概念
mapreduce是一个分布式编程的计算框架,是一个将分布式计算抽象成map和reduce两阶段的变成模型
注意:分布式计算的理解 - 之前是移动数据到应用程序所在机械进行运算,mapreduce是移动程序到数据所在机械进行计算
mapreduce简易流程

map任务处理 - 映射
读取hdfs中的文件,将每一行解析成
按照业务需求重写map,转换成新的
对输出的新
reduce任务处理 - 规约
map任务输出的
按照业务需求重写reduce函数,对输入
把reduce的输出保存到hdfs文件系统中
mapreduce详情工作流程
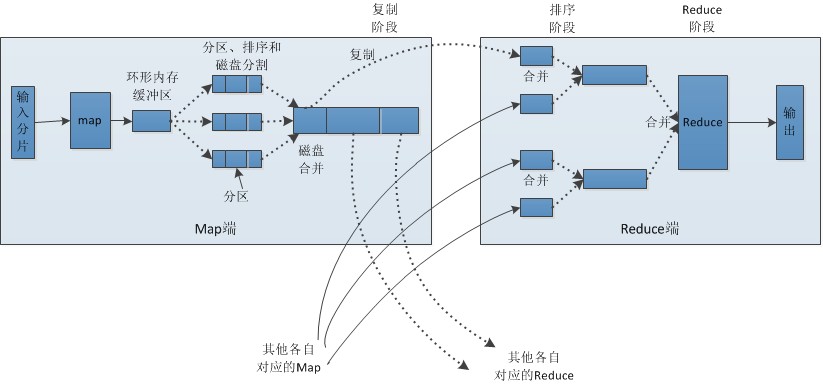
shuffle机制
map阶段处理完数据将数据传递给reduce阶段之前对数据处理的这个流程称为shuffle — 在map中,每个map函数会输出一组一组的key-value对,shuffle阶段会把所有map主机上相同的key-value对组合在一起(这里省略了combine阶段 — map阶段的局部聚合)组合后传给reduce主机,作为reduce函数的输入
shuffle工作流程

map阶段
- map阶段输出的key-value会先输出到内存的环形缓冲区(大小默认100M,由io.sort.mb属性控制)
- 环形缓冲区满后(缓冲区大小的80%)会溢出到磁盘,在本地文件系统创建一个溢出文件,并将数据写入
- 在写入文件之前,会根据分区规则对数据进行分区、排序;如果此时设置了combiner,会进行局部合并
注意:分区规则默认是hash规则,也可以自定义分区规则 — 数据倾斜的问题
- 当map任务输出最后一个记录时,可能会产生很多溢出文件,这时需要将这些文件合并,合并的过程中会不断的进行排序和combiner操作,最后合并成一个已分区且已排序的文件。为了减少网络传输,可以对文件进行压缩(将mapred.compress.map.out设置为true)
-
reduce阶段
reduce接收map阶段传过来的数据,,如果数据量比较小,则直接在内存中计算(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制),如果超出缓冲区大小的比例,则对数据进行合并并溢出到磁盘
- 随着溢出文件增多,后台会对文件进行合并,形成一个更大的排序文件
- 合并的过程会产生很多中间文件,但mapreudce会让写入磁盘的数据尽可能少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数


若有收获,就点个赞吧
0 人点赞
