闭包定义
结合了函数和作用域的一个普通概念
闭包是自带运行环境的函数
闭包的核心就是延迟垃圾回收机制
- 从理论角度:所有的函数。因为它们都在创建的时候就将上层上下文的数据保存起来了。哪怕是简单的全局变量也是如此,因为函数中访问全局变量就相当于是在访问自由变量,这个时候使用最外层的作用域。
函数体内部的变量都可以保存在函数作用域内,这种特性称为闭包,技术上说所有的函数都是闭包。 - 从实践角度:以下函数才算是闭包:
- 即使创建它的上下文已经销毁,它仍然存在(比如,内部函数从父函数中返回)
- 在代码中引用了自由变量
如果定义函数时的作用域链和调用函数时闭包所指向的作用域链不相同的话,
也就是一个函数嵌套了另外一个函数,外部函数将嵌套的函数作为返回值返回。
mDN的定义: 闭包是指那些能够访问自由变量的函数。
自由变量:自由变量是指在函数中使用的,但既不是函数参数也不是函数的局部变量的变量。
闭包 = 函数 + 函数能够访问的自由变量
闭包的作用
- 可以从外部读取函数内的变量?通过作用域,这些变量的值始终保持在内存中。
var scope = "global scope";function checkscope(){var scope = "local scope";function f(){return scope;}return f;}var foo = checkscope();foo();fContext = {Scope: [AO, checkscopeContext.AO, globalContext.VO],}
就是因为这个作用域链,f 函数依然可以读取到 checkscopeContext.AO 的值,说明当 f 函数引用了 checkscopeContext.AO 中的值的时候,即使 checkscopeContext 被销毁了,但是 JavaScript 依然会让 checkscopeContext.AO 活在内存中,f 函数依然可以通过 f 函数的作用域链找到它,正是因为 JavaScript 做到了这一点,从而实现了闭包这个概念。
调用了函数后,该函数的执行环境的作用域链会被销毁,但是它的活动对象留在内存,作用域链仍然在引用。
优化
在 V8引擎会尝试回收被闭包占用的内存
推荐做法
在闭包使用完之后,置为 null,通知垃圾回收程序将其内存清除
闭包与变量
闭包只能取得包含函数中任何变量的最 后一个值,
别忘了闭包所保存的是整个变量对象,而不是某个特殊的变量
function createFunctions(){ var result = new Array();for (var i=0; i < 10; i++){result[i] = function(){return i;};}return result;}
function createFunctions(){ var result = new Array();for (var i=0; i < 10; i++){result[i] = function(num){return function(){return num;};}(i);}return result;}
我们没有直接把闭包赋值给数组,而是定义了一个匿名函数,并将立即执行该匿名函数的结果赋 给数组。这里的匿名函数有一个参数 num,也就是最终的函数要返回的值。在调用每个匿名函数时,我 们传入了变量 i。由于函数参数是按值传递的,所以就会将变量 i 的当前值复制给参数 num。而在这个 匿名函数内部,又创建并返回了一个访问 num 的闭包。
function createFunctions(){ var result = new Array();for (let i=0; i < 10; i++){ result[i] = function(){return i; };}return result;}
例子
function foo() {var myName = " 极客时间 "let test1 = 1const test2 = 2var innerBar = {setName:function(newName){myName = newName},getName:function(){console.log(test1)return myName}}return innerBar}var bar = foo()bar.setName(" 极客邦 ")bar.getName()console.log(bar.getName())复制代码
当执行这段代码的时候,你应该有过这样的分析:由于变量 myName、test1、test2 都是原始类型数据,所以在执行 foo 函数的时候,它们会被压入到调用栈中;当 foo 函数执行结束之后,调用栈中 foo 函数的执行上下文会被销毁,其内部变量 myName、test1、test2 也应该一同被销毁。
我们介绍了当 foo 函数的执行上下文销毁时,由于 foo 函数产生了闭包,所以变量 myName 和 test1 并没有被销毁,而是保存在内存中,那么应该如何解释这个现象呢?
