基础信息
- hadoop版本
3.3.1
下载地址:http://archive.apache.org/dist/hadoop/common/
- 网络信息
通过wget命令测试出网络带宽大概在50MB/s

- 服务器信息 | 角色 | IP | 操作系统 | CPU | 内存 | 磁盘空间 | 顺序读 | 顺序写 | | —- | —- | —- | —- | —- | —- | —- | —- | | hadoop01 | 10.241.90.2 | CentOS Linux release 7.6.1810 | 4 | 8 | 300G | 238MB/s | 137MB/s | | hadoop02 | 10.241.90.22 | CentOS Linux release 7.6.1810 | 4 | 8 | 300G | 142MB/s | 126MB/s | | hadoop03 | 10.241.40.2 | CentOS Linux release 7.6.1810 | 4 | 8 | 300G | 267MB/s | 136MB/s | | 写 | 10.241.40.4 | CentOS Linux release 7.6.1810 | 4 | 8 | 36G | 261 MB/s | 193MB/s | | 读 | 10.241.90.34 | CentOS Linux release 7.6.1810 | 4 | 4 | 36G | 268 MB/s | 188MB/s |
1.读写测试命令如下:
顺序写:
time dd if=/dev/zero of=/data/ddtest bs=1k count=10000000 conv=fdatasync
顺序读:
time dd if=/data/ddtest of=/dev/null bs=1k count=10000000 status=progress
服务器信息
测试场景1
- 背景
在副本数为3的条件下,验证用TestDFSIO工具来压测hdfs性能是否准确及写入数据客户端所处设备对写入性能是否有影响 - 案例1
写命令,在写入节点进行发压
hadoop jar ./hadoop-mapreduce-client-jobclient-3.3.1-tests.jar TestDFSIO -write -nrFiles 10 -size 128MB -resFile /data/br/logs/TestDFSIO.log
- 测试结果| | ip | 写入TPS | 读取TPS | CPU | 内存 | IO | 入流量 | 出流量 || --- | --- | --- | --- | --- | --- | --- | --- | --- || hadoop01 | 10.241.90.2 | 39.48MB/s | | 22.49 | 38.90 | 10.40 | 58.2M | 54.5M || hadoop02 | 10.241.90.22 | 39.48MB/s | | 21.34 | 41.22 | 10.30 | 55.8M | 41.9M || hadoop03 | 110.241.40.2 | 39.48MB/s | | 35.33 | 28.51 | 11.00 | 54.9M | 54.2M || 写入节点 | 10.241.40.4 | 39.48MB/s | | 19.90 | 21.71 | 0 | 132.6K | 51.2M |- 问题列表```shell[root@hadoop04 