Flannel是由CoreOS提出的跨主通信容器网络解决方案,通过分配和管理全局唯一容器IP以及实现跨组网络转发的方式,构建基于Overlay Network的容器通信网络。作为最早出现的网络编排方案,Flannel是最简单的集群编排方案之一,为容器跨节点通信提供了多种网络连接方式,后续很多插件的方案也是基于Flannel的方案进行扩展。Flannel的框架包含以下组件:每个节点上的代理服务flanneld,负责为每个主机分配和管理子网;全局的网络配置存储etcd(或K8S API)负责存储主机和容器子网的映射关系;多种网络转发功能的后端实现。UDP Mode: UDP是 与Docker网桥模式最相似的实现模式。不同的是,UDP模式在虚拟网桥基础上引入了TUN设 备(flannel0)。TUN设备的特殊性在于它可以把数据包转给创建它的用户空间进程,从而实现内核到用户空间的拷贝。在Flannel中,flannel0由flanneld进程创建,因此会把容器的数据包转到flanneld,然后由flanneld封包转给宿主机发向外部网络。 UDP转发的过程为:Node1的Pod-1发起的IP包(目的地址为Node2的Pod-2)通过容器网关发到cni0,宿主机根据本地路由表将该包转到flannel0,接着发给flanneld。Flanneld根据目的容器容器子网与宿主机地址的关系(由etcd维护)获得目的宿主机地址,然后进行UDP封包,转给宿主机网卡通过物理网络传送到目标节点。在UDP数据包到达目标节点后,根据对称过程进行解包,将数据传递给目标Pod。 UDP模式使用了Flannel自定义的一种包头协议,实现三层网络Overlay网络处理跨主通信的问题。但是由于数据在内核和用户态经过了多次拷贝:容器是用户态,cni0和flannel0是内核态,flanneld是用户态,最终又要通过内核将数据发到外部网络,因此性能损耗较大,对于有数据传输有要求的在线业务并不适用。Kubernetes CNI Flannel [UDP Mode]
Kubernetes CNI Flannel Pod - Pod Communication[Different Node][UDP Mode]
运行在用户空间[root@master ~]# netstat -nlptu | grep flanneldudp 0 0 192.168.130.10:8285 0.0.0.0:* 22962/flanneld[root@master ~]# netstat -nlpu | grep flanneldudp 0 0 192.168.130.10:8285 0.0.0.0:* 22962/flanneld
Kubernetes CNI Flannel Container - Container Communication[Same Pod]
Container:一个容器直接使用另外一个已经存在容器的网络配置:IP信息和网络端口等所有网络相关的信息都是共享的。需要注意的是:这两个容器的计算和存储资源还是隔离的。kubernetes 的 pod 就是用这个实现的,同一个 pod 中的容器共享一个 network namespace。container网络模式用于容器和容器直接频繁交流的情况.
Kubernetes CNI Flannel Pod - Pod Communication[Same Node][UDP Mode]
Pod - Pod[Same Node]:通常情况下,在Flannel上解决同节点Pod之间的通信依赖的是Linux Bridge,和我们在Docker中不同的是,在Kubernetes Flannel的环境中使用的Linux Bridge为cni0,而不是原来的docker0。可通过:brctl show查看对应的Linux Bridge的bridge name和interfaces。
[root@node ~]# brctl showbridge name bridge id STP enabled interfacescni0 8000.ceed8853aa9e no veth0e17916dveth98110d62docker0 8000.0242e2e0fd6f no
Kubernetes CNI VETH Pair
The veth devices are virtual Ethernet devices. They can act as tunnels between network namespaces to create abridge to a physical network device in another namespace, but can also be used as standalone network devices.veth devices are always created in interconnected pairs. A pair can be created using the command:# ip link add <p1-name> type veth peer name <p2-name>In the above, p1-name and p2-name are the names assigned to the two connected endpoints.Packets transmitted on one device in the pair are immediately received on the other device. When either devicesis down the link state of the pair is down.veth device pairs are useful for combining the network facilities of the kernel together in interesting ways. Aparticularly interesting use case is to place one end of a veth pair in one network namespace and the other end inanother network namespace, thus allowing communication between network namespaces.To do this, one can provide the netns parameter when creating the interfaces:# ip link add <p1-name> netns <p1-ns> type veth peer <p2-name> netns <p2-ns>ethtool can be used to find the peer of a veth network interface,using commands something like:ethtool -S ve_ANIC statistics:peer_ifindex: 16# ip link | grep '^16:' # Look up interface16: ve_B@ve_A: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc ...Kubernetes CNI Flannel - VETH Pair
虚拟网卡对:一端是POD里面eth0网卡,一端linux bridge里面的某个接口(这里指的是cni0而不是docker0)
验证1:Node节点验证
kubectl run wang1 --image=burlyluo/nettoolbox创建一个容器[root@node ~]# kubectl exec -it wang1 bashkubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.bash-5.1# clearbash-5.1# ethtool -S eth0NIC statistics:peer_ifindex: 9
进入容器查看peer,以及查看linux bridge
[root@node ~]# kubectl exec -it wang1 bashkubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.bash-5.1# clearbash-5.1# ethtool -S eth0NIC statistics:peer_ifindex: 9[root@node ~]# brctl showbridge name bridge id STP enabled interfacescni0 8000.ceed8853aa9e no veth0e17916dveth98110d62docker0 8000.0242e2e0fd6f no

在宿主机上查看,容器中的eth0网卡与宿主机上的bridge cni0形成了veth peer。
验证2:Master节点验证
kubectl taint nodes --all node-role.kubernetes.io/master- 去掉master节点上污点[root@master ~]# brctl showbridge name bridge id STP enabled interfacescni0 8000.f673f7ea038a no veth6fb5e260docker0 8000.024225466d00 no[root@master ~]#
[root@master ~]# ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope hostvalid_lft forever preferred_lft forever2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 00:0c:29:84:78:2e brd ff:ff:ff:ff:ff:ffinet 192.168.130.10/24 brd 192.168.130.255 scope global noprefixroute ens33valid_lft forever preferred_lft foreverinet6 fe80::a14c:3318:52d:de89/64 scope link noprefixroutevalid_lft forever preferred_lft forever3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group defaultlink/ether 02:42:25:46:6d:00 brd ff:ff:ff:ff:ff:ffinet 172.17.0.1/16 brd 172.17.255.255 scope global docker0valid_lft forever preferred_lft forever4: dummy0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default qlen 1000link/ether 96:59:4e:51:1f:9b brd ff:ff:ff:ff:ff:ff5: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group defaultlink/ether ca:b9:51:ea:8f:ee brd ff:ff:ff:ff:ff:ffinet 10.96.0.10/32 brd 10.96.0.10 scope global kube-ipvs0valid_lft forever preferred_lft foreverinet 10.96.0.1/32 brd 10.96.0.1 scope global kube-ipvs0valid_lft forever preferred_lft forever6: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group