浏览器渲染过程
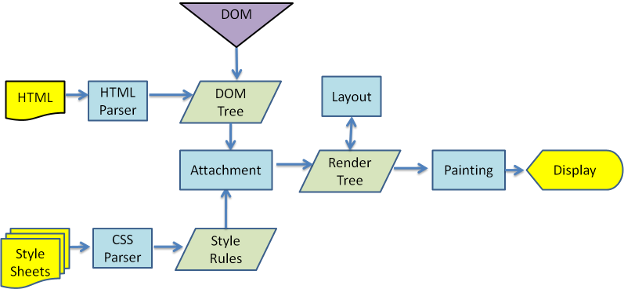
首先,下载html文件,然后通过浏览器内核中的parser解析htm文件中的标签,转换成DOM树。然后会下载css文件,再通过浏览器内核中的parser解析成css规则,然后会将DOM树和CSS规则结合到一起,生成渲染树(Render Tree)。再通过浏览器的布局引擎进行布局生成最终的渲染树(Render Tree),接着进行绘制,生成页面。
如果在执行过程中,HTML解析的时候遇到了JavaScript标签,应该怎么办呢?
- 会停止解析HTML,而去加载和执行JavaScript代码
为什么不直接异步去加载执行JavaScript代码,而要在这里停止掉呢?
- 这是因为JavaScript代码可以操作我们的DOM
- 所以浏览器希望将HTML解析的DOM和JavaScript操作之后的DOM放到一起来生成最终的DOM树,而不是频繁的去生成新的DOM树
那么,JavaScript代码由谁来执行呢?
-
JavaScript引擎
为什么需要JavaScript引擎?
实际上我们编写的JavaScript代码无论是浏览器执行还是Node执行,最后都是要被CPU执行的
- 但是CPU只认识自己的指令集,实际上是机器语言,才能被CPU所执行
- 所以我们需要JavaScript引擎帮助我们将JavaScript代码翻译成CPU指令来执行
比较常见的JavaScript引擎有哪些?
- SpiderMonkey:第一款JavaScript引擎,由JavaScript作者编写
- Chakra:微软开发,用于IE浏览器
- JavaScriptCore:WebKit中的JavaScript引擎,Apple公司开发
V8:Google开发的强大的JavaScript引擎,帮助Chrome脱颖而出
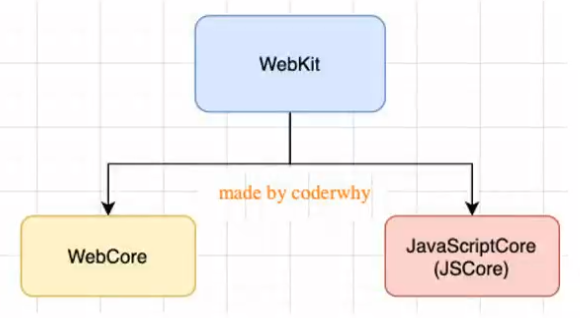
浏览器内核和JS引擎的关系
以WebKit为例,WebKit事实上分为两部分:
WebCore:负责HTML解析、布局、渲染等等相关工作