hadoop]# hadoop jar /data/br/base/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.1-tests.jarjava.lang.NoClassDefFoundError: junit/framework/TestCaseat java.lang.ClassLoader.defineClass1(Native Method)at java.lang.ClassLoader.defineClass(ClassLoader.java:763)at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)at java.net.URLClassLoader.defineClass(URLClassLoader.java:467)at java.net.URLClassLoader.access$100(URLClassLoader.java:73)at java.net.URLClassLoader$1.run(URLClassLoader.java:368)at java.net.URLClassLoader$1.run(URLClassLoader.java:362)at java.security.AccessController.doPrivileged(Native Method)at java.net.URLClassLoader.findClass(URLClassLoader.java:361)at java.lang.ClassLoader.loadClass(ClassLoader.java:424)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)at java.lang.ClassLoader.loadClass(ClassLoader.java:357)at org.apache.hadoop.test.MapredTestDriver.<init>(MapredTestDriver.java:109)at org.apache.hadoop.test.MapredTestDriver.<init>(MapredTestDriver.java:61)at org.apache.hadoop.test.MapredTestDriver.main(MapredTestDriver.java:147)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.hadoop.util.RunJar.run(RunJar.java:323)at org.apache.hadoop.util.RunJar.main(RunJar.java:236)Caused by: java.lang.ClassNotFoundException: junit.framework.TestCaseat java.net.URLClassLoader.findClass(URLClassLoader.java:381)at java.lang.ClassLoader.loadClass(ClassLoader.java:424)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)at java.lang.ClassLoader.loadClass(ClassLoader.java:357)... 21 more
