translator: http://www.jobbole.com/members/q3057027161/ reviewer: http://www.jobbole.com/members/hanxiaomax/
via: https://medium.com/@CanHasCommunism/understanding-compilers-for-humans-ba970e045877
Understanding Compilers — For Humans (Version 2)
人人都能读懂的编译器原理
How Programming Languages Work 编程语言是怎样工作的
Understanding your compiler internally allows you to use it effectively. Walk through how programming languages and compilers work in this chronological synopsis. Lots of links, example code, and diagrams have been composed to aid in your understanding.
理解你的编译器内部原理可以使你更高效地利用它。按照编译的工作顺序逐步深入编程语言和编译器是怎样工作的。这篇文章中有大量的链接,样例代码,和图表帮助你理解编译器。
Author’s Note
作者的话
Understanding Compilers — For Humans (Version 2) is a successor to my second article on Medium, with over 21 thousand views. I am so glad I could make a positive impact on people’s education, and I am excited to bring a complete rewrite based on the input I received from the original article. 理解编译器 - 为人类准备的 (版本2) 是我在 Medium 上的第二篇文章的再版,那篇文章有超过 21000 的阅读量。很高兴我能够帮助到各位的学习,因此我根据上篇文章的评论,完完全全地重写了那篇文章。
I chose Rust as this work’s primary language. It is verbose, efficient, modern, and seems, by design, to be really simple for making compilers. I enjoyed using it. https://www.rust-lang.org/
我选择 Rust 作为这篇文章的主要语言。它是一种详尽的、高效的、现代的而且看起来特意使得设计编译器变得简单。我很喜欢使用它。 https://www.rust-lang.org/
This article is written for the goal of keeping the reader’s attention, and to not have 20 pages of mind numbing reading. There are many links in the text that will guide you to resources that go deeper on topics that intrigue you. Most links direct you to Wikipedia.
写这篇文章的目的主要是吸引读者的注意力,而不是提供 20 多页的令人头皮发麻的阅读材料。对于那些你感兴趣的更深层次的话题,文章中有许多链接会引导你找到相关的资料。大多数链接到维基百科 。
Thank you for your interest, and I hope you enjoy what I’ve been working on for little over 20 hours. Feel free to drop any questions and suggestions in the comment section at the bottom.
感谢你的关注,我希望你能够喜欢这些我花费了超过 20 个小时的写出的文章。欢迎在文章底部评论处留下任何问题或者建议。
Introduction
简单介绍
What a Compiler is
编译器是什么
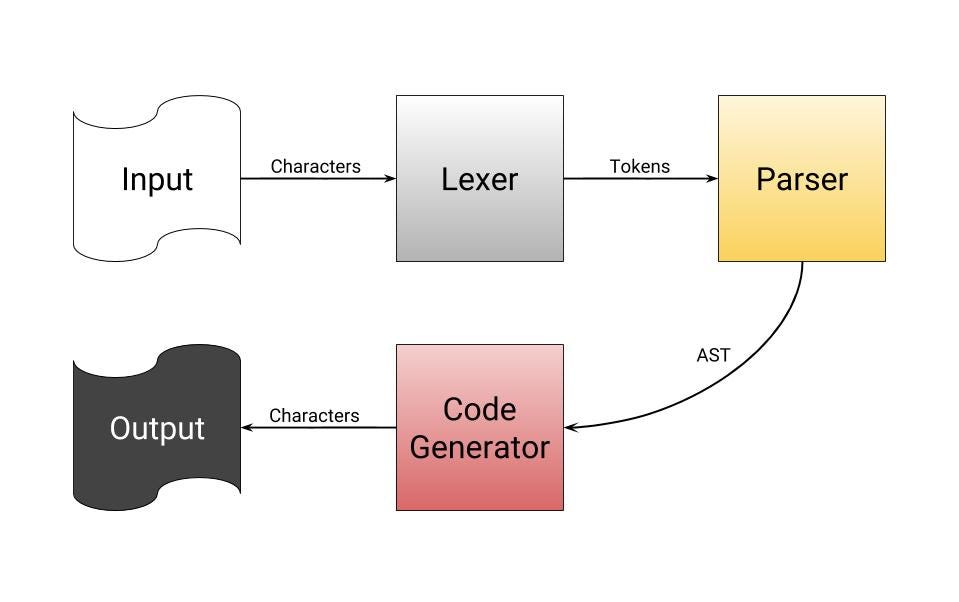
What you may call a programming language is really just software, called a compiler, that reads a text file, processes it a lot, and generates binary. The language part of a compiler is just what the style of text it is processing. Since a computer can only read 1s and 0s, and humans write better Rust than they do binary, compilers were made to turn that human-readable text into computer-readable machine code.
