一、使用labelImg标注数据
labelImg已经打包好放在网盘中了
链接:https://pan.baidu.com/s/1gwfB2bsc0ygW2yOH-8t9Tg 提取码:ABCD
下载labelImg后解压得到两个文件,一个是可执行文件labelImg.exe,另一个是存放标签的文件data/predefined_classes.txt
打开labelImg.exe
使用说明:按W会出现光标,按A是前一张照片,按D是后一张照片,使用光标将目标物框住以后,输入标签名字,再保存即可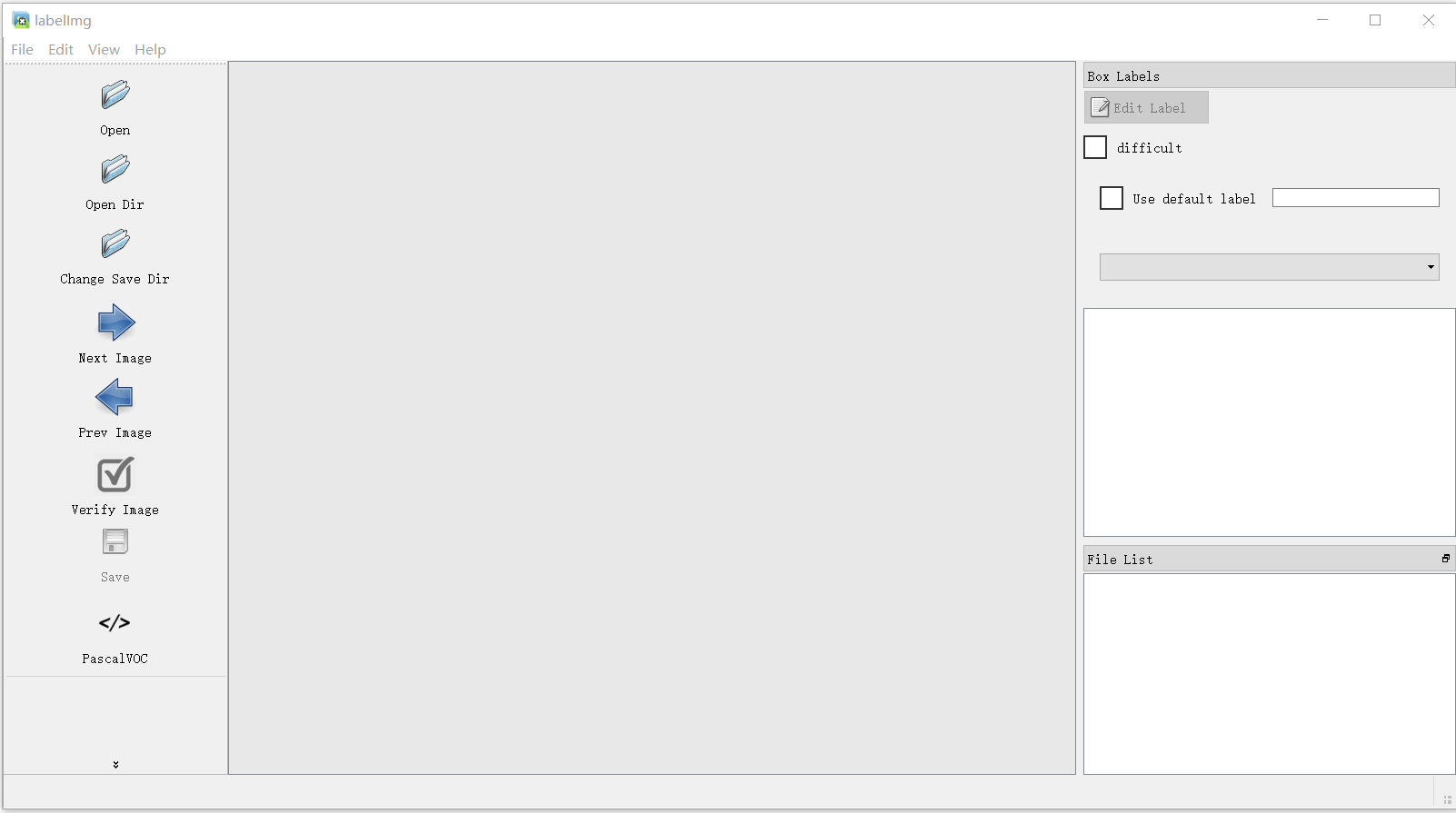
open Dir 打开是存放图片的文件夹 change save Dir 是设置标签保存的文件夹 PascalVOC 是修改数据集标签格式(有YOLO和VOC两种)
二、数据集划分
数据集需要按图片和标签划分为训练集和测试集,所以要对图片和标签进行划分,划分结果如下图所示: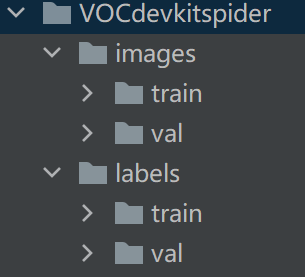
数据集划分主要用到两个代码:make_txt.py和train_val.py,下面已给出完整代码
在数据集划分之前,先新建几个文件夹,把数据集图片保存在images中,数据集标签保存在labels中,文件夹名和路径如下所示:
- images
- 存放数据集图片
- ImageSets
- labels
- 存放数据集标签
- make_txt.py
- train_val.py
先运行make_txt.py,会在ImageSets文件下生成四个文件test.txt, train.txt, trainval.txt, val.txt,里面存放的是划分好的图片名,如下所示: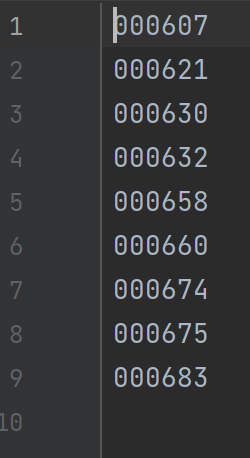
再运行train_val.py ,需要修改的是最后四行中的文件路径,改成自己的数据集文件名,需要修改的部分如下:
import os #路径处理包import random #随机数包trainval_percent = 0.1 #所有数据中测试用数据比例10%train_percent = 0.9 #训练数据比例90%#├── train 占90%#└── trainval 占10%# ├── test 占90%*10%# └── val 占10%*10%xmlfilepath = 'images' #图片所在路径txtsavepath = 'ImageSets' #生成txt文件路径total_xml = os.listdir(xmlfilepath)num = len(total_xml) #所有图片数list = range(num)#计算各类数据实际量tv = int(num * trainval_percent)tr = int(tv * train_percent)#随机生成固定个数序列trainval = random.sample(list, tv) #从所有list中返回tv个数量的项目train = random.sample(trainval, tr)if not os.path.exists('ImageSets/'):os.makedirs('ImageSets/')ftrainval = open('ImageSets/trainval.txt', 'w')ftest = open('ImageSets/test.txt', 'w')ftrain = open('ImageSets/train.txt', 'w')fval = open('ImageSets/val.txt', 'w')for i in list:name = total_xml[i][:-4] + '\n'if i in trainval:ftrainval.write(name)if i in train:ftest.write(name)else:fval.write(name)else:ftrain.write(name)ftrainval.close()ftrain.close()fval.close()ftest.close()