这个是因为当前目录下缺少lib/junit-4.11.jar依赖包
- 案例总结
当压测客户端和datanode不在一个机器上时,namenode会随机挑选一台datanode节点进行存放第一个副本。
hadoop受网络带宽影响,写入速度在 39.48MB/s- 案例2
- 发压命令
#在hadoop01上面进行文件写入测试#写命令hadoop jar ./hadoop-mapreduce-client-jobclient-3.3.1-tests.jar TestDFSIO -write -nrFiles 10 -size 128MB -resFile /data/br/logs/TestDFSIO.log
测试结果
| | ip | 写入TPS | 读取TPS | CPU | 内存 | IO | 入流量 | 出流量 | | —- | —- | —- | —- | —- | —- | —- | —- | —- | | hadoop01 | 10.241.90.2 | 58.17MB/s | | 56.77 | 44.44 | 15.40 | 176.3K | 61.9M | | hadoop02 | 10.241.90.22 | 58.17MB/s | | 33.07 | 41.43 | 14.1 | 57.0M | 57.7M | | hadoop03 | 110.241.40.2 | 58.17MB/s | | 30.56 | 27.38 | 16.40 | 56.8M | 46.2M |问题列表
无- 案例总结
通过观察hadoop01机器的入口和出口流量可以看出,当压测客户端和datanode在一个机器上时,会将第一个副本放置在上传文件的这个datanode节点上。
hadoop写入速度在58.17MB/s- 案例3
- 发压命令
#直接使用put命令在hadoop01上进行文件写入操作,ddtest文件大小为9.6G,耗时166秒[root@hadoop01:/data]#dateWed Apr 13 14:10:53 CST 2022[root@hadoop01:/data]#hadoop fs -put ddtest /[root@hadoop01:/data]#dateWed Apr 13 14:13:37 CST 2022
测试结果
| | ip | 写入TPS | 读取TPS | CPU | 内存 | IO | 入流量 | 出流量 | | —- | —- | —- | —- | —- | —- | —- | —- | —- | | hadoop01 | 10.241.90.2 | 60MB/s | | 55.67 | 40.55 | 17.20 | 223.4K | 63.5M | | hadoop02 | 10.241.90.22 | 60MB/s | | 37.56 | 41.56 | 11.70 | 60.9M | 58.8M | | hadoop03 | 110.241.40.2 | 60MB/s | | 27.37 | 27.50 | 11.90 | 57.9M | 43.0M |问题列表
无- 案例总结
通过观察hadoop01机器的入口和出口流量可以看出,当压测客户端和datanode在一个机器上时,会将第一个副本放置在上传文件的这个datanode节点上。
hadoop写入速度在58.17MB/s- 测试结论
案例总结
