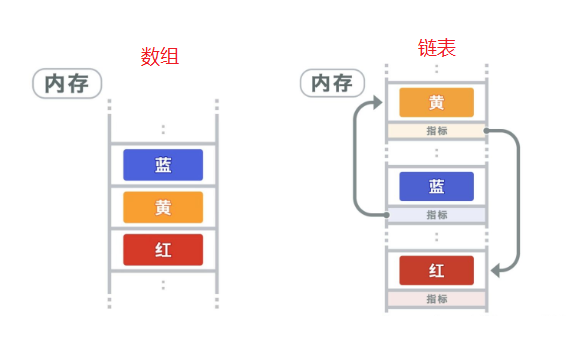
从逻辑结构上来说,这两种数据结构都属于线性表。所谓线性表,就是所有数据都排列在只有一个维度的“线”上,就像羊肉串一样,把数据串成一串。
在内存中,数组占用的是一块连续的内存区,而链表在内存中,是分散的,因为是分散的,就需要一种东西把他们串起来,这样才能形成逻辑上的线性表,不像数组,与生俱来具有“线性”的成分。因为链表比数组多了一个“串起来”的额外操作,这个操作就是加了个指向下个节点的指针,所以对于链表来说,存储一个节点,所要消耗的资源就多了。也正因为这种物理结构上的差异,导致了他们在访问、增加、删除节点这三种操作上所带来的时间复杂度不同。
对于访问,数组在物理内存上是连续存储的,硬件上支持“随机访问”,所谓随机访问,就是你访问一个a[3]的元素与访问一个a[10000],使用数组下标访问时,这两个元素的时间消耗是一样的。但是对于链表就不是了,链表也没有下标的概念,只能通过头节点指针,从每一个节点,依次往下找,因为下个节点的位置信息只能通过上个节点知晓(这里只考虑单向链表),所以访链表中的List(3)与List(10000),时间就不一样了,访问List(3),只要通过前两个节点,但要想访问List(10000),不得不通过前面的9999个节点;而数组是一下子就跳到了a[10000],无需逐个访问a[10000]之前的这些个元素。所以对于访问,数组和链表时间复杂度分别是O(1)与O(n),方式一种是“随机访问”,一种是“顺序访问”。
对于增加,因为数组在内存中是连续存储的,要想在某个节点之前增加,且保持增加后数组的线性与完整性,必须要把此节点往后的元素依次后移。要是插在第一个节点之前,那就GG了,数组中所有元素位置都得往后移一格,最后把这个后来的“活宝元素”,稳稳的放在第一个腾出来的空闲位置上,真是不考虑其他元素的感受,就像我们日常生活排队时,出现的“加塞”现象一样。“加塞”位置前的人没什么意见,因为他们的领先位置没动,还是按原来的顺序先到先得的享受服务,“加塞”位置后的人就有意见了,他们不得不都往后挪一个位置,很有可能面对突然的后挪,踩到后面人的脚,享受服务的顺序也往后挪了一位。对于数组来说,有“加塞”时,一定要先做好数据迁移,不然就会踩到脚,数组元素丢了,而且数组下标也要往后+1,享受服务的顺序往后推了一位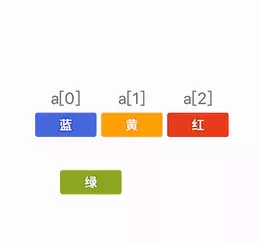
而链表却为其他元素着想多了,链表中只需要改变节点中的“指针”,就可以实现增加。自身在内存中所占据的位置不变,只是这个节点所占据的这块内存中数据(指针)改变了,相对于数组“牵一发而动全身”的大动作,链表则要显示温和的多,局部数据改写就可以了。如下图所示: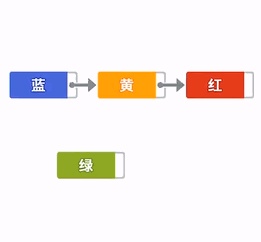
对于数组与链表的节点删除操作,同理。
除了访问、插入、删除的不同外,还有在操作系统内存管理方面也有不同。正因为数组与链表的物理存储结构不同,在内存预读方面,内存管理会将连续的存储空间提前读入缓存(局部性原理),所以数组往往会被都读入到缓存中,这样进一步提高了访问的效率,而链表由于在内存中分布是分散的,往往不会都读入到缓存中,这样本来访问效率就低,这样效率反而更低了。在实际应用中,因为链表带来的动态扩容的便利性,在做为算法的容器方面,用的更普遍一点。

若有收获,就点个赞吧
0 人点赞
