- 每日反馈
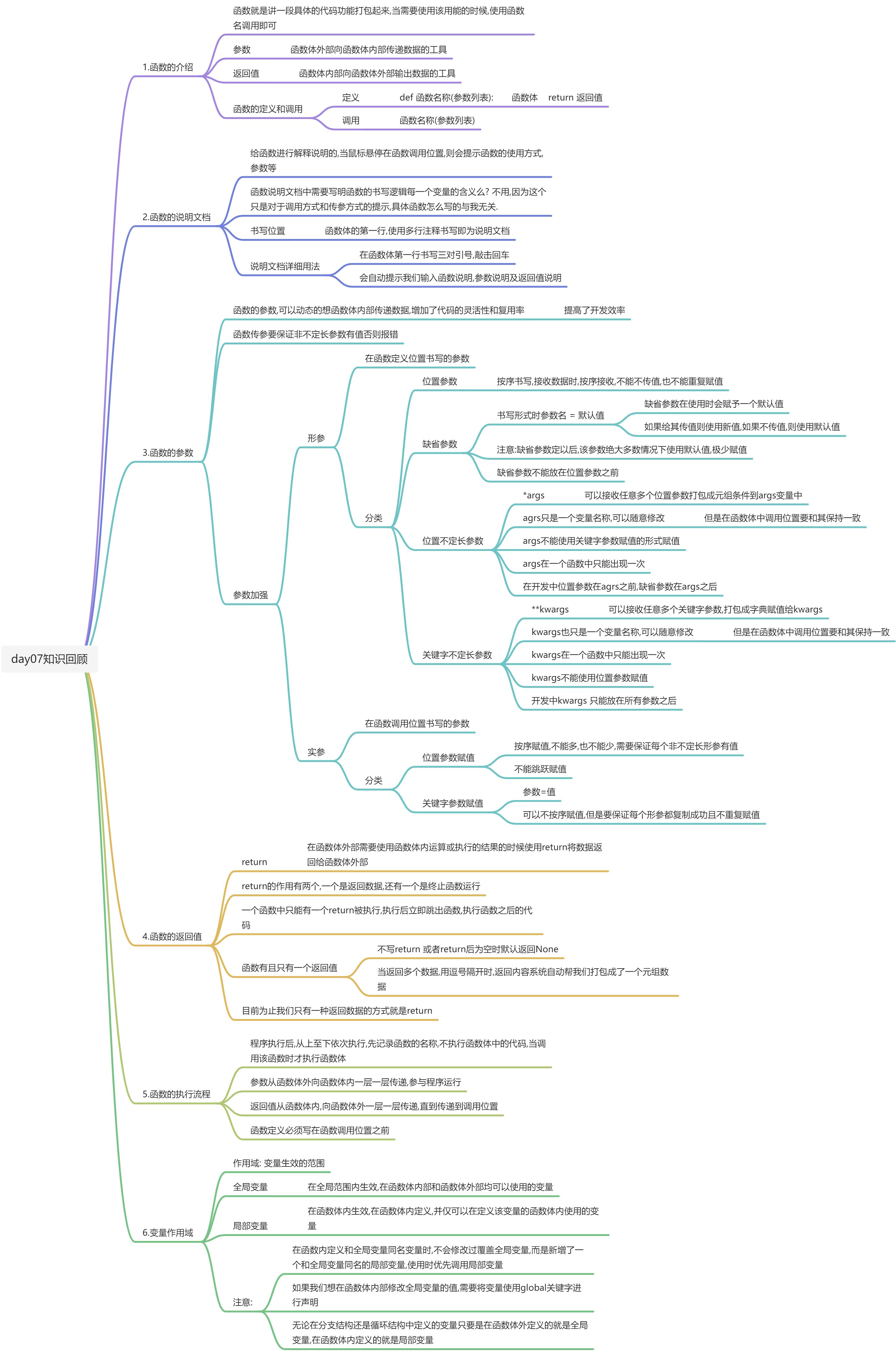
- day07知识回顾
- 00-今日课程内容
- 01-组包和拆包[熟悉]
- 组包(打包): 将多个数据,自动组合为一个数据的过程
- 当我们使用return进行返回多个数据时,自动组包(打包)成一个元组
- 我们使用一个变量,接收多个数值的时候,也会自动组包(打包)成一个元组
- 拆包(解包): 将一个数据拆分为多个数据的过程
- 使用多个变量接收一个容器(将一个容器中的元素依次赋值给多个变量),这种情况就是拆包
- 容器类型都可以进行拆包操作,但是,要注意,容器类型中拆包时,前方的变量数量,与容器内的元素数量要保持一致,否则报错.