你口中所说的编程语言本质上只是一个软件,这个软件叫做编译器,编译器读入一个文本文件,经过大量的处理,最终产生一个二进制文件。 编译器的语言部分就是它处理的文本样式。因为电脑只能读取 1 和 0 ,而人们编写 Rust 程序要比直接编写二进制程序简单地多,因此编译器就被用来把人类可读的文本转换成计算机可识别的机器码。
A compiler can be any program that translates one text into another. For example, here is a compiler written in Rust that turns 0s into 1s, and 1s into 0s:
编译器可以是任何可以把文本文件转换成其他文件的程序。例如,下面有一个用 Rust 语言写的编译器把 0 转换成 1,把 1 转换成 0 :
// An example compiler that turns 0s into 1s, and 1s into 0s.fn main() {let input = "1 0 1 A 1 0 1 3";// iterate over every character `c` in inputlet output: String = input.chars().map(|c|if c == '1' { '0' }else if c == '0' { '1' }else { c } // if not 0 or 1, leave it alone).collect();println!("{}", output); // 0 1 0 A 0 1 0 3}
What a Compiler Does
编译器做什么
In short, compilers take source code and produce binary. Since it would be pretty complicated to go straight from complex, human readable code to ones and zeros, compilers have several steps of processing to do before their programs are runnable:
简言之,编译器获取源代码,产生一个二进制文件。因为从复杂的、人类可读的代码直接转化成0/1二进制会很复杂,所以编译器在产生可运行程序之前有多个步骤:
- Reads the individual characters of the source code you give it.
从你给定的源代码中读取单个词。
Sorts the characters into words, numbers, symbols, and operators.
把这些词按照单词、数字、符号、运算符进行分类。
Takes the sorted characters and determines the operations they are trying to perform by matching them against patterns, and making a tree of the operations.
通过模式匹配从分好类的单词中找出运算符,明确这些运算符想进行的运算,然后产生一个运算符的树(表达式树)。
Iterates over every operation in the tree made in the last step, and generates the equivalent binary.
- 最后一步遍历表达式树中的所有运算符,产生相应的二进制数据。
While I say the compiler immediately goes from a tree of operations to binary, it actually generates assembly code, which is then assembled/compiled into binary. Assembly is like a higher-level, human-readable binary. Read more about what assembly is here.
尽管我说编译器直接从表达式树转换到二进制,但实际上它会产生汇编代码,之后汇编代码会被汇编/编译到二进制数据。汇编程序就好比是一种高级的、人类可读的二进制。更多关于汇编语言的阅读资料在这里。
What an Interpreter is
解释器是什么
Interpreters are much like compilers in that they read a language and process it. Though, interpreters skip code generation and execute the AST just-in-time. The biggest advantage to interpreters is the time it takes to start running your program during debug. A compiler may take anywhere from a second to several minutes to compile a program, while an interpreter begins running immediately, with no compilation. The biggest downside to an interpreter is that it requires to be installed on the user’s computer before the program can be executed.