defaultlink/ether de:e9:d8:e2:14:65 brd ff:ff:ff:ff:ff:ffinet 10.244.0.0/32 scope global flannel.1valid_lft forever preferred_lft foreverinet6 fe80::dce9:d8ff:fee2:1465/64 scope linkvalid_lft forever preferred_lft forever7: flannel0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1472 qdisc pfifo_fast state UNKNOWN group default qlen 500link/noneinet 10.244.0.0/32 scope global flannel0valid_lft forever preferred_lft foreverinet6 fe80::e972:9e58:b895:774/64 scope link flags 800valid_lft forever preferred_lft forever8: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1472 qdisc noqueue state UP group default qlen 1000link/ether f6:73:f7:ea:03:8a brd ff:ff:ff:ff:ff:ffinet 10.244.0.1/24 brd 10.244.0.255 scope global cni0valid_lft forever preferred_lft foreverinet6 fe80::f473:f7ff:feea:38a/64 scope linkvalid_lft forever preferred_lft forever9: veth6fb5e260@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1472 qdisc noqueue master cni0 state UP group defaultlink/ether fe:35:16:e8:6f:18 brd ff:ff:ff:ff:ff:ff link-netnsid 0inet6 fe80::fc35:16ff:fee8:6f18/64 scope linkvalid_lft forever preferred_lft forever


真正数据报文路径:
Note:veth pair 试用于不同的network namespace 间进行通信,veth pair 将一个network namespace 数据发往另一个network namespace 的veth。
模拟两个不同Namespace之前的POD进行通信
[root@master ~]# ip netns add ns1 创建名称空间1
[root@master ~]# ip netns add ns2 创建名称空间2
[root@master ~]# ip link add veth0 type veth peer name veth1 创建一对veth peer,但还没有加入到任何的名称空间中,处于游离状态
可以通过ifconfig -a 或者 ip -a来查看
veth0: flags=4098<BROADCAST,MULTICAST> mtu 1500
ether 96:52:7a:b3:f5:ef txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth1: flags=4098<BROADCAST,MULTICAST> mtu 1500
ether 56:ce:8d:a5:ef:af txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
将veth0 veth1分别加入到ns1,ns2中;
[root@master ~]# ip link set veth0 netns ns1 将veth0加入ns1
[root@master ~]# ip link set veth1 netns ns2 将veth1加入到ns2
将网卡加入到namespace中,使用ip -a或ifconfig -a看不到了
[root@master ~]# ip netns exec ns1 ip a
[root@master ~]# ip netns exec ns2 ip a
[root@master ~]# ip netns exec ns1 ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
12: veth0@if11: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 96:52:7a:b3:f5:ef brd ff:ff:ff:ff:ff:ff link-netnsid 1
[root@master ~]# ip netns exec ns2 ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
11: veth1@if12: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 56:ce:8d:a5:ef:af brd ff:ff:ff:ff:ff:ff link-netnsid 0
[root@master ~]#
给两个veth0 veth1配上ip并启动
[root@master ~]# ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0
[root@master ~]# ip netns exec ns2 ip a a 10.1.1.3/24 dev veth1
[root@master ~]# ip netns exec ns1 ip l s veth0 up
[root@master ~]# ip netns exec ns2 ip l s veth1 up
[root@master ~]# ip netns exec ns1 ethtool -S veth0 查看index
NIC statistics:
peer_ifindex: 11
查看不在宿主机root namespace下
[root@master ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:84:78:2e brd ff:ff:ff:ff:ff:ff
inet 192.168.130.10/24 brd 192.168.130.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::a14c:3318:52d:de89/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:25:46:6d:00 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
4: dummy0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 96:59:4e:51:1f:9b brd ff:ff:ff:ff:ff:ff
5: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default
link/ether ca:b9:51:ea:8f:ee brd ff:ff:ff:ff:ff:ff
inet 10.96.0.10/32 brd 10.96.0.10 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.96.0.1/32 brd 10.96.0.1 scope global kube-ipvs0
valid_lft forever preferred_lft forever
6: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
link/ether de:e9:d8:e2:14:65 brd ff:ff:ff:ff:ff:ff
inet 10.244.0.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
inet6 fe80::dce9:d8ff:fee2:1465/64 scope link
valid_lft forever preferred_lft forever
7: flannel0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1472 qdisc pfifo_fast state UNKNOWN group default qlen 500
link/none
inet 10.244.0.0/32 scope global flannel0
valid_lft forever preferred_lft forever
inet6 fe80::e972:9e58:b895:774/64 scope link flags 800
valid_lft forever preferred_lft forever
8: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1472 qdisc noqueue state UP group default qlen 1000
link/ether f6:73:f7:ea:03:8a brd ff:ff:ff:ff:ff:ff
inet 10.244.0.1/24 brd 10.244.0.255 scope global cni0
valid_lft forever preferred_lft forever
inet6 fe80::f473:f7ff:feea:38a/64 scope link
valid_lft forever preferred_lft forever
10: veth6a5fe3d9@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1472 qdisc noqueue master cni0 state UP group default
link/ether 26:dd:aa:d6:0e:e7 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::24dd:aaff:fed6:ee7/64 scope link
valid_lft forever preferred_lft forever
[root@master ~]# ip netns exec ns2 ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
11: veth1@if12: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 56:ce:8d:a5:ef:af brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.1.1.3/24 scope global veth1
valid_lft forever preferred_lft forever
inet6 fe80::54ce:8dff:fea5:efaf/64 scope link
valid_lft forever preferred_lft forever
[root@master ~]# ip netns exec ns1 ping 10.1.1.3
PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data.
