您现在已经到达了本书的最后一章,您坚忍的识字了,您。您的旅程即将完成!
总结一下,我希望您能与我一起简短地回顾历史,从使用MapReduce进行大规模数据处理的古老时代开始,然后回顾随后十年半中的一些重要事件。将流媒体系统带到了今天。这是一本相对轻量级的章节,在其中我对一些知名系统(以及一些可能不太知名的系统)的重要贡献进行了一些观察,并向您推荐了一些您可以阅读的参考资料。您想自己了解更多,而同时又不试图冒犯或激怒负责那些真正具有影响力的系统的人,为了空间,重点和凝聚力的叙述,我将过度简化或完全忽略。应该是个好时机。
关于这一点,请记住,在阅读本章时,我们实际上只是在这里谈论大规模数据处理的MapReduce / Hadoop族谱的特定部分。我不会以任何形式或形式覆盖SQL领域;我们不是在谈论HPC /超级计算机,等等。因此,正如本章的标题听起来可能广泛而广泛,我确实专注于大规模数据处理的整体领域的特定垂直范围。请注意文人,以及所有这些。
另请注意,我在这里介绍了不成比例的Google技术。您可能以为这可能与我在Google工作了十多年有关。但是,还有其他两个原因:1)大数据对Google一直很重要,因此在那里产生了许多有价值的贡献,值得详细讨论;2)我的经验是,Google以外的人通常似乎喜欢学习更多关于我们已完成的工作的信息,因为我们作为一家公司在历史上一直对此保持沉默。因此,当我专心致志地讲解我们一直在秘密关门工作的东西时,请让我沉迷一些。
为了使旅行遵循具体的时间顺序,我们将遵循图10-1中的时间表,该时间表显示了我所讨论的各种系统的大致存在日期。
图10-1 本章讨论的系统的大致时间表
在每个站点,我都会尽可能简要地介绍该系统的历史,并从塑造我们今天所知道的流式系统的角度来阐述其贡献。最后,我们对所有贡献进行了总结,以了解它们如何总结,共同创建了当今的现代流处理生态系统。
MapReduce
我们从MapReduce(图10-2)开始旅程。
图10-2 时间轴:MapReduce
我认为可以肯定地说,今天众所周知的大规模数据处理是从2003年的MapReduce开始的。当时,Google的工程师正在构建各种定制系统,以应对大规模的数据处理挑战万维网。当他们这样做时,他们注意到三件事:
数据处理困难
正如我们中的数据科学家和工程师所熟知的,您可以专注于从原始数据中提取有用的见解的最佳方法,从而建立自己的职业。
可扩展性很难
提取关于大规模数据的有用见解甚至更加困难。
容错能力很难
在商品硬件上以容错,正确的方式从大规模数据中提取有用的见解是残酷的。
在许多用例中一并解决了所有这三个挑战之后,他们开始注意到他们所构建的自定义系统之间存在一些相似之处。他们得出的结论是,如果他们能够建立一个解决后两个问题(可伸缩性和容错性)的框架,那么将注意力集中在第一个问题上就变得非常简单。这样就诞生了MapReduce。
MapReduce的基本思想是提供一个简单的数据处理API,该API围绕功能编程领域中的两个很好理解的操作:map和reduce(图10-3)。然后,使用该API构建的管道将在分布式系统框架上执行,该框架将处理所有令人讨厌的可扩展性和容错功能,这些功能可加快核心分布式系统工程师的心胸并压倒我们其余凡人的灵魂。
图10-3 可视化MapReduce作业
我们已经在第6章中详细讨论了MapReduce的语义,因此在此不再赘述。只需回顾一下,在流和表分析的一部分中,我们将事情分为六个离散阶段(MapRead,Map,MapWrite,ReduceRead,Reduce,ReduceWrite),最后得出的结论是,实际上并没有总体Map和Reduce阶段之间存在很大差异;在较高级别上,它们都执行以下操作:
- 将表转换为流
- 将用户转换应用于该流以产生另一个流
- 将流分组到表中
在Google投入使用后,MapReduce在各种任务中发现了如此广泛的应用,因此该团队认为值得与世界其他地方分享其想法。结果就是MapReduce论文,该论文发表于OSDI 2004(请参见图10-4)。
图10-4 MapReduce论文,在OSDI 2004上发布
在其中,团队详细描述了项目的历史,API的设计和实现,以及有关已应用MapReduce的许多不同用例的详细信息。不幸的是,他们没有提供实际的源代码,因此当时Google之外的人们所能做的最好的事情就是说:“是的,的确听起来非常不错”,然后重新构建自己的定制系统。
在随后的十年中,MapReduce继续在Google内部进行大量开发,投入了大量时间使系统规模达到前所未有的水平。要详细了解该过程中的一些亮点,我推荐由我们的官方MapReduce历史学家/可扩展性和性能向导MariánDvorský撰写的帖子“ Google大规模排序实验的历史”(图10-5)。
图10-5 MariánDvorský的“大规模分选实验的历史”博客文章
但就我们在这里的目的而言,可以说,MapReduce所达到的规模还没有任何其他影响,甚至在Google内部也没有。考虑到MapReduce已经存在了多久,这说明了一点。14年是我们行业的永恒。
从流系统的角度来看,MapReduce我想带给您的主要好处是简单性和可伸缩性。Map‐Reduce迈出了勇敢的第一步,以驯服大规模数据处理过程中的野兽,它公开了一个简单而直接的API,可用于构建强大的数据处理管道,其紧缩性掩盖了复杂的分布式系统魔术的秘密 使这些管道可以在大型商品硬件集群上大规模运行。
Hadoop
