这里我们要清楚,我们编写的HTML其实都只是普通的文本,重点在于如何将这种有固定格式的文本渲染到浏览器中,从普通文本到程序的运行必不可少的需要解释和转化(专业点叫词法分析和语法分析)。
- 词法分析:这个过程是对一个个字符读入,并对程序代码进行扫描,根据构词规则识别单词生成
token令牌- 语法分析:在词法分析的基础上将令牌组合生成各类语法短句,例如表达式、语句等等
举个栗子
HTML文档内容
<!DOCTYPE html><html><head><meta charset="UTF-8"><link rel="stylesheet" href=""></head><body><p>Hello<span>web preformance</span>students</p><div><img src="xxx" alt="xxx"></div></body></html>
解析全过程
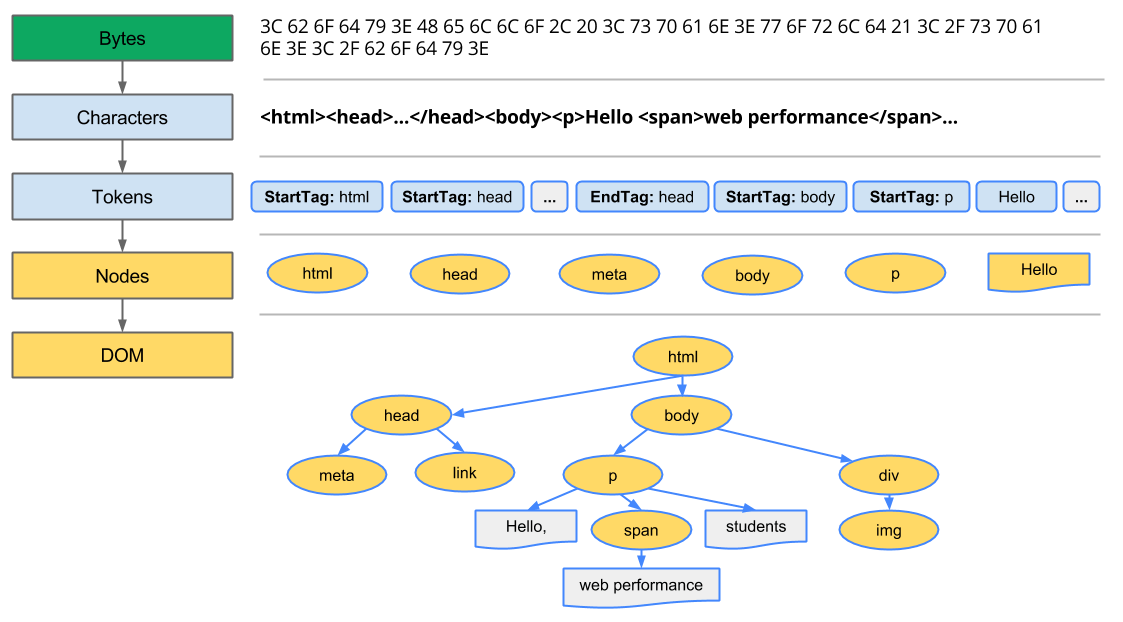
- 获取HTML文档
- 浏览器根据URL向服务器发送请求,服务器会将HTML文件的内容放置在响应体中返回给浏览器
- 确定资源类型:浏览器根据响应头字段
content-type得知这是一个HTML文件,准备开始解析HTML文档内容 - 确定资源编码:浏览器根据响应头字段
content-type同时可以确定文件编码,从而正确对文档内容正确转码确保Byte->Charaters的过程
- 转码
- 浏览器使用HTML文档解析工具来逐行读入该文档,然后依次读入
Byte字节并转码成Charaters字符,此时才是我们所看到的HTML文档内容
- 浏览器使用HTML文档解析工具来逐行读入该文档,然后依次读入
词法分析
- 例如浏览器读取到
<html>,根据HTML结构规则知道这是一个开始标签,并且标签名叫html;这个解析过程会对文档逐行执行,直到所有的标签都解释完成,存储在一个数组结构tokens中,等待进去下一个流程此流程还不是节点,只是将html文本转换成浏览器能够理解的数据结构[// 第1行{ tagName: "html", type: "DOCTYPE", attr: "", text: "" },{ tagName: "", type: "Character", attr: "", text: "\n" },// 第2行{ tagName: "html", type: "startTag", attr: "", text: "" },{ tagName: "", type: "Character", attr: "", text: "\n " },// 第3行{ tagName: "head", type: "startTag", attr: "", text: "" },{ tagName: "", type: "Character", attr: "", text: "\n " },// 第4行{ tagName: "meta", type: "startTag", attr: "charset=UTF-8", text: "" },{ tagName: "meta", type: "endTag", attr: "", text: "" },{ tagName: "", type: "Character", attr: "", text: "\n " },// 第5行{ tagName: "link", type: "startTag", attr: "rel=stylesheet&href=", text: "" },{ tagName: "link", type: "endTag", attr: "", text: "" },{ tagName: "", type: "Character", attr: "", text: "\n" },// 第6行{ tagName: "head", type: "endTag", attr: "", text: "" },{ tagName: "", type: "Character", attr: "", text: "\n" },// 第7行{ tagName: "body", type: "startTag", attr: "", text: "" },{ tagName: "", type: "Character", attr: "", text: "\n " },// 第8-9行{ tagName: "p", type: "startTag", attr: "", text: "" },{ tagName: "", type: "Character", attr: "", text: "\n Hello\n " },// 第10-11行{ tagName: "span", type: "startTag", attr: "", text: "" },{ tagName: "", type: "Character", attr: "", text: "web preformance" },{ tagName: "span", type: "endTag", attr: "", text: "" },{ tagName: "", type: "Character", attr: "", text: "\n students\n " },// 第12行{ tagName: "p", type: "endTag", attr: "", text: "" },{ tagName: "", type: "Character", attr: "", text: "\n " },// 第13行{ tagName: "div", type: "startTag", attr: "", text: "" },{ tagName: "", type: "Character", attr: "", text: "\n " },// 第14行{ tagName: "img", type: "startTag", attr: "src=xxx&alt=xxx", text: "" },{ tagName: "img", type: "endTag", attr: "", text: "" },{ tagName: "", type: "Character", attr: "", text: "\n " },// 第15行{ tagName: "div", type: "endTag", attr: "", text: "" },{ tagName: "", type: "Character", attr: "", text: "\n" },// 第16行{ tagName: "body", type: "endTag", attr: "", text: "" },{ tagName: "", type: "Character", attr: "", text: "\n" },// 第17行{ tagName: "html", type: "endTag", attr: "", text: "" },{ tagName: "", type: "Character", attr: "", text: "\n" },// 第结束{ tagName: "", type: "EndOffile", attr: "", text: "" },]
- 例如浏览器读取到
语法分析
- 处理通过上一步得到的
tokens,将其从数据转换成浏览器内支持并可操作的Node节点
- 处理通过上一步得到的
- DOM构造
- 最后根据标签之间的关系,构造成DOM树

若有收获,就点个赞吧
0 人点赞