解释器 非常像编译器,它也是读入编程语言的代码,然后处理这些代码。尽管如此,解释器会跳过了代码生成,然后即时编译并执行 AST。 解释器最大的优点就在于在你 debug 期间运行程序所消耗的时间。编译器编译一个程序可能在一秒到几分钟不等,然而解释器可以立即开始执行程序,而不必编译。解释器最大的缺点在于它必须安装在用户电脑上,程序才可以执行。
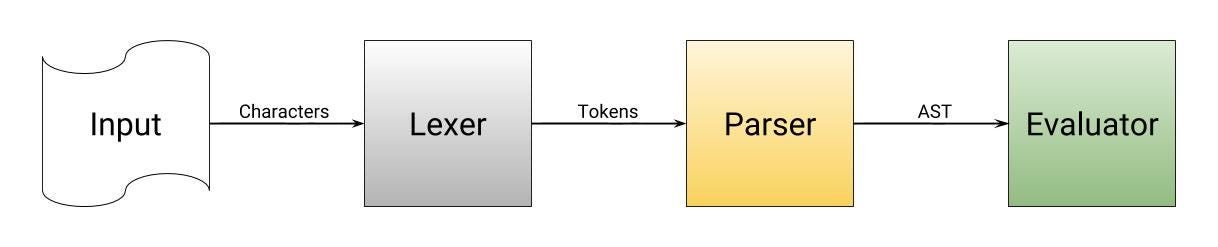
This article refers mostly to compilers, but it should be clear the differences between them and how compilers relate.
虽然这篇文章主要是关于编译器的,但是对于编译器和解释器之间的区别和编译器相关的内容一定要弄清楚。
1. Lexical Analysis
1. 词法分析
The first step is to split the input up character by character. This step is called lexical analysis, or tokenization. The major idea is that we group characters together to form our words, identifiers, symbols, and more. Lexical analysis mostly does not deal with anything logical like solving 2+2 — it would just say that there are three tokens: a number: 2, a plus sign, and then another number: 2.
第一步是把输入一个词一个词的拆分开。这一步被叫做 词法分析,或者说是分词。这一步的关键就在于 我们把字符组合成我们需要的单词、标识符、符号等等。 词法分析大多都不需要处理逻辑运算像是算出 2+2 - 其实这个表达式只有三种 标记:一个数字:2,一个加号,另外一个数字:2。
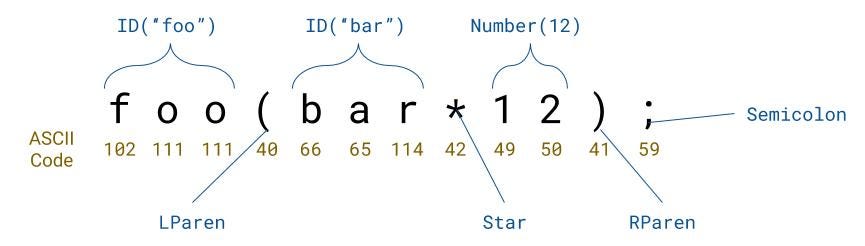
Let’s say you were lexing a string like 12+3: it would read the characters 1, 2, +, and 3. We have the separate characters but we must group them together; one of the major tasks of the tokenizer. For example, we got 1 and 2 as individual letters, but we need to put them together and parse them as a single integer. The + would also need to be recognized as a plus sign, and not its literal character value — the character code 43.
让我们假设你正在解析一个像是 12+3 这样的字符串:它会读入字符 1,2,+,和 3。我们已经把这些字符拆分开了,但是现在我们必须把他们组合起来;这是分词器的主要任务之一。举个例子,我们得到了两个单独的字符 1 和 2,但是我们需要把它们放到一起,然后把它们解析成为一个整数。至于 +也需要被识别为加号,而不是它的字符值 - 字符值是43 。
If you can see code and make more meaning of it that way, then the following Rust tokenizer can group digits into 32-bit integers, and plus signs as the Token value Plus.
如果你可以阅读过上面的代码,并且弄懂了这样做的含义,接下来的 Rust 分词器会组合数字为32位整数,加号就最后了标记值 Plus(加).
You can click the “Run” button at the top left corner of the Rust Playground to compile and execute the code in your browser.
你可以点击 Rust playgroud 左上角的 “Run” 按钮来编译和执行你浏览器中的代码。
In a compiler for a programming language, the lexer may need to have several different types of tokens. For example: symbols, numbers, identifiers, strings, operators, etc. It is entirely dependent on the language itself to know what kind of individual tokens you would need to extract from the source code.