我们列表中的下一个是Hadoop(图10-6)。合理的警告:这是我为了集中叙述而严重过分简化系统影响的时候之一。Hadoop对我们行业乃至整个世界的影响是不容小stat的,它的影响远远超出了我在此讨论的相对具体范围。
图10-6 时间轴:Hadoop
Hadoop诞生于2005年,当时Doug Cutting和Mike Cafarella认为MapReduce论文中的想法正是他们构建Nutch WebCrawler的分布式版本时所需要的。他们已经建立了自己的Google分布式文件系统版本(最初称为NDFS for Nutch Distributed File System,后来更名为HDFS或Hadoop Distributed File System),因此,下一步是自然的下一步,即在此之后的顶部添加MapReduce层。那篇论文发表了。他们将这一层称为Hadoop。
Hadoop和MapReduce之间的主要区别在于Cutting和Cafarella通过将Hadoop的源代码开源(以及HDFS的源代码)开源(最终成为Apache Hadoop项目的一部分)来确保与世界其他地方共享Hadoop的源代码。。Yahoo雇用了Cutting来帮助将Yahoo Webcrawler架构过渡到Hadoop,从而使该项目进一步提高了有效性和工程性能,并由此发展了整个开源数据处理工具生态系统。与MapReduce一样,其他人在其他方面告诉Hadoop的历史也比我想象的要好得多。一个特别好的参考书是Marko Bonaci的“ Hadoop的历史”,它本身最初计划包含在印刷书籍中(图10-7)。
图10-7 Marko Bonaci的“ Hadoop历史”
我希望您从本节中脱颖而出的主要观点是,围绕Hadoop兴起的开源生态系统对整个行业产生了巨大影响。通过创建一个开放的社区,工程师们可以在该社区中改进和扩展早期GFS和MapReduce论文中的想法,从而催生了繁荣的生态系统,产生了数十种有用的工具,例如Pig,Hive,HBase,Crunch等。开放性是增强我们整个行业目前存在的想法多样性的关键,这就是为什么我将Hadoop的开放源代码生态系统作为其对当今流媒体系统世界的最重要贡献的原因。
Flume
现在,我们回到Google领域,讨论Google内部MapReduce的正式继任者:Flume([图10-8]有时也称为FlumeJava,指的是系统的原始Java版本,不要与Apache Flume混淆)。是一种完全不同的野兽,恰好使用相同的名称)。
图10-8 时间轴:Flume
Flume项目由克雷格·钱伯斯(Craig Chambers)在2007年Google西雅图办事处成立时创立。其动机是希望解决MapReduce的某些固有缺陷,这种缺陷在其成功的最初几年中就显而易见了。其中许多缺点都围绕着MapReduce的刚性Map→Shuffle→Reduce结构;尽管非常简单,但它也有一些缺点:
由于单个Map‐Reduce的应用无法满足许多用例,因此Google弹出了许多定制的编排系统,以协调MapReduce作业的顺序。这些系统基本上都达到了相同的目的(将多个MapReduce作业粘合在一起以创建解决复杂问题的连贯管道)。但是,由于它们是独立开发的,因此它们自然是不兼容的,并且是不必要重复工作的教科书示例。
更糟糕的是,在许多情况下,由于API的僵化结构,如果MapReduce作业的书写顺序清晰,则会导致效率低下。例如,一个团队可能编写了一个MapReduce,它只是过滤掉了一些元素。就是说,一个只有地图的工作带有一个空化的reducer。接下来可能是另一支团队仅在地图上进行的工作,进行了逐元素的浓缩(还有另一个空化器)。然后,最终团队的MapReduce可能最终消耗了第二项工作的输出,该小组对数据进行了一些分组汇总。该管道实质上由Map阶段的单个链和随后的单个Reduce阶段组成,将需要编排三个完全独立的作业,每个作业通过改组和实现数据的输出阶段链接在一起。但这是假设您要保持代码库的逻辑性和整洁性,这将导致最终的弊端…
为了尽量减少MapReduction中的这些低效率,工程师开始引入手动优化,这会使管道的简单逻辑难以理解,从而增加了维护和调试成本。
Flume通过提供一种可组合的高级API来描述数据处理管道,从而解决了这些问题,该API主要基于Beam中找到的相同PCollection和PTransform概念,如图10-9所示。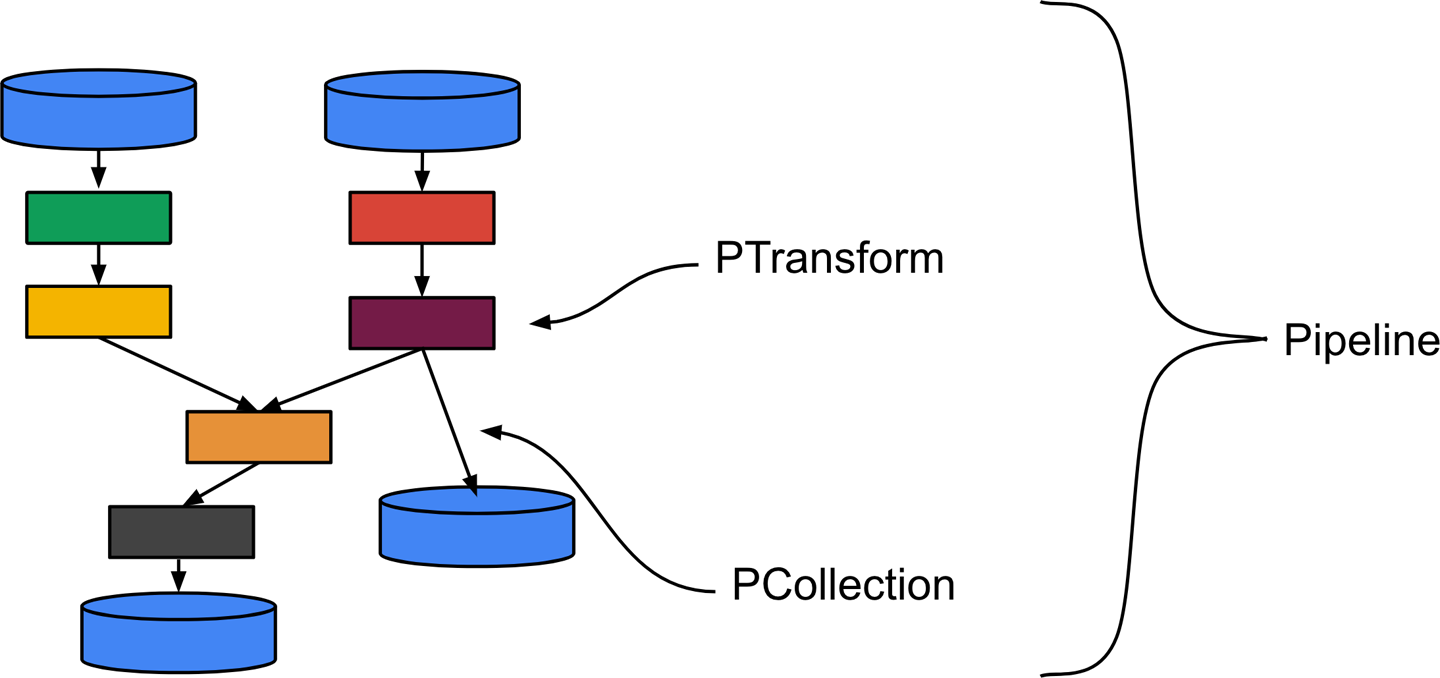
图10-9 Flume的高级管道(图片来源:Frances Perry)
这些管道在启动时将通过优化器馈送,以生成针对MapReduce作业的最佳高效序列的计划,然后由框架协调执行该计划,您可以在图10-10中看到该计划。
图10-10 从逻辑管道到物理执行计划的优化
Flume可以执行的自动优化的最重要示例可能是融合(Reuven在第5章中进行了讨论),在融合中,两个逻辑上独立的阶段可以按顺序(消费者-生产者融合)或在同一工作中运行 并行(同级融合),如图10-11所示。
图10-11 融合优化将连续或并行操作组合到同一物理操作中
将两个阶段融合在一起可以消除序列化/反序列化和网络成本,这在处理大量数据的管道中可能非常重要。
自动优化的另一种类型是组合器提升(参见图10-12),当我们讨论增量组合时,我们已经在第7章中谈到了其机制。合并器提升只是我们在本章中讨论过的多个合并逻辑的自动应用:在分组操作被部分提升到按键之前的阶段之后,逻辑上发生的合并操作(例如求和) 根据定义,需要进行一次网络旅行以对数据进行混洗),以便它可以在进行分组之前执行部分合并。在热键非常高的情况下,这可以大大减少网络上的随机数据传输量,并且还可以在多台计算机之间更平稳地分配计算最终聚集的负载。
