一、namenode文件结构

edits -
- 记录客户端对hdfs的每一步操作(记录元数据的增加和修改),可通过edits运算出元数据
- edits_start transaction ID - end transaction ID
- edits_inprogress_start transaction ID
当前正在被追加的edit log, hdfs默认会为该文件提前申请IMB的空间用于提升性能
fsimage -
- namenode内存中元数据序列化后形成的文件,元数据镜像
- fsimage_end transaction ID:每次checkpoint(合并所有edits到一个fsimage的过程)产生的最终fsimage, 同时会生成一个.md5的文件用来对文件做完整性校验
seen_txid -
- 是存放transactionid的文件,format之后是0,他代表的是namenode里面的edits*文件的尾数,namenode 重启时,会按照seen_txid的数字,循环从头跑edits_00001-到seen_txid的数字
- 当hdfs发送异常重启时,一定要对seen_txid内的数字与edits最后的尾数进行比对,不然会发生元数据丢失
VERSION - 保存hdfs的版本号
namespaceID是文件系统的唯一标识符,是在文件系统初次格式化时生成的
clusterID是系统生成或手动指定的集群ID
cTime表示namenode存储时间的创建时间,升级后会更新该值
storageType:是namenode or datanode
blockpoolID:改ID包括了namespace对应的namenode节点的ip地址
layoutVersion:分层版本,它是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号
in_use.lock
防止一台机械同时启动多个namenode进程导致目录数据不一致
二、secondary namenode目录结构

