如何调整kafka分区
一、故障现象
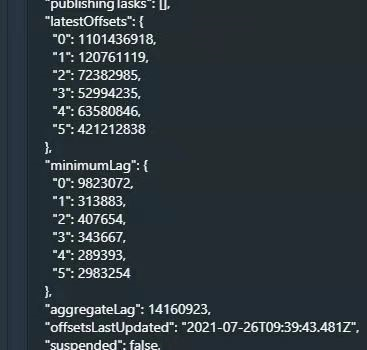
druid数据源数据积压
二、排查思路
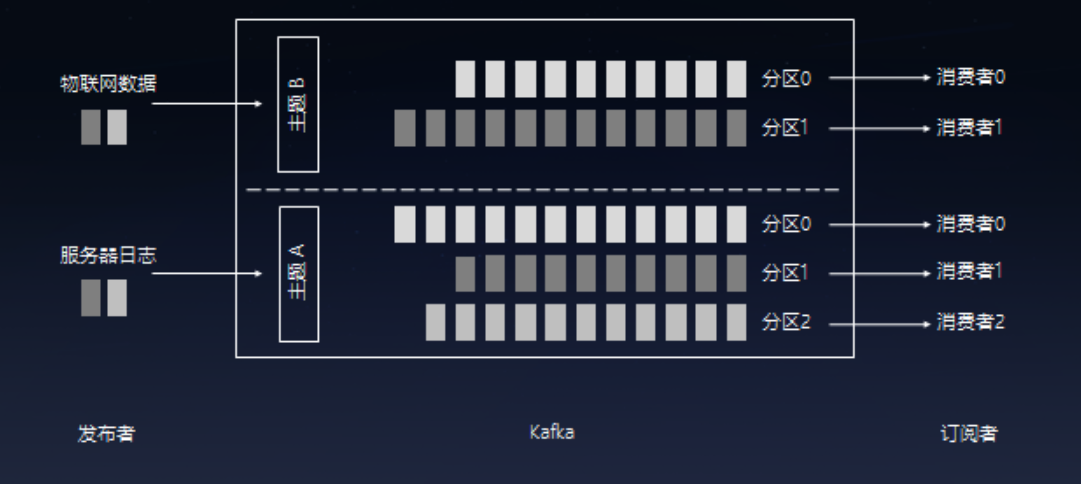
1、分区的作用
一个topic分区越多,理论上整个集群所能达到的吞吐量就越大。
kafka使用分区将topic的消息打散到多个分区分布保存在不同的broker上,实现了producer和consumer消息处理的高吞吐量。Kafka的producer和consumer都可以多线程地并行操作,而每个线程处理的是一个分区的数据。因此分区实际上是调优Kafka并行度的最小单元。对于producer而言,它实际上是用多个线程并发地向不同分区所在的broker发起Socket连接同时给这些分区发送消息;而consumer,同一个消费组内的所有consumer线程都被指定topic的某一个分区进行消费。
2、分区是不是越多越好呢
不是的
客户端/服务器端需要使用的内存就越多
1)在客户端producer有个参数batch.size,它会为每个分区缓存消息,一旦满了就打包将消息批量发出。如果分区数越多,这部分缓存所需的内存占用也会更多。