图10-12 合并器提升在按用户方完成聚合之前,对按组操作的发送方应用部分聚合
由于其更清洁的API和自动优化功能,Flume Java于2009年初在Google上推出后立即受到了欢迎。紧随这一成功之后,该团队发表了题为“Flume Java: Easy, Efficient Data-Parallel Pipelines”(请参见图10-13),它本身就是一个很好的资源,可用于了解有关系统的更多信息。
图10-13 FlumeJava论文
在2011年下半年,Flume C ++紧随其后,并在2012年初将Flume引入了为Google的所有新工程师提供的Nooglier6培训。那是Map-Reduce终结的开始。
从那时起,Flume已经迁移到不再使用MapReduce作为其执行引擎。相反,它使用直接内置于框架本身的自定义执行引擎,称为Dax。通过将Flume自身从先前的Map→Shuffle→Reduce MapReduce结构的限制中解放出来,Dax实现了新的优化,例如Eugene Kirpichov和Malo Denielou的“不遗余力”博客中描述的动态工作平衡功能。发布(图10-14)。
图10-14 “No shard left behind”帖子
尽管在那篇文章中是在Cloud Dataflow的背景下讨论的,但动态工作平衡(或液体分片,如Google口语中所说的那样)在完成工作时会自动将多余的工作从散布碎片重新平衡到系统中的其他空闲工人早期的。通过随着时间动态地重新分配工作分配,有可能比最佳的受过良好教育的初始分配更接近最佳工作分配。它还可以适应整个工人群体的变化,在这种情况下,一台可能会阻碍工作完成的速度较慢的机器只需将其大部分任务转移给其他工人来弥补。在Google进行液体分片时,它收回了整个车队的大量资源。
关于Flume的最后一点是,它后来也进行了扩展以支持流语义。除了批处理Dax后端之外,Flume进行了扩展,使其能够在MillWheel流处理系统(稍后讨论)上执行管道。我们在本书中讨论的大多数高级流语义概念最初都已合并到Flume中,然后才发现它们在Cloud Dataflow和Apache Beam中的应用。
综上所述,在本节中,Flume的主要优点是引入了高级管道的概念,该概念可以自动优化清晰编写的逻辑管道。这样就可以创建更大,更复杂的管道,而无需手动进行编排或优化,并且始终保持这些管道的代码逻辑清晰。
Storm
接下来是Apache Storm(图10-15),这是我们介绍的第一个真正的流系统。Storm无疑不是现有的第一个流媒体系统,但是我认为这是第一个在整个行业中得到真正广泛采用的流媒体系统,因此,我们在此进行详细介绍。
图10-15 时间轴:Storm
Storm是Nathan Marz的创意,后来他在博客文章“History of Apache Storm and lessons learned”中记录了其创建的历史(图10-16)。它的TL;DR版本是Nathan在初创公司的团队雇用当时的Back-Type,他一直试图使用自定义的队列和工作人员系统处理Twitter的火水软管。他基本上意识到MapReduce员工已经有将近十年的历史了:他们代码中实际的数据处理部分只是系统的一小部分,如果有的话,建立这些实时数据处理管道会容易得多。是一个框架,负责处理所有分布式系统在磁盘下的工作。Storm由此诞生。
图10-16 “History of Apache Storm and lessons learned”
与到目前为止,我们讨论过的其他系统相比,Storm有趣的是,团队选择放宽了到目前为止我们讨论过的所有其他系统中发现的强大一致性保证。提供较低的延迟。通过将最多一次或至少一次语义与每个记录的处理相结合,并且没有持久状态的集成(即,没有一致的)概念,Storm在提供结果方面的延迟比在批处理中执行的系统要低得多。数据并保证一次正确性。对于某些类型的用例,这是一个非常合理的权衡。
不幸的是,人们很快很清楚地知道,人们真的也想吃蛋糕并吃掉它。他们不仅希望快速获得答案,还希望同时获得低延迟的结果和最终的正确性。但是仅凭Storm不可能做到这一点。输入Lambda体系结构。
鉴于Storm的局限性,精明的工程师开始运行弱一致性的Storm流管道和强一致性的Hadoop批处理管道。前者产生低延迟,不精确的结果,而后者产生高延迟,精确的结果,然后将两者最终以某种方式合并在一起,以提供单个低延迟,最终一致的输出视图。在第1章中,我们了解到Lambda架构是Marz的另一个构想,详见他的帖子“如何克服CAP定理”(图10-17)。
图 10-17 《如何击败CAP定理》
我已经花了很多时间来克服Lambda架构的缺点,因此在这里我不会be惜这些观点。但我要重申一下:尽管有成本和令人头疼的问题,Lambda体系结构还是很受欢迎的,这仅仅是因为它满足了许多企业否则很难实现的关键需求:低延迟,但是 最终从其数据处理管道中纠正结果。
从流系统发展的角度来看,我认为Storm首先负责将低延迟数据处理带给大众。但是,这样做的代价是缺乏一致性,这反过来又导致了Lambda体系结构的兴起,以及随之而来的多年的双管道黑暗时代。
但是,除了夸张的戏剧性外,Storm是使行业首次体验低延迟数据处理的系统,其影响体现在当今对流系统的广泛兴趣和采用中。
