- 每日反馈
- day08知识回顾
- 01-文件备份案例[熟练使用]
- 02-字节型文件备份案例[熟练掌握]
- 思考1: 图片文件的读取和写入方式,和纯文本文件相同么? 不一样
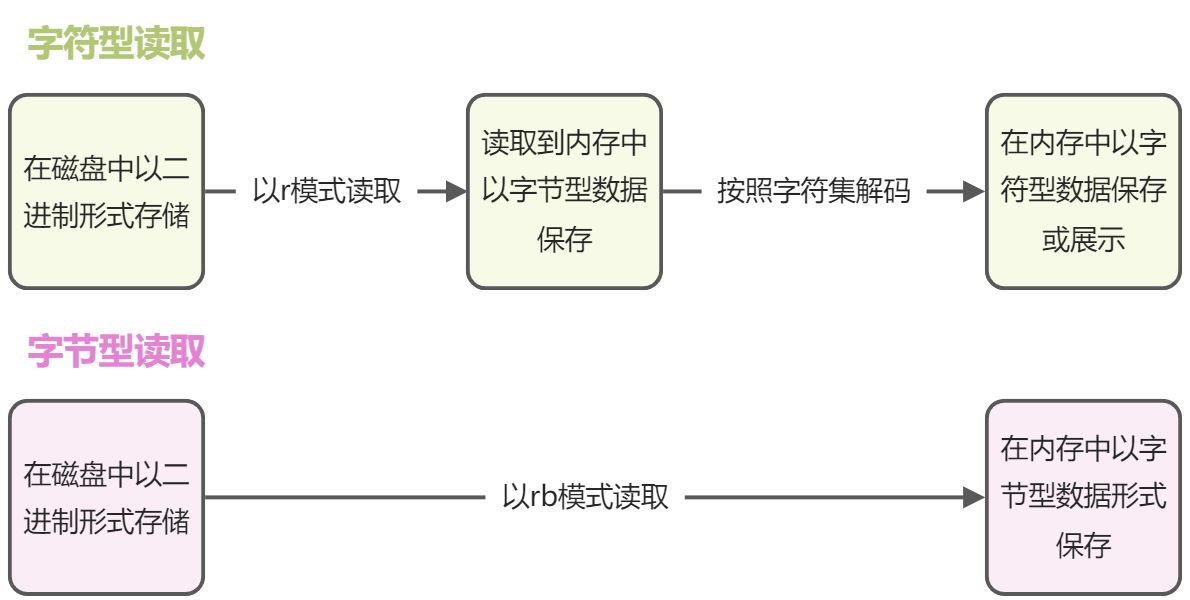
- 图片,声音,压缩包等,非纯文本文件,读取和写入时要使用rb wb ab模式进行
- 思考2: 纯文本类型文件可以使用字节模式备份么? 可以
- 可以,所有文件的本质都是字节,所以字节流又叫做万能流.
- 备份图片的流程:
- 1. 请用户输入要备份图片的名称
- 2.打开图片文件 r
- UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x89 in position 0: invalid start byte
- 图片类型不能使用编码集, 也不能使用字符型读写模式读取
- old_file = open(file_name, ‘r’, encoding=’utf8’)
- 图片类型数据,要使用字节型文件读写模式才可以,字节型数据不能使用编码集 字节型数据,在读写模式后加b即可
- ValueError: binary mode doesn’t take an encoding argument 字节型读取不能指定编码集
- old_file = open(file_name, ‘rb’, encoding=’utf8’)
- 3.读取图片文件中的数据信息
- 字节型工属具的本质就是二进制文件,但是我们输出时为了让数据不那么冗长,显示的是16进制数据
- 4.拼接新的文件名
- 5.打开新的文件
- 当我们使用字符型写入模式打开文件时,只能写入字节数据
- new_file = open(new_file_name,’w’, encoding=’utf8’)
- 6.将图片数据写入到新文件中
- 7.关闭新文件
- 8.关闭旧文件
- 05-相对路径和绝对路径[熟悉]
- 06-os模块介绍[了解]
- 07-异常介绍[了解]
- 08-异常捕获[熟练掌握]
- 09-捕获指定类型的异常[熟练掌握]
- 10-获取异常描述信息[熟练掌握]
- 异常的描述信息: 当异常出现后,错误内容最后一行中冒号后边的内容
- NameError(异常类型): name ‘a’ is not defined(异常描述信息)
- 思考: 上边不同的异常类型为什么可以使用同样的变量名呢?