| 案例 | 压测方式 | 写TPS | 主机名 | 入流量 | 出流量 | | —- | —- | —- | —- | —- | —- | | 1 | 使用TestDFSIO工具在集群外提交 | 39.48MB/s | hadoop01 | 58.2M | 54.5M | | 1 | 使用TestDFSIO工具在集群外提交 | 39.48MB/s | hadoop02 | 55.8M | 41.9M | | 1 | 使用TestDFSIO工具在集群外提交 | 39.48MB/s | hadoop03 | 54.9M | 54.2M | | 2 | 使用TestDFSIO工具在集群内提交 | 58.17MB/s | hadoop01 | 176.3K | 61.9M | | 2 | 使用TestDFSIO工具在集群内提交 | 58.17MB/s | hadoop02 | 57.0M | 57.7M | | 2 | 使用TestDFSIO工具在集群内提交 | 58.17MB/s | hadoop03 | 56.8M | 46.2M | | 3 | 使用客户端PUT工具在集群内提交 | 60MB/s | hadoop01 | 223.4K | 63.5M | | 3 | 使用客户端PUT工具在集群内提交 | 60MB/s | hadoop02 | 60.9M | 58.8M | | 3 | 使用客户端PUT工具在集群内提交 | 60MB/s | hadoop03 | 57.9M | 43.0M |案例分析
1、通过案例1,案例2对比可以得出,当压测客户端在集群外提交会比压测客户端在集群内提交写入性能差。
2、通过案例2和案例3对比可以得出,TestDFSIO工具和客户端工具测试出来的写入速度差不多,说明TestDFSIO测试hadoop集群性能是准确的。
3、通过案例2和案例3的hadoop01入流量可以看出,当压测客户端和datanode在一个机器上时,会将第一个副本放置在上传文件的这个datanode节点上。- 案例结果
1、当压测客户端在集群外提交会比压测客户端在集群内提交写入性能差。
2、TestDFSIO测试hadoop集群性能是准确的。
3、当压测客户端和datanode在一个机器上时,会将第一个副本放置在上传文件的这个datanode节点上。
测试场景2
- 背景
测试不同hadoop副本数对hdfs读写性能的影响 - 案例1
写命令,修改副本数为3
hadoop jar ./hadoop-mapreduce-client-jobclient-3.3.1-tests.jar TestDFSIO -write -nrFiles 100 -size 128MB -resFile /data/br/logs/TestDFSIO.log
- 测试结果| | ip | 写入TPS | 读取TPS | CPU | 内存 | IO | 入流量 | 出流量 || --- | --- | --- | --- | --- | --- | --- | --- | --- || hadoop01 | 10.241.90.2 | 48.99MB/s | | 21.93 | 40.20 | 10.40 | 52.8M | 46.7M || hadoop02 | 10.241.90.22 | 48.99MB/s | | 30.99 | 37.09 | 16.1 | 56.2M | 52.5M || hadoop03 | 110.241.40.2 | 48.99MB/s | | 35.33 | 24.46 | 18.70 | 58.6M | 57.7M || 写入节点 | 10.241.40.4 | 48.99MB/s | | 15.12 | 24.39 | 0 | 132.6K | 56.4M |- 问题列表<br />无- 案例总结<br />当副本数为3时,写入速度在48.99MB/s,由于写入客户端不在集群内,所以会随机往一个datanode写入数据,由于是3个副本,每个机器都会放一个副本,所以hadoop机器之间流量较大。