再一次问好! 希望您像我一样喜欢第3章。水印是一个引人入胜的话题,Slava比地球上的任何人都对水印了解得更多。现在,我们对水印有了更深入的了解,我想深入探讨一些与什么,在哪里,何时以及如何提出问题有关的高级话题。
我们首先看一下处理时间窗口化,它是在何时何地的有趣组合,以便更好地了解它与事件时间窗口化的关系,并了解何时才是正确的方法。然后,我们深入探讨一些更高级的事件时间窗口概念,详细研究会话窗口,最后通过探索三种不同类型的自定义获胜窗口,来说明为什么通用自定义窗口是有用的(且令人惊讶的是简单明了)的概念。dows:未对齐的固定窗口,每键固定窗口和有界会话窗口。
时间/地点:处理时间窗口
处理时间开窗很重要,原因有两个:
- 对于某些使用情况(例如使用情况监视(例如,Web服务流量QPS)),您想要对其分析观察到的输入数据流,则处理时间窗口绝对是采取的适当方法。
- 对于事件发生时间很重要的用例(例如,分析用户行为趋势,计费,评分等),处理时间窗口化绝对是错误的方法,并且能够识别这些情况 至关重要。
因此,有必要深入了解处理时间窗口和事件时间窗口之间的区别,特别是考虑到当今许多流系统中普遍存在处理时间窗口的情况。
当在一个模型中使用窗口作为一等概念的模型严格基于事件时间时,例如在本书中介绍的模型时,可以使用两种方法来实现处理时间窗口化:
触发器
忽略事件时间(即使用跨所有事件时间的全局窗口),并使用触发器在处理时间轴上提供该窗口的快照。
进入时间
将进入时间指定为数据到达时的事件时间,然后使用正常的事件时间窗口。本质上,这就是Spark Streaming 1.x的功能。
请注意,尽管这两种方法在多级管道中略有不同,但它们在某种程度上是等效的:在触发器版本中,多级管道将在每个阶段独立地分割处理时间“窗口”,因此,例如,数据在阶段N的窗口中,可能会在接下来的阶段结束在N-1或N + 1窗口中;在进入时间版本中,将数据合并到窗口N中后,由于阶段之间通过水印(在Cloud Dataflow情况下),微批处理边界(在火花流情况),或在引擎级别涉及其他任何协调因素。
正如我已经指出的那样,处理时间窗口化的一大缺点是,当输入的观察顺序改变时,窗口的内容也会改变。为了更具体地说明这一点,我们将研究以下三个用例:事件时间窗口,通过触发器的处理时间窗口以及通过入口时间的处理时间窗口。
每个都将应用于两个不同的输入集(因此共有六个变体)。这两个输入集将用于完全相同的事件(即,在相同事件时间发生的相同值),但具有不同的观察顺序。第一组是我们一直看到的观测顺序,颜色为白色;第二个值将使所有值在处理时间轴上移动,如图4-1所示,颜色为紫色。您可以简单地想象紫色的例子是如果风从东方吹来而不是从西方吹来,那就是现实发生的另一种方式(即底层复杂的分布式系统以稍微不同的顺序播放事物)。
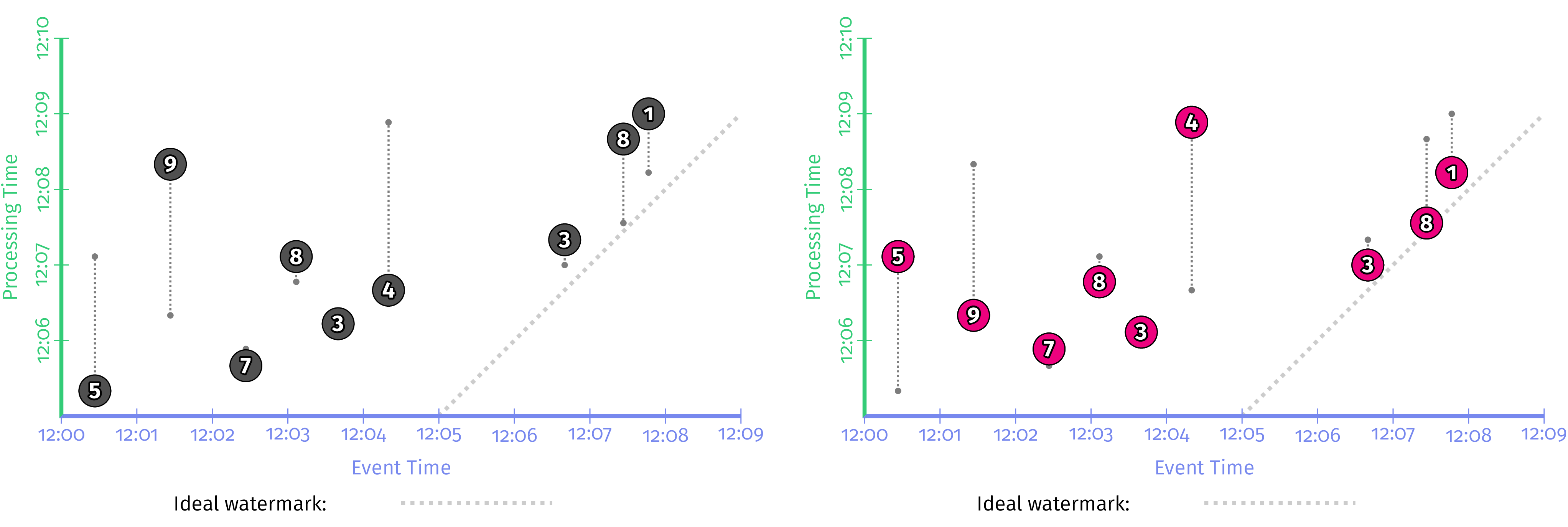
图4-1 在处理时间,保持值和事件时间不变的情况下改变输入观察顺序
事件时间窗口
为了建立基线,我们首先将事件时间中的固定窗口与这两个观察顺序上的启发式水印进行比较。我们将重用示例2-7 /图2-10中的早期/晚期代码,以得到如图4-2所示的结果。从本质上讲,左侧是我们之前看到的。右侧是第二个观察顺序的结果。这里要注意的重要一点是,即使输出的整体形状有所不同(由于处理时间的观察顺序不同),四个窗口的最终结果仍保持不变:14、18、3和12。
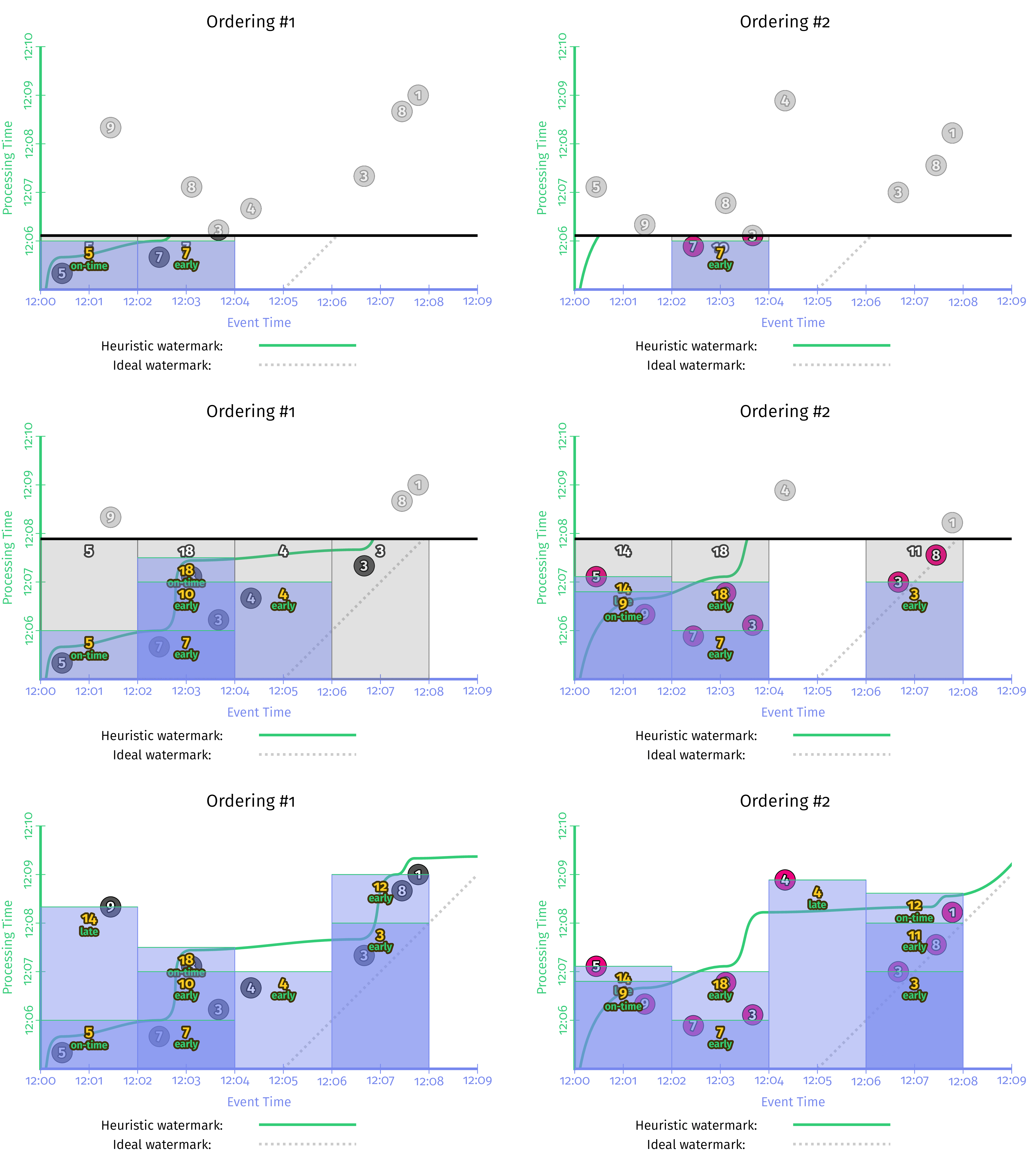
图4-2 在相同输入的两个不同处理时间顺序上的事件时间窗口
通过触发器处理时间窗口化
现在,将其与上述两种处理时间方法进行比较。首先,我们将尝试使用触发器方法。以这种方式使处理时间的“窗口”工作包含三个方面:
加窗
我们之所以使用全局事件时间窗口,是因为我们实际上是在使用事件时间窗格来模拟处理时间窗口。
触发方式
我们根据所需的处理时间窗口大小在处理时间域中定期触发。
积累
我们使用丢弃模式来使窗格彼此独立,从而使每个窗格都像一个独立的处理时间“窗口”。
相应的代码类似于示例4-1; 请注意,全局窗口化是Beam中的默认设置,因此没有特定的窗口化策略替代。
