Redis故障转移
案例1
一、故障现象
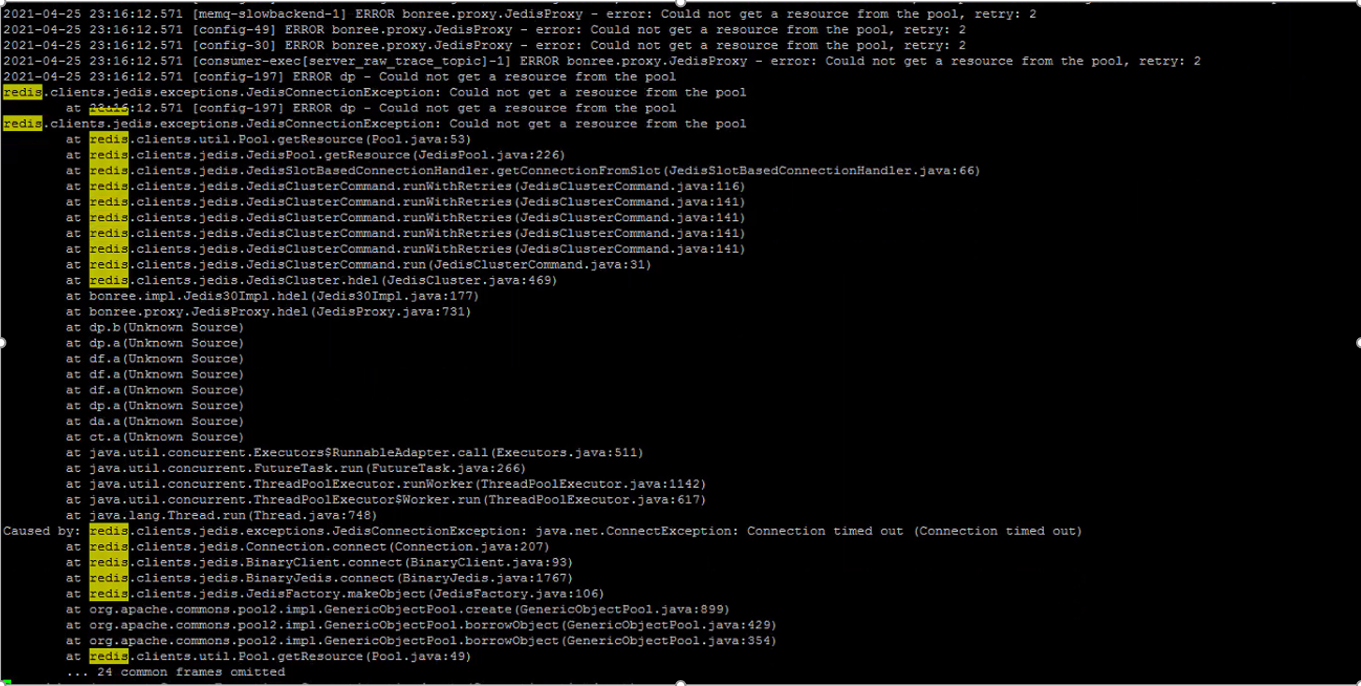
二、排查思路
- 网络问题引起连接
Redis超时 Redis集群状态不可用
三、排查过程
1、查看redis集群状态和节点状态
redis集群状态和节点状态都是正常
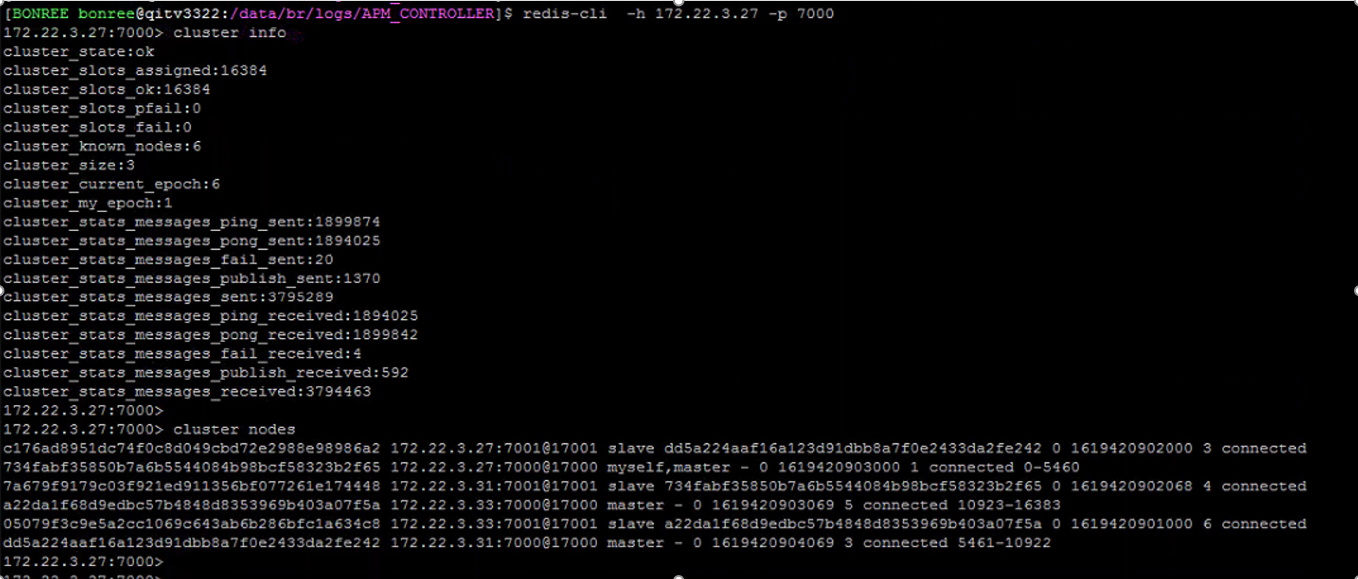
2、检查集群节点网络情况
通过ping,telnet命令测试连接集群节点网络情况都是正常的