- 不同的except中可以使用相同的变量名接收异常信息,因为同一个try中只能捕获一个类型的异常.
- 只能有一个类型的error被触发,所以元组指向一个error变量就可以了.
- 12-异常中的finally[熟悉]
- 作业
- 作业提交
- 文件链接
每日反馈
| 老师讲的特别好~ |
|---|
day08知识回顾

笔记记录注意事项
- 做笔记是为了查看,阅读,复习等,所以要保证笔记,便于搜索,代码可复制可粘贴,图片声音等多媒体形式数据也可以添加进来.索引尽量不要使用纸笔进行笔记记录.
- 笔记要详细,但是不要麻烦.很多内容可以使用截图,或者复制的形式进行书写,但是需要自己分析,排版,知识体系划分
- 有条件的同学,尽量使用云笔记,,记录完成后,把笔记下载下来
- 记录笔记时,重点不突出.
推荐笔记软件:
印象笔记
有道云笔记
语雀
石墨文档
typora
使用word 记事本等软件记录也没有什么问题,但是缺乏代码块功能,没有代码的语法高亮,查询笔记时不方便,
建议程序员记笔记时,学习一下markdown语法.
01-文件备份案例[熟练使用]
# 需求: 用户输入当前目录下任意文件名后,程序完成对该文件的备份功能(备份文件名称为xxx[备份].扩展名)# 例如: test.txt = test[备份].txt# 思考: 为什么要使用代码完成文件读写 操作???# 1. 绝大多数情况下,程序员操作文件不是单纯的修改,而是具有一定的逻辑性的,我们书写逻辑,计算机帮我们精确控制修改内容.不容易出错# 2. 程序员处理文件数量一般比较庞大.# 3. 很多情况下,处理文件的时机我们不好把控,例如: 程序奔溃的一刹那我们将日志写入文件中.每天的定时任务.当某一个文件存满的一刹那.某一个文件达到一定大小.# 4. 真实服务器中没有可视化界面,甚至无法使用鼠标,所有操作需要使用键盘命令完成,包括复制粘贴# 使用代码完成的原因,人类做不到!!! 就算做到了 极易出错!# 分析: 现实生活中的步骤是什么? 打开文件,复制文件中的内容,粘贴到新文件中# 代码的步骤:# 1.获取用户输入的文件名称file_name = input('请输入您要备份的文件名称: ') # input获取的数据 是字符串类型数据# 2.打开用户输入名称的文件(旧文件) rold_file = open(file_name, 'r', encoding='utf8')# 3.读取旧文件中的数据content = old_file.read()# 4.拼接新文件的文件名称# 规则 就是在文件名称末尾追加一个[副本] 后边的扩展名不变# 可以将文件名称和扩展名之间的点 替换为[副本].new_file_name = file_name.replace('.', '[副本].')# 5.将新文件打开(如果不存在,则自行创建) wnew_file = open(new_file_name, 'w', encoding='utf8')# 6. 将刚才读取到的旧文件中的数据,写入新文件中new_file.write(content)# 7.关闭旧文件old_file.close()# 8.关闭新文件new_file.close()
02-字节型文件备份案例[熟练掌握]
能够使用记事本打开的文件都是纯文本文件,不能的就是非纯文本文件
- 所有编程语言的源文件,都是纯文本文件.
- 所有的office软件都不是纯文本文件
- md格式的文件,是markdwon语法文件,这种语法被称为纯文本标记语法. 所以md 是纯文本文件
```python
思考1: 图片文件的读取和写入方式,和纯文本文件相同么? 不一样
图片,声音,压缩包等,非纯文本文件,读取和写入时要使用rb wb ab模式进行
思考2: 纯文本类型文件可以使用字节模式备份么? 可以
可以,所有文件的本质都是字节,所以字节流又叫做万能流.
备份图片的流程:
1. 请用户输入要备份图片的名称
file_name = input(‘请输入您要备份的图片文件名称: ‘)
2.打开图片文件 r
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x89 in position 0: invalid start byte
图片类型不能使用编码集, 也不能使用字符型读写模式读取
old_file = open(file_name, ‘r’, encoding=’utf8’)
图片类型数据,要使用字节型文件读写模式才可以,字节型数据不能使用编码集 字节型数据,在读写模式后加b即可
ValueError: binary mode doesn’t take an encoding argument 字节型读取不能指定编码集
old_file = open(file_name, ‘rb’, encoding=’utf8’)
old_file = open(file_name, ‘rb’)
3.读取图片文件中的数据信息
字节型工属具的本质就是二进制文件,但是我们输出时为了让数据不那么冗长,显示的是16进制数据
content = old_file.read() print(content)
4.拼接新的文件名
new_file_name = file_name.replace(‘.’, ‘[副本].’)