示例4-1 通过全局事件时间窗口的重复,丢弃窗格来处理时间窗口
PCollection<KV<Team, Integer>> totals = input.apply(Window.triggering(Repeatedly(AlignedDelay(ONE_MINUTE))).discardingFiredPanes()).apply(Sum.integersPerKey());
在针对我们的输入数据的两个不同顺序在流式运行程序上执行时,结果如图4-3所示。以下是有关此图的一些有趣注释:
- 因为我们是通过事件时间窗格来模拟处理时间窗口,所以“窗口”在处理时间轴上画出了轮廓,这意味着它们的有效宽度是在y轴而不是x轴上测量的。
- 因为处理时间开窗对遇到输入数据的顺序很敏感,所以即使两个版本的事件本身在技术上都在同一时间发生,但两个观察顺序的每个“窗口”的结果也有所不同。左边是12、18、18,右边是7、36、5。
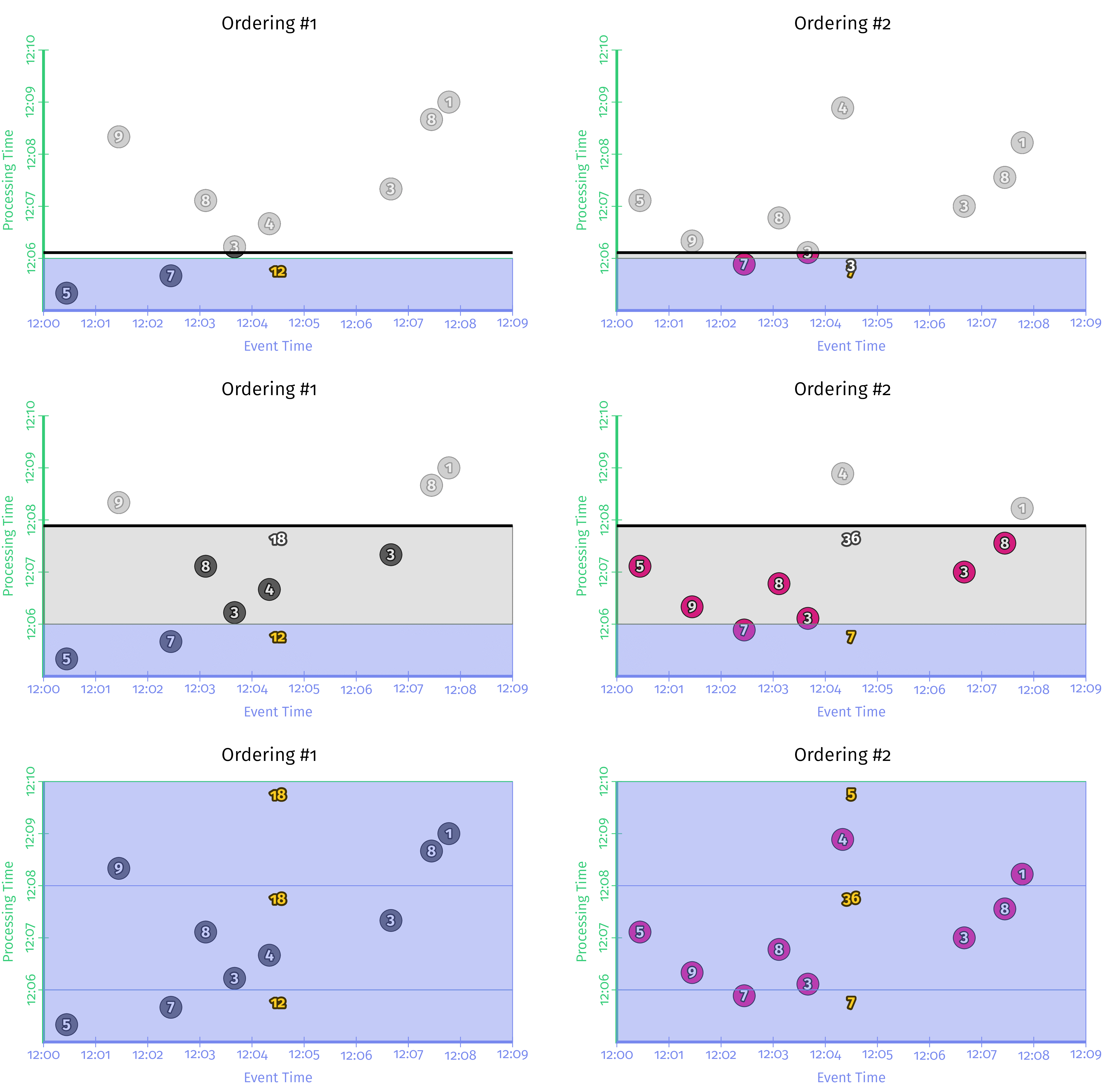
图4-3 通过触发器,在相同输入的两个不同处理时间顺序上,通过处理“窗口化”
通过入口时间进行处理时窗口化
最后,让我们看一下通过将输入数据的事件时间映射为其输入时间来实现的处理时间窗口化。在代码方面,这里我们可以通过提供一个新的DoFn在Beam中进行此操作,该DoFn通过outputWithTimestamp方法将元素的时间戳设置为当前时间。
加窗
返回到使用标准事件时间固定窗口。
触发方式
因为进入时间提供了计算完美水印的能力,所以我们可以使用默认触发器,在这种情况下,当水印通过窗口末端时,它会隐式触发一次。
累积模式因为每个窗口只有一个输出,所以累积模式无关紧要。
因此,实际代码可能类似于示例4-2。
示例4-2 通过全局事件时间窗口的重复,丢弃窗格来处理时间窗口
PCollection<String> raw = IO.read().apply(ParDo.of(new DoFn<String, String>() {public void processElement(ProcessContext c) {c.outputWithTimestmap(new Instant());}});PCollection<KV<Team, Integer>> input =raw.apply(ParDo.of(new ParseFn());PCollection<KV<Team, Integer>> totals = input.apply(Window.info(FixedWindows.of(TWO_MINUTES)).apply(Sum.integersPerKey());
流引擎上的执行类似于图4-4。当数据到达时,它们的事件时间被更新以匹配它们的进入时间(即,到达时的处理时间),导致向右水平移动到理想水印线上。以下是有关此图的一些有趣注释:
与其他处理时间窗口化示例一样,即使输入的值和事件时间保持不变,但当输入的顺序更改时,我们也会得到不同的结果。
- 与其他示例不同,在事件时间域中(因此沿x轴)再次描绘了窗口。尽管如此,它们并不是真正的事件时间窗口;我们只需将处理时间映射到事件时域上,就可以删除每个输入的原始发生记录,并用新记录代替它,该新记录代表管道首次观察到数据的时间。
- 尽管如此,由于有了水印,触发器触发仍然与上一个处理时间示例中的时间完全相同。此外,所产生的输出值与该示例相同,如预测的那样:左侧为12、18、18,右侧为7、36、5。
- 因为在使用进入时间时可以使用完美的水印,所以实际水印与理想水印相匹配,并以1的斜率向上和向右升。

图4-4 在相同输入的两个不同处理时间排序上,通过使用进入时间来处理时间窗口
虽然有趣的是,您可以看到实现处理时间窗口的不同方法,但这里最大的收获是自第一章以来我一直在努力:事件时间窗口是不可知的,至少在一定程度上是(实际的) 在输入完成之前,沿途窗格可能会有所不同); 处理时间窗口化不是。如果您关心事件实际发生的时间,则必须使用事件时间窗口,否则结果将毫无意义。我现在就下车。
地点:会话窗口
处理时间窗口化足够了。现在让我们回到久经考验的事件时间窗口,但是现在我们来看一下我最喜欢的功能之一:称为会话的动态数据驱动窗口。