64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.061 ms
64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.063 ms
c64 bytes from 10.1.1.3: icmp_seq=3 ttl=64 time=0.041 ms
使用tcpdump进行抓包分析
[root@master ~]# ip netns exec ns1 tcpdump -n -e -i veth0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth0, link-type EN10MB (Ethernet), capture size 262144 bytes
13:27:10.608741 96:52:7a:b3:f5:ef > 56:ce:8d:a5:ef:af, ethertype IPv4 (0x0800), length 98: 10.1.1.2 > 10.1.1.3: ICMP echo request, id 39136, seq 1, length 64
13:27:10.608781 56:ce:8d:a5:ef:af > 96:52:7a:b3:f5:ef, ethertype IPv4 (0x0800), length 98: 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 39136, seq 1, length 64
13:27:11.610111 96:52:7a:b3:f5:ef > 56:ce:8d:a5:ef:af, ethertype IPv4 (0x0800), length 98: 10.1.1.2 > 10.1.1.3: ICMP echo request, id 39136, seq 2, length 64
13:27:11.610138 56:ce:8d:a5:ef:af > 96:52:7a:b3:f5:ef, ethertype IPv4 (0x0800), length 98: 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 39136, seq 2, length 64
13:27:12.609654 96:52:7a:b3:f5:ef > 56:ce:8d:a5:ef:af, ethertype IPv4 (0x0800), length 98: 10.1.1.2 > 10.1.1.3: ICMP echo request, id 39136, seq 3, length 64
13:27:12.609780 56:ce:8d:a5:ef:af > 96:52:7a:b3:f5:ef, ethertype IPv4 (0x0800), length 98: 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 39136, seq 3, length 64
13:27:13.611400 96:52:7a:b3:f5:ef > 56:ce:8d:a5:ef:af, ethertype IPv4 (0x0800), length 98: 10.1.1.2 > 10.1.1.3: ICMP echo request, id 39136, seq 4, length 64
13:27:13.611425 56:ce:8d:a5:ef:af > 96:52:7a:b3:f5:ef, ethertype IPv4 (0x0800), length 98: 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 39136, seq 4, length 64
13:27:14.611247 96:52:7a:b3:f5:ef > 56:ce:8d:a5:ef:af, ethertype IPv4 (0x0800), length 98: 10.1.1.2 > 10.1.1.3: ICMP echo request, id 39136, seq 5, length 64
13:27:14.611306 56:ce:8d:a5:ef:af > 96:52:7a:b3:f5:ef, ethertype IPv4 (0x0800), length 98: 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 39136, seq 5, length 64
13:27:15.612292 96:52:7a:b3:f5:ef > 56:ce:8d:a5:ef:af, ethertype IPv4 (0x0800), length 98: 10.1.1.2 > 10.1.1.3: ICMP echo request, id 39136, seq 6, length 64
13:27:15.612314 56:ce:8d:a5:ef:af > 96:52:7a:b3:f5:ef, ethertype IPv4 (0x0800), length 98: 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 39136, seq 6, length 64


通过验证是这两个名称空间的网卡是通过veth peer来进行通信,通过tcpdump进行抓包是通过内核抓包。
Kubernetes CNI Flannel Pod - Pod Communication[Same Node][UDP Mode]
Pod - Pod[Same Node]:通常情况下,在Flannel上解决同节点Pod之间的通信依赖的是Linux Bridge,和我们在Docker中不同的是,在Kubernetes Flannel的环境中使用的Linux Bridge为cni0,而不是原来的docker0。
可通过:brctl show查看对应的Linux Bridge的bridge name和interfaces。
相同节点不同pod如何通信(POD测试)
[root@node ~]# kubectl get pods -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
bb-5767fb4df4-jsn9s 1/1 Running 0 26s 10.244.1.6 node <none> <none>
cc-6785cd79fd-l5r2s 1/1 Running 0 44m 10.244.0.3 master <none> <none>
nettoolbox-6cd998555d-h48b9 1/1 Running 0 44m 10.244.1.5 node <none> <none>
[root@node ~]# kubectl exec -it bb-5767fb4df4-jsn9s ping 10.244.1.5
PING 10.244.1.5 (10.244.1.5): 56 data bytes
64 bytes from 10.244.1.5: seq=0 ttl=64 time=0.196 ms
64 bytes from 10.244.1.5: seq=1 ttl=64 time=0.090 ms
^C
--- 10.244.1.5 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.090/0.143/0.196 ms
[root@node ~]#

抓包
[root@node ~]# kubectl exec -it bb-5767fb4df4-jsn9s -- tcpdump -n -e -i eth0
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
05:44:41.218336 72:ae:f1:b5:af:dc > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 10.244.1.5 tell 10.244.1.6, length 28
05:44:41.218343 72:ae:f1:b5:af:dc > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 10.244.1.5 tell 10.244.1.6, length 28
05:44:41.218361 e6:ea:b8:35:c3:35 > 72:ae:f1:b5:af:dc, ethertype ARP (0x0806), length 42: Reply 10.244.1.5 is-at e6:ea:b8:35:c3:35, length 28