在一种编程语言的编译器中,词法解析器可能需要许多不同类型的标记。例如:符号,数字,标识符,字符串,操作符等。想知道要从源文件中提取怎样的标记完全取决于编程语言本身。
int main() {int a;int b;a = b = 4;return a - b;}Scanner production:[Keyword(Int), Id("main"), Symbol(LParen), Symbol(RParen), Symbol(LBrace), Keyword(Int), Id("a"), Symbol(Semicolon), Keyword(Int), Id("b"), Symbol(Semicolon), Id("a"), Operator(Assignment), Id("b"),Operator(Assignment), Integer(4), Symbol(Semicolon), Keyword(Return), Id("a"), Operator(Minus), Id("b"), Symbol(Semicolon), Symbol(RBrace)]
2. Parsing
2. 解析
The parser is truly the heart of the syntax. The parser takes the tokens generated by the lexer, attempts to see if they’re in certain patterns, then associates those patterns with expressions like calling functions, recalling variables, or math operations. The parser is what literally defines the syntax of the language.
解析器确实是语法解析的核心。解析器提取由词法分析器产生的标记,并尝试判断它们是否符合特定的模式,然后把这些模式与函数调用,变量调用,数学运算之类的表达式关联起来。 解析器逐词地定义编程语言的语法。
The difference between saying int a = 3 and a: int = 3 is in the parser. The parser is what makes the decision of how syntax is supposed to look. It ensures that parentheses and curly braces are balanced, that every statement ends with a semicolon, and that every function has a name. The parser knows when things aren’t in the correct order when tokens don’t fit the expected pattern.int a = 3 和 a: int = 3 的区别在于解析器的处理上面。解析器决定了语法的外在形式是怎样的。它确保括号和花括号的左右括号是数量平衡的,每个语句结尾都有一个分号,每个函数都有一个名称。当标记不符合预期的模式时,解析器就会知道标记的顺序不正确。
There are several different types of parsers that you can write. One of the most common is a top-down, recursive-descent parser. Recursive-descent parsing is one of the simplest to use and understand. All of the parser examples I created are recursive-descent based.
你可以写好几种不同类型的解析器。最常见的解析器之一是从上到下的,递归降解的解析器。递归降解的解析器是用起来最简单也是最容易理解的解析器。我写的所有解析器样例都是基于递归降解的。
The syntax a parser parses can be outlined using a grammar. A grammar like EBNF can describe a parser for simple math operations like 12+3:
解析器解析的语法可以使用一种 语法 表示出来。像 EBNF 这样的语法就可以描述一个解析器用于解析简单的数学运算,像是这样 12+3 :
expr = additive_expr ;additive_expr = term, ('+' | '-'), term ;term = number ;
Remember that the grammar file is not the parser, but it is rather an outline of what the parser does. You build a parser around a grammar like this one. It is to be consumed by humans and is simpler to read and understand than looking directly at the code of the parser.
请记住语法文件并不是解析器,但是它确实是解析器的一种表达形式。你可以围绕上面的语法创建一个解析器。语法文件可以被人使用并且比起直接阅读和理解解析器的代码要简单许多。
The parser for that grammar would be the expr parser, since it is the top-level item that basically everything is related to. The only valid input would have to be any number, plus or minus, any number. expr expects an additive_expr, which is where the major addition and subtraction appears. additive_expr first expects a term (a number), then plus or minus, another term.