会话是一种特殊类型的窗口,可捕获数据中的活动周期,该活动周期由不活动的间隙终止。它们在数据分析中特别有用,因为它们可以提供特定用户在特定时间段内从事某些活动的活动视图。这允许会话内活动的相关性,根据会话的时间得出关于参与程度的推论,等等。
从窗口的角度来看,会议有两种特别有趣的方式:
- 它们是数据驱动窗口的一个示例:窗口的位置和大小是输入数据本身的直接结果,而不是像固定窗口和滑动窗口那样基于时间上的某些预定义模式。
- 它们也是未对齐窗口的示例; 也就是说,一个窗口不会在数据中统一应用,而是仅应用于数据的特定子集(例如,每个用户)。这与诸如固定窗口和滑动窗口之类的对齐窗口相反,后者通常在数据上均匀地应用。
在某些用例中,可以提前在一个会话中使用通用标识符标记数据(例如,视频播放器发出带有服务质量信息的心跳ping;对于任何给定的观看,所有ping都可以标记提前使用单个会话ID)。在这种情况下,会话更容易构建
因为它基本上只是一种按键分组的形式。
但是,在更一般的情况下(即,实际会话本身事先未知),必须仅在一段时间内从数据位置构造会话。当处理乱序数据时,这变得特别棘手。
图4-5显示了一个示例,其中五个独立的记录被分组到会话窗口中,间隔超时为60分钟。每条记录都在其自身的60分钟窗口(原始会话)中开始。将重叠的协议合并在一起会产生两个较大的会话窗口,分别包含三个和两个记录。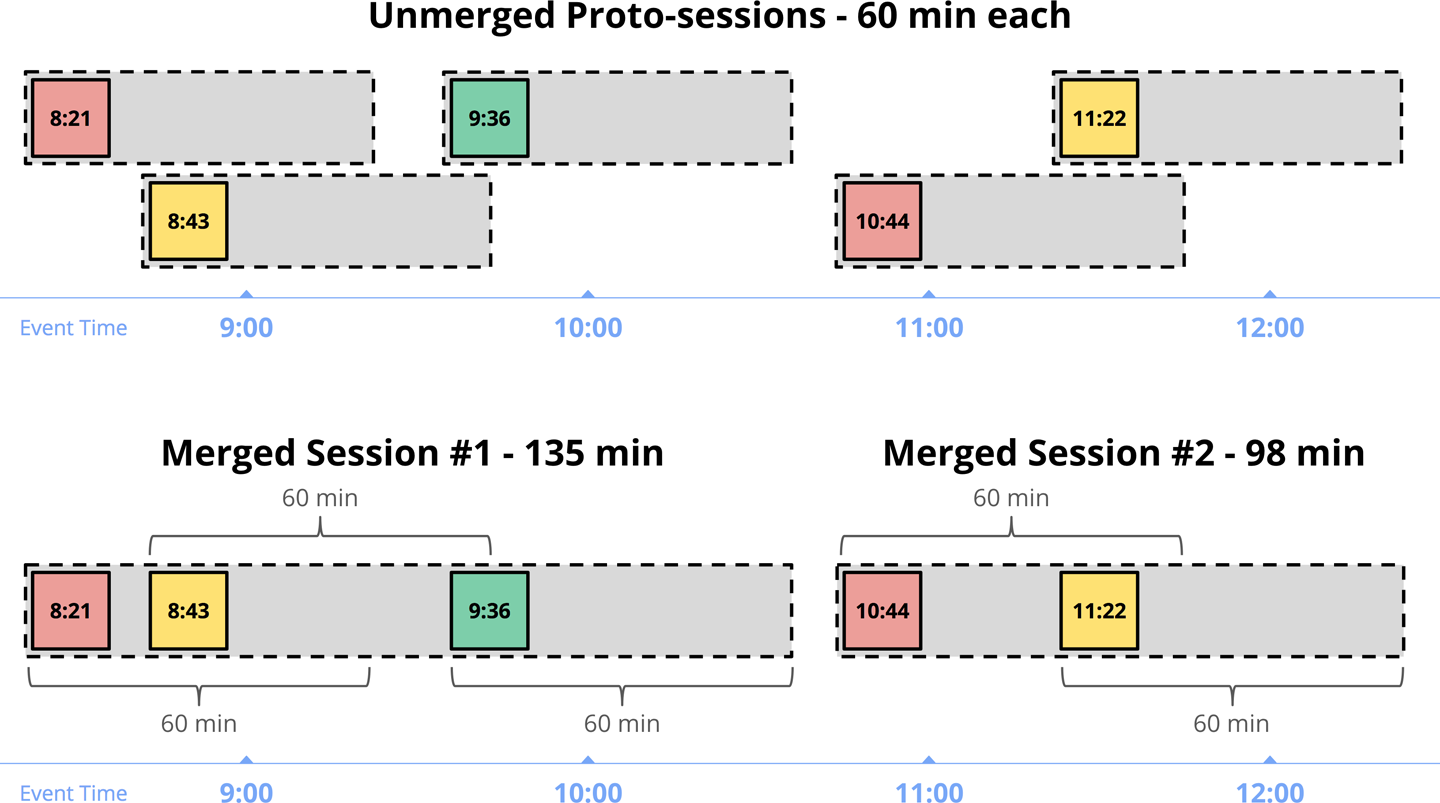
图4-5 未合并的原始会话窗口以及由此产生的合并会话
他们提供一般会话支持的关键见解是,按照定义,一个完整的会话窗口是一组较小的重叠窗口的组合,每个窗口包含一个记录,每个记录中的每个记录与下一个如果我们将会话超时指定为一分钟,那么我们将期望在数据中识别出两个会话,在图4-6中用黑色虚线表示。这些会话中的每个会话都会捕获来自用户的突发事件,会话中的每个事件与会话中至少一个其他事件的间隔不到一分钟。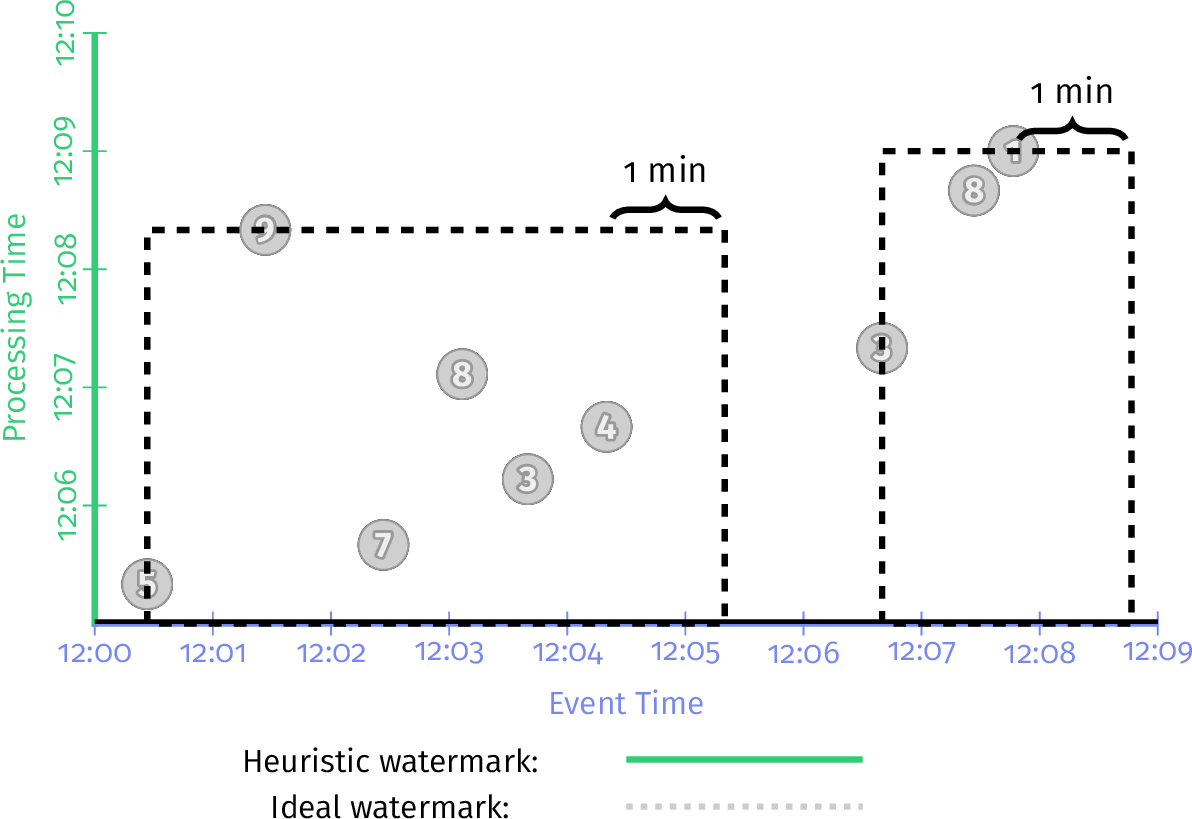
图4-6 我们要计算的会话
要了解随着事件的发生,窗口合并如何随着时间的推移建立这些会话,让我们来看一下实际情况。我们将使用示例2-10中启用撤回功能的早/晚代码,并更新窗口以建立具有一分钟间隔时间超时的会话。例4-3说明了它的外观。
示例4-3 提前/准时/延迟触发会话窗口和撤回
PCollection<KV<Team, Integer>> totals = input.apply(Window.into(Sessions.withGapDuration(ONE_MINUTE)).triggering(AfterWatermark().withEarlyFirings(AlignedDelay(ONE_MINUTE)).withLateFirings(AfterCount(1)))).apply(Sum.integersPerKey());
在流引擎上执行,您将得到如图4-7所示的内容(请注意,我已经在黑色虚线中留下了注释,表示预期的最终会话供参考)。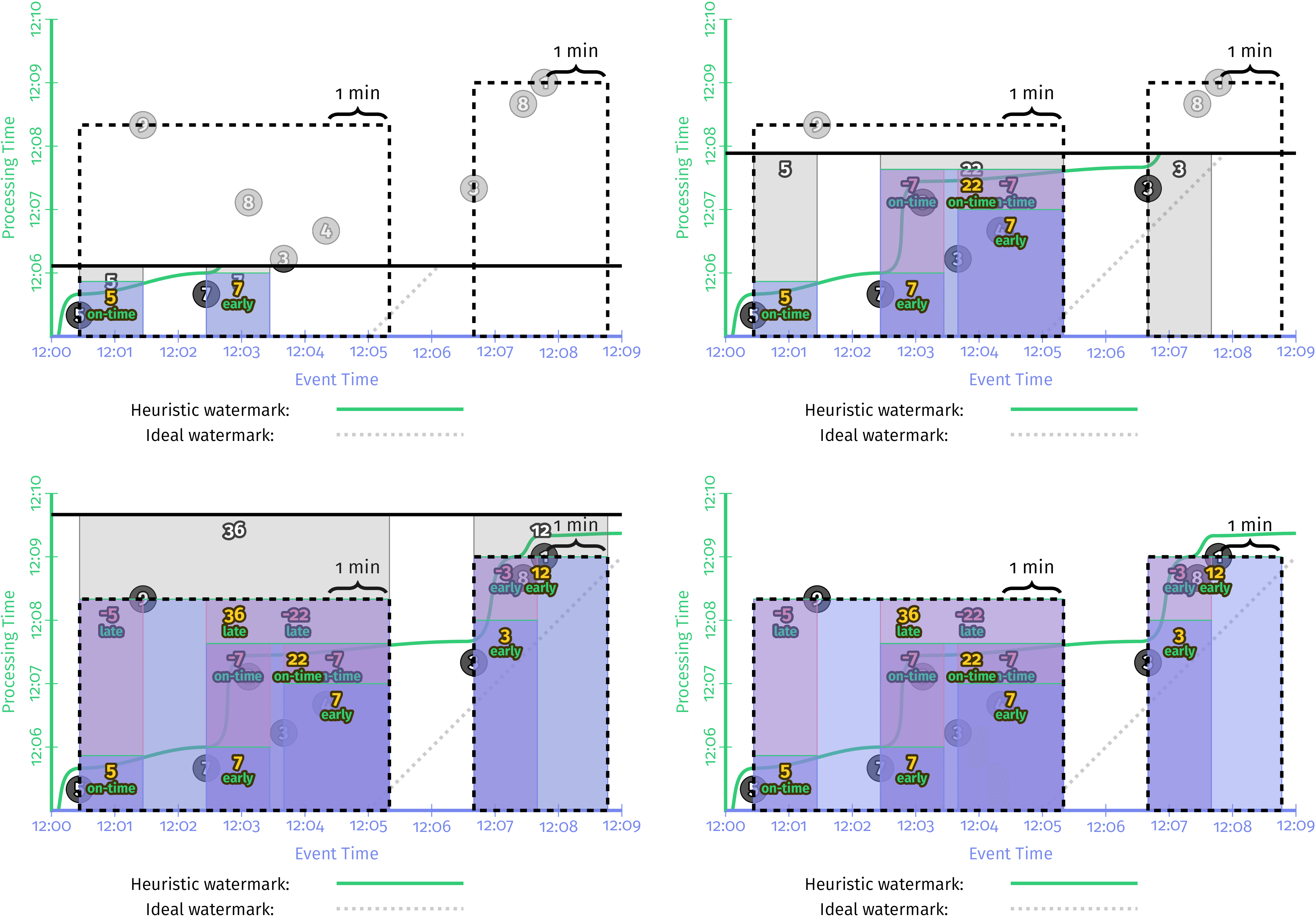
图4-7 会话窗口的早期和晚期触发以及流引擎上的撤回
这里有很多事情,所以我将引导您完成其中的一些工作:
- 遇到第一个值为5的记录时,会将其放在一个protosession窗口中,该窗口从该记录的事件时间开始,并跨越会话间隔持续时间的宽度;例如,在该基准点之后的一分钟。我们将来遇到的任何与该窗口重叠的窗口都应该是同一会话的一部分,因此将被合并到该会话中。
- 到达的第二个记录是7,由于它与5的窗口不重叠,因此类似地放置在其自己的protosession窗口中。
- 同时,水印已通过第一个窗口的末尾,因此值5会作为准时结果在12:06之前实现。此后不久,恰好在处理时间达到12:06时,第二个窗口也作为值为7的推测结果出现。
- 接下来,我们观察一对记录3和4,它们的原始会话重叠。结果,它们合并在一起,并且在12:07的早期触发器触发时,将发射一个值为7的单个窗口。