05:44:41.218363 72:ae:f1:b5:af:dc > e6:ea:b8:35:c3:35, ethertype IPv4 (0x0800), length 98: 10.244.1.6 > 10.244.1.5: ICMP echo request, id 3584, seq 0, length 64
05:44:41.218472 e6:ea:b8:35:c3:35 > 72:ae:f1:b5:af:dc, ethertype IPv4 (0x0800), length 98: 10.244.1.5 > 10.244.1.6: ICMP echo reply, id 3584, seq 0, length 64
05:44:42.219660 72:ae:f1:b5:af:dc > e6:ea:b8:35:c3:35, ethertype IPv4 (0x0800), length 98: 10.244.1.6 > 10.244.1.5: ICMP echo request, id 3584, seq 1, length 64
05:44:42.219700 e6:ea:b8:35:c3:35 > 72:ae:f1:b5:af:dc, ethertype IPv4 (0x0800), length 98: 10.244.1.5 > 10.244.1.6: ICMP echo reply, id 3584, seq 1, length 64
05:44:46.231953 e6:ea:b8:35:c3:35 > 72:ae:f1:b5:af:dc, ethertype ARP (0x0806), length 42: Request who-has 10.244.1.6 tell 10.244.1.5, length 28
05:44:46.231962 72:ae:f1:b5:af:dc > e6:ea:b8:35:c3:35, ethertype ARP (0x0806), length 42: Reply 10.244.1.6 is-at 72:ae:f1:b5:af:dc, length 28

Srcip-10.244.1.6 有>Desip-10.244.1.5有
Src-mac(72:ae:f1:b5:af:dc)有>Dst-mac未知 (广播macff:ff:ff:ff:ff:ff) ARP会广播出来,谁有这个10.244.1.5。一来一回完成了由arp解析到icmp的整个环。
第二次进行icmp ping测的时候,发现目的mac不是全ffffff的mac地址了
MAC(Media Access Control)地址用来定义网络设备的位置。MAC地址由48比特长、12位的16进制数字组成其中从左到右开始,0到23bit是厂商向IETF等机构申请用来标识厂商的代码(OUI),24到47bit由厂商自行分派,是各个厂商制造的所有网卡的一个唯一编号。
MAC地址可以分为3种类型:
⚫ 物理MAC地址:这种类型的MAC地址唯一的标识了以太网上的一个终端,该地址为全球唯一的硬件地址。
⚫ 广播MAC地址:全1的MAC地址(FF-FF-FF-FF-FF-FF),用来表示LAN上的所有终端设备。
⚫ 组播MAC地址:除广播地址外,第8bit为1的MAC地址为组播MAC地址(例如01-00-00-00-00-00),用来代表LAN上的一组终端。
静态MAC地址(Static MAC)
1、由用户通过命令配置的静态转发的MAC地址,静态MAC地址和动态MAC地址的功能不同 ,静态地址一旦被加入,该地址在删除之前将一直有效,不受最大老化时间的限制。
2、动态MAC地址(Dynamic MAC)
由交换机从接受到报文自动学习到的MAC地址,当端口收到一个报文时,会查找报文的源MAC地址是否存 在于MAC地址表中,如果不存在则会将相应的端口、VLAN和源MAC地址关联起来,并保存到MAC地址表中, 动态MAC地址在达到一定老化时间后会被老化删除,但如果该地址在老化时间内被正确使用过,则会重新 激活该条地址的老化时间,同时MAC地址和端口的对应关系会随着设备所连的交换机的端口的变化而变化。
3、过滤MAC地址、黑洞MAC地址
由用户通过命令配置的静态过滤的MAC地址,当网关接收到的报文中,源或者目的MAC 地址为过滤MAC地址,则直接丢弃该报文。
ARP Request Packet Format:
[root@node ~]# brctl showmacs cni0
port no mac addr is local? ageing timer
2 4e:8a:b7:f1:4b:05 yes 0.00
2 4e:8a:b7:f1:4b:05 yes 0.00
2 6a:00:0a:f2:62:64 no 0.17
3 6e:ca:62:74:e8:37 yes 0.00
3 6e:ca:62:74:e8:37 yes 0.00
3 72:ae:f1:b5:af:dc no 25.28 POD1
4 92:8b:7c:e2:04:18 yes 0.00
4 92:8b:7c:e2:04:18 yes 0.00
1 ce:26:a9:80:f8:3e yes 0.00
1 ce:26:a9:80:f8:3e yes 0.00
4 e6:ea:b8:35:c3:35 no 25.28 POD2
1 fa:8b:31:f4:03:f5 no 0.17
[root@node ~]#
 类似于交换机上面的3口4口。
类似于交换机上面的3口4口。
基于华为ensp+wireshark抓包工具

<Huawei>dis mac-address
MAC address table of slot 0:
-------------------------------------------------------------------------------
MAC Address VLAN/ PEVLAN CEVLAN Port Type LSP/LSR-ID
VSI/SI MAC-Tunnel
-------------------------------------------------------------------------------
5489-98e7-75c0 1 - - Eth0/0/1 dynamic 0/-
5489-98d4-231c 1 - - Eth0/0/2 dynamic 0/-
-------------------------------------------------------------------------------
Total matching items on slot 0 displayed = 2
同节点不同pod之间的通信
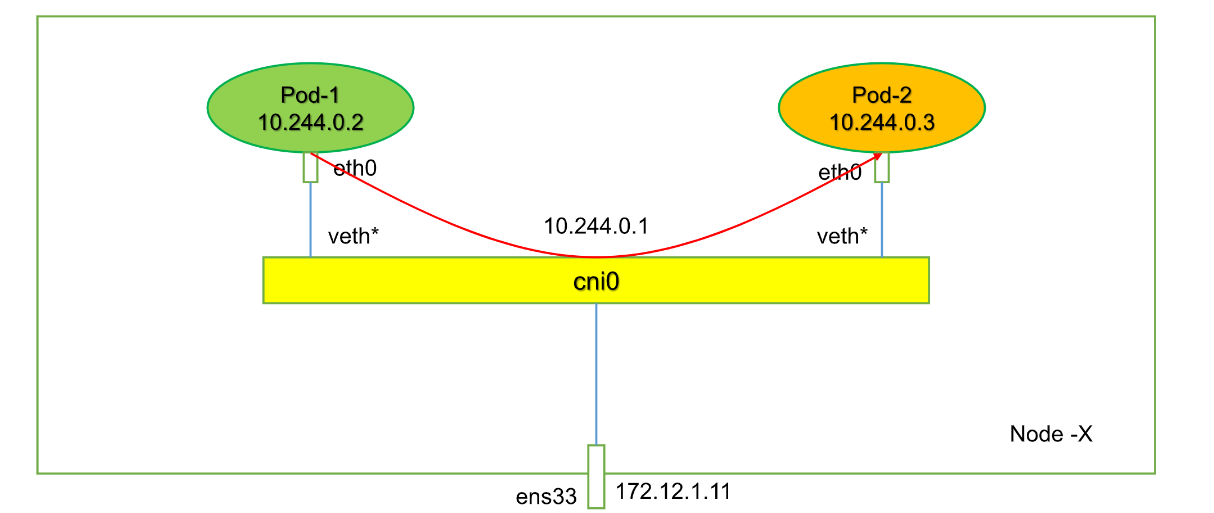
同节点不同Pod之间的通信:
/#/ 有一个前提,我们在iconfig中看到的网卡都是在内核级别的,或是说在内核这个层面。
Pod - Pod[Same Node]:通常情况下,在Flannel上解决同节点Pod之间的通信依赖的是Linux Bridge,和我们在Docker中不同的是,在Kubernetes Flannel的环境中使用的Linux Bridge为cni0,而不是原来的docker0。
可通过:brctl show查看对应的Linux Bridge的bridge name和interfaces。
[root@k8s-1 ~]# brctl show
bridge name bridge id STP enabled interfaces
cni0 8000.1edb12e1c079 no veth54a9e98a # cni0 为Linux下的一个虚拟Bridge。
docker0 8000.0242da0ca579 no
[root@k8s-1 ~]#
此时我们看到一端在ROOT NS中的一个接口,而Pod中的eth0中的接口在Pod所在的namespace中。此时两者之间有通信的需求,何种方案比较合适呢?--- #[veth pair]
其中veth device(pair)的定义为:
# The veth devices are virtual Ethernet devices. They can act as tunnels between network namespaces。topo like below:
APP APP
| |
| |
kernel ------------------------------ kernel
| |
network stack network stack
| |
|______________________________|
veth-m veth-n
#
对于此种模式我们普通Linux中是怎么实现呢?