那种语法的解析器应该是 expr 解析器,因为它直接与所有内容都相关的顶层。唯一有效的输入必须是任意数字,加号或减号,任意数字。expr 需要一个 additive_expr,这主要出现在加法和减法表达式中。additive_expr 首先需要一个 term (一个数字),然后是加号或者减号,最后是另一个 term 。
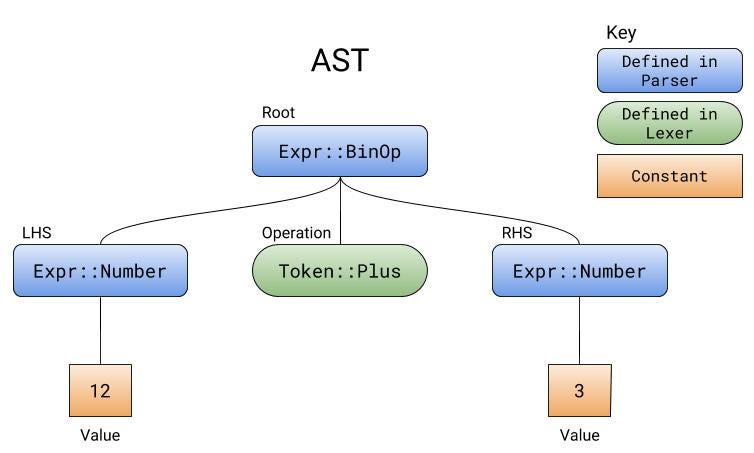
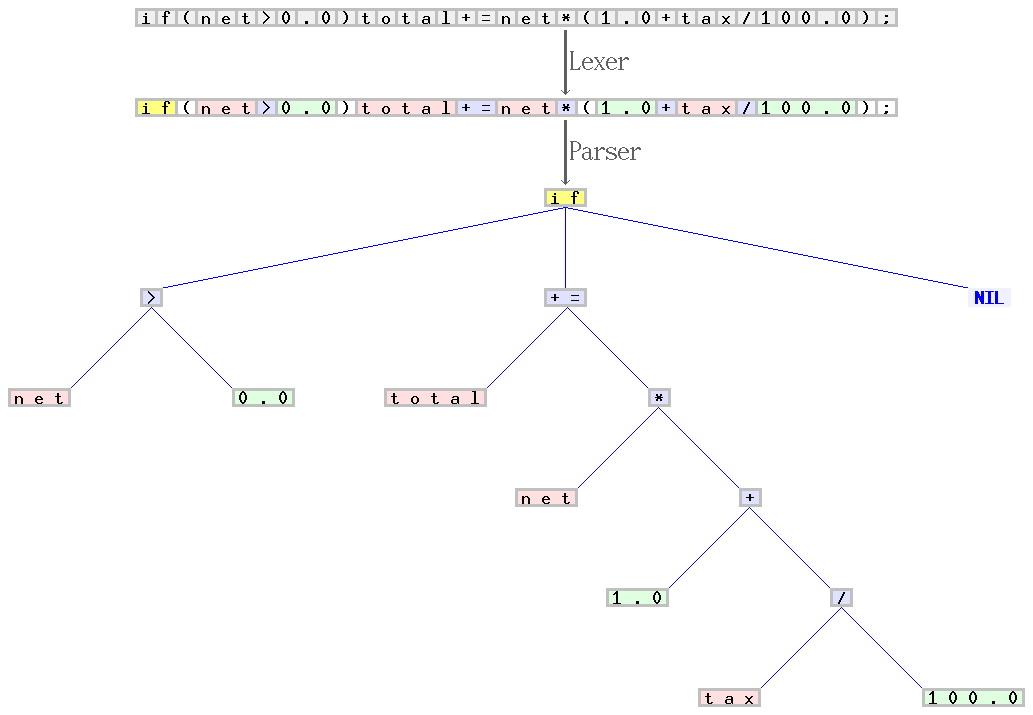
解析 12+3 产生的样例 AST
The tree that a parser generates while parsing is called the abstract syntax tree, or AST. The ast contains all of the operations. The parser does not calculate the operations, it just collects them in their correct order.
解析器在解析时产生的树状结构被称为 抽象的语法树,或者称之为 AST。 ast 中包含了所有要进行操作。解析器不会计算这些操作,它只是以正确的顺序来收集其中的标记。
I added onto our lexer code from before so that it matches our grammar and can generate ASTs like the diagram. I marked the beginning and end of the new parser code with the comments // BEGIN PARSER // and // END PARSER //.