- 当8不久之后到达时,它与两个具有值7的窗口重叠。因此,所有三个窗口合并在一起,形成一个具有值22的新组合会话。当水印通过该会话的末尾时,它将实现两个值22的新会话,以及先前发出但后来并入其中的值7的两个窗口的撤回。
- 当9到达较晚时,会发生类似的舞蹈,将具有值5的原型会话和具有值22的会话加入到较大的值36的单个会话中。36以及5和22窗口的缩回都由窗口立即发出。延迟数据触发。
这是一些非常强大的功能。真正令人敬畏的是,在一个模型中描述这样的东西是多么容易,它可以将流处理的维度分解为不同的,可组合的部分。最后,您可以将更多的精力放在手头有趣的业务逻辑上,而不是将数据整形为某种可用形式的细节。
如果您不相信我,请查看此博客文章,描述如何在Spark Streaming 1.x上手动建立会话(请注意,这样做并不是为了让他们指指点点; Spark伙计们在此方面做得很好 别人实际上不愿去麻烦的所有其他事情,即记录下在Spark 1.x上构建特定的各种会话支持所需的内容;对于大多数其他系统,您不能说相同的话)。它涉及很多,他们甚至没有进行适当的事件时间会议,也没有提供投机或延迟解雇或撤退。
地点:自定义窗口
到目前为止,我们主要讨论了预定义的窗口策略类型:固定,滑动和会话。您可以从标准类型的窗口中获得很多收益,但是在现实世界中,有很多用例能够定义自定义窗口策略可以真正节省一天的时间(现在我们将看到其中的三种) )。
如今,大多数系统不支持Beam所支持的自定义窗口,因此我们着重于Beam方法。在Beam中,自定义窗口化策略包括两件事:
窗口分配
这会将每个元素放入初始窗口。在极限情况下,这允许将每个元素放置在一个非常强大的唯一窗口中。
(可选)窗口合并
这允许窗口在分组时进行合并,从而使窗口有可能随着时间的推移而演变,这是我们之前在会话窗口中看到的。
为了让您了解真正的简单窗口策略以及自定义窗口支持的实用性,我们将详细介绍Beam中固定窗口和会话的常规实现,然后考虑一些实际的用例 需要在这些主题上自定义变体。在此过程中,我们将看到创建自定义窗口策略非常容易,并且当您的用例不太适合现有方法时,如何限制缺少自定义窗口支持也可以。
固定窗口上的变化
首先,让我们看一下固定窗口的相对简单的策略。库存的fixedwindows实现非常简单,它包含以下逻辑:
分配
根据元素的时间戳以及窗口的大小和偏移量参数,将元素放置在适当的固定窗口中。
合并中
没有。
该代码的缩写形式类似于示例4-4。
示例4-4 简化的FixedWindows实现。
public class FixedWindows extends WindowFn<Object, IntervalWindow> {private final Duration size;private final Duration offset;public Collection<IntervalWindow> assignWindow(AssignContext c) {long start = c.timestamp().getMillis() - c.timestamp().plus(size).minus(offset).getMillis() % size.getMillis();return Arrays.asList(IntervalWindow(new Instant(start), size));}}
请记住,此处向您展示代码的目的并不是要教您如何编写窗口策略(尽管对它们进行神秘化处理并指出它们的简单程度很好)。这确实是要帮助对比支持某些相对基本的用例(分别带有和不带有自定义窗口)的相对容易程度和难度。让我们考虑两个这样的用例,它们现在是fixedwindows主题的变体。
未对齐的固定窗口
我们之前提到的默认固定窗口实现的一个特征是,窗口在所有数据上对齐。在我们的运行示例中,任何给定团队从中午到下午1点的窗口都与所有其他团队的相应窗口对齐,该窗口也从中午延伸到下午1点。在要比较的用例中,例如跨另一个维度的窗口(例如,团队之间),这种对齐方式非常有用。但是,它付出了微妙的代价。从正午到下午1点的所有活动窗口几乎都在同一时间完成,这意味着每小时一次,系统将遭受巨大的负载以实现。