要解释这个现象,我们就得站在内存模型的角度来分析这段代码的执行流程。
- 当 JavaScript 引擎执行到 foo 函数时,首先会编译,并创建一个空执行上下文。
- 在编译过程中,遇到内部函数 setName,JavaScript 引擎还要对内部函数做一次快速的词法扫描,发现该内部函数引用了 foo 函数中的 myName 变量,由于是内部函数引用了外部函数的变量,所以 JavaScript 引擎判断这是一个闭包,于是在堆空间创建换一个“closure(foo)”的对象(这是一个内部对象,JavaScript 是无法访问的),用来保存 myName 变量。
- 接着继续扫描到 getName 方法时,发现该函数内部还引用变量 test1,于是 JavaScript 引擎又将 test1 添加到“closure(foo)”对象中。这时候堆中的“closure(foo)”对象中就包含了 myName 和 test1 两个变量了。
- 由于 test2 并没有被内部函数引用,所以 test2 依然保存在调用栈中。
通过上面的分析,我们可以画出执行到 foo 函数中“return innerBar”语句时的调用栈状态,如下图所示: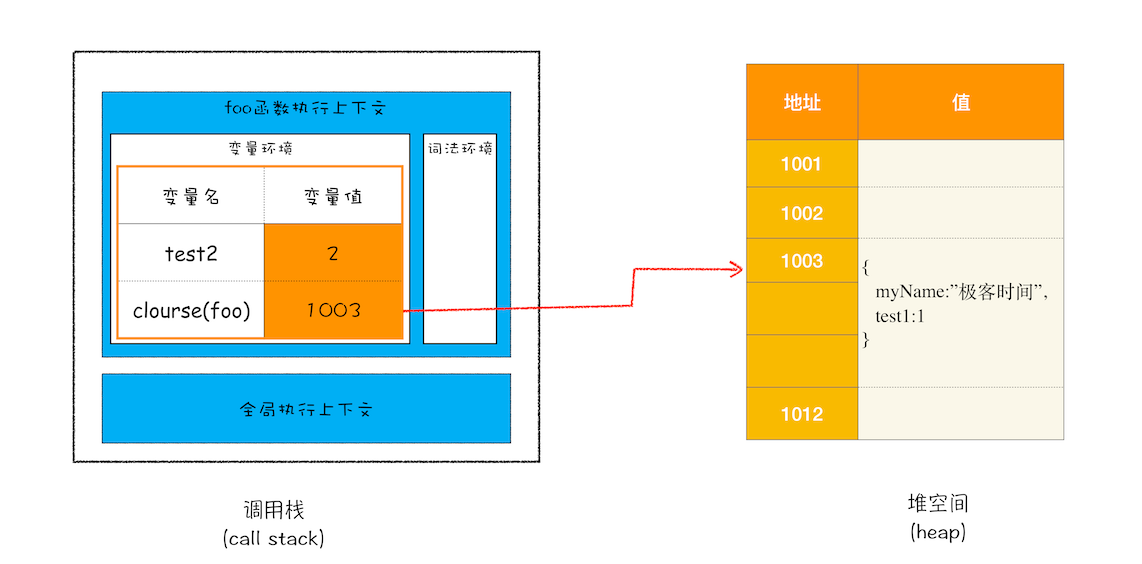
闭包的产生过程
从上图你可以清晰地看出,当执行到 foo 函数时,闭包就产生了;当 foo 函数执行结束之后,返回的 getName 和 setName 方法都引用“clourse(foo)”对象,所以即使 foo 函数退出了,“clourse(foo)”依然被其内部的 getName 和 setName 方法引用。所以在下次调用bar.setName或者bar.getName时,创建的执行上下文中就包含了“clourse(foo)”。
总的来说,产生闭包的核心有两步:第一步是需要预扫描内部函数;第二步是把内部函数引用的外部变量保存到堆中。

若有收获,就点个赞吧
0 人点赞