在继续之前,还值得向苍鹭大喊大叫。2015年,Twitter(世界上最大的Storm知名用户,以及最初开发Storm项目的公司)对业界感到惊讶,宣布它放弃了Storm执行引擎,取而代之的是自己开发的新系统,称为苍鹭。Heron旨在解决困扰Storm的许多性能和可维护性问题,同时保持API兼容,这在该公司名为“ Twitter Heron:大规模流处理”的论文中进行了详细介绍(图10-18)。Heron本身随后是开源的(治理移至其自己的独立基金会,而不是像Apache这样的现有基金会)。鉴于Storm的持续开发,现在有Storm系列的两个竞争版本。任何人都会猜到事情将要结束的地方,但是观看将令人兴奋。
图10-18 Heron论文
Spark
继续,我们现在来看Apache Spark(图10-19)。这是另一个部分,我将重点放在流处理领域中的特定部分上,以大大简化Spark对行业的总体影响。提前致歉。
图10-19 时间轴:Spark
Spark于2009年左右在加州大学伯克利分校的著名实验室AMPLab上开始运作。最初激发星火名声的是,它通常能够完全在内存中执行管道的大部分计算,而无需接触磁盘直到最后。工程师通过弹性分布式数据集(RDD)的思想实现了这一点,该思想基本上捕获了管道中任何给定点的全部数据沿袭,并允许在假设a)输入为前提下,根据机器故障根据需要重新计算中间结果。始终可重播,并且b)您的计算是确定性的。在许多用例中,这些前提条件是正确的,或者考虑到用户能够实现超过标准Hadoop作业的性能大幅提升,至少这些条件是足够正确的。从那里开始,Spark逐渐确立了其作为Hadoop实际继任者的最终声誉。
创建Spark几年后,当时AMPLab的一名研究生Tathagata Das意识到:嘿,我们有了这个快速的批处理引擎,如果我们只是将它们连接起来就可以运行多个批处理,那该怎么办?接一个,并用它来处理流数据?通过这种见识,Spark Streaming诞生了。
Spark Streaming真正令人着迷的是:由于强大的批处理引擎为幕后提供了动力,因此现在世界上都有一个流处理引擎,它可以自己单独提供正确的结果,而无需额外的批处理工作。换句话说,给定正确的用例,您可以放弃Lambda Architecture系统,而仅使用Spark Streaming。所有的冰雹火花流!
这里的一个主要警告是“正确的用例”部分。原始版本的Spark Streaming(1.x变体)的最大缺点是它仅支持特定类型的流处理:处理时窗口。因此,任何关心事件时间,需要处理最新数据等等的用例,如果没有用户编写的额外代码来实现某种形式的事件时间处理,就无法开箱即用地处理。在Spark的处理时间窗口架构之上。这意味着Spark Streaming最适合有序数据或与事件时间无关的计算。而且,正如我在整本书中所重申的那样,在处理当今常见的以用户为中心的大规模数据集时,这些条件并不像您希望的那样普遍。
关于Spark Streaming的另一个有趣的争议是古老的“微批处理与真正的流式传输”辩论。因为Spark Streaming基于小批量重复运行批处理引擎的思想,所以批评者声称,Spark Streaming并不是真正的流引擎,因为系统的进步受到每个批处理的全局障碍的控制。那里有一些真相。即使真正的流引擎几乎总是为了吞吐量而利用某种批处理或捆绑功能,但它们仍可以灵活地以更细粒度的级别(直到单个密钥)进行这种操作。微批量架构在全球范围内进行流程捆绑的事实意味着,几乎不可能同时具有较低的每键延迟和较高的总体吞吐量,并且有许多基准测试表明这一点或多或少是正确的。但同时,几分钟或几秒量级的延迟仍然相当不错。而且很少有用例需要精确的正确性和如此严格的延迟功能。因此从某种意义上说,Spark绝对可以针对最初的目标受众。大多数人都属于这一类。但这并没有阻止竞争对手将其抨击为该平台的巨大劣势。我个人认为,在大多数情况下,充其量只是个小问题。
除了缺点之外,Spark Streaming是流处理的分水岭:第一个公开可用的大型流处理引擎,还可以为批处理系统提供正确性保证。当然,如前所述,流媒体只是Spark整体成功案例中的一小部分,在迭代处理和机器学习,其本机SQL集成以及前面提到的如闪电般快速的过程中做出了重要贡献。存储器性能,仅举几例。
如果您想了解更多有关原始Spark 1.x架构的详细信息,我强烈建议Matei Zaharia在主题为“大型集群上快速和通用数据处理的架构”的论文(图10-20)。共有113页的Sparky天赋,非常值得投资。
图10-20 Spark论文
到目前为止,Spark的2.x变体在Spark Streaming的语义功能上进行了极大的扩展,并结合了本书中描述的模型的许多部分,同时尝试简化一些更复杂的部分。而且,Spark甚至在推动一种新的真正的流传输架构,以试图关闭微批处理的naysayer参数。但是,当它首次出现时,Spark带来的重要贡献是它是第一个具有强大一致性语义的可公开使用的流处理引擎,尽管仅在按顺序数据或事件的情况下才如此。时间不可知的计算。
MillWheel
接下来,我们讨论MillWheel,这是我在2008年加入Google后,在20%的时间内首次涉足的项目,后来在2010年全职加入了该团队(图10-21)。
图10-21 时间线:MillWheel
MillWheel是Google最初的通用流处理架构,该项目是由Paul Nordstrom在Google西雅图办事处开业时创立的。