- 案例2- 发压命令```shell#写命令,修改副本数为2hadoop jar ./hadoop-mapreduce-client-jobclient-3.3.1-tests.jar TestDFSIO -write -nrFiles 100 -size 128MB -resFile /data/br/logs/TestDFSIO.log
测试结果
| | ip | 写入TPS | 读取TPS | CPU | 内存 | IO | 入流量 | 出流量 | | —- | —- | —- | —- | —- | —- | —- | —- | —- | | hadoop01 | 10.241.90.2 | 65.45MB/s | | 17.18 | 39.16 | 13.70 | 50.4M | 49.0M | | hadoop02 | 10.241.90.22 | 65.45MB/s | | 20.00 | 35.19 | 4.30 | 55.5M | 42.7M | | hadoop03 | 110.241.40.2 | 65.45MB/s | | 27.82 | 23.60 | 10.60 | 41.9M | 49.0M | | 写入节点 | 10.241.40.4 | 65.45MB/s | | 15.86 | 24.33 | 0.00 | 216.3K | 68.0M |问题列表
无- 案例总结
当副本数为2时,写入速度在65.45MB/s,由于是2个副本,副本会存放在2个机器上,所以hadoop机器之间流量较小。- 案例3
- 发压命令
#写命令,修改副本数为1hadoop jar ./hadoop-mapreduce-client-jobclient-3.3.1-tests.jar TestDFSIO -write -nrFiles 100 -size 128MB -resFile /data/br/logs/TestDFSIO.log
- 测试结果
| | ip | 写入TPS | 读取TPS | CPU | 内存 | IO | 入流量 | 出流量 |
| ———— | —————— | ———- | ———- | ——- | ——- | ——- | ——— | ——— |
| hadoop01 | 10.241.90.2 | 71MB/s | | 55.67 | 40.55 | 17.20 | 37.9M | 109.6K |
| hadoop02 | 10.241.90.22 | 71MB/s | | 37.56 | 41.56 | 11.70 | 41.3M | 334.7K |
| hadoop03 | 110.241.40.2 | 71MB/s | | 27.37 | 26.90 | 11.90 | 46.7M | 136.5K |
| 写入节点 | 10.241.40.4 | 71MB/s | | 27.98 | 26.90 | 0.00 | 156.5K | 85.0M | - 问题列表
无
- 案例总结
当副本数为1时,写入速度在71MB/s,由于是1个副本,datanode节点之间不会同步数据,所以hadoop机器之间没有产生流量。 - 案例4
- 发压命令