要了解我的意思,我们来看一个具体示例(示例4-5)。首先,我们将在大多数示例中使用分数总和管道,其中包括固定的两分钟窗口和单个水印触发器。
示例4-5 水印完整性触发(与示例2-6相同)
PCollection<KV<Team, Integer>> totals = input.apply(Window.into(FixedWindows.of(TWO_MINUTES)).triggering(AfterWatermark())).apply(Sum.integersPerKey());
但是在这种情况下,我们将并行查看来自同一数据集的两个不同的键(参见图4-8)。我们将看到,由于窗口在所有键上都对齐,因此这两个键的输出都已对齐。结果,每次水印通过窗口的末尾时,我们最终会出现N个窗格,其中N是该窗口中具有更新的键的数量。在此示例中,N为2时,可能不会太痛苦。但是,当N开始以数千,数百万甚至更多的顺序进行排序时,同步的突发性可能会成为问题。
图4-8 对齐的固定窗口
在不需要跨窗口比较的情况下,通常更希望在整个时间范围内平均分配窗口完成负载。这使系统负载更可预测,从而可以减少处理高峰负载的配置要求。但是,在大多数系统中,未对齐的固定窗口仅在系统提供开箱即用的支持时才可用。但是有了customwindowing支持,它对默认的固定窗口实现进行了相对微不足道的修改,以提供不固定的固定窗口支持。我们要做的是继续保证分组在一起的所有元素的窗口(即,具有相同键的窗口)具有相同的对齐方式,同时放宽了跨不同键的对齐限制。该代码将更改为默认的固定窗口策略,外观类似于示例4-6。
示例4-6 缩写UnalignedFixedWindows实现
public class UnalignedFixedWindowsextends WindowFn<KV<K, V>, IntervalWindow> {private final Duration size;private final Duration offset;public Collection<IntervalWindow> assignWindow(AssignContext c) {long perKeyShift = hash(c.element().key()) % size;long start = perKeyShift + c.timestamp().getMillis()- c.timestamp().plus(size).minus(offset)return Arrays.asList(IntervalWindow(new Instant(start), size));}}
进行此更改后,具有相同键的所有元素的窗口将对齐,但是具有(不同)键的元素的窗口将(通常)未对齐,因此分散窗口完成负载的代价是使跨键的比较也没有那么有意义。我们可以切换管道以使用示例4-7中所示的新的窗口化策略。
示例4-7 带有单个水印触发器的未对齐固定窗口
PCollection<KV<Team, Integer>> totals = input.apply(Window.into(UnalignedFixedWindows.of(TWO_MINUTES)).triggering(AfterWatermark())).apply(Sum.integersPerKey());
然后,通过像以前一样比较同一数据集上的不同固定窗口对齐方式,可以看到图4-9的样子(在这种情况下,我选择了两种对齐方式之间的最大相移,以最清楚地说明其优势, 假设跨大量密钥随机选择的阶段会产生类似的效果)。

图4-9 未对齐的固定窗口
请注意,在任何情况下我们都不会同时为多个键发出多个窗格。相反,窗格分别以更均匀的节奏到达。这是在用例允许的情况下,能够在一个维度上进行权衡(在键之间进行比较的能力)以换取另一维度上的收益(减少峰值资源配置需求)的另一个示例。当您尝试尽可能高效地处理大量数据时,这种灵活性至关重要。
现在,让我们看一下固定窗口上的第二种变化,这种变化本质上与正在处理的数据有关。
每个元素/键的固定窗口
我们的第二个示例来自Cloud Dataflow的早期采用者之一。该公司为其客户生成分析数据,但允许每个客户配置要汇总其指标的窗口大小。换句话说,每个客户都可以定义其固定窗口的特定大小。