edits -
从namenode复制的日志文件
fsimage -
从namenode复制的镜像文件
VERSION -
与namenode一样
in_use.lock**
防止一台机械同时启动多个secondary namenode进程
三、namenode解决了以下几个问题
- 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。
元数据存储在内存中,备份在fsimage中
- 这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
为了数据一致性和更新元数据的性能,采用edits来顺序写记录操作日志
- 但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
防止文件过大,引入SecondaryNamenode节点,定期合并数据
四、namenode和secondary namenode的工作原理
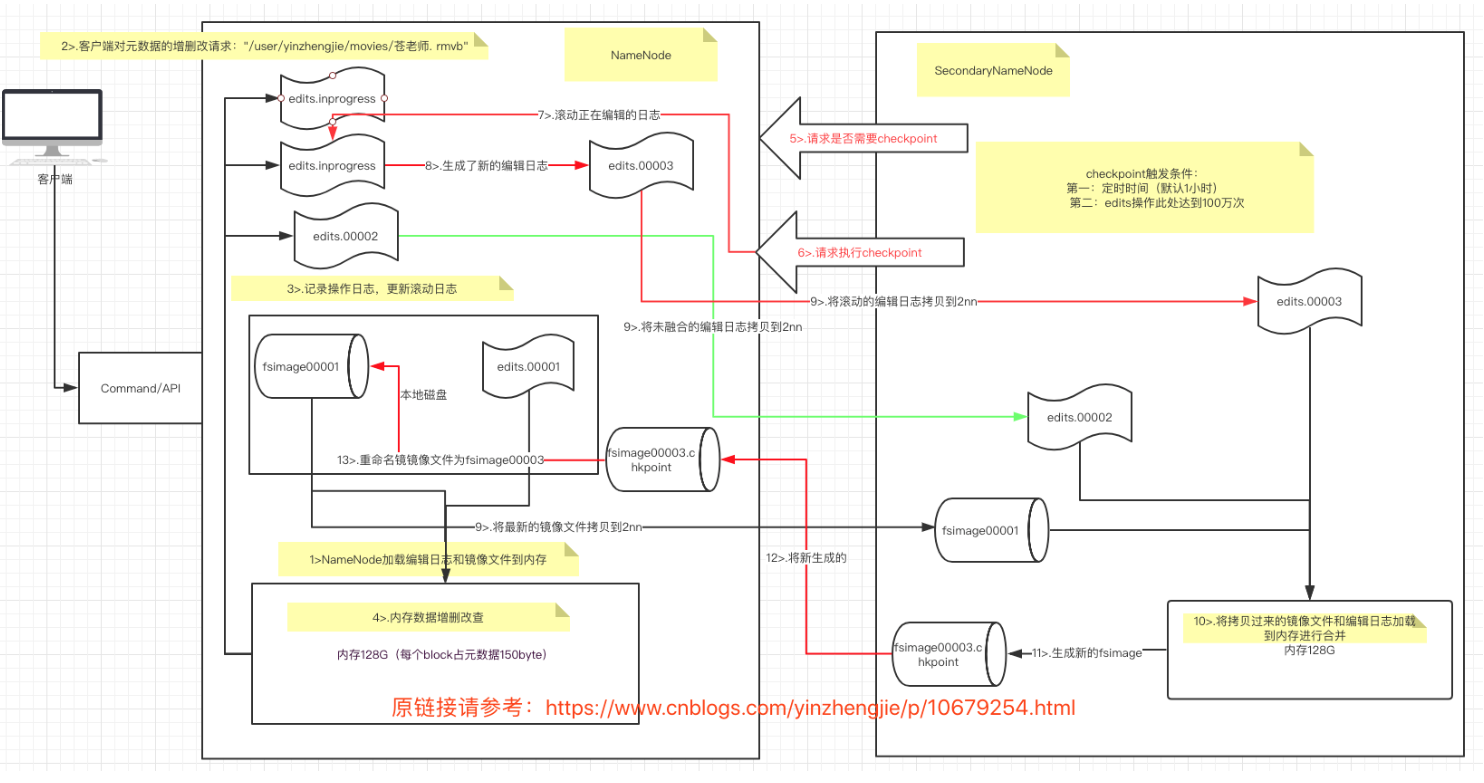
第一阶段:namenode工作
- 第一次启动namenode格式化后,创建fsimage和edits文件,如果不是第一次启动,加载并合并edits和fsimage文件到内存
- 客户端对元数据进行增删改的请求
- namenode记录操作日志,更新滚动edits日志
-
第二阶段:secondary namenode的工作
secondary namenode定期询问namenode是否需要checkpoint,直接带回namenode的结果
secondary namenode请求执行checkpoint
namenode滚动正在写edits日志
将滚动前的编辑日志和镜像文件拷贝至secondary namenode
secondary namenode加载并合并日志和镜像文件到内存
生成新的镜像文件fsimage
将新的镜像文件拷贝至namenode
namenode将新的fsimage.checkpoint重命名为fsimagecheckpoint触发条件配置
默认一分钟检查一次操作数,当操作数达到100万时,secondary namenode执行一次
<property><name>dfs.namenode.checkpoint.txns</name><value>1000000</value><description>操作动作次数</description></property><property><name>dfs.namenode.checkpoint.check.period</name><value>60</value><description> 1分钟检查一次操作次数</description></property>
通常情况下,secondary namenode每隔一小时执行一次
[hdfs-default.xml]<configuration><property><name>dfs.namenode.checkpoint.period</name><value>3600</value></property></configuration>
namenode配置
<property><name>dfs.namenode.name.dir</name><value>file://${hadoop.tmp.dir}/dfs/name</value><description>Determines where on the local filesystem the DFS name nodeshould store the name table(fsimage). If this is a comma-delimited listof directories then the name table is replicated in all of thedirectories, for redundancy. </description></property>//目录可配置多个<configuration><property><name>fs.default.name</name><value>hdfs://neusoft-master:9000</value></property><property><name>hadoop.tmp.dir</name><value>/opt/hadoop-2.6.0-cdh5.6.0/tmp</value></property>
五、问题
blocksize究竟调多大合适?
也和mapreduce有关,计算时间在分钟内最好
集群启动后,可以查看目录,但是上传文件报错,查看集群显示safemode状态
namenode的三种状态:active、standby、safemode安全模式
namenode进入安全模式的原理
当namenode发现集群block块丢失率达到0.01%(可配置),namenode就会进入安全模式,在安全模式下,客户端不能对数据进行任何操作只能查看
如何退出安全模式
hdfs集群正常冷启动时,namenode会加载镜像文件,所以会在safemode状态下维持相当长的时间,启动完毕后自动退出安全模式
如果有问题找到问题进行修复

若有收获,就点个赞吧
0 人点赞