- JavaScriptCore:解析、执行JavaScript代码
V8引擎的原理
官方对V8引擎的定义:
- V8是用C++编写的Google开源的高性能JavaScript和WebAssembly引擎,用于Chrome和Node.js等
- 它实现EcmaScript和WebAssembly,并在windows7或更高版本,macOS10.12+和使用x64,IA-32,ARM或MIPS处理器的Linux系统上运行
- V8可以独立运行,也可以嵌入到任何C++应用程序中
- V8就是引擎名称,不是版本名,所以没有V9,V10之类的
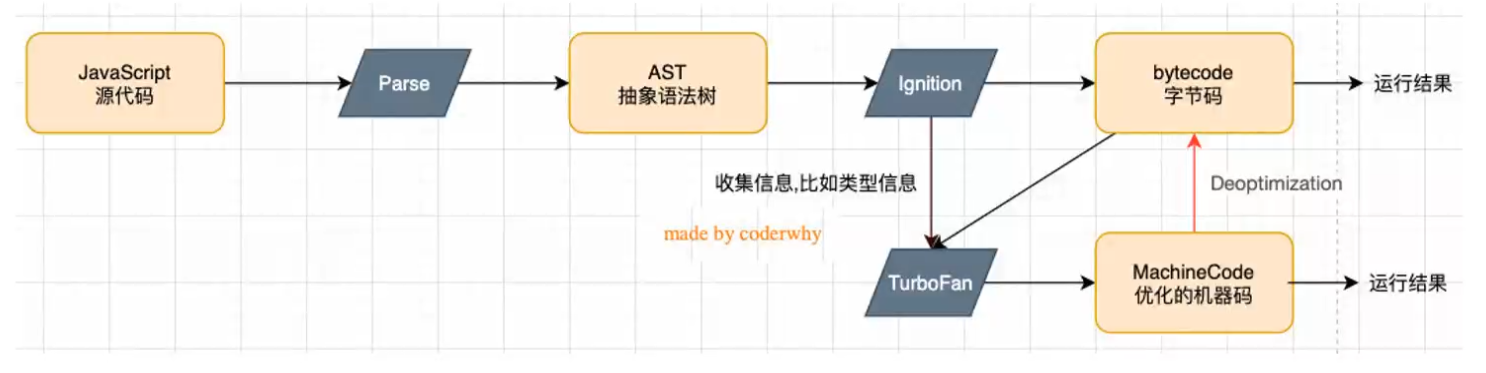
V8引擎本身的源码非常复杂,大概有超过100W行C++代码,但是我们可以简单了解一下它执行JavaScript代码的原理:
Parse模块会将JavaScript代码转换成AST(抽象语法树),这是因为解释器并不直接认识JavaScript代码
- 如果函数没有被调用,那么是不会被转换成AST的
Ignition是一个解释器,会将AST转换成ByteCode(字节码)
- 同时会收集TurboFan优化所需要的信息(比如函数参数的类型信息,有了类型才能进行真实的运算)
- 如果函数只调用一次,Ignition会执行解释执行ByteCode
TurboFan是一个编译器,可以将字节编译为CPU可以直接执行的机器码
- 如果一个函数被多次调用,那么就会被标记为热点函数,那么就会经过TurboFan转换成优化后的机器码,提高代码的执行性能
- 但是,机器码实际上也可能会被还原为ByteCode,这是因为如果后续执行函数的过程中,类型发生了变化(比如sum函数原来执行的是number类型,后代执行变成了string类型),之前优化的机器码并不能正确的处理运算,就会逆向的转换成字节码
V8引擎解析图(官方)
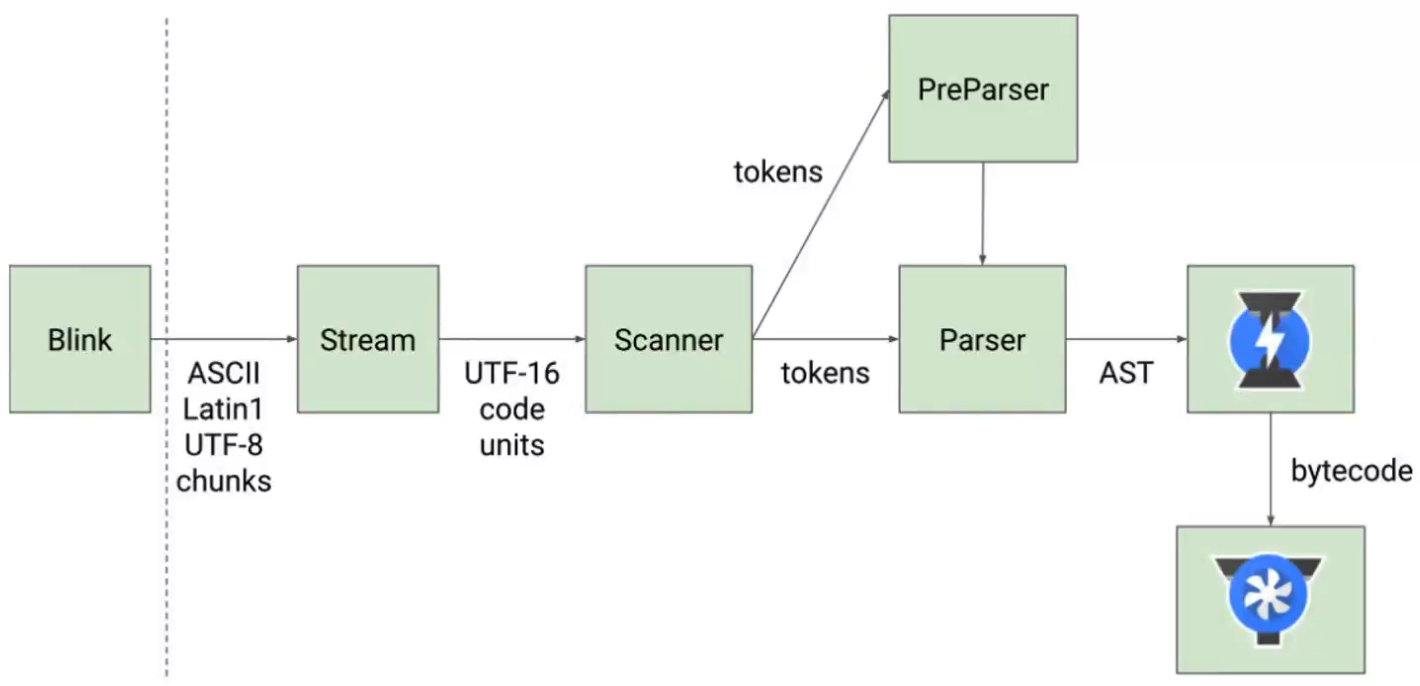
