类管道都必须执行以下操作:
处理乱序数据
由于网站访问量和广告印象数据来自不同的系统,这两个系统本身都是作为分布式收集服务实现的,因此数据可能会乱序到达。因此,我们的管道必须能够抵抗这种混乱。
处理大量数据
我们不仅必须假设该管道将为大量独立用户处理数据,而且根据给定广告活动的数量和给定网站的受欢迎程度,我们可能需要存储大量的印象和/或流量数据,因为我们试图建立损耗的证据。例如,为每位用户存储90天的访问,展示和目标树5数据,这使我们能够建立跨越数月活动的归因,这并非闻所未闻。
防止垃圾邮件
考虑到涉及金钱,正确性至关重要。我们不仅必须确保访问次数和展示次数仅占一次(通过使用支持有效一次处理的执行引擎,我们将免费获得或多或少的收益),而且还必须保护我们的广告客户免受垃圾邮件攻击的侵害试图对广告客户收取不公平的费用。例如,同一位用户连续点击多次的单个广告将获得多次展示,但只要这些点击在一定时间内(例如同一天之内)发生就可以了,则它们只能被赋值一次。换句话说,即使系统保证我们将一次看到每个单独的印象,我们也必须在技术上不同的事件但业务逻辑要求我们将其解释为重复的印象之间执行一些手动重复数据删除。
优化性能
最重要的是,由于该管道的潜在规模,我们必须始终注意优化管道的性能。由于写入持久性存储的固有成本,持久性状态通常可能是此类管道中的性能瓶颈。因此,我们前面讨论的灵活性特性对于确保我们的设计尽可能地发挥性能至关重要。
使用Apache Beam的转化归因
现在,我们了解了我们要解决的基本问题并牢记一些重要要求,让我们使用Beam的State和Timers API构建基本的转化归因转换。我们将像在Beam中的任何其他DoFn一样编写此代码,但是我们将利用状态和计时器扩展名,这些扩展名允许我们写入和读取持久状态和计时器字段。那些想用真实代码进行学习的人可以在GitHub上找到完整的实现。
请注意,与Beam中的所有分组操作一样,State API的使用范围仅限于当前键和窗口,窗口寿命由指定的允许的延迟参数决定;在此示例中,我们将在单个全局窗口中进行操作。像大多数DoFns一样,并行化是每个键线性化的。另外请注意,为简单起见,我们将取消90天范围之外的访问和展示的手动垃圾收集,这对于防止持久状态永远增长是必要的。
首先,我们为访问,印象,访问/印象联合(用于加入)和完成的归因定义一些POJO类,如示例7-4所示。
示例7-4访问,印象,VisitOrImpression和归因对象的POJO定义
@DefaultCoder(AvroCoder.class) class Visit {@Nullable private String url;@Nullable private Instant timestamp;// The referring URL. Recall that we’ve constrained the problem in this // example to assume every page on our website has exactly one possible // referring URL, to allow us to solve the problem for simple trees// rather than more general DAGs.@Nullable private String referer;@Nullable private boolean isGoal;@SuppressWarnings("unused") public Visit() {}public Visit(String url, Instant timestamp, String referer, boolean isGoal) {this.url = url; this.timestamp = timestamp; this.referer = referer; this.isGoal = isGoal;}public String url() { return url; }public Instant timestamp() { return timestamp; } public String referer() { return referer; }public boolean isGoal() { return isGoal; }@Overridepublic String toString() {return String.format("{ %s %s from:%s%s }", url, timestamp, referer,isGoal ? " isGoal" : "");} }@DefaultCoder(AvroCoder.class) class Impression {@Nullable private Long id; @Nullable private String sourceUrl; @Nullable private String targetUrl; @Nullable private Instant timestamp;public static String sourceAndTarget(String source, String target) { return source + ":" + target;}@SuppressWarnings("unused") public Impression() {}public Impression(Long id, String sourceUrl, String targetUrl, Instant timestamp) {this.id = id; this.sourceUrl = sourceUrl; this.targetUrl = targetUrl; this.timestamp = timestamp;}public Long id() { return id; }public String sourceUrl() { return sourceUrl; } public String targetUrl() { return targetUrl; } public String sourceAndTarget() {return sourceAndTarget(sourceUrl, targetUrl); }public Instant timestamp() { return timestamp; }@Overridepublic String toString() {return String.format("{ %s source:%s target:%s %s }",id, sourceUrl, targetUrl, timestamp);} }@DefaultCoder(AvroCoder.class) class