#5.2.1:创建 namespace
ip netns a ns1
ip netns a ns2
#5.2.2:创建一对 veth-pair veth0 veth1
ip l a veth0 type veth peer name veth1
#5.2.3:将 veth0 veth1 分别加入两个 ns
ip l s veth0 netns ns1
ip l s veth1 netns ns2
#5.2.4:给两个 veth0 veth1 配上 IP 并启用
ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0
ip netns exec ns1 ip l s veth0 up
ip netns exec ns2 ip a a 10.1.1.3/24 dev veth1
ip netns exec ns2 ip l s veth1 up
# veth0 ping veth1
[root@k8s-1 ~]# ip netns exec ns1 ping 10.1.1.3
PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data.
64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.060 ms
/
此时需要弄清楚两个问题:
1.此时如何知道Pod中的eth0的pair是谁?
2.此时由Pod-1进入内核,如果想要把数据包转发给另外一个Pod-2?
#1.使用ethtool -S eth0
[root@k8s-1 ~]# kubectl exec -it cni-59h6g bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
bash-5.1# ethtool -S eth0
NIC statistics:
peer_ifindex: 6 ##此时在Pod中查看peer的index为6.我们可以在ROOT NS中查看,ifindex为6的网卡。
rx_queue_0_xdp_packets: 0
rx_queue_0_xdp_bytes: 0
rx_queue_0_drops: 0
rx_queue_0_xdp_redirect: 0
rx_queue_0_xdp_drops: 0
rx_queue_0_xdp_tx: 0
rx_queue_0_xdp_tx_errors: 0
tx_queue_0_xdp_xmit: 0
tx_queue_0_xdp_xmit_errors: 0
bash-5.1# exit
exit
[root@k8s-1 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:bd:fb:4a brd ff:ff:ff:ff:ff:ff
inet 172.12.1.11/24 brd 172.12.1.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::e222:32bb:f400:f0c3/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:da:0c:a5:79 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
4: flannel0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1472 qdisc pfifo_fast state UNKNOWN group default qlen 500
link/none
inet 10.244.0.0/32 brd 10.244.0.0 scope global flannel0
valid_lft forever preferred_lft forever
inet6 fe80::9af7:c926:3592:e41f/64 scope link flags 800
valid_lft forever preferred_lft forever
5: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1472 qdisc noqueue state UP group default qlen 1000
link/ether 1e:db:12:e1:c0:79 brd ff:ff:ff:ff:ff:ff
inet 10.244.0.1/24 brd 10.244.0.255 scope global cni0
valid_lft forever preferred_lft forever
inet6 fe80::1cdb:12ff:fee1:c079/64 scope link
valid_lft forever preferred_lft forever
6: veth54a9e98a@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1472 qdisc noqueue master cni0 state UP group default # 这里的ifindex为6.
link/ether 66:c5:ab:c8:03:4e brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::64c5:abff:fec8:34e/64 scope link
valid_lft forever preferred_lft forever
[root@k8s-1 ~]#
[root@k8s-1 ~]# brctl show
bridge name bridge id STP enabled interfaces
cni0 8000.1edb12e1c079 no veth54a9e98a # 此时该接口是在cni0这个bridge上。
docker0 8000.0242da0ca579 no
[root@k8s-1 ~]#
下边以两个在同一个节点上的两个Pod的情况分析:
# network topo:
10.244.1.10 10.244.1.7
[ns1] [ns2]
| |
-- [cni0] --
#
[root@k8s-1 ~]# kubectl get pods -o wide | grep k8s-2
cc 1/1 Running 0 32h 10.244.1.10 k8s-2 <none> <none>
cni-svtwf 1/1 Running 1 109d 10.244.1.7 k8s-2 <none> <none>
[root@k8s-1 ~]#
在pod cni-svtwf中去ping cc这个pod。抓包显示为:
[root@k8s-1 ~]# kubectl exec -it cni-svtwf bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
bash-5.1# tcpdump -n -e -i eth0
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
14:31:06.751041 9a:16:45:30:3a:c6 > ee:6f:75:01:ed:bb, ethertype IPv4 (0x0800), length 98: 10.244.1.7 > 10.244.1.10: ICMP echo request, id 17920, seq 0, length 64
14:31:06.751096 ee:6f:75:01:ed:bb > 9a:16:45:30:3a:c6, ethertype IPv4 (0x0800), length 98: 10.244.1.10 > 10.244.1.7: ICMP echo reply, id 17920, seq 0, length 64
^C
#从抓包可以看出,cni-svtwf 的eth0的网卡的MAC地址为:9a:16:45:30:3a:c6
cc 的eth0的网卡的MAC地址为:ee:6f:75:01:ed:bb
此时我们在cni0 bridge中查看MAC地址表:
[root@k8s-2 ~]# brctl showmacs cni0
port no mac addr is local? ageing timer
1 1e:89:b9:2c:44:b1 yes 0.00
1 1e:89:b9:2c:44:b1 yes 0.00
3 32:2e:01:1d:a1:53 yes 0.00
3 32:2e:01:1d:a1:53 yes 0.00
2 4a:bc:c1:08:30:04 no 1.70
2 5e:14:4c:e2:2b:22 yes 0.00
2 5e:14:4c:e2:2b:22 yes 0.00
3 9a:16:45:30:3a:c6 no 32.42 # 此地址对应 cni-svtwf的eht0 MAC地址,对应bridge上的端口3.
4 b2:8e:21:90:45:39 yes 0.00
4 b2:8e:21:90:45:39 yes 0.00
1 ce:22:d7:ee:59:7d no 1.70
4 ee:6f:75:01:ed:bb no 32.42 # 此地址对应cc 的eth0 的MAC地址,对应bridge上的端口4.
[root@k8s-2 ~]#
#此种Bridge模式把相应的peer建立在pod和bridge之间。此时Linux中又是如何实现呢:
# network topo:
10.1.1.2 10.1.1.3
[ns1] [ns2]
| |
-- [br0] --
#
#创建ns
ip netns a ns1
ip netns a ns2
#首先创建 bridge br0
ip l a br0 type bridge
ip l s br0 up
#然后创建两对 veth-pair
ip l a veth0 type veth peer name br-veth0
ip l a veth1 type veth peer name br-veth1
#分别将两对 veth-pair 加入两个 ns 和 br0
ip l s veth0 netns ns1
ip l s br-veth0 master br0
ip l s br-veth0 up
ip l s veth1 netns ns2
ip l s br-veth1 master br0
ip l s br-veth1 up
#给两个 ns 中的 veth 配置 IP 并启用
ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0
ip netns exec ns1 ip l s veth0 up
ip netns exec ns2 ip a a 10.1.1.3/24 dev veth1
ip netns exec ns2 ip l s veth1 up
# ping 测:
[root@k8s-2 ~]# ip netns exec ns1 ping 10.1.1.3
PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data.