#写命令,修改副本数为4hadoop jar ./hadoop-mapreduce-client-jobclient-3.3.1-tests.jar TestDFSIO -write -nrFiles 100 -size 128MB -resFile /data/br/logs/TestDFSIO.log
- 发压命令
测试结果
| | ip | 写入TPS | 读取TPS | CPU | 内存 | IO | 入流量 | 出流量 | | —- | —- | —- | —- | —- | —- | —- | —- | —- | | hadoop01 | 10.241.90.2 | 52.52MB/s | | 14.10 | 40.80 | 10.40 | 51.8M | 51.1M | | hadoop02 | 10.241.90.22 | 52.52MB/s | | 14.14 | 37.09 | 8.1 | 50.2M | 52.2M | | hadoop03 | 110.241.40.2 | 52.52MB/s | | 14.14 | 37.74 | 10.70 | 52.6M | 49.7M | | 写入节点 | 10.241.40.4 | 52.52MB/s | | 32.18 | 15.74 | 0 | 132.6K | 51.7M |问题列表
无- 案例总结
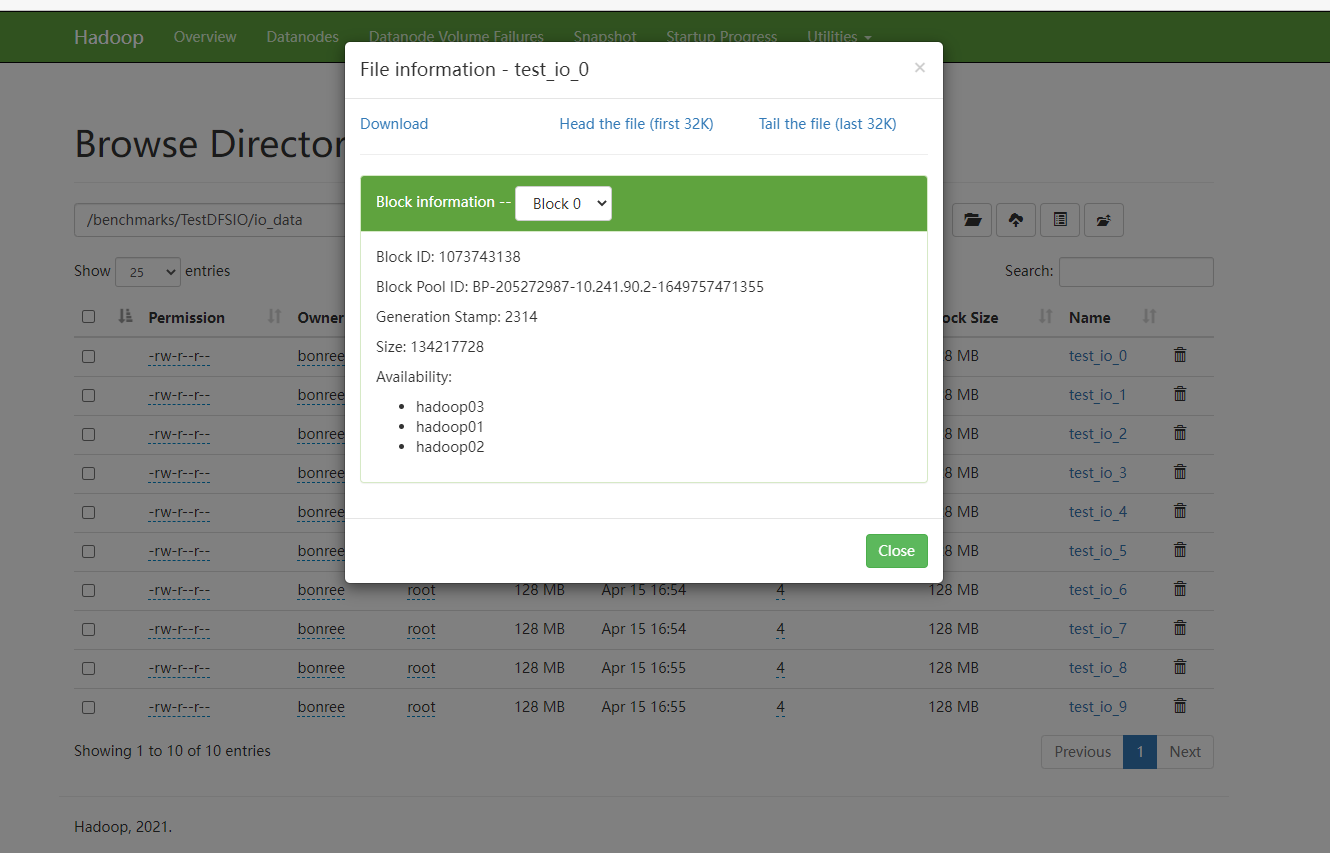
当副本数为4时,由于datanode节点只有3个,所以一会保存3个副本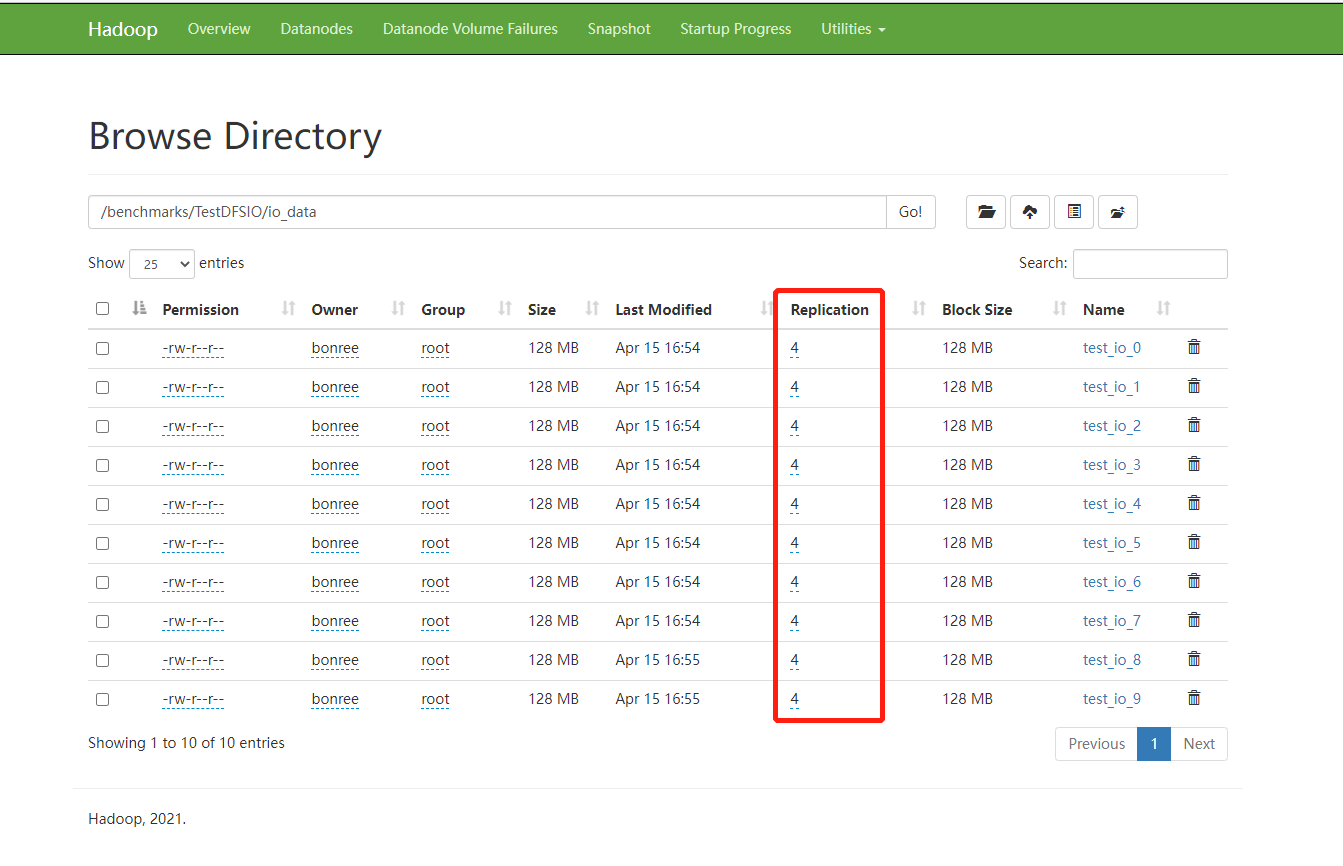
- 测试结论
案例总结
| 案例 | 副本数 | 写TPS | 主机名 | 入流量 | 出流量 | | —- | —- | —- | —- | —- | —- | | 1 | 3 | 48.99MB/s | hadoop01 | 52.8M | 46.7M | | 1 | 3 | 48.99MB/s | hadoop02 | 56.2M | 52.5M | | 1 | 3 | 48.99MB/s | hadoop03 | 58.6M | 57.7M | | 2 | 2 | 65.45MB/s | hadoop01 | 50.4M | 49.0M | | 2 | 2 | 65.45MB/s | hadoop02 | 55.5M | 42.7M | | 2 | 2 | 65.45MB/s | hadoop03 | 41.9M | 49.0M | | 3 | 1 | 71MB/s | hadoop01 | 37.9M | 109.6K | | 3 | 1 | 71MB/s | hadoop02 | 41.3M | 334.7K | | 3 | 1 | 71MB/s | hadoop03 | 46.7M | 136.5K |案例分析
1、通过案例1,2,3中hadoop机器的流量情况可以得出,副本数越多,机器之间因为同步数据所产生的流量越大。当副本数为1时,机器之间不会产生同步数据的流量。
2、通过案例1,2,3中写TPS可以得出副本数越小,写入TPS越大
3、通过案例4得出,hadoop副本数不能超过datanode节点数,就算副本数配置超过了datanode节点数,副本数也只等于datanode节点个数- 案例结果
1、副本数越多,机器之间因为同步数据所产生的流量越大。当副本数为1时,机器之间不会产生同步数据的流量。
2、副本数越小,写入TPS越大。
3、hadoop副本数不能超过datanode节点数,就算副本数配置超过了datanode节点数,副本数也只等于datanode节点个数。

若有收获,就点个赞吧
0 人点赞