3、查看redis日志
准备登录redis机器查询redis日志,发现其中一台redis机器无法登录,联系客户重启机器后,发现恢复正常,web能够正常访问。
四、故障原因
Redis集群其中一台机器异常,引起redis集群异常。
五、解决方案
重启系统
六、拓展
由于redis是通过ping,pong协议进行通讯的,所以系统虽然异常,但是由于端口依然能够通讯,所以没有做故障转移。
案例2
一、故障现象
WEB页面无法访问,tomcat日志显示连接redis异常
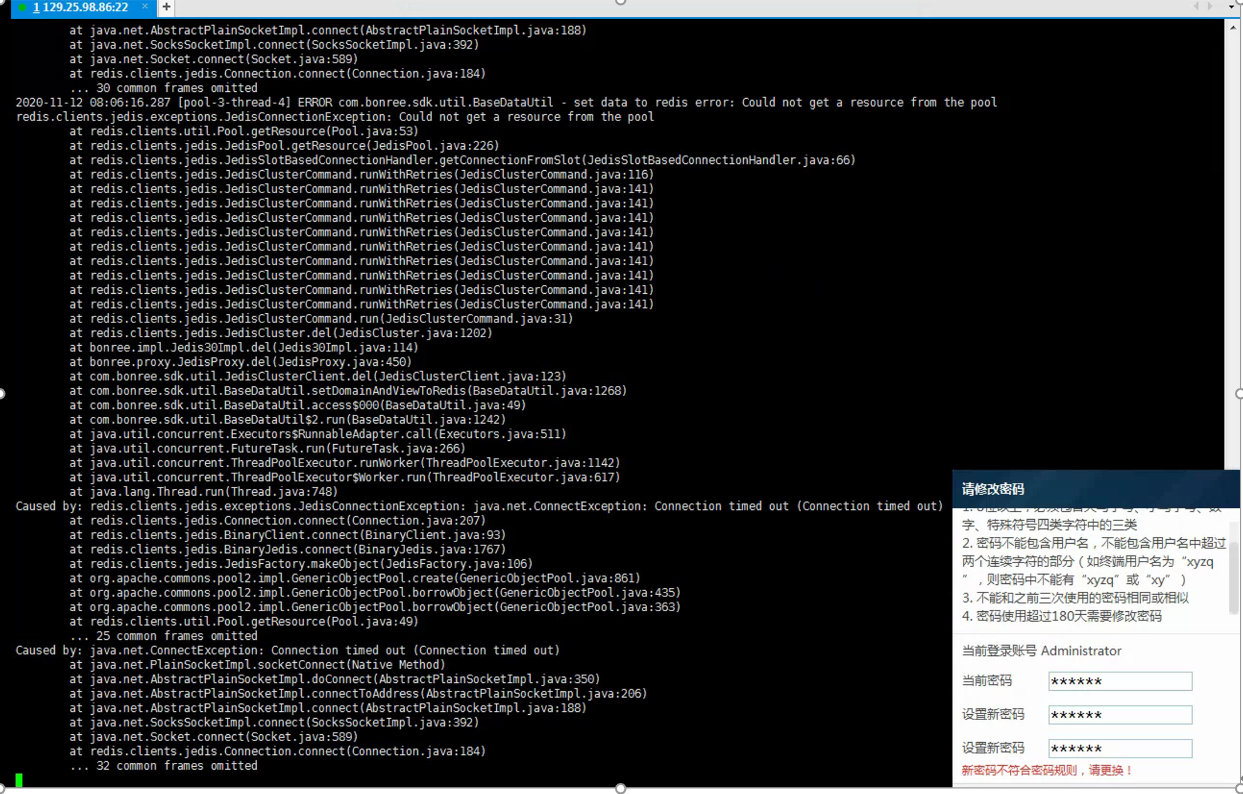
二、排查思路
- 网络问题引起连接
Redis超时 Redis集群状态不可用
三、排查过程
1、查看redis集群状态和节点状态
发现10.25.98.171机器宕机,导致上面的redis节点故障,且上面有两个master节点也是故障的状态
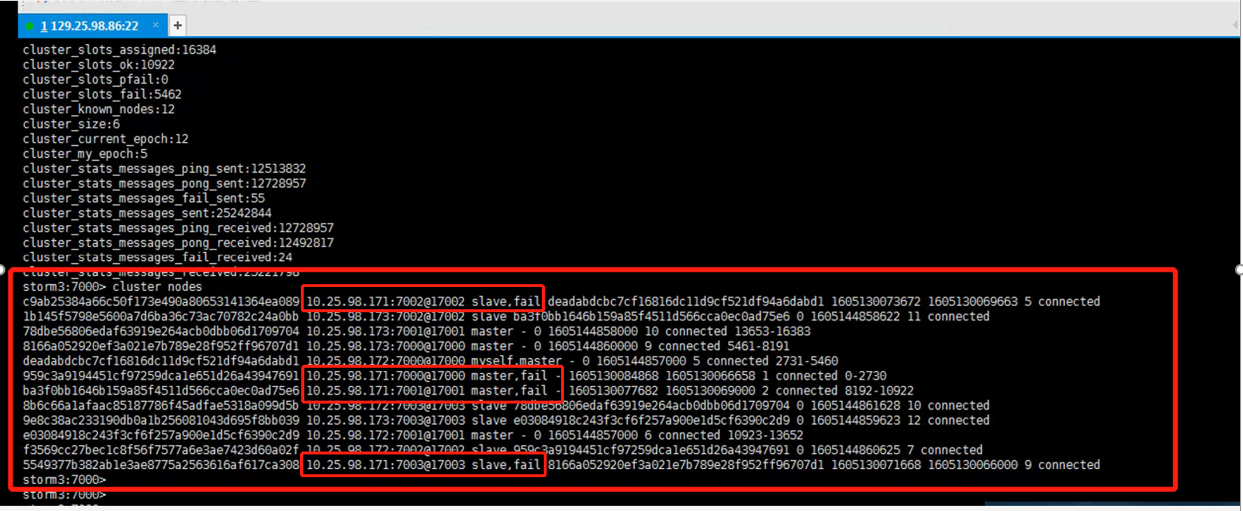
四、故障原因
Redis集群中一台机器宕机,导致redis集群中两个master处于故障状态,且两个master对应的slave节点没有切换成master节点,所以redis集群为不可用状态。