只要可用的窗口尺寸本身是固定的,支持这样的用例就不太困难。例如,您可以想象提供一个选项,选择30分钟,60分钟和90分钟的固定窗口,然后为每个选项运行一个单独的管道(或管道的分支)。不理想,但也不是太可怕。但是,随着选项数量的增加,这很快变得很棘手,并且在为真正的任意窗口大小(这是该客户的用例要求)提供支持的限制内,这是完全不切实际的。
幸运的是,由于每条记录都已经用描述元数据所需的用于聚合的窗口大小的元数据注释客户流程,因此支持每用户固定的固定窗口大小就像从固定窗口的固定更改几行一样简单,例如 在示例4-8中进行了演示。
示例4-8 修改(并缩写)的FixedWindows实现,支持每个元素的窗口大小
public class PerElementFixedWindows<T extends HasWindowSize%gt;extends WindowFn<T, IntervalWindow> {private final Duration offset;public Collection<IntervalWindow> assignWindow(AssignContext c) {long perElementSize = c.element().getWindowSize();long start = perKeyShift + c.timestamp().getMillis()- c.timestamp().plus(size).minus(offset).getMillis() % size.getMillis();return Arrays.asList(IntervalWindow(new Instant(start), perElementSize));}}
进行此更改后,每个元素都将分配给具有适当大小的固定窗口,这取决于元素本身中携带的元数据。如示例4-9所示,更改管道代码以使用此新策略也很容易。
示例4-9 每个元素具有单个水印触发器的固定窗口大小
PCollection<KV<Team, Integer>> totals = input.apply(Window.into(PerElementFixedWindows.of(TWO_MINUTES)).triggering(AfterWatermark())).apply(Sum.integersPerKey());
然后查看运行中的这个管道(图4-10),可以很容易地看到,密钥A的元素的窗口大小均为2分钟,而密钥B的元素的窗口大小为一分钟。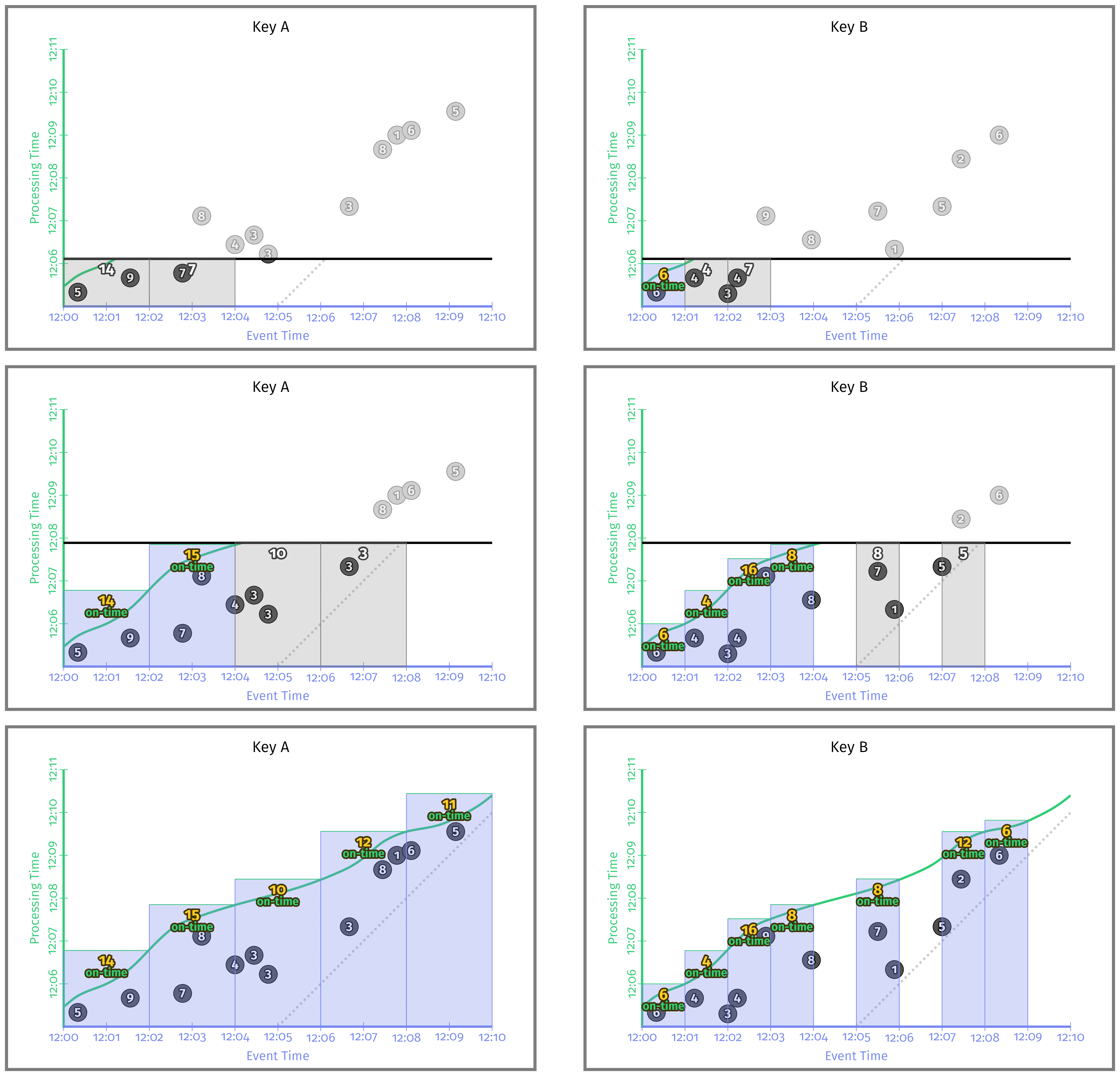
图4-10 每键自定义大小的固定窗口
实际上,您绝对不会期望系统为您提供这种服务; 存储窗口大小首选项的性质太特殊了用例,以至于无法尝试构建到标准API中。但是,正如该客户的需求所表明的那样,确实存在这样的用例。这就是自定义窗口提供如此强大的灵活性的原因。
会话窗口的变体
为了真正了解自定义窗口的实用性,让我们看一个最后的示例,它是会话的一种变体。可以理解,会话窗口比固定窗口要复杂一些。它的实现包括以下内容:
分配
每个元素最初都放置在proto-session窗口中,该窗口从元素的时间戳开始,并持续间隔时间。
合并中
在分组时,将对所有符合条件的窗口进行排序,然后将所有重叠的窗口合并在一起。
会话代码的缩写版本(由多个帮助程序类手动合并在一起)看起来类似于示例4-10中所示。
示例4-10 简短会话的实施
public class Sessions extends WindowFn<Object, IntervalWindow> {private final Duration gapDuration;public Collection<IntervalWindow> assignWindows(AssignContext c) {return Arrays.asList(new IntervalWindow(c.timestamp(), gapDuration));}public void mergeWindows(MergeContext c) throws