5.打开新的文件
当我们使用字符型写入模式打开文件时,只能写入字节数据
new_file = open(new_file_name,’w’, encoding=’utf8’)
new_file = open(new_file_name, ‘wb’)
6.将图片数据写入到新文件中
new_file.write(content)
7.关闭新文件
new_file.close()
8.关闭旧文件
old_file.close()
<a name="GGSfI"></a># 03-文件的读写模式[了解]:::info_<br />文件读写模式一共分为三大类,12种:<br />r 读取模式<br /> r: 文本型数据读取模式<br /> rb: 字节型数据读取模式<br /> r+: 文本型数据读取加强模式<br /> rb+: 字节型数据读取加强模式w 写入模式<br /> w: 文本型数据写入模式<br /> wb: 字节型数据写入模式<br /> w+: 文本型数据写入加强模式<br /> wb+: 字节型数据写入加强模式a 追加模式<br /> a: 文本型数据追加模式<br /> ab: 字节型数据追加模式<br /> a+: 文本型数据追加加强模式<br /> ab+: 字节型数据追加加强模式<br /> <br />拆分:<br /> 读写类别:<br /> 读取: 从文件件中读取数据,已读取模式打开文件时,文件必须存在,从文件开头进行读取,不会影响原数据<br /> 写入: 向文件中写入数据,当以写入模式打开文件时,文件如果存在,则清空原数据,如果不存在则新建<br /> 追加: 向文件中追加数据,当以追加模式打开文件时,如果文件存在,则在文件末尾追加数据,如果不存在则新建文件.<br /> <br /> 模式:<br /> 字符操作: 读写操作时,操作的是字符型数据<br /> 字节操作: 读写操作时,操作的是字节型数据<br /> 字符加强操作: 操作的是字符型数据,但是在读取的模式下,可以进行写入操作,在写入时可以读取<br /> 字节加强操作: 操作的是字节型数据,但是在读取的模式下,可以进行写入操作,在写入时可以读取<br /> <br />每一种读写模式的意义 我们使用上述类别和模式自由组合即可:<br />举例:<br />wb+: 字节型数据写入加强模式:向文件中写入数据,当以写入模式打开文件时,文件如果存在,则清空原数据,如果不存在则新建.操作的是字节型数据,在写入时可以读取 _:::<a name="sP9Fv"></a># 04-字符集的了解[了解]本质:使用字符型读写模式,其实本质上,就是读取字节数据的同时,进行了解码操作.<br />传呼机 : 给传呼台打电话,告诉给这个人发什么样的信息内容, 传呼台给这个机器发送一串数字, 数字是什么含义,需要使用者自己用小本本查询.```python# 思考1: 纯文本文件,为什么可以使用字符型读写,也可以使用字节型读写# 纯文本文件,依照字符集的不同可以在字符和字节型数据间进行转换.