VisitOrImpression {@Nullable private Visit visit; @Nullable private Impression impression;@SuppressWarnings("unused") public VisitOrImpression() { }public VisitOrImpression(Visit visit, Impression impression) { this.visit = visit;this.impression = impression;}public Visit visit() { return visit; }public Impression impression() { return impression; } }@DefaultCoder(AvroCoder.class) class Attribution {@Nullable private Impression impression; @Nullable private List<Visit> trail; @Nullable private Visit goal;@SuppressWarnings("unused") public Attribution() {}public Attribution(Impression impression, List<Visit> trail, Visit goal) { this.impression = impression;this.trail = trail;this.goal = goal;}public Impression impression() { return impression; } public List<Visit> trail() { return trail; }public Visit goal() { return goal; }@Overridepublic String toString() {StringBuilder builder = new StringBuilder();builder.append("imp=" + impression.id() + " " + impression.sourceUrl()); for (Visit visit : trail) {builder.append(" → " + visit.url()); }builder.append(" → " + goal.url());return builder.toString(); }}
接下来,我们定义一个Beam DoFn,以使用由用户键入的扁平化的Visits和Impressions集合。 反过来,它将产生一个归因集合。 其签名类似于示例7-5。
示例7-5 DoFn签名用于我们的转化归因转换
AttributionFn类扩展DoFn
- 将所有访问记录存储在以其URL为关键字的地图中,以便在跟踪从目标向后的访问记录时,我们可以轻松地对其进行查找。
- 将所有印象存储在以它们所引用的URL为关键字的地图中,这样我们就可以识别出引发目标跟踪的印象。
- 每当我们看到访问恰好是一个目标时,请为该目标的时间戳设置一个事件时间计时器。与该计时器相关联的是一种对未完成目标执行目标归因的方法。这将确保归因仅在完成目标的输入后才发生。
- 由于Beam缺乏对动态计时器集的支持(当前,所有计时器都必须在管道定义时声明,尽管可以在运行时为每个不同的时间点设置和重置每个单独的计时器),我们还需要跟踪我们仍然需要归因于所有目标的时间戳。这样一来,我们就可以为所有未完成目标的最小时间戳设置一个归因计时器。在为目标分配了最早的时间戳后,我们再次为定时器设定了下一个最早目标的时间戳。
现在,让我们分步介绍实施过程。首先,我们需要声明DoFn中所有状态和计时器字段的规范。对于状态,规范规定了字段本身的数据结构类型(例如,映射或列表)以及其中包含的数据类型以及与之相关的编码器。对于计时器,它指示相关的时域。然后为每个规范分配一个唯一的ID字符串(通过@ StateID / @ TimerId批注),这将使我们以后可以将这些规范与参数和方法动态关联。对于我们的用例,我们将定义(在示例7-6中)以下内容:
- 针对访问和展示的两个MapState规范
- 目标的单一SetState规范
- 用于跟踪最小未决目标时间戳记的ValueState规范
- 延迟归因逻辑的计时器规范
示例7-6 州立规范
class AttributionFn extends DoFn<KV<String, VisitOrImpression>, Attribution> { @StateId("visits")private final StateSpec<MapState<String, Visit>> visitsSpec =StateSpecs.map(StringUtf8Coder.of(), AvroCoder.of(Visit.class));// Impressions are keyed by both sourceUrl (i.e., the query) and targetUrl// (i.e., the click), since a single query can result in multiple impressions. // The source and target are encoded together into a single string by the// Impression.sourceAndTarget method.@StateId("impressions")private final StateSpec<MapState<String, Impression>> impSpec =StateSpecs.map(StringUtf8Coder.of(), AvroCoder.of(Impression.class));@StateId("goals")private final StateSpec<SetState<Visit>> goalsSpec =StateSpecs.set(AvroCoder.of(Visit.class));@StateId("minGoal")private final StateSpec<ValueState<Instant>> minGoalSpec =StateSpecs.value(InstantCoder.of());@TimerId("attribution")private final TimerSpec timerSpec =TimerSpecs.timer(TimeDomain.EVENT_TIME);... continued in Example 7-7 below ...