2)假设有10000个分区,同时consumer线程数要匹配分区数(大部分情况下是最佳的消费吞吐量配置)的话,那么在consumer client就要创建10000个线程,也需要创建大约10000个Socket去获取分区数据
文件句柄的开销
每个分区在底层文件系统都有属于自己的一个目录。该目录下通常会有两个文件: base_offset.log和base_offset.index。Kafak的controller和ReplicaManager会为每个broker都保存这两个文件句柄(file handler)。
降低高可用性
Kafka通过副本(replica)机制来保证高可用。具体做法就是为每个分区保存若干个副本(replica_factor指定副本数)。每个副本保存在不同的broker上。期中的一个副本充当leader 副本,负责处理producer和consumer请求。其他副本充当follower角色,由Kafka controller负责保证与leader的同步。如果leader所在的broker挂掉了,contorller会检测到然后在zookeeper的帮助下重选出新的leader——这中间会有短暂的不可用时间窗口,虽然大部分情况下可能只是几毫秒级别。但如果你有10000个分区,10个broker,也就是说平均每个broker上有1000个分区。此时这个broker挂掉了,那么zookeeper和controller需要立即对这1000个分区进行leader选举。比起很少的分区leader选举而言,这必然要花更长的时间,并且通常不是线性累加的。如果这个broker还同时是controller情况就更糟了。
三、排查过程
1、查询kafka分区数
kafka配置文件server.properties中num.partitions参数就是kafka默认分区数
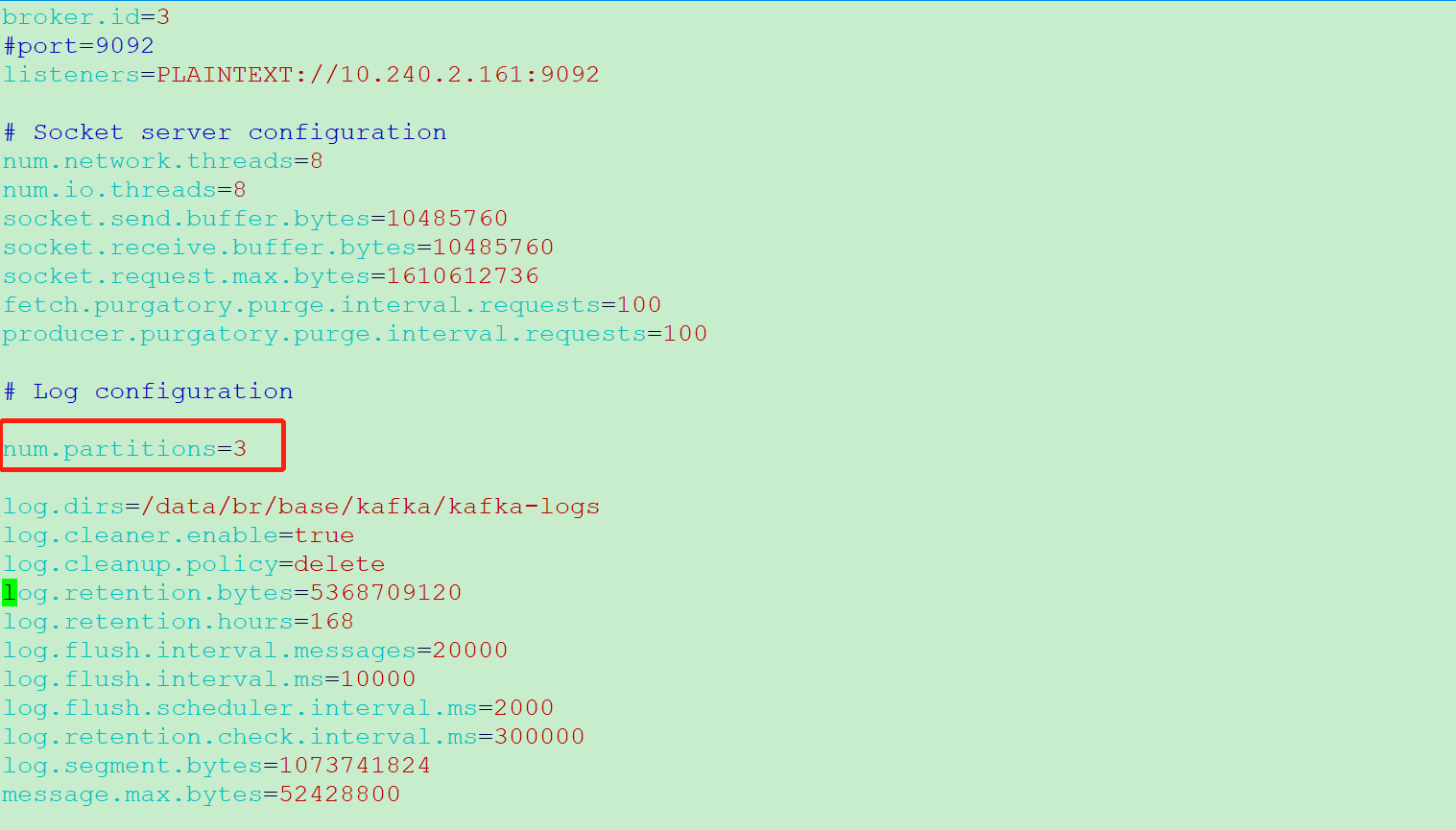
通过命令查看kafka分区数
kafka-topics.sh —zookeeper 127.0.0.1:2181 —describe |grep SERVER_DELIVERY_GRAN

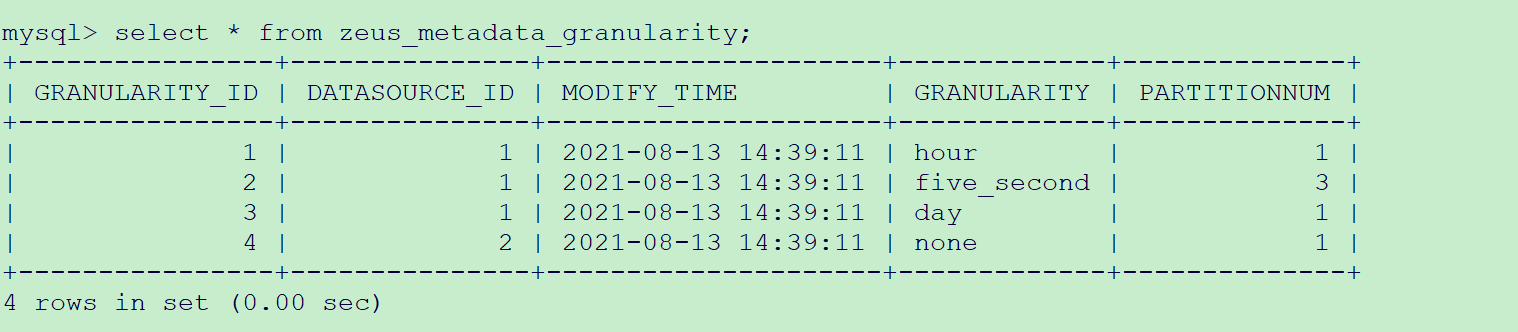
2、查询druid分区数
四、故障原因
由于kafka分区数限制,消费者druid work消费不过来,导致数据消费积压
五、解决方案
1、手动添加kafka分区数
kafka-topics.sh —alter —topic SERVER_DELIVERY_GRAN —zookeeper 127.0.0.1:2181 —partitions 6

通过命令查询分区添加是否成功