MillWheel在Google内部的成功长期以来一直围绕着提供低延迟,高度一致的无边界,无序数据处理能力。在本书的学习过程中,我们研究了MillWheel中使之成为现实的大多数点点滴滴:
- Reuven在第5章中讨论了一次准确的保证。完全一次的保证对于正确性至关重要。
- 在第7章中,我们研究了持久状态,其持久一致的变化为在不可靠的硬件上执行的长期运行的管道中保持正确性提供了基础。
- Slava在第3章中讨论了水印。水印为推理输入数据中的混乱提供了基础。
- 同样在第7章中,我们介绍了持久计时器,该计时器提供了水印和管道的业务逻辑之间的必要链接。
注意到MillWheel项目最初并不是专注于正确性,也许有些令人惊讶。保罗的最初愿景更紧密地针对了Storm后来拥护的利基市场:低延迟,弱一致性数据处理。是最初的MillWheel客户,一个在搜索数据上进行构建的会话以及另一个对搜索查询进行异常检测的用户(MillWheel论文中的Zeitgeist示例),将项目推向了正确性的方向。两者都非常需要一致的结果:使用会话来推断用户行为,使用异常检测来推断搜索查询中的趋势;如果他们提供的数据不可靠,则两者的效用都会大大降低。结果,Millwheel的方向转向了强一致性之一。
客户也对无序处理的支持(这是通常归因于MillWheel的强大流处理的另一个核心方面)。作为一个真正的流使用案例,Zeitgeist管道希望生成一个输出流,该流可以识别搜索查询流量中的异常,而只能识别异常(即,对于其分析的消费者来说,轮询实例化中的所有键是不切实际的查看输出表以等待标记异常;仅当特定键发生异常时,使用者才需要直接发出信号)。对于异常峰值(即查询流量增加),这是相对简单的:当给定查询的计数超过模型中该查询的模型中的期望值统计上显着的数量时,您可以发出异常信号。但是,对于异常下降(即查询流量减少)而言,这个问题有点棘手。仅查看给定搜索词的查询数量已经减少是不够的,因为在任何时间段内,观察到的数量始终从零开始。在这些情况下,您真正需要做的就是等待,直到有理由相信您在给定的时间段内看到输入中具有足够代表性的部分,然后再将计数与模型进行比较。
| 真流
“真正的流使用案例”需要一些解释。流系统的最新趋势是尝试简化编程模型,以通过限制人们可以解决的用例类型来使其更易于访问。例如,在撰写本文时,Spark的结构化流和Apache Kafka的Kafka Streams系统都将自身限制在我在第8章中称为“物化视图语义”的位置,本质上是对最终一致的输出表进行了重复更新。当您想将输出作为查询表使用时,实体化视图语义非常有用:只要您可以只在该表中查找一个值,并且在查询时就可以得到最新结果,那么实体化视图就非常合适。但是,它们并不特别适用于您希望将输出作为真实流使用的用例。我将这些称为真正的流使用案例,异常检测是更好的示例之一。
正如我们将很快讨论的那样,异常检测的某些方面使其不适用于纯粹的物化视图语义(即,仅逐记录处理),特别是它依赖于输入数据完整性的推理这一事实。准确识别由于缺少数据而导致的异常(除了对输出表进行轮询以查看异常信号是否到达这一事实之外,这种方法还不能很好地扩展)。因此,真正的流使用案例是诸如水印之类的功能的动机(最好是低水印,如第3章所述,这些水印可合理跟踪输入的完整性,而不是高水印,它跟踪系统意识到的最新记录的事件时间)。由Spark Structured Streaming编写,用于垃圾收集窗口,因为随着事件时间偏差在管道中变化,高水位标记更容易错误地丢弃数据)和触发器。为了简单起见,忽略这些功能的系统会这样做,但会降低功能。毫无疑问,这样做有很大的价值,但是如果您听到这样的系统声称这些简化产生了同等甚至更大的通用性,就不要上当。您将无法解决更少的用例,而变得同样或普遍。 |
| :—- |
Zeitgeist管道首先尝试通过在查找逻辑的分析逻辑之前插入处理时间延迟来实现此目的。当数据按顺序到达时,这会相当不错,但是管道的作者发现,数据有时可能会大大延迟,从而导致乱序地到达。在这种情况下,他们使用的处理时间延迟不足,因为管道会错误地报告一系列实际上不存在的倾角异常。他们真正需要的是一种等待输入完成的方法。
因此,出于对乱序数据中输入完整性进行推理的需要,水印便应运而生。正如Slava在第3章中所述,基本思想是使用给定类型的数据源使用尽可能多的数据来跟踪提供给系统的输入的已知进度,以构建可以使用的进度指标量化输入完整性。对于简单的输入源,例如按时间顺序递增的静态分区的Kafka主题(例如,通过实时记录事件的Web前端记录),可以计算出完美的水印。对于更复杂的输入源(例如动态的输入日志集),启发式可能是您最好的选择。但是,无论哪种方式,水印都比使用处理时间来推断事件时间的完整性提供了明显的优势,这种经验在尝试导航开罗街道时显示出与服务以及伦敦地图一样的优势。
因此,由于客户的需求,MillWheel最终成为具有正确功能集的系统,可支持对无序数据进行可靠的流处理。结果,题为“ MillWheel:Internet规模的容错流处理” 8(图10-22)的论文花费了大部分时间讨论了在这样的系统中提供正确性的困难,其中一致性保证和水印是主要重点领域。如果您对此主题感兴趣,那很值得您花时间。在MillWheel论文发表后不久,MillWheel被集成为Flume的替代后端流后端,通常称为Streaming Flume。在今天的Google内部,MillWheel正在被其继任者Windmill(将在稍后讨论的还为Cloud Dataflow提供动力的执行引擎)取代,这是一种完全重写的方法,其中融合了MillWheel的所有最佳创意以及很少有新的东西,例如更好的调度和调度,以及用户和系统代码的更清晰分离。