我之前补充了我们的词法分析器代码,以便它与我们的语法想匹配,并且可以产生像图表一样的 AST。我用 // BEGIN PARSER // 和 // END PARSER // 的注释标记出了新的解析器代码的开头和结尾。
We can actually go much further. Say we want to support inputs that are just numbers without operations, or adding multiplication and division, or even adding precedence. This is all possible with a quick change of the grammar file, and an adjustment to reflect it inside of our parser code.
我们可以再深入一点。假设我们想要支持只有数字没有运算符的输入,或者添加除法和乘法,甚至添加优先级。只要简单地修改一下语法文件,这些都是完全有可能的,任何调整都会直接反映在我们的解析器代码中。
expr = additive_expr ;additive_expr = multiplicative_expr, { ('+' | '-'), multiplicative_expr } ;multiplicative_expr = term, { ("*" | "/"), term } ;term = number ;
3. Generating Code
3. 生成代码
The code generator takes an AST and emits the equivalent in code or assembly. The code generator must iterate through every single item in the AST in a recursive descent order — much like how a parser works — and then emit the equivalent, but in code.
代码生成器 接收一个 AST ,然后生成相应的代码或者汇编代码。代码生成器必须以递归下降的顺序遍历AST中的所有内容-就像是解析器的工作方式一样-之后生成相应的内容,只不过这里生成的不再是语法树,而是代码了。
If you open the above link, you can see the assembly produced by the example code on the left. Lines 3 and 4 of the assembly code show how the compiler generated the code for the constants when it encountered them in the AST.
如果打开上面的链接,你就可以看到左侧样例代码产生的汇编代码。汇编代码的第三行和第四行展示了编译器在AST中遇到常量的时候是怎样为这些常量生成相应的代码的。
The Godbolt Compiler Explorer is an excellent tool and allows you to write code in a high level programming language and see it’s generated assembly code. You can fool around with this and see what kind of code should be made, but don’t forget to add the optimization flag to your language’s compiler to see just how smart it is. (-O for Rust)
Godbolt Compiler Explorer 是一个很棒的工具,允许你用高级语言编写代码,并查看它产生的汇编代码。你可以有点晕头转向了,想知道产生的是哪种代码,但不要忘记给你的编程语言编译器添加优化选项来看看它到底有多智能。(对于 Rust 是 -O )
If you are interested in how a compiler saves a local variable to memory in ASM, this article (section “Code Generation”) explains the stack in thorough detail. Most times, advanced compilers will allocate memory for variables on the heap and store them there, instead of on the stack, when the variables are not local. You can read more about storing variables in this StackOverflow answer.
如果你对于编译器是在汇编语言中怎样把一个本地变量保存到内存中感兴趣的话,这篇文章 (“代码生成”部分)非常详细地解释了堆栈的相关知识。大多数情况下,当变量不是本地变量的时候,高级编译器会在堆区为变量分配空间,并把它们保存到堆区,而不是栈区。你可以从这个 StackOverflow 的回答上阅读更多关于变量存储的内容。
Since assembly is an entirely different, complicated subject, I won’t talk much more about it specifically. I just want to stress the importance and work of the code generator. Furthermore, a code generator can produce more than just assembly. The Haxe compiler has a backend that can generate over six different programming languages; including C++, Java, and Python.
因为汇编是一个完全不同的,而且复杂的主题,因此这里我不会过多地讨论它。我只是想强调代码生成器的重要性和它的作用。此外,代码生成器不仅可以产生汇编代码。Haxe 编译器有一个可以产生 6 种以上不同的编程语言的后端:包括 C++,Java,和 Python。
Backend refers to a compiler’s code generator or evaluator; therefore, the front end is the lexer and parser. There is also a middle end, which mostly has to do with optimizations and IRs explained later in this section. The back end is mostly unrelated to the front end, and only cares about the AST it receives. This means one could reuse the same backend for several different front ends or languages. This is the case with the notorious GNU Compiler Collection. 后端指的是编译器的代码生成器或者表达式解析器;因此前端是词法分析器和解析器。同样也有一个中间端,它通常与优化和 IR 有关,这部分会在稍后解释。后端通常与前端无关,后端只关心它接收到的 AST。这意味着可以为几种不同的前端或者语言重用相同的后端。大名鼎鼎的 GNU Compiler Collection 就属于这种情况。
I couldn’t have a better example of a code generator than my C compiler’s backend; you can find it here.