五、解决方案
找到故障机器master节点对应的slave节点,通过redis-cli命令登录进去,然后通过cluster failover force命令强制将slave节点切换成master节点
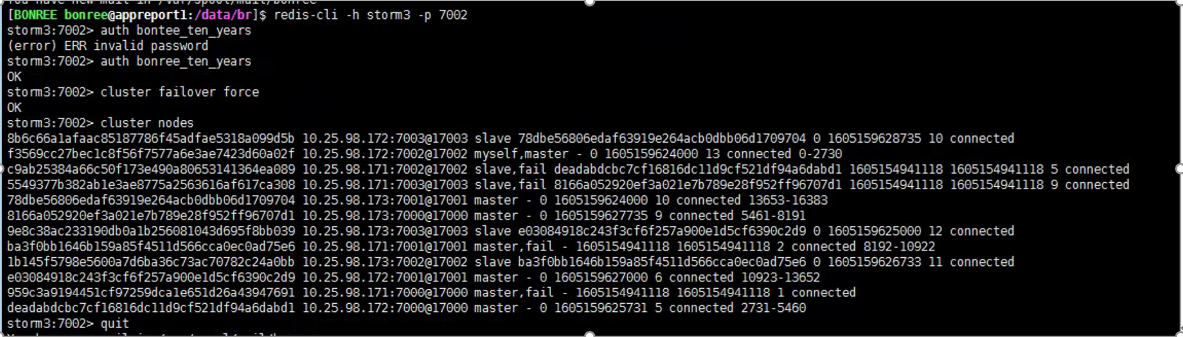
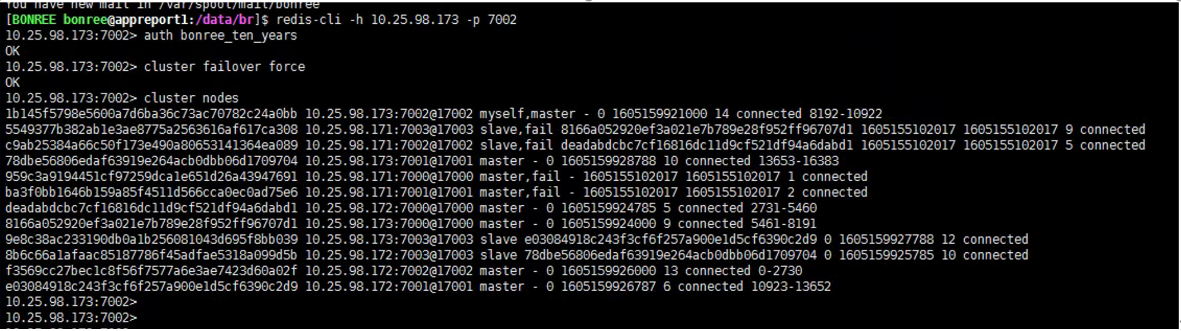
六、拓展
这次Redis集群中一台down机了,且集群中master节点状态为fail状态,为什么对应的slave节点没有切换为master节点呢?
查看Redis配置发现cluster-node-timeout参数设置的1200000,也就是20分钟。
cluster-node-timeout表示集群节点的不可用时间(超时时间), 超过这个时间就会被认为下线,单位是毫秒。
验证:
1、将cluster-node-timeout设置为1200000,手动停止其中一个master节点
手动将master节点10.241.80.113:7100停止,观察它对应的slave节点10.241.80.114:7200什么时候能够切换为master节点