接下来,我们实现我们的核心@ProcessElement方法。 这是每次新记录到达时都会运行的处理逻辑。 如前所述,我们需要记录访问和对持久状态的印象,并跟踪目标并管理计时器,以将归因逻辑绑定到水印所跟踪的事件时间完整性的进度。 通过传递给@ProcessElement方法的参数提供对状态和计时器的访问,并且Beam运行时使用@StateId和@TimerId批注指示的适当参数来调用我们的方法。 这样,逻辑本身就相对简单了,如示例7-7所示。
示例7-7 @ProcessElement实现
... continued from Example 7-6 above ...@ProcessElementpublic void processElement(@Element KV<String, VisitOrImpression> kv,@StateId("visits") MapState<String, Visit> visitsState, @StateId("impressions") MapState<String, Impression> impressionsState, @StateId("goals") SetState<Visit> goalsState,@StateId("minGoal") ValueState<Instant> minGoalState,@TimerId("attribution") Timer attributionTimer) { Visit visit = kv.getValue().visit();Impression impression = kv.getValue().impression();if (visit != null) {if (!visit.isGoal()) {LOG.info("Adding visit: {}", visit);visitsState.put(visit.url(), visit); }else{LOG.info("Adding goal (if absent): {}", visit); goalsState.addIfAbsent(visit);Instant minTimestamp = minGoalState.read();if (minTimestamp == null || visit.timestamp().isBefore(minTimestamp)) {LOG.info("Setting timer from {} to {}", Utils.formatTime(minTimestamp),Utils.formatTime(visit.timestamp())); attributionTimer.set(visit.timestamp()); minGoalState.write(visit.timestamp());}LOG.info("Done with goal"); }}if (impression != null) {// Dedup logical impression duplicates with the same source and target URL. // In this case, first one to arrive (in processing time) wins. A more// robust approach might be to pick the first one in event time, but that // would require an extra read before commit, so the processing-time// approach may be slightly more performant.LOG.info("Adding impression (if absent): {} → {}", impression.sourceAndTarget(), impression);impressionsState.putIfAbsent(impression.sourceAndTarget(), impression); }}... continued in Example 7-8 below ...
请注意,这是如何与常规状态API中的三个所需功能联系在一起的:
数据结构的灵活性
我们有地图,集合,值和计时器。 它们使我们能够以对算法有效的方式有效地操纵状态。
灵活的读写粒度
我们处理的每次访问和展示都会调用我们的@ProcessElement方法。因此,我们需要它尽可能地高效。我们利用仅对所需的特定字段进行细粒度,盲目写入的能力。在遇到新目标的罕见情况下,我们也只会从@ProcessElement方法中的状态读取数据。当我们这样做时,我们只读取一个整数值,而无需触摸(可能更大)的地图和列表。
加工安排的灵活性
多亏了计时器,我们才能够延迟复杂的目标归因逻辑(下定义),直到我们确信已收到所有必要的输入数据,从而最大程度地减少了重复工作并最大程度地提高了效率。
定义了核心处理逻辑之后,现在让我们看一下最后的代码,目标归因方法。该方法带有@TimerId注释,以将其标识为在触发相应的归属计时器时要执行的代码。这里的逻辑比@ProcessElement方法要复杂得多:
- 首先,我们需要加载整个访问和印象图以及我们的目标集。我们需要地图在要建立的归因路径中向后退一步,我们需要目标来了解由于当前计时器触发以及下一个未完成的目标而归因于哪些目标我们希望将来安排归因(如果有)。
- 加载状态后,我们会一次循环地处理此计时器的目标,重复一次:
- 检查是否有任何印象将用户引向了路径中的当前访问(从目标开始)。如果是这样,我们就已经完成了该目标的归因,可以突围而出并归因于此。
- 接下来检查是否有任何访问是当前访问的引荐来源。如果是这样,我们就在路径中找到了向后指针,因此我们对其进行遍历并重新开始循环。
- 如果没有找到匹配的印象或访问,则我们的目标是自然实现的,没有相关的印象。在这种情况下,我们可以简单地跳出循环并继续进行下一个目标(如果有)。
- 用尽目标列表准备好归因后,我们为列表中的下一个未完成目标(如果有)设置计时器,并重置相应的ValueState来跟踪最小未完成目标时间戳。
为了简洁起见,我们首先来看一下核心目标归因逻辑,如下所示
为了简洁起见,我们首先查看示例7-8中所示的核心目标归因逻辑,该逻辑大致对应于上一列表中的点2。
示例7-8目标归因逻辑
... continued from Example 7-7 above ...private Impression attributeGoal(Visit goal,Map<String, Visit> visits,Map<String, Impression> impressions,List<Visit> trail) { Impression impression = null;Visit visit = goal; while (true) {String sourceAndTarget = Impression.sourceAndTarget( visit.referer(), visit.url());LOG.info("attributeGoal: visit={} sourceAndTarget={}", visit, sourceAndTarget);if (impressions.containsKey(sourceAndTarget)) { LOG.info("attributeGoal: impression={}", impression);// Walked entire path back to impression. Return success. return impressions.get(sourceAndTarget);} else if (visits.containsKey(visit.referer())) {// Found another visit in the path, continue searching. visit = visits.get(visit.referer());trail.add(0, visit);}else{LOG.info("attributeGoal: not found");// Referer not found, trail has gone cold. Return failure. return null;} }}... continued in Example 7-9 below ...