Exception {List<IntervalWindow> sortedWindows = new ArrayList<>();for (IntervalWindow window : c.windows()) {sortedWindows.add(window);}Collections.sort(sortedWindows);List<MergeCandidate> merges = new ArrayList<>();MergeCandidate current = new MergeCandidate();for (IntervalWindow window : sortedWindows) {if (current.intersects(window)) {current.add(window);} else {merges.add(current);current = new MergeCandidate(window);}}merges.add(current);for (MergeCandidate merge : merges) {merge.apply(c);}}}
和以前一样,看代码的目的并不是要教您如何实现自定义窗口功能,甚至不是会话的实现。的确表明您可以通过自定义窗口轻松支持新用途。
有界会话
我多次遇到的一个这样的自定义用例是有界会话:在时间,元素数或其他方面,不允许增长超过一定大小的会话。这可能是出于语义原因,也可能只是垃圾邮件防护中的一种做法。但是,鉴于限制类型的变化(某些用例关注事件时间的总会话大小,某些关注元素的总数,某些关注元素的密度等),很难为边界提供清晰简洁的API 会议。更实际的是允许用户实现针对其特定用例的自定义窗口逻辑。会话窗口是有时间限制的一个此类用例的示例可能类似于示例4-11(省略了一些我们将在此处使用的构建器样板)。
示例4-11 简短会话的实施
public class BoundedSessions extends WindowFn<Object, IntervalWindow> {private final Duration gapDuration;private final Duration maxSize;public Collection<IntervalWindow> assignWindows(AssignContext c) {return Arrays.asList(new IntervalWindow(c.timestamp(), gapDuration));}private Duration windowSize(IntervalWindow window) {return window == null? new Duration(0): new Duration(window.start(), window.end());}public static void mergeWindows(WindowFn<?, IntervalWindow>.MergeContext c) throws Exception {List<IntervalWindow> sortedWindows = new ArrayList<>();for (IntervalWindow window : c.windows()) {sortedWindows.add(window);}Collections.sort(sortedWindows);List<MergeCandidate> merges = new ArrayList<>();MergeCandidate current = new MergeCandidate();for (IntervalWindow window : sortedWindows) {MergeCandidate next = new MergeCandidate(window);if (current.intersects(window)) {current.add(window);if (windowSize(current.union) <= (maxSize - gapDuration))continue;// Current window exceeds bounds, so flush and move to nextnext = new MergeCandidate();}merges.add(current);current = next;}merges.add(current);for (MergeCandidate merge : merges) {merge.apply(c);}}}