通过日志可以看到09:20:26连接master节点异常

09:40:29故障转移成功。故障转移大概耗时20分钟。

通过cluster nodes命令发现节点10.241.80.114:7200切换为master节点

2、将cluster-node-timeout设置为12000,手动停止其中一个master节点
手动将master节点10.241.80.114:7200停止,观察它对应的slave节点10.241.80.113:7100什么时候能够切换为master节点

通过日志可以看到09:59:25连接master节点异常
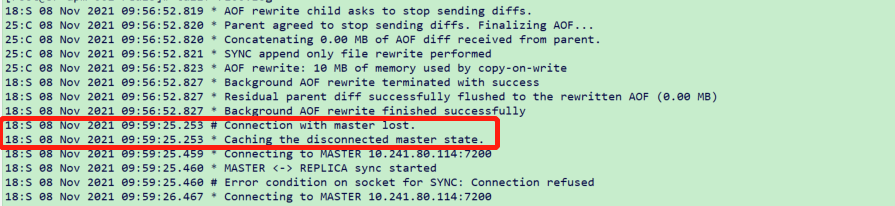
09:59:39故障转移成功。故障转移大概耗时14秒。

通过cluster nodes命令发现节点10.241.80.113:7100切换为master节点

结论:
cluster-node-timeout参数直接影响发生故障转移时长,主节点不可用时间达到cluster-node-timeout参数值,才会认为主节点不可能,从而主节点被下线,从节点切换为主节点。
8415](C:\Users\29649\AppData\Roaming\Typora\typora-user-images\image-20211108195308415.png)
结论:
cluster-node-timeout参数直接影响发生故障转移时长,主节点不可用时间达到cluster-node-timeout参数值,才会认为主节点不可能,从而主节点被下线,从节点切换为主节点。

若有收获,就点个赞吧
0 人点赞
