LRU算法原理,图片来自https://mp.weixin.qq.com/s/h_Ns5HY27NmL_odCYLgx_Q:
1.假设我们使用哈希链表来缓存用户信息,目前缓存了4个用户,这4个用户是按照时间顺序依次从链表右端插入的
2.此时,业务方访问用户5,由于哈希链表中没有用户5的数据,我们从数据库中读取出来,插入到缓存当中。这时候,链表中最右端是最新访问到的用户5,最左端是最近最少访问的用户1。
3.接下来,业务方访问用户2,哈希链表中存在用户2的数据,我们怎么做呢?我们把用户2从它的前驱节点和后继节点之间移除,重新插入到链表最右端。这时候,链表中最右端变成了最新访问到的用户2,最左端仍然是最近最少访问的用户1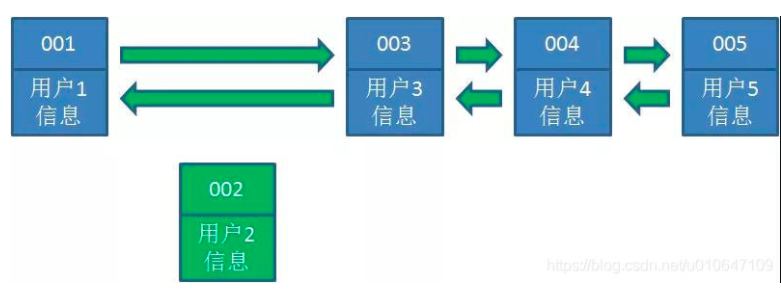
4.接下来,业务方请求修改用户4的信息。同样道理,我们把用户4从原来的位置移动到链表最右侧,并把用户信息的值更新。这时候,链表中最右端是最新访问到的用户4,最左端仍然是最近最少访问的用户1。
5.后来业务方换口味了,访问用户6,用户6在缓存里没有,需要插入到哈希链表。假设这时候缓存容量已经达到上限,必须先删除最近最少访问的数据,那么位于哈希链表最左端的用户1就会被删除掉,然后再把用户6插入到最右端。
简易实现
package mainimport ("errors""fmt")type Cache interface {Len() int64Set(k string, v interface{}) errorGet(k string) (interface{}, error)Refresh(k string) errorDel(k string) errorDelOld() errorForEach()}type Node struct {Key stringValue interface{}Next *NodePre *Node}type List struct {len int64head *Nodeend *Node}func (l *List) Len() int64 {return l.Len()}func (l *List) Set(k string, v interface{}) error {node := &Node{Key: k, Value: v}if l.len == 0 {node.Pre, node.Next = nil, nill.head, l.end = node, node} else {node.Pre, node.Next = l.end, nill.end.Next = nodel.end = node}l.len++return nil}func (l *List) Refresh(k string) error {if l.len < 1 { // 只有一个节点,不需要更新return nil}current := l.headif current.Key == k { // 如果是头节点l.head = current.Nextl.head.Pre = nilcurrent.Next = nilcurrent.Pre = l.endl.end.Next = currentl.end = currentreturn nil}if l.end.Key == k { // 如果已经是最新的一个元素,不需要更新return nil}for {if current.Key == k {current.Pre.Next = current.Nextcurrent.Next.Pre = current.Precurrent.Next = nilcurrent.Pre = l.endl.end.Next = currentl.end = currentreturn nil}if current.Next == nil {return errors.New("没找到该节点")}current = current.Next}return nil}func (l *List) Get(k string) (interface{}, error) {var v interface{}var err errorif l.len < 1 {err = errors.New("list 为空")return v, err}current := l.headif current.Key == k { // 如果是头节点v = current.Valuel.head = current.Nextl.head.Pre = nilcurrent.Next = nilcurrent.Pre = l.endl.end.Next = currentl.end = currentreturn v, err}if l.end.Key == k { // 如果尾节点是要找的节点v = current.Valuereturn v, err}for {if current.Key == k {v = current.Valuecurrent.Pre.Next = current.Nextcurrent.Next.Pre = current.Precurrent.Next = nilcurrent.Pre = l.endl.end.Next = currentl.end = currentreturn v, err}if current.Next == nil {err = errors.New("没找到该节点")return v, err}current = current.Next}return v, err}func (l *List) Del(k string) error {var err errorcurrent := l.headif current.Key == k { // 如果是头节点current.Next.Pre = nill.head = current.Nextreturn err}if l.end.Key == k { // 如果尾节点l.end.Pre.Next = nill.end = l.end.Pre}for {if current.Key == k {current.Pre.Next = current.Nextcurrent.Next.Pre = current.Pre}if current.Next == nil {err = errors.New("没找到该节点")return err}current = current.Next}}func (l *List) DelOld() error {current := l.headcurrent.Next.Pre = nill.head = current.Nextreturn nil}func (l *List) ForEach() {current := l.headfor {fmt.Print(current.Value)if current.Next == nil {break}current = current.Next}fmt.Println()}func main() {var c Cache = &List{}c.Set("1", 1)c.Set("2", 2)c.Set("3", 3)c.Set("4", 4)c.Set("5", 5)c.Refresh("1")c.ForEach()c.Get("3")c.ForEach()c.Del("4")c.ForEach()c.DelOld()c.ForEach()}
一种O1的lru思路
节点的结构如下:
type List struct {
len int64
head *Node
end *Node
}
type Node struct {
Key string
Value interface{}
Next *Node
Pre *Node
}
普通的链表结构,在更新查找时,复杂度总是O(n),我们可以额外定义一张hash表
// key: node中的key, value: node节点
map[string]*Node
例如:此时访问了对象 “A”, 我们需要把”A” 改为最热的状态,需经过如下步骤:
- 在map中找到对象”A” 对应的Node,成为 AN,复杂度O(1)
- 将A的上一个节点与下一个节点建立关系,复杂度O(1)
- 将当前的 end 与 A建立关系,复杂度O(1)
- 更新当前的 end 为A ,复杂度O(1)

若有收获,就点个赞吧
0 人点赞