本质上字符型数据还是二进制数据.# 思考2: 为什么字节型读写时,不能够使用编码集# 因为字符型数据,就是字节型数据+字符集,字节型文件读写时加上编码集,就变成字符型了,文件类型错误# 或者说字节型文件本身就不支持编码集# 以字节形式读取文件file = open('test.txt', 'rb')# b'\xe4\xbc\xa0\xe6\x99\xba\r\n'# 以b开头的字符串数据,就是字节型数据,也叫做二进制字符信息.# 在该字符串中,以\x开头的是16进制数据2位,可以代表8位二进制字符# print(file.read())# 字节型数据如何转换为字符型数据# 使用字符集,可以将二进制数据转换为字符型数据print(file.read().decode(encoding='utf8')) # 传智file.close()# 结论: 字节型数据+字符集=字符型数据# 以字符型数据进行读取文件file1 = open('test.txt', 'r', encoding='utf8')# print(file1.read())# 如何将字符型数据转换为字节型数据print(file1.read().encode('utf8')) # b'\xe4\xbc\xa0\xe6\x99\xba\n'file1.close()# 结论: 使用字符型数据,依照编码集进行序列化,可以将其转换为字节型数据# 字符型数据 按照 字符集 进行编码 = 字节型数据# 编码: 将字符型数据转换为字节型数据 encode# 解码: 将字节型数据转换为字符型数据 decode# 编解码时,用什么字符集编码,就用什么字符集解码str1 = '传智教育' # 字符型# 编码# 用不同的字符集编码,得到的数据内容是不一样# 常识: 在utf8字符集中汉字占3个字节, 在gbk字符集中汉字占2个字节u_str = str1.encode('utf8')print(u_str) # b'\xe4\xbc\xa0\xe6\x99\xba\xe6\x95\x99\xe8\x82\xb2'g_str = str1.encode('gbk')print(g_str) # b'\xb4\xab\xd6\xc7\xbd\xcc\xd3\xfd'# 解码print(u_str.decode('gbk')) # 浼犳櫤鏁欒偛print(u_str.decode('utf8')) # 传智教育#print(g_str.decode('gbk')) # 传智教育# 解析数据时,发现没有按照gbk编码也无法解析数据print(g_str.decode('utf8')) # UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb4 in position 0: invalid start byte# 结论: 在读写文件时,使用什么字符集写入,就用什么字符集读取,如果读取和写入的字符集不相同,可能会出现乱码或者报错的情况# 常用的编码集:# GBK: 国标码 里边保存了所有的中文,并且前128位就是ASCII(兼容ASCII)# Unicode:又叫做万国码,我们使用最多的编码格式,内部有绝大多数国家的语言,兼容ASCII,我们使用最多的是utf8# ASCII: 最早的编码集, 美国信息交换标准码, 内部只有中文