64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.173 ms
64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.068 ms
^C
--- 10.1.1.3 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1020ms
rtt min/avg/max/mdev = 0.068/0.120/0.173/0.053 ms
# 查看bridge br0上的端口:
[root@k8s-2 ~]# brctl show
bridge name bridge id STP enabled interfaces
br0 8000.8e495ef498dd no br-veth0
br-veth1
# 查看对应的MAC地址和不同ns中的MAC。
[root@k8s-2 ~]# brctl showmacs br0
port no mac addr is local? ageing timer
2 06:b5:78:d9:7b:75 no 16.28 # ns2
1 1a:7e:30:46:72:11 no 12.18 # ns1
1 8e:49:5e:f4:98:dd yes 0.00
1 8e:49:5e:f4:98:dd yes 0.00
2 ca:b6:7e:6:c2:bf yes 0.00
2 ca:b6:7e:06:c2:bf yes 0.00
[root@k8s-2 ~]#
不同节点的不同pod之前的通信
物理网卡是硬件网卡,它位于硬件层,虚拟网卡则可以看作是用户空间的网卡,就像用户空间的文件系统(fuse)一样。
物理网卡和虚拟网卡唯一的不同点在于物理网卡本身的硬件功能:物理网卡以比特流的方式传输数据。也就是说,内
核会公平对待物理网卡和虚拟网卡,物理网卡能做的配置,虚拟网卡也能做。比如可以为虚拟网卡接口配置IP地址、
设置子网掩码,可以将虚拟网卡接入网桥等等。只有在数据流经物理网卡和虚拟网卡的那一刻,才会体现出它们的不
同,即传输数据的方式不同:物理网卡以比特流的方式传输数据,虚拟网卡则直接在内存中拷贝数据(即,在内核之
间和读写虚拟网卡的程序之间传输)。正因为虚拟网卡不具备物理网卡以比特流方式传输数据的硬件功能,所以,绝
不可能通过虚拟网卡向外界发送数据,外界数据也不可能直接发送到虚拟网卡上。能够直接收发外界数据的,只能是
物理设备。
虽然虚拟网卡无法将数据传输到外界网络,但却:
可以将数据传输到本机的另一个网卡(虚拟网卡或物理网卡)或其它虚拟设备(如虚拟交换机)上。
可以在用户空间运行一个可读写虚拟网卡的程序,该程序可将流经虚拟网卡的数据包进行处理,这个用户程序就
像是物理网卡的硬件功能一样,可以收发数据(可将物理网卡的硬件功能看作是嵌入在网卡上的程序),比如
OpenVPN和VTun就是这样的工具。
Note:
很多人会误解这样的用户空间程序,认为它们可以对数据进行封装。比如认为OpenVPN可以在数据包的基础上再封
装一层隧道IP首部,但这种理解是错的。
一定请注意,用户空间的程序是无法对数据包做任何封装和解封操作的,所有的封装和解封都只能由内核的网络协议
栈来完成。
使用OpenVPN之所以可对数据再封装一层隧道IP层,是因为OpenVPN可以读取已经封装过一次IP首部的数据,并将
包含ip首部的数据作为普通数据通过虚拟网卡再次传输给内核。因为内核接收到的是来自虚拟网卡的数据,所以内核
会将其当作普通数据从头开始封装(从四层封装到二层封装)。当数据从网络协议栈流出时,就有了两层IP首部的封装。
用户空间和内核空间与标准TCP/IP协议栈对应关系:用户空间的程序是无法对数据包做任何封装和解封操作的,所有的封装和解封都只能由内核的网络协议栈来完成。

tap/tun 是 Linux 内核 2.4.x 版本之后实现的虚拟网络设备,不同于物理网卡靠硬件板卡实现,tap/tun 虚拟网卡完全由软件实现,功能和硬件实现完全没差别,它们都属于网络设备,都可配置 IP,都归 Linux 网络设备管理模块统一管理。
tap/tun 提供了一台主机内用户空间的数据传输机制。它虚拟了一套网络接口,这套接口和物理的接口无任何区别,
可以配置 IP,可以路由流量,不同的是,它的流量只在主机内流通。
作为网络设备,tap/tun 也需要配套相应的驱动程序才能工作。tap/tun 驱动程序包括两个部分,一个是字符设备驱动,
一个是网卡驱动。这两部分驱动程序分工不太一样,字符驱动负责数据包在内核空间和用户空间的传送,网卡驱动负
责数据包在 TCP/IP 网络协议栈上的传输和处理。
tap/tun 有些许的不同,tun 只操作三层的 IP 包,而 tap 操作二层的以太网帧。
在 Linux 中,用户空间和内核空间的数据传输有多种方式,字符设备就是其中的一种。tap/tun 通过驱动程序和一个与
之关联的字符设备,来实现用户空间和内核空间的通信接口。
在 Linux 内核 2.6.x 之后的版本中,tap/tun 对应的字符设备文件分别为:
tap:/dev/tap0
tun:/dev/net/tun
设备文件即充当了用户空间和内核空间通信的接口。当应用程序打开设备文件时,驱动程序就会创建并注册相应的虚
拟设备接口,一般以 tunX 或 tapX 命名。当应用程序关闭文件时,驱动也会自动删除 tunX 和 tapX 设备,还会删除已
经建立起来的路由等信息。
tap/tun 设备文件就像一个管道,一端连接着用户空间,一端连接着内核空间。当用户程序向文件 /dev/net/tun 或
/dev/tap0 写数据时,内核就可以从对应的 tunX 或 tapX 接口读到数据,反之,内核可以通过相反的方式向用户程序
发送数据。
tun和tap都是虚拟网卡设备:
tun是三层设备,其封装的外层是IP头。
tap是二层设备,其封装的外层是以太网帧(frame)头。
tun是PPP点对点设备,没有MAC地址。
tap是以太网设备,有MAC地址tap比tun更接近于物理网卡,可以认为,tap设备等价于去掉了硬件功能的物理网卡。
这意味着,如果提供了用户空间的程序去收发tun/tap虚拟网卡的数据,所收发的内容是不同的。
收发tun设备的用户程序,只能间接提供封装和解封数据包的IP头的功能
收发tap设备的用户程序,只能间接提供封装和解封数据包的帧头的功能
注意,此处用词是【收发数据】而非【处理数据】,是【间接提供】而非【直接提供】,因为在不绕过内核网络
协议栈的情况下,读写虚拟网卡的用户程序是不能封装和解封数据的,只有内核的网络协议栈才能封装和解封数
据。
虚拟网卡的两个主要功能是:
连接其它设备(虚拟网卡或物理网卡)和虚拟交换机(bridge)。
提供用户空间程序去收发虚拟网卡上的数据
基于这两个功能,tap设备通常用来连接其它网络设备(它更像网卡),tun设备通常用来结合用户空间程序实现再次封
装。换句话说,tap设备通常接入到虚拟交换机(bridge)上作为局域网的一个节点,tun设备通常用来实现三层的ip隧道。
但tun/tap的用法是灵活的,只不过上面两种使用场景更为广泛。例如,除了可以使用tun设备来实现ip层隧道,使用
tap设备实现二层隧道的场景也颇为常见。
tun、tap作为虚拟网卡,除了不具备物理网卡的硬件功能外,它们和物理网卡的功能是一样的,此外tun、tap负责在
内核网络协议栈和用户空间之间传输数据。
程序 A 希望构造数据包发往 192.168.1.0/24 网段的主机 192.168.1.1。
1. 应用程序 X 构造数据包,目的 IP 是 192.168.1.1,通过 socket X 将这个数据包发给协议栈。
2. 协议栈根据数据包的目的 IP 地址,匹配路由规则,发现要从 tun0 出去。
3. tun0 发现自己的另一端被应用程序 Y 打开了,于是将数据发给程序 Y.