其余代码(省略一些简单的辅助方法)将处理初始化和获取状态,调用归因逻辑,并进行清理以安排任何剩余的未决目标归因尝试,如示例7-9所示。
示例7-9 目标归因的整体@TimerId处理逻辑
@OnTimer("attribution") public void attributeGoal(@Timestamp Instant timestamp,@StateId("visits") MapState<String, Visit> visitsState,@StateId("impressions") MapState<String, Impression> impressionsState,@StateId("goals") SetState<Visit> goalsState,@StateId("minGoal") ValueState<Instant> minGoalState,@TimerId("attribution") Timer attributionTimer,OutputReceiver<Attribution> output) {LOG.info("Processing timer: {}", Utils.formatTime(timestamp));// Batch state reads together via futures.ReadableState<Iterable<Map.Entry<String, Visit> > > visitsFuture = visitsState.entries().readLater();ReadableState<Iterable<Map.Entry<String, Impression> > > impressionsFuture = impressionsState.entries().readLater();ReadableState<Iterable<Visit>> goalsFuture = goalsState.readLater();// Accessed the fetched state.Map<String, Visit> visits = buildMap(visitsFuture.read());Map<String, Impression> impressions = buildMap(impressionsFuture.read()); Iterable<Visit> goals = goalsFuture.read();// Find the matching goalVisit goal = findGoal(timestamp, goals);// Attribute the goalList<Visit> trail = new ArrayList<>();Impression impression = attributeGoal(goal, visits, impressions, trail); if (impression != null) {output.output(new Attribution(impression, trail, goal));impressions.remove(impression.sourceAndTarget()); }goalsState.remove(goal);// Set the next timer, if any.Instant minGoal = minTimestamp(goals, goal); if (minGoal != null) {LOG.info("Setting new timer at {}", Utils.formatTime(minGoal)); minGoalState.write(minGoal);attributionTimer.set(minGoal);}else{ minGoalState.clear();} }
此代码块以与@ProcessElement方法非常相似的方式将通用状态API的三个所需功能联系起来,但有一个明显的区别:
灵活的读写粒度
我们能够进行一个粗粒度的读取,以便将所有数据加载到地图中并进行设置。 这通常比分别加载每个字段,甚至更糟地逐元素加载每个字段要有效得多。 它还显示了能够遍历访问粒度范围(从细粒度到粗粒度)的重要性。
就是这样! 我们已经实施了基本的转化归因管道,其效率足以使用合理数量的资源以可观的规模进行运营。 而且重要的是,面对乱序的数据,它可以正常运行。 如果查看示例7-10中用于单元测试的数据集,则即使在很小的规模下,也可以看到许多挑战:
- 跨一组共享的URL跟踪并归因于多个不同的转化。
- 数据乱序到达,特别是目标(在处理时间内)在导致访问的访问和印象之前到达,以及较早出现的其他目标。
- 对不同的目标URL产生不同印象的源URL。
- 必须将物理上完全不同的印象(例如,对同一广告的多次点击)重复数据删除为一个逻辑印象。
示例7-10 用于验证转化归因逻辑的示例数据集
private static TestStream<KV<String, VisitOrImpression>> createStream() {// Impressions and visits, in event-time order, for two (logical) attributable // impressions and one unattributable impression.Impression signupImpression = new Impression(123L, "http://search.com?q=xyz","http://xyz.com/", Utils.parseTime("12:01:00")); Visit signupVisit = new Visit("http://xyz.com/", Utils.parseTime("12:01:10"),"http://search.com?q=xyz", false/*isGoal*/); Visit signupGoal = new Visit("http://xyz.com/join-mailing-list", Utils.parseTime("12:01:30"), "http://xyz.com/", true/*isGoal*/);Impression shoppingImpression = new