2、修改druid work数
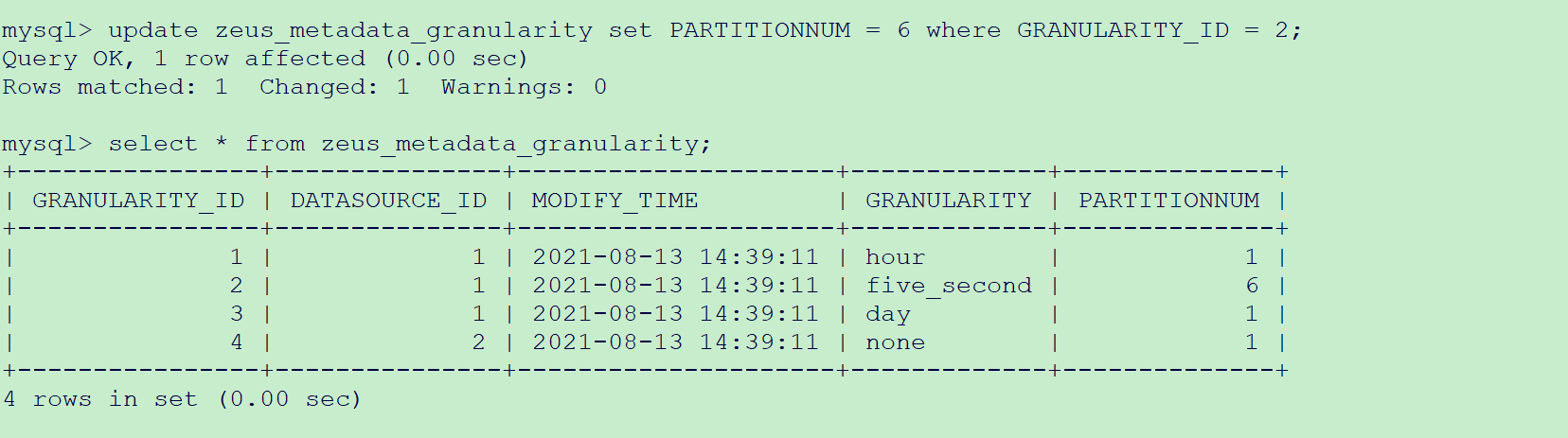
update zeus_metadata_granularity set PARTITIONNUM = 6 where GRANULARITY_ID = 2;
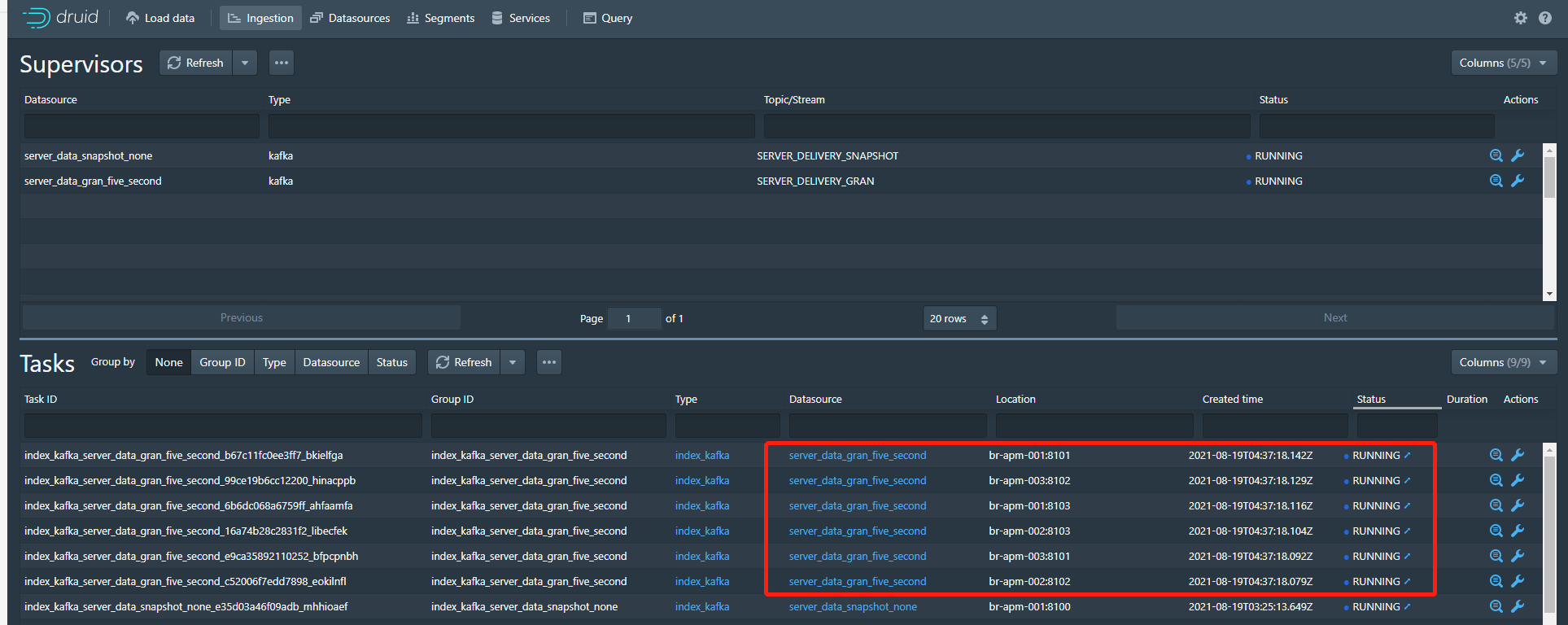
3、检查数据积压情况
5秒数据源有6个消费者在进行消费
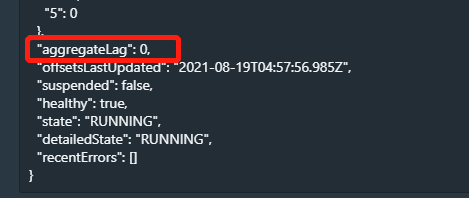
积压数据量为0
六、拓展
1、手动创建topic,并指定分区数
kafka-topics.sh —create —zookeeper 127.0.0.1:2181 —replication-factor 2 —partitions 5 —topic test-partition-5
\1629349174396.png)
六、拓展
1、手动创建topic,并指定分区数
kafka-topics.sh —create —zookeeper 127.0.0.1:2181 —replication-factor 2 —partitions 5 —topic test-partition-5

若有收获,就点个赞吧
0 人点赞