4. 程序 Y 收到数据后,做一些跟业务相关的操作,然后构造一个新的数据包,源 IP 是 eth0 的 IP,目的 IP 是 10.1.1.0/24 的网关 10.1.1.1,封装原来的数
据的数据包,重新发给协议栈。
5. 协议栈再根据本地路由,将这个数据包从 eth0 发出。
UDP模式下flanneld进程在启动时会通过打开/dev/net/tun的方式生成一个TUN设备(flannel0),TUN设备可以简单理解为Linux当中提供的一种内核网络与用户空间(应用程序)通信的一种机制, TUN设备的特殊性在于它可把数据包转给创建它的用户空间进程,从而实现内核到用户空间的拷贝。即可通过直接读写tun设备的方式收发RAW IP包。
[root@master ~]# netstat -nlptu | grep flanneld
udp 0 0 192.168.130.10:8285 0.0.0.0:* 22962/flanneld
flannel0: flags=4305<UP,POINTOPOINT,RUNNING,NOARP,MULTICAST> mtu 1472
inet 10.244.0.0 netmask 255.255.255.255 destination 10.244.0.0
inet6 fe80::e972:9e58:b895:774 prefixlen 64 scopeid 0x20<link>
unspec 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00 txqueuelen 500 (UNSPEC)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3 bytes 144 (144.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.0.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::dce9:d8ff:fee2:1465 prefixlen 64 scopeid 0x20<link>
ether de:e9:d8:e2:14:65 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 8 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 464419 bytes 89419120 (85.2 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 464419 bytes 89419120 (85.2 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@master ~]# ip -d link show flannel0
7: flannel0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1472 qdisc pfifo_fast state UNKNOWN mode DEFAULT group default qlen 500
link/none promiscuity 0
tun addrgenmode random numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535

不同节点之间POD如何实现通信<br />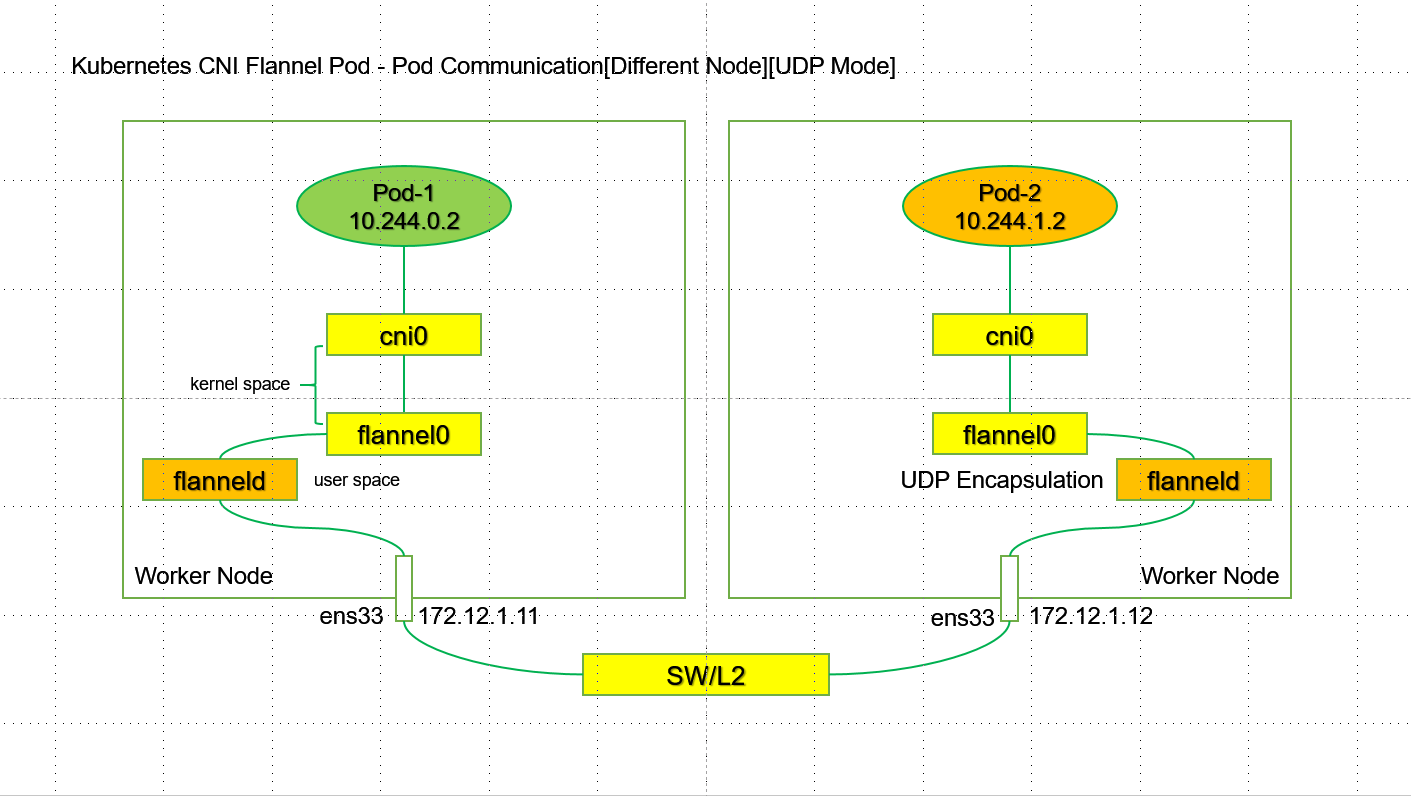
不同节点之前POD如何通信
[root@master ~]# kubectl get pods -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
aa 1/1 Running 0 12m 10.244.1.3 node <none> <none>
bb 1/1 Running 0 12m 10.244.0.3 master <none> <none> <none>
pod-aa10.244.1.3 pod-bb10.244.0.3
aa容器: 路由表为
bash-5.1# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.244.1.1 0.0.0.0 UG 0 0 0 eth0
10.244.0.0 10.244.1.1 255.255.0.0 UG 0 0 0 eth0
10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
路由匹配规则是:
1.按照最长匹配原则。
2.路由优先级 前提是同一网络 对象是不同路由协议。
3.路由度量 前提是同一网络 同一路由协议 对象是不同开销。
容器aa的mac地址:
bash-5.1# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1472 qdisc noqueue state UP group default
link/ether f6:17:d8:dc:0a:78 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.244.1.3/24 brd 10.244.1.255 scope global eth0
valid_lft forever preferred_lft forever
bash-5.1#
容器bb的mac地址:
bash-5.1# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1472 qdisc noqueue state UP group default
link/ether fa:f7:7a:f9:7b:d6 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.244.0.3/24 brd 10.244.0.255 scope global eth0
valid_lft forever preferred_lft forever
S_ip D_ip S_Mac D_Mac四元组,进行三层转发的时候S_ip跟D_ip不会变,而Mac一直变。
aa_ip bb_ip aa_mac (bb_Mac??)