但是,MillWheel的一大收获是,前面列出的四个概念(一次,持久状态,水印,持久计时器)一起提供了一个系统的基础,该系统最终可以实现流处理的真正希望:即使在不可靠的商品硬件上,也可以对无序数据进行健壮,低延迟的处理。
图10-22 MillWheel论文
Kafka
现在我们来看看Kafka(图10-23)。Kafka在本章讨论的系统中是独一无二的,因为它不是数据处理框架9,而是传输层。不过,请不要误解:Kafka在推进此处讨论的所有系统中的流处理方面发挥了最有影响力的作用之一。
图10-23 时间轴:Kafka
如果您不熟悉它,那么Kafka本质上是一种持久的流传输,可以实现为一组分区日志。它最初是由Neha Narkhede和Jay Kreps等业内知名人士在LinkedIn开发的,其赞誉包括:
- 提供清晰的持久性模型,在流友好界面中打包了批处理环境中持久,可重播的输入源的温暖模糊感觉。
- 在生产者和消费者之间提供一个弹性的隔离层。
- 体现了我们在第6章中讨论过的流和表之间的关系,揭示了总体上对数据处理的基本思考方式,同时还提供了与丰富而又富于数据库的世界的概念性链接。
- 从上述所有方面来看,不仅成为整个行业中大多数流处理装置的基石,而且还促进了流处理作为数据库和微服务的发展。
Kafka在流处理领域做出了巨大贡献,可以说比其他任何单一系统都多。特别是,将耐久性和可重播性应用于输入和输出流,在帮助将流处理从逼近工具的利基领域转移到大型通用数据处理中起了很大作用。此外,由Kafka社区推广的流和表理论对一般的数据处理机制提供了深入的了解。
图10-24 I ❤ Logs
图10-25 马丁的帖子(左)和杰伊的帖子(右)
Cloud Dataflow
Cloud Dataflow(图10-26)是Google完全托管的基于云的数据处理服务。Dataflow于2015年8月向全球推出。其构建目的是为了汲取构建MapReduce,Flume和MillWheel已有的十多年经验,并将其打包为无服务器云体验。
图10-26 时间轴:Cloud Dataflow
Cloud Dataflow(图10-26)是Google完全托管的基于云的数据处理服务。Dataflow于2015年8月向全球推出。其构建目的是为了汲取构建MapReduce,Flume和MillWheel已有的十多年经验,并将其打包为无服务器云体验。
尽管从系统的角度来看,Cloud Dataflow的无服务器方面可能是其在技术上最具挑战性和与众不同的因素,但我想在此讨论的对流系统的主要贡献是其统一的批处理加流编程模型。这就是我们花了很多时间在谈论的所有转换,窗口,水印,触发器和累积优势。当然,所有这些都包含了思考事物的方式/位置/时间/方式。
该模型最初返回Flume,是因为我们希望将MillWheel中强大的乱序处理支持纳入Flume提供的高级编程模型中。然后,Flume内部可用于Google员工的批处理和流式合并方法便成为数据流中包含的完全统一模型的基础。
统一模型的关键见解-当时我们甚至没有人真正欣赏过它的全部范围-掩盖之下,批处理和流处理实际上并没有太大不同:它们只是流和表的微小变化主题。正如我们在第6章了解到的那样,主要的区别实际上归结为将表逐步触发到流中的能力。其他所有概念在概念上都是相同的。11通过利用这两种方法的潜在共性,可以提供适用于两个世界的单一,近乎无缝的体验。这是使流处理更易于访问的一大进步。
除了利用批处理和流式处理之间的共性之外,我们还长期仔细地研究了我们在Google多年来遇到的各种用例,并利用这些用例来告知进入统一模型的部分。我们针对的关键方面包括:
- 未对齐的事件时间窗口,例如会话,提供了简洁表达功能强大的分析结构并将其应用于乱序数据的功能。
- 自定义窗口支持,因为一种(或什至三种或四种)大小几乎无法容纳所有大小。
- 灵活的触发和累积模式,能够调整数据流经管道的方式,以匹配给定用例的正确性,等待时间和成本需求。
- 使用水印来推理输入完整性,这对于异常情况检测(例如,异常依赖于缺少数据的分析)等用例至关重要。
- 底层执行环境的逻辑抽象,无论是批处理,微批处理还是流式处理,都为执行引擎提供了选择的灵活性,并避免了系统级构造(例如微批处理大小)爬入逻辑API。
综上所述,这些方面提供了灵活性,可以在正确性,等待时间和成本之间进行权衡,从而允许在广泛的用例中应用该模型。
既然您已经阅读了完整的书,涵盖了Dataflow / Beam Model的更多细节,那么尝试在此处重新阅读所有这些概念毫无意义。但是,如果您希望在学术上做些更多的事情,并且对前面提到的一些激励性用例有一个很好的概述,那么您可能会发现我们值得推荐的2015年数据流模型论文(图10-27)。
图10-27 Dataflow Model论文
尽管Cloud Dataflow还有许多其他吸引人的方面,但从本章的角度来看,重要的贡献在于其统一的批处理加流式编程模型。它为世界带来了一种全面的方法来处理无序,无序的数据集,并以某种方式提供了灵活性,可以进行必要的权衡以平衡正确性,延迟和匹配成本之间的紧张关系。给定用例的需求。
Flink
Flink(图10-28)在2015年出现,迅速地将自己从几乎没人听说过的系统转变为流媒体世界的强国之一,似乎在一夜之间。
图10-28 时间轴:Flink
Flink脱颖而出的主要原因有两个:
- 快速采用了Dataflow / Beam编程模型,这使其成为当时地球上语义上最强大的完全开源流系统。