05-相对路径和绝对路径[熟悉]
# 在开发中,想找到一个文件,需要知道文件的路径.
# 如果要打开文件,格式: open(文件路径, 读写模式, 编码集)
# 思考1: 为什么我们直接输入文件名称,就可以找到该文件了???
# 因为源文件和目标文件在同一级目录下,使用./文件名就可以查找到,同时./可以省略
# 思考2: 如果这个文件在计算机中有多个同名的文件,我们找的是哪一个呢?
# 根据路径不同查找到不同的文件,同一个路径下只能有一个该名称的文件
# 思考3: 现在我想将文件备份到桌面上,我应该怎么做????
# 需要知道桌面的路径信息,在写入文件时,路径信息填写该位置即可。
# 相对路径和绝对路径:
# 相对路径: 从当前文件位置开始查找,直到找到该文件位置的查找路径
# ./代表当前目录, 可以省略, ../ 代表上一级目录
# 绝对路径: 从根目录或者盘符开始,直到查找到当前文件的查找路径
# 路径的格式: 文件层级1/文件层级2/文件层级3..../目标文件
# file = open('demo.java', 'r', encoding='utf8')
# 为什么不会读取chuanzhi目录下的demo.java呢??
file = open('./chuanzhi/demo.java','r', encoding='utf8')
print(file.read()) # 我今天还不会写java,明天也学不会
file.close()
# 在windows中 / \都可以路径层级分隔符,但是在linux,macos和Unix中都只能使用/作为分隔符,所以建议大家使用/
文件的位置就是文件的路径
绝对路径和相对路径
# 相对路径: 从当前文件位置开始查找,直到找到该文件位置的查找路径
- 使用相对路径时,./代表当前目录, ../代表上一级目录 表示当前目录时, ./可以省略
绝对路径: 从根目录或者盘符开始,直到查找到当前文件的查找路径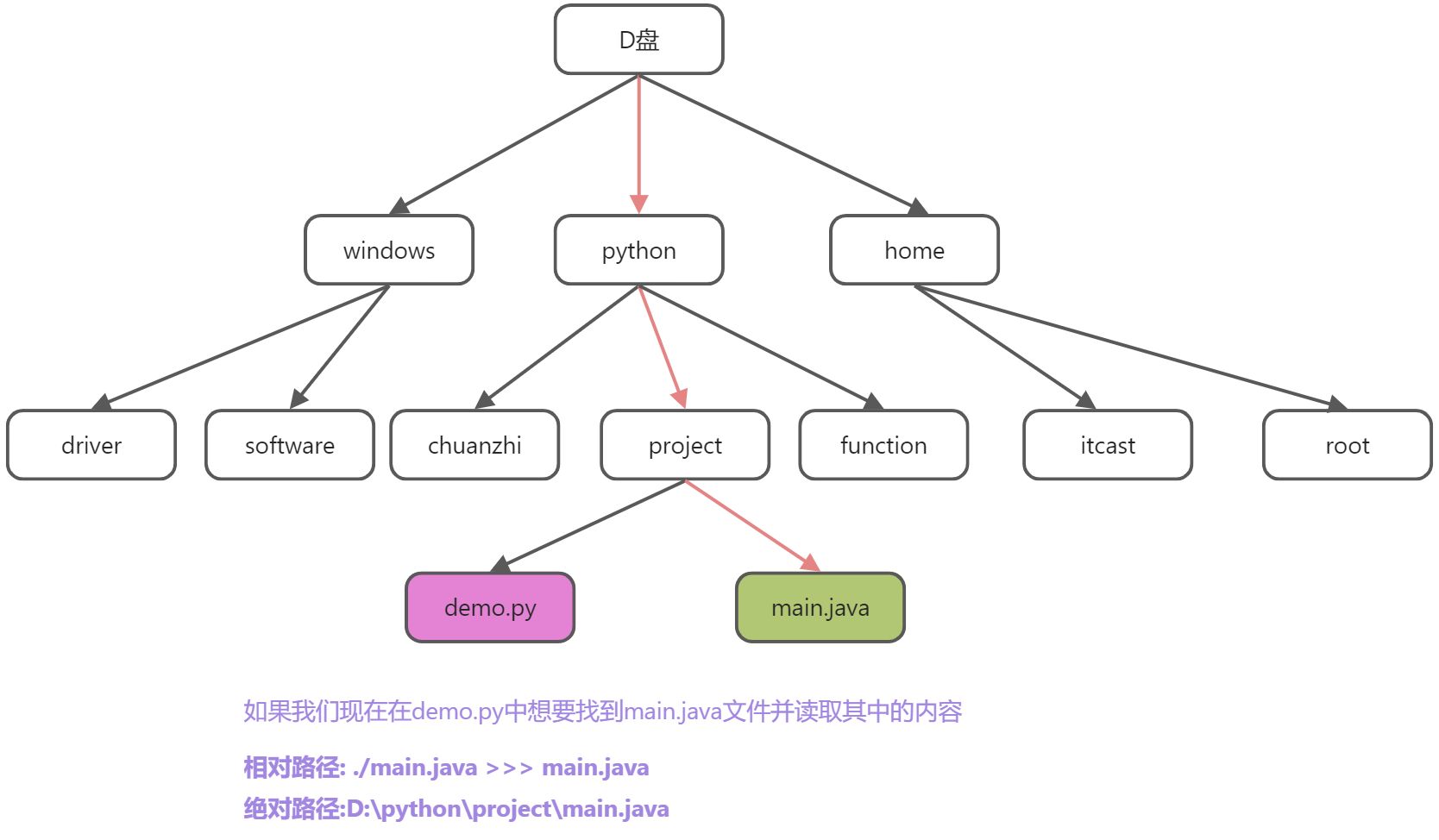

练习: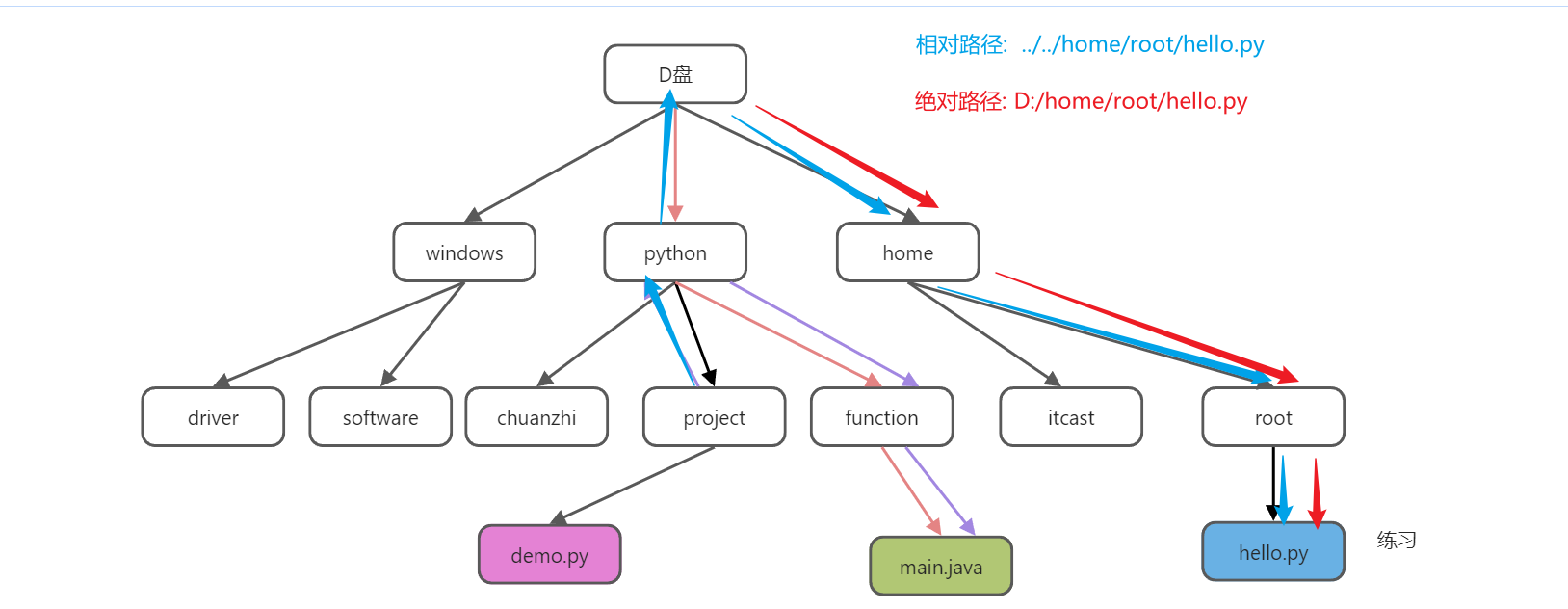
小技巧: 在pycharm中如何快速获取文件的绝对路径
第一步: 在文件中右键点击Copy Path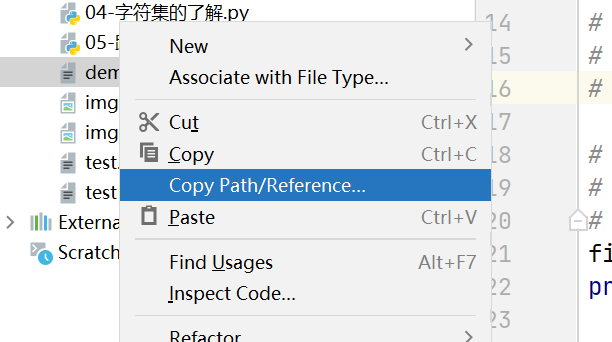
第二步: 选择你要获取的路径格式(绝对路径, 文件名称, 相对于工程目录的相对路径)
06-os模块介绍[了解]