Impression(456L, "http://search.com?q=thing", "http://xyz.com/thing", Utils.parseTime("12:02:00"));Impression shoppingImpressionDup = new Impression(789L, "http://search.com?q=thing", "http://xyz.com/thing", Utils.parseTime("12:02:10"));Visit shoppingVisit1 = new Visit( "http://xyz.com/thing", Utils.parseTime("12:02:30"), "http://search.com?q=thing", false/*isGoal*/);Visit shoppingVisit2 = new Visit( "http://xyz.com/thing/add-to-cart", Utils.parseTime("12:03:00"), "http://xyz.com/thing", false/*isGoal*/);Visit shoppingVisit3 = new Visit( "http://xyz.com/thing/purchase", Utils.parseTime("12:03:20"), "http://xyz.com/thing/add-to-cart", false/*isGoal*/);Visit shoppingGoal = new Visit("http://xyz.com/thing/receipt", Utils.parseTime("12:03:45"), "http://xyz.com/thing/purchase", true/*isGoal*/);Impression unattributedImpression = new Impression(000L, "http://search.com?q=thing", "http://xyz.com/other-thing", Utils.parseTime("12:04:00"));Visit unattributedVisit = new Visit("http://xyz.com/other-thing", Utils.parseTime("12:04:20"), "http://search.com?q=other thing", false/*isGoal*/);// Create a stream of visits and impressions, with data arriving out of order.return TestStream.create(KvCoder.of(StringUtf8Coder.of(), AvroCoder.of(VisitOrImpression.class))) .advanceWatermarkTo(Utils.parseTime("12:00:00")) .addElements(visitOrImpression(shoppingVisit2, null)) .addElements(visitOrImpression(shoppingGoal, null)) .addElements(visitOrImpression(shoppingVisit3, null)) .addElements(visitOrImpression(signupGoal, null)) .advanceWatermarkTo(Utils.parseTime("12:00:30")) .addElements(visitOrImpression(null, signupImpression)) .advanceWatermarkTo(Utils.parseTime("12:01:00")) .addElements(visitOrImpression(null, shoppingImpression)) .addElements(visitOrImpression(signupVisit, null)) .advanceWatermarkTo(Utils.parseTime("12:01:30")) .addElements(visitOrImpression(null, shoppingImpressionDup)) .addElements(visitOrImpression(shoppingVisit1, null)) .advanceWatermarkTo(Utils.parseTime("12:03:45")) .addElements(visitOrImpression(null, unattributedImpression)) .advanceWatermarkTo(Utils.parseTime("12:04:00")) .addElements(visitOrImpression(unattributedVisit, null)) .advanceWatermarkToInfinity();}
另外请记住,我们在此工作的是一个相对受限的转化归因版本。 全面的实施将面临其他挑战(例如,垃圾收集,访问DAG(而不是树木))。 无论如何,该管道与原始分组增量组合所提供的通常不够灵活的方法形成了鲜明的对比。 通过权衡一些实现复杂性,我们能够在不影响正确性的情况下找到必要的效率平衡。 此外,该管道还强调了状态和计时器提供的更为急切的流处理方法(请考虑使用C或Java),这是对窗口和触发器提供的更具功能性的方法(例如Haskell)的很好的补充。
概括
在本章中,我们仔细研究了持久状态为何如此重要,得出的结论是,持久状态为长期使用的管道的正确性和效率提供了基础。然后,我们研究了数据处理系统中两种最常见的隐式状态类型:原始分组和增量组合。我们了解到,原始分组很简单,但可能效率很低,渐进式组合极大地提高了可交换和关联操作的效率。最后,我们看了一个基于实际经验的相对复杂但非常实用的用例(以及通过Apache Beam Java的实现),并用它来强调一般状态抽象所需的重要特征:
- 数据结构的灵活性,允许使用针对手头特定用例量身定制的数据类型。
- 写入和读取粒度的灵活性,允许在任何时候根据使用情况量身定制写入和读取的数据量,并酌情最小化或最大化I / O。
- 处理调度的灵活性,允许将处理的某些部分延迟到更合适的时间点,例如,当输入被认为是在事件时间的特定点完成时。

若有收获,就点个赞吧
0 人点赞