- 此后不久便实现了高效的快照实施(源自Chandy和Lamport的原始论文“分布式快照:确定分布式系统的全局状态” [图10-29]),从而为正确性提供了强大的一致性保证。

图10-29 Chandy-Lamport快照
Reuven在第5章中简要介绍了Flink的一致性机制,但重申一下,其基本思想是沿着系统中工作人员之间的通信路径传播周期性的障碍。障碍充当了在消费者上游生成数据的各种分布式工作人员之间的一种协调机制。当消费者在其所有输入渠道(即从其所有上游生产者)接收到给定的障碍时,它会检查所有活动密钥的当前进度,然后可以安全地确认对屏障之前的所有数据的处理。通过调整障碍物通过系统发送的频率,可以调整检查点的频率,从而权衡增加的延迟(由于仅在检查点时间才需要实现副作用),以换取更高的吞吐量。
Flink现在能够提供精确的一次语义以及对事件时间处理的本地支持这一简单事实在当时是巨大的。但是直到杰米·格里尔(Jamie Grier)发表了题为“扩展雅虎! 流基准测试”(图10-30),可以清楚地看出Flink的性能如何。在那篇文章中,杰米描述了两项令人印象深刻的成就:
图10-30 “Extending the Yahoo! Streaming Benchmark”
- 建立原型Flink管道,其准确性要比Twitter现有的Storm管道之一(由于Flink的一次精确语义)高,而成本仅为原始成本的1%。
- 更新Yahoo! 流式基准测试显示Flink(一次准确)达到了Storm(不完全一次)吞吐量的7.5倍。此外,由于网络饱和,Flink的性能受到限制。消除网络瓶颈后,Flink的吞吐量几乎达到了Storm的40倍。
从那时起,许多其他项目(尤其是Storm和Apex)都采用了相同类型的一致性机制。
通过添加快照机制,Flink获得了端到端精确一次所需的强大一致性。但值得称赞的是,Flink进一步走了一步,并利用其快照的全局特性提供了从过去的任何一点重新启动整个管道的能力,这一功能称为保存点(在“保存点:调低时间”中进行了介绍) ”(作者:Fabian Hueske和Michael Winters [图10-31])。保存点功能采用了Kafka应用于流传输层的持久重播的温暖模糊性,并将其扩展为覆盖整个管道的宽度。随着时间的流逝,长期运行的流水线管道的平稳演变仍然是该领域的一个重要开放问题,尚有很多改进空间。但是Flink的保存点功能是朝着正确方向迈出的第一步,而这一步在撰写本文时在整个行业中仍然是独一无二的。
图10-31 “Savepoints: Turning Back Time”
如果您想了解有关系统构造Flink快照和保存点的更多信息,请参阅“ Apache Flink中的状态管理”(图10-32)一文,详细讨论实现。
图10-32 “State Management in Apache Flink”
除了保存点之外,Flink社区还在不断创新,包括将第一个实用的流SQL API推向市场,以用于大型分布式流处理引擎,如我们在第8章中讨论的那样。
总而言之,Flink迅速发展为流处理巨头的主要原因是其方法的三个特征:1)融合了业界最佳的现有想法(例如,作为Dataflow / Beam模型的第一个开源采用者),2 )将自己的创新技术带到桌面上,以推动最先进的技术水平(例如,通过快照和保存点,流SQL的强大一致性),以及3)快速重复地完成这两项工作。再加上所有这些都是在开源中完成的事实,您可以了解为什么Flink一直持续提高整个行业中流处理的标准。
Beam
我们讨论的最后一个系统是Apache Beam(图10-33)。Beam与本章中大多数其他系统的不同之处在于,它主要是编程模型,API和可移植层,而不是在其下面具有执行引擎的完整堆栈。但这正是重点:就像SQL充当声明性数据处理的通用语言一样,Beam的目标是成为程序化数据处理的通用语言。让我们探讨一下。
图10-33 时间轴:Beam
具体而言,Beam由许多组件组成:
- 一个统一的批处理加流式编程模型,该模型继承自其起源的Cloud Dataflow,并且我们在本书的大部分时间中都讨论了其中的优缺点。该模型独立于任何语言实现或运行时系统。您可以将其视为Beam等同于SQL的关系代数。
- 一组实现该模型的SDK(软件开发工具包),允许在给定语言下以惯用方式根据模型来表达管道。Beam目前提供Java,Python和Go形式的SDK。您可以将它们视为Beam与SQL语言本身的程序等效项。
- 一组基于SDK的DSL(特定领域语言),提供专用接口,以独特的方式捕获模型的各个部分。需要SDK来体现模型的所有方面,而DSL只能公开那些对于DSL所针对的特定领域有意义的部分。Beam当前提供了一个称为Scio的Scala DSL和一个SQL DSL,这两个层均位于现有Java SDK之上。
- 一组可以执行Beam管道的流道。运行程序采用Beam SDK术语中描述的逻辑管线,并将它们尽可能高效地转换为可以执行的物理管线。目前,Apex,Flink,Spark和Google Cloud Dataflow都存在束流道。用SQL术语来说,您可以将这些竞争者视为Beam等同于各种SQL数据库实现,例如Postgres,MySQL,Oracle等。
Beam的核心愿景是围绕其作为可移植性层的价值而建立的,该领域中最引人注目的功能之一是其计划中的对全面跨语言可移植性的支持。尽管尚未完全完成(但迫在眉睫),但Beam的计划是在SDK和运行程序之间提供足够性能的抽象层,以实现SDK×运行程序对的完整交叉产品。在这种情况下,即使Haskell运行器本身没有执行JavaScript代码的本机能力,使用JavaScript SDK编写的管道也可以在使用Haskell编写的运行器上无缝执行。