# os模块 是操作系统模块 os就是operation system的缩写
# 这个模块中可以进行文件的创建,查询和修改等操作
# 注意: 所有内容不需要记忆,只要知道有这个功能就可以了
# 导包: 我们想要使用一个功能,我自己又没有实现,此时,可以使用别人写好的包,让别人书写的代码实现我们的需求
import os
# 1. os.getcwd() 获取当前文件所在目录的绝对路径
print(os.getcwd()) # C:\Users\admin\Desktop\Python+大数据基础班\03-授课资料\day09\代码
# 2.os.rename()
# 格式: os.rename(旧文件路径, 新文件路径)
# os.rename('test.txt', 'bigdata.txt')
# FileNotFoundError: [WinError 2] 系统找不到指定的文件。: 'test.txt' -> 'bigdata.txt'
# 当要修改的文件不存在时会报错
# 如果修改后的路径和当前源文件路径不在同一个路径下,则可以移动文件
# os.rename('bigdata.txt', 'chuanzhi/bigdata.txt')
# 3.os.remove() 删除文件
# 格式: os.remove(被删除文件路径)
# FileNotFoundError: [WinError 2] 系统找不到指定的文件。: 'demo.java'
# 如果被删除的文件不存在,则报错
# os.remove('demo.java')
# 4.os.listdir() 查询目录下所有文件的名称
# 当括号内什么也不写,则获取的就是当前文件所在的目录中的所有文件名称
print(os.listdir()) # ['.idea', '01-文件备份案例.py', '02-文件备份案例-字节型.py', '03-文件读写模式.py', '04-字符集的了解.py', '05-路径问题.py', '06-os模块的简单介绍.py', 'chuanzhi', 'img.png', 'img[副本].png', 'test[副本].txt']
# 当括号内书写路径时,则查看该路径下所有文件的名称
print(os.listdir('./chuanzhi')) # ['bigdata.txt', 'demo.java']
# NotADirectoryError: [WinError 267] 目录名称无效。: './chuanzhi/bigdata.txt'
# listdir括号内,必须放置目录信息,否则报错
# print(os.listdir('./chuanzhi/bigdata.txt'))
# 5.mkdir() 创建一个空的文件夹
# FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。: './study'
# 如果创建的目录已经存在,则会报错
os.mkdir('./study')
07-异常介绍[了解]