import xml.etree.ElementTree as ET #Python标准库中处理xml的APIimport pickle # 可以将对象以文件的形式存放在磁盘上。import os # 路径处理包import shutil # python高级文件操作模块(例如复制文件内容,创建文件的新副本并进行归档)from os import listdir, getcwdfrom os.path import joinsets = ['train', 'trainval'] #数据集名称classes = ['pinecone'] #类别名称# xyxy -> xywh######################### 返回值为ROI中心点相对于图片大小的比例坐标,和ROI的w、h相对于图片大小的比例# box里保存的是ROI感兴趣区域的坐标(xyxy)def convert(size, box):dw = 1. / size[0] #浮点数除法则执行精确除法dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)# 对于单个xml的处理def convert_annotation(image_id):in_file = open('Annotations/%s.xml' % (image_id))out_file = open('labels/%s.txt' % (image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))print(b)bb = convert((w, h), b) #生成ROI# print(bb)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')#打印当前路径wd = getcwd()print(wd)#遍历所有数据集和类别,对每个数据进行处理并按结构保存for image_set in sets:if not os.path.exists('labels/'):os.makedirs('labels/')image_ids = open('ImageSets/%s.txt' % (image_set)).read().strip().split()image_list_file = open('images_%s.txt' % (image_set), 'w')labels_list_file=open('labels_%s.txt'%(image_set),'w')for image_id in image_ids:image_list_file.write('%s.JPG\n' % (image_id))labels_list_file.write('%s.txt\n'%(image_id))# convert_annotation(image_id) #如果标签已经是txt格式,将此行注释掉,所有的txt存放到all_labels文件夹。image_list_file.close()labels_list_file.close()#创建yolo训练格式新路径def copy_file(new_path,path_txt,search_path):#参数1:存放新文件的位置 参数2:为上一步建立好的train,val训练数据的路径txt文件 参数3:为搜索的文件位置if not os.path.exists(new_path):os.makedirs(new_path)with open(path_txt, 'r') as lines:filenames_to_copy = set(line.rstrip() for line in lines)# print('filenames_to_copy:',filenames_to_copy)# print(len(filenames_to_copy))for root, _, filenames in os.walk(search_path):# print('root',root)# print(_)# print(filenames)for filename in filenames:if filename in filenames_to_copy:shutil.copy(os.path.join(root, filename), new_path)#按照划分好的训练文件的路径搜索目标,并将其复制到yolo格式下的新路径copy_file('../VOCdevkit408409/images/train/', './images_train.txt', './images')copy_file('../VOCdevkit408409/images/val/', './images_trainval.txt', './images')copy_file('../VOCdevkit408409/labels/train/', './labels_train.txt', './labels')copy_file('../VOCdevkit408409/labels/val/', './labels_trainval.txt', './labels')

若有收获,就点个赞吧
0 人点赞