我找不到比我的 C 编译器后端更好的代码生成器示例了;你可以在这里查看它
After the assembly has been produced, it would be written to a new assembly file (.s or .asm). That file would then be passed through an assembler, which is a compiler for assembly, and would generate the equivalent in binary. The binary code would then be written to a new file called an object file (.o).
在生成汇编代码之后,这些汇编代码会被写入到一个新的汇编文件中 (.s 或 .asm)。然后该文件会被传递给汇编器,汇编器是汇编语言的编译器,它会生成相应的二进制代码。之后这些二进制代码会被写入到一个新的目标文件中 (.o) 。
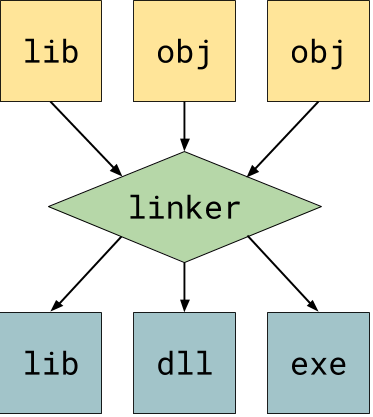
Object files are machine code but they are not executable. For them to become executable, the object files would need to be linked together. The linker takes this general machine code and makes it an executable, a shared library, or a static library. More about linkers here.
目标文件是机器码,但是它们并不可以被执行。 为了让它们变成可执行文件,目标文件需要被链接到一起。链接器读取通用的机器码,然后使它变为一个可执行文件、共享库或是 静态库。更多关于链接器的知识在这里。
Linkers are utility programs that vary based on operating systems. A single, third-party linker should be able to compile the object code your backend generates. There should be no need to create your own linker when making a compiler.
链接器是因操作系统而不同的应用程序。随便一个第三方的链接器都应该可以编译你后端产生的目标代码。因此在写编译器的时候不需要创建你自己的链接器。
A compiler may have an intermediate representation, or IR. An IR is about representing the original instructions losslessly for optimizations or translation to another language. An IR is not the original source code; the IR is a lossless simplification for the sake of finding potential optimizations in the code. Loop unrolling and vectorization are done using the IR. More examples of IR-related optimizations can be found in this PDF.
编译器可能有 中间表示,或者简称 IR 。IR 主要是为了在优化或者翻译成另一门语言的时候,无损地表示原来的指令。 IR 不再是原来的代码;IR 是为了寻找代码中潜在的优化而进行的无损简化。循环展开 和 向量化 都是利用 IR 完成的。更多关于 IR 相关的优化可以在这个 PDF 中找到。
Conclusion
When you understand compilers, you can work more efficiently with your programming languages. Maybe someday you would be interested in making your own programming language? I hope this helped you.
总结
当你理解了编译器的时候,你就可以更有效地使用你的编程语言。或许有一天你会对创建你自己的编程语言感兴趣?我希望这能够帮到你。
Resources & Further Reading
资源&更深入的阅读资料
- http://craftinginterpreters.com/ — guides you through making an interpreter in C and Java.
- http://craftinginterpreters.com/ - 指导你编写一个 C 和 Java 的解释器。
- https://norasandler.com/2017/11/29/Write-a-Compiler.html — probably the most beneficial “writing a compiler” tutorial for me.
- https://norasandler.com/2017/11/29/Write-a-Compiler.html - 大概是对我来说最有用的 “编写编译器” 的教程了
- My C compiler and scientific calculator parser can be found here and here).
- 我的 C 编译器和科学计算解析器可以在这里和这里找到。
- An example of another type of parser, called a precedence climbing parser, can be found here. Credit: Wesley Norris.
- 另一类的解析器,被称作自底向上的解析器,可以在这里找到。来源于:Wesley Norris.

若有收获,就点个赞吧
0 人点赞

{kind=link}