作为一个抽象层,Beam相对于其运行者的自身定位方式对于确保Beam真正为社区带来价值至关重要,而不是仅仅引入了不必要的抽象层。这里的关键点是,Beam的目标绝不只是其流道中要素的交集(最低公分母)或并集(厨房水槽)。相反,它旨在仅将整个数据处理社区中的最佳创意包括在内。这允许在两个方面进行创新:
Beam的创新
Beam可能包括并非所有运行程序最初都支持的运行时功能的API支持。没关系随着时间的流逝,我们期望许多跑步者会将这些功能合并到将来的版本中。对于需要此类功能的用例,那些不那么有吸引力的选择将是亚军。
Beam的SplittableDoFn API就是一个例子,它用于编写可组合的,可扩展的源(Eugene Kirpichov在他的文章“ Apache Beam中具有Splittable DoFn的强大和模块化I / O连接器”中进行了描述[图10-34])。它既独特又功能强大,但尚未获得所有参赛者对某些更具创新性的部分(如动态工作平衡)的广泛支持。鉴于这些功能所带来的价值,但是,我们希望随着时间的流逝会发生变化。
跑步者创新
跑步者可能会引入Beam最初不提供API支持的运行时功能。没关系随着时间的流逝,已证明其实用性的运行时功能将把API支持集成到Beam中。
这里的一个示例是Flink中的状态快照机制或保存点,我们前面已经讨论过。Flink仍然是唯一以这种方式支持快照的公共可用流系统,但是Beam提议在快照周围提供一个API,因为我们认为管道随时间推移的平稳发展是一项重要功能,它将在整个行业中发挥重要作用。。如果我们今天要神奇地推出这样的API,Flink将是唯一支持它的运行时系统。再次,没关系。这里的要点是,随着这些功能的价值逐渐明朗,整个行业将开始随着时间的推移而发展。而且,这对每个人都更好。
通过鼓励Beam自身以及赛跑者内部的创新,我们希望随着时间的推移以更大的速度推进整个行业的能力,而不会一路接受妥协。通过实现跨运行时执行引擎的可移植性的承诺,我们希望将Beam建立为表达程序化数据处理管道的通用语言,类似于如今的SQL作为声明性数据处理的通用货币。这是一个雄心勃勃的目标,截至撰写本文时,我们仍无法完全实现它,但到目前为止,我们还有很长的路要走。
概括
我们刚刚浏览了数据处理技术十年半的进步,重点关注了使流式系统成为当今之作的贡献。最后总结一下,每个系统的主要收获是:
MapReduce-可扩展性和简单性
通过在健壮且可扩展的执行引擎之上提供一组简单的数据处理抽象,MapReduce允许数据工程师专注于其数据处理需求的业务逻辑,而不是构建对故障模式具有弹性的分布式系统的繁琐细节。商品硬件。
Hadoop-开源生态系统
通过基于MapReduce的思想构建一个开源平台,Hadoop创造了一个繁荣的生态系统,其生态系统已经远远超出了其祖先的范围,并允许许多新的思想蓬勃发展。
Flume—管道,优化
通过将逻辑流水线操作的高级概念与智能优化器结合,Flume可以编写干净且可维护的流水线,其功能超出了Map→Shuffle→减少MapReduce的限制,而不会牺牲通过扭曲获得的任何性能通过手动调整的手动优化实现逻辑管道。
Storm-低延迟且一致性较弱
通过牺牲结果的正确性以减少延迟,Storm将流处理带入了大众,也迎来了Lambda架构时代,在该时代中,弱一致性流处理引擎与强一致性批处理系统一起运行以实现真正的业务目标低延迟,最终保持一致的结果。
Spark—高度一致性
通过重复运行高度一致的批处理引擎来提供对无边界数据集的连续处理,Spark Streaming证明了至少对于有序数据集,它既具有正确性又具有低延迟性。
MillWheel-乱序处理
通过将强大的一致性和精确的一次处理与诸如水印和计时器之类的用于推理时间的工具相结合,MillWheel克服了对乱序数据进行可靠的流处理的挑战。
Kafka-耐用的流,流和表
通过将持久日志的概念应用于流传输问题,Kafka带回了短暂的流传输(如RabbitMQ和TCP套接字)所失去的温暖,模糊的可重播性。通过普及流和表理论的思想,它有助于阐明一般数据处理的概念基础。
Cloud Dataflow-统一的批处理加上流
通过将MillWheel的乱序流处理概念与Flume的逻辑,可自动优化的流水线相融合,Cloud Dataflow为批处理和流数据处理提供了一个统一的模型,该模型提供了平衡正确性,延迟,以及与任何给定用例匹配的成本。
Flink-开源流处理创新者
通过将乱序处理功能迅速带入开源世界,并将其与分布式快照及其相关保存点功能等自身创新相结合,Flink提升了开源流处理的门槛并帮助领导了当前的工作。整个行业的流处理创新。
Beam-便携式
通过提供一个强大的抽象层,该层融合了行业内的最佳创意,Beam提供了一个可移植层,该层被定位为与SQL提供的声明性通用语言等效的程序,同时还鼓励整个行业采用创新的新创意。
可以肯定的是,我在这里重点介绍的这10个项目及其成就的样本并不能完全涵盖导致该行业发展到今天的整个历史范围。但是在我看来,它们是重要而又不重要的里程碑,这些里程碑共同描绘了过去十五年中流处理的发展,为我们提供了丰富的信息。自MapReduce成立以来,我们已经走了很长一段路,在此过程中经历了许多起伏。即便如此,在流系统领域中,还有很长的开放问题要解决。我很高兴看到未来。

若有收获,就点个赞吧
0 人点赞