# 异常,就是代码在执行过程中出现的错误,会造成程序的终止
# 在开发中应尽量避免因异常造成的程序崩溃,异常不能完全避免,所以需要进行一定程度的处理.
# 异常时开发中的一种安全措施
# 如果所有的代码都不出现异常,会造成数据错误,服务混乱,业务问题,或者直接造成经济损失.
# 异常是让程序员在开发过程中,尽量多的发现自己代码中的问题,但是在上线后,需要尽量避免程序崩溃.
# 常见的异常类型
# NameError
# TypeError
# ValueError
# KeyError
# IndexError
# FileNotFoundError
# ...
08-异常捕获[熟练掌握]
# 在开发中,一般我们不希望异常造成程序崩溃,所以我们会使用ry...except进行异常捕获.
# 注意: 此时异常已经出现, 但是我们捕获异常后,程序不会崩溃.
"""
异常捕获的格式:
try:
可能出现异常的代码
except:
如果出现异常后,我们将会执行此处代码
# 异常处理完成后,继续执行后续代码
print('程序结束')
"""
# try不能单独出现,必须有except
try:
# ZeroDivisionError: division by zero 会出现异常,造成查程序终止运行
print(1 / 0)
# 在try中异常代码之后的代码将不会被执行,直接执行except中的命令,在开发中,try中的代码要尽可能的少
print('123')
except:
# 当代码运行到此位置,证明代码已经出现异常了.如果未出现异常此处代码不会被执行
print('出现异常了')
# NameError: name 'a' is not defined
# print(a)
# 如果except中的代码出现了异常,一样会终止程序运行
print('程序结束')
# 注意: try..except 不能阻止异常出现,但是可以在异常出现时,进行处理,防止由于异常出现是的程序终止或崩溃
09-捕获指定类型的异常[熟练掌握]
# 在出现异常时,通常在异常信息的最后一行会出现异常的类型及描述
# NameError: name 'a' is not defined
# print(a)
# 冒号之前是异常类型, 冒号之后是异常描述信息
# 例如:上述异常中NameError就是异常类型, name 'a' is not defined这个就是异常描述信息.
# 获取指定类型的异常的方法
"""
try:
可能出现异常的代码
except 异常类型:
出现该异常类型时执行的代码
"""
# # 异常捕获
# try:
# # print(a)
# # TypeError: unsupported operand type(s) for +: 'int' and 'str'
# # 如果指定了异常类型,则仅可以捕获该类型的异常,其他类型异常,依然会造成程序终止
# print(1 + '123')
# except NameError:
# print('出现了未定义的变量')
#
# print('程序结束')
# 问题1: 我们可以捕获多种类型的异常么?? 可以
"""
try:
可能出现异常的代码
except 异常类型1:
出现该异常类型时执行的代码
except 异常类型2:
出现该异常类型时执行的代码
except 异常类型3:
出现该异常类型时执行的代码
....
"""