与往常一样,使用示例自定义窗口更新策略来更新管道(在本例中为例2-7)是较早/较早/较晚的版本,如例4-12所示。
示例4-12 通过早期/及时/后期API提前,按时和延迟触发
PCollection<KV<Team, Integer>> totals = input.apply(Window.into(BoundedSessions.withGapDuration(ONE_MINUTE).withMaxSize(THREE_MINUTES)).triggering(AfterWatermark().withEarlyFirings(AlignedDelay(ONE_MINUTE)).withLateFirings(AfterCount(1)))).apply(Sum.integersPerKey());
并在我们正在运行的示例中执行,则它可能类似于图4-11。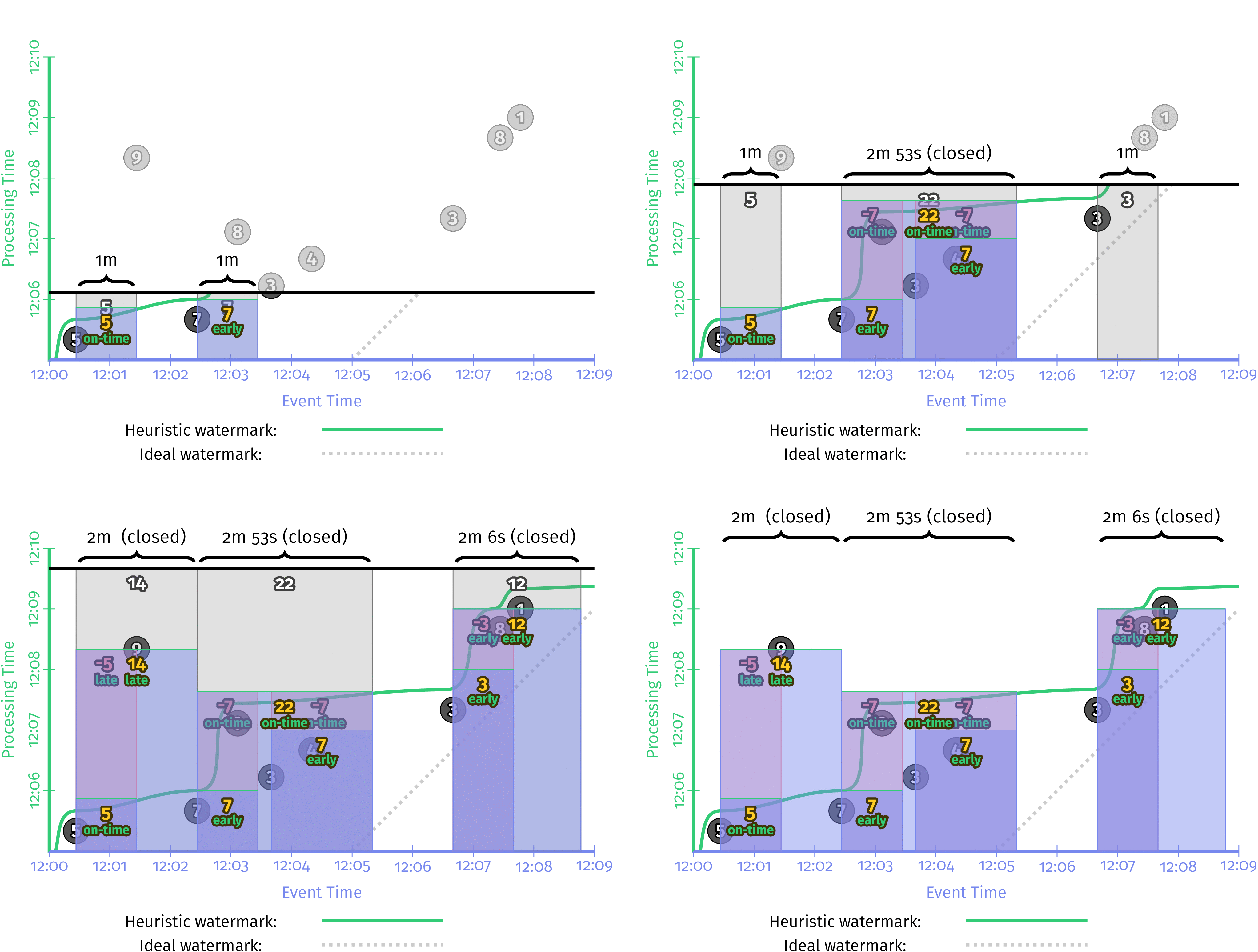
图4-11 会话窗口长度为三分钟
请注意,在图2-7的无限制会话实现中,具有值为36的大型会话跨越了[12:00.26,12:05.20)或将近五分钟的时间,现在如何分解为两个较短的会话,长度为2分钟2分53秒
鉴于当今很少有系统提供自定义窗口支持,值得指出的是,使用仅支持无限制会话实现的系统来实现这种事情需要花费更多的精力。您唯一真正的求助方法是在会话分组逻辑的下游编写代码,该代码查看生成的会话,并在超出长度限制时将其切碎。这将需要在事后分解会话的能力,这将消除增量聚合的好处(我们将在第7章中详细介绍),从而增加了成本。这也将消除人们可能希望通过限制会话时长而获得的任何垃圾邮件保护优势,因为会话在被切断或截断之前首先需要增长到其完整大小。
一种尺寸并不适合所有人
现在,我们研究了三个实际用例,每个用例都是数据处理系统通常提供的窗口存储类型的细微变化:未对齐的固定窗口,每个元素的固定窗口和有界会话。在这三种情况下,我们都知道通过自定义窗口支持这些用例非常简单,而没有它来支持这些用例将变得更加困难(或昂贵)。尽管自定义窗口尚未获得整个行业的广泛支持,但它的功能为构建需要处理尽可能多的数据的复杂,真实世界的用例的数据处理管道时,在平衡取舍之间提供了迫切需要的灵活性。可能。
概要
高级窗口化是一个复杂而多样的主题。在本章中,我们涵盖了三个高级概念:
处理时间窗口
我们了解了事件时间窗口化与事件时间窗口化之间的关系,指出了事件时间窗固有的作用,最重要的是,通过突出显示事件时间窗提供给我们的结果的稳定性来识别那些地方没有。
会话窗口
我们首次介绍了合并窗口策略的动态类,并了解了系统在提供如此强大的结构以使您可以轻松放置到位方面对我们来说有多大的负担。
自订视窗
在这里,我们看了三个定制窗口的现实世界示例,这些示例在仅提供一组静态股票开窗策略但在具有定制窗口支持的系统中实现起来相对比较琐碎的系统中很难或不可能实现:
- 未对齐的固定窗口,当将水印触发器与固定窗口结合使用时,可在一段时间内提供更均匀的输出分布。
- 每个元素的固定窗口,可灵活地动态选择每个元素的固定窗口的大小(例如,提供可自定义的每个用户或每个广告系列的窗口大小),以更好地定制使用的管道语义手头的情况。
- 会话限制窗口,限制给定会话的增长量;例如,为了抵消垃圾邮件的尝试或对管道实现的已完成会话的延迟设置限制。
在与Slava深入探讨了第3章中的水印并在此处对高级窗口进行了广泛调查之后,我们现在已经远远超出了在多个维度上进行可靠的流处理的基础。到此,我们结束了对梁模型的关注,并因此完成了本书的第一部分。接下来是Reuven关于一致性保证,一次处理和副作用的第5章,之后我们从第6章开始进入第二部分,流和表。

若有收获,就点个赞吧
0 人点赞