这张图中,闪电标志的图标代表的是上图中的Ignition,也就是解释器,用于将parse解析出的token转换成字节码;而下方的风扇样式的图标代表的是上图中的turbofan,也就是解码器,用于将ignition解析出的字节码转换为计算机能够理解的机器码。
模块介绍:
- Blink:Blink引擎,它会加载HTML文件,当加载到JS文件时,它会以流的形式把不同编码规则的JS文件传递给Scanner
- Scanner:扫描器,用于做词法分析,词法分析后会将JS转换成一个个tokens传递给Parser
- Parser:解析器,用于将得到的tokens转换成AST(抽象语法树)
- Ignition:解释器,用于将AST转换成字节码(bytecode),字节码是一种跨平台的机器码抽象。
- 有人可能会好奇,既然计算机最后只能识别机器码,那书写代码时书写机器码非常不现实,但是我们可以在编译代码的时候将JS代码直接转换成机器码啊,为什么要先转换成字节码呢?这不是多此一举吗?
- 因为直接转换成机器码会非常的大,占据非常多的内存
- 代码复杂度太高:不同的CPU架构对应的指令集是完全不同的,而市面上CPU架构的种类又非常多,那么将AST转化为二进制代码的Full-Codegen引擎以及优化编译的Crankshaft引擎要针对不同的CPU架构编写代码,这个复杂程度及工作量可想而知,而对字节码进行编译可以大大的减少这个工作量
- Turbofan:解码器,用于将字节码转换成机器码,让计算机能够读懂。
这张图比起上一张图,还多了一个PreParser(预解析)的部分:
- PreParser称之为预解析,为什么需要预解析呢?
- 这是因为并不是所有的JS代码,在一开始就会被执行。那么对所有的JS代码进行解析,必然会影响网页性能。
- 所以V8引擎就实现了LazyParsing(延迟解析)的方案,它的作用是将不必要的函数进行预解析,也就是只解析暂时需要的内容,而对函数的全量解析是在函数被调用时才会进行
- 比如我们在一个函数outer内部定义了另外一个函数inner,那么inner函数就会进行预解析

若有收获,就点个赞吧
0 人点赞