master节点: mac地址为fe80::a8ac:56ff:fe2e:fc3b
进行抓包ping测
[root@master ~]# kubectl exec -it aa ping 10.244.0.3
[root@master ~]# kubectl exec -it aa -- tcpdump -n -e -i eth0
[root@master ~]# kubectl exec -it aa -- tcpdump -n -e -i eth0
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
03:23:56.808045 f6:17:d8:dc:0a:78 > 82:e8:46:c2:89:63, ethertype IPv4 (0x0800), length 98: 10.244.1.3 > 10.244.0.3: ICMP echo request, id 7680, seq 0, length 64
03:23:56.808478 82:e8:46:c2:89:63 > f6:17:d8:dc:0a:78, ethertype IPv4 (0x0800), length 98: 10.244.0.3 > 10.244.1.3: ICMP echo reply, id 7680, seq 0, length 64
03:23:57.808217 f6:17:d8:dc:0a:78 > 82:e8:46:c2:89:63, ethertype IPv4 (0x0800), length 98: 10.244.1.3 > 10.244.0.3: ICMP echo request, id 7680, seq 1, length 64
03:23:57.808557 82:e8:46:c2:89:63 > f6:17:d8:dc:0a:78, ethertype IPv4 (0x0800), length 98: 10.244.0.3 > 10.244.1.3: ICMP echo reply, id 7680, seq 1, length 64
目的mac是cni0也就是路由表Gateway的mac地址
到达宿主机以后,宿主机启动路由表查询过程
[root@master ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.4.1 0.0.0.0 UG 0 0 0 eth0
10.0.4.0 0.0.0.0 255.255.252.0 U 0 0 0 eth0
10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.0.0 0.0.0.0 255.255.0.0 U 0 0 0 flannel0
10.244.1.0 10.244.1.0 255.255.255.0 UG 0 0 0 flannel.1
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker
Flannel0为tun设备,发送给flannel0接口的RAW IP包(无MAC信息)将被flanneld进程接收到,flanneld进程接收到RAW IP包后在原有的基础上进行UDP封包.UDP封包的形式为:src_ip:src port -> 10.0.4.2:8285
[root@master ~]# netstat -nlptu | grep 8285
udp 0 0 10.0.4.2:8285 0.0.0.0:* 14189/flanneld
此时在flannel上抓包:
[root@master ~]# tcpdump -n -e -i flannel.1
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on flannel.1, link-type EN10MB (Ethernet), capture size 262144 bytes
12:29:11.697201 26:7e:4a:b7:2f:0f > 52:6d:93:c5:85:ae, ethertype IPv4 (0x0800), length 98: 10.244.1.3 > 10.244.0.3: ICMP echo request, id 14848, seq 31, length 64
12:29:11.697258 52:6d:93:c5:85:ae > 26:7e:4a:b7:2f:0f, ethertype IPv4 (0x0800), length 98: 10.244.0.3 > 10.244.1.3: ICMP echo reply, id 14848, seq 31, length 64
12:29:12.697382 26:7e:4a:b7:2f:0f > 52:6d:93:c5:85:ae, ethertype IPv4 (0x0800), length 98: 10.244.1.3 > 10.244.0.3: ICMP echo request, id 14848, seq 32, length 64
12:29:12.697464 52:6d:93:c5:85:ae > 26:7e:4a:b7:2f:0f, ethertype IPv4 (0x0800), length 98: 10.244.0.3 > 10.244.1.3: ICMP echo reply, id 14848, seq 32, length 64
12:29:13.697570 26:7e:4a:b7:2f:0f > 52:6d:93:c5:85:ae, ethertype IPv4 (0x0800), length 98: 10.244.1.3 > 10.244.0.3: ICMP echo request, id 14848, seq 33, length 64
12:29:13.697616 52:6d:93:c5:85:ae > 26:7e:4a:b7:2f:0f, ethertype IPv4 (0x0800), length 98: 10.244.0.3 > 10.244.1.3: ICMP echo reply, id 14848, seq 33, length 64
12:29:14.697680 26:7e:4a:b7:2f:0f > 52:6d:93:c5:85:ae, ethertype IPv4 (0x0800), length 98: 10.244.1.3 > 10.244.0.3: ICMP echo request, id 14848, seq 34, length 64
12:29:14.697728 52:6d:93:c5:85:ae > 26:7e:4a:b7:2f:0f, ethertype IPv4 (0x0800), length 98: 10.244.0.3 > 10.244.1.3: ICMP echo reply, id 14848, seq 34, length 64
flanneld在启动时会将该节点的网络信息通过api-server保存到etcd当中,故在发送报文时可以通过查询etcd得到bb这个容器的IP属于10.0.4.2。
flanneld将封装好的UDP报文从用户空间发往Linux内核协议栈,然后经ens33发出,从这里可以看出网络包在通过ens33发出前先是加上了UDP头(8个字节),再然后加上了IP头(20个字节)进行封装,这也是为什么flannel0的MTU要比ens33的MTU小28个字节的原因(防止封装后的以太网帧超过ens33的MTU而在经过ens33时被丢弃
此过程中flanneld的作用:
# UDP封包解包
# 节点上的路由表的动态更新

若有收获,就点个赞吧
0 人点赞