# 异常捕获
# try中可能出现两种异常类型么???不可以,因为出现一个异常后,后续代码将不会继续执行,直接执行except中的代码
# 结论: 在异常捕获时,如果一个try中有多个except,也只能执行一个中的 代码.
try:
# print(1/0)
print(a)
# TypeError: unsupported operand type(s) for +: 'int' and 'str'
# 如果指定了异常类型,则仅可以捕获该类型的异常,其他类型异常,依然会造成程序终止
print(1 + '123')
except NameError:
print('出现了未定义的变量')
except TypeError:
print('不同数据类型间不能相加')
print('程序结束')
"""
try:
可能出现异常的代码
except (异常类型1,异常类型2,异常类型3...):
出现该异常类型时执行的代码
"""
try:
print(a)
print(1 + '123')
except (NameError, TypeError):
print('出现了异常可能是未定义变量,也可能是不同数据类型间不能相加')
# 问题2: 如果想要捕获未知异常我们该怎么做??? 指定异常类型为Exception
try:
print(1/0)
print(a)
# TypeError: unsupported operand type(s) for +: 'int' and 'str'
# 如果指定了异常类型,则仅可以捕获该类型的异常,其他类型异常,依然会造成程序终止
print(1 + '123')
except NameError:
print('出现了未定义的变量')
except TypeError:
print('不同数据类型间不能相加')
except Exception:
# 如果我们需要捕获未知异常,可以不加异常类型,或者指定异常类型为Exception(可以捕获所有异常类型)
print('出现了未知异常')
print('程序结束')
练习:
打开一个文件,读取其中的内容,
- 如果打开不成功报FIleNotFoundError 错误,我们就输出,您打开的文件不存在
- 如果打开了就读取其中的内容,并输出,读取完成
- 如果出现其他异常,就输出 代码出错了,我也不知道怎么回事
try: # FileNotFoundError: [Errno 2] No such file or directory: 'demo.txt' # 要打开的文件不存在 file = open('demo.txt', 'r', encoding='utf8') print(file.read()) print('读取完成') file.close() except FileNotFoundError: print('您打开的文件不存在') except Exception: print('代码出错了,我也不知道怎么回事')10-获取异常描述信息[熟练掌握]
```python异常的描述信息: 当异常出现后,错误内容最后一行中冒号后边的内容
NameError(异常类型): name ‘a’ is not defined(异常描述信息)
“”” 获取异常描述信息的格式: try: 可能出现异常的代码 except 异常类型1 as 变量名: print(变量名) 此时将会输出异常信息 except 异常类型2 as 变量名: print(变量名) 此时将会输出异常信息 …. “””
try:
# print(a)
print(1 / 0)
except NameError as error: print(error) except ValueError as error: print(error) except Exception as error: print(error)
思考: 上边不同的异常类型为什么可以使用同样的变量名呢?
不同的except中可以使用相同的变量名接收异常信息,因为同一个try中只能捕获一个类型的异常.
try: print(a) except (NameError, ValueError) as error: print(error)
只能有一个类型的error被触发,所以元组指向一个error变量就可以了.
<a name="JrSTi"></a>
# 11-异常中的else[熟悉]
```python
# else 在 异常中也是否则的意思, 当我们出现异常时,执行except中的命令,否则执行else中的命令
# except和 else只能执行其一,不可能全部执行
"""
else格式:
try:
可能出现异常的代码
except:
如果try中的代码出现了异常,将会执行该位置的代码
else:
如果try中的代码没有出现异常,将会执行该位置的代码
在开发中,except是必须的,但是else 可以没有
"""
try:
# a = 10
print(a)
except:
print('出现异常了')
else:
print('没有出现异常')
# 等价于:
try:
a = 10
print(a)
print('没有出现异常')
except:
print('出现异常了')
# 那为什么还要使用else呢??? 结构清晰,可读性强
12-异常中的finally[熟悉]
# finally:就是最后的意思, 也就是无论异常是否出现,最终都会执行finally中的命令
"""
finally格式:
try:
可能出现异常的代码
except:
try中的代码出现异常后执行这里的代码
else:
try中的代码没有出现异常时执行这里的代码
finally:
无论是否出现异常都会执行的代码
"""
try:
a = 10
print(a)
print(1 / 0)
except NameError:
print('出现异常了')
else:
print('没有出现异常')
finally:
print('无论是否出现异常都会执行')
# 如果把代码写到try...except结构之外,和finally有什么区别么?
# 当异常没有捕获成功时,finally中的代码依旧会执行,下方的内容不会被执行
try:
a = 10
print(a)
print(1 / 0)
except NameError:
print('出现异常了')
else:
print('没有出现异常')
print('无论是否出现异常都会执行')
# 利用其崩溃也会执行的特性,finally中可以赋值一些程序结束时必须要做的事情
# 1.将崩溃时间,崩溃原因,崩溃前的重要信息进行记录等,都可以卸载finally中
# 2.可以在finally中关闭文件.
当异常捕获失败,程序崩溃后,finally中的代码依旧执行
当异常捕获失败,程序崩溃后,try结构下方的代码不会被执行
作业
作业提交
文件链接
百度云盘: 链接:https://pan.baidu.com/s/13TqhouBQ8h1lP2VFtQHgMw 提取码:lh3d
阿里云盘:「python+大数据79期基础」等文件 https://www.aliyundrive.com/s/G6iPqGFQgfJ

若有收获,就点个赞吧
0 人点赞