- ValueError: too many values to unpack (expected 2)
- a, b = [1, 2, 3]
- ValueError: not enough values to unpack (expected 2, got 1)
- a, b = [1]
- 拆包在之前我们也用过
- 1.一次性给多个变量赋不同的值
- 首先将1,2,3组包为一个元组,然后将其拆包依次赋值给a,b,c
- 2.在遍历字典时,将一个item拆分给key 和value
- 遍历字典的items方法时每次获取的是一个元组,内部有两个元素,我们将其拆包依次赋值给key和value
- a, b, c = {3, 2, 1}
- 每一个不可变数据类型都可以使用哈希算法进行计算得到一个唯一的值(哈希算法是一个散列函数算法),用这个唯一的值当做数据标识符,如果重复则去重,如果不重复,则保存并根据哈希排序,取用数据时也根据哈希取用
- 交换数据位置
- 需求: 将num1 和num2进行位置互换
- 方法一: 引入空值变量(临时变量)
- 方法二: 组包和拆包
- 首先将等号右侧的num2,num1中的数据读取出来,组包为一个元组
- 将等号右侧的元组,解包依次赋值给等号左侧的变量
- 03-参数传递和赋值都是进行引用地址的传递[理解]
- 04-可变类型和不可变类型[理解]
- 05-函数解构(拓展)[了解]
- 06-lambda表达式[掌握]
- 07-递归[了解]
- 08-文件介绍[了解]
- 09-文件的读取操作[掌握]
- 10-文件的写入操作[掌握]
- 11-文件的追加操作[掌握]
- 作业
- 作业提交
- 文件链接
每日反馈
1.return作用就是讲函数运算或者执行的结果传递到函数体外部,当我们在函数体外部想要操作或者使用函数内部运算的结果的时候,我们就使用他,如果不需要则不用.
注意: 打印不算在外部使用(打印就相当于去ATM机取钱,余额显示在屏幕上,钱没有放在兜里,出门能用先进买菜么??? 但是用变量接收返回值,就相当于把钱放在兜里,出门可以随意使用)
day07知识回顾
00-今日课程内容
- 组包和拆包
- 引用
- 可变和不可变数据类型
- lambda函数和递归(了解)
- 文件读写操作
当我们使用return进行返回多个数据时,自动组包(打包)成一个元组
print(func1()) # (1, 2, 3)
我们使用一个变量,接收多个数值的时候,也会自动组包(打包)成一个元组
tuple1 = 1, 2, 3 print(tuple1) # (1, 2, 3)
拆包(解包): 将一个数据拆分为多个数据的过程
使用多个变量接收一个容器(将一个容器中的元素依次赋值给多个变量),这种情况就是拆包
a, b = [1, 2] print(a, b) # 1 2
a, b = ‘12’ print(a, b) # 1 2
a, b = {‘a’: 1, ‘b’: 2} print(a, b) # a b 字典拆包时,会将字典的键拆给每一个变量
容器类型都可以进行拆包操作,但是,要注意,容器类型中拆包时,前方的变量数量,与容器内的元素数量要保持一致,否则报错.
ValueError: too many values to unpack (expected 2)
a, b = [1, 2, 3]
ValueError: not enough values to unpack (expected 2, got 1)
a, b = [1]
拆包在之前我们也用过
1.一次性给多个变量赋不同的值
首先将1,2,3组包为一个元组,然后将其拆包依次赋值给a,b,c
a, b, c = 1, 2, 3
2.在遍历字典时,将一个item拆分给key 和value
dict1 = {‘a’: 1, ‘b’: 2}
遍历字典的items方法时每次获取的是一个元组,内部有两个元素,我们将其拆包依次赋值给key和value
for key, value in dict1.items(): print(key, value)
a, b, c = {3, 2, 1}
a, b, c = {‘Tom’, ‘Bob’, ‘Rose’} print(a)
每一个不可变数据类型都可以使用哈希算法进行计算得到一个唯一的值(哈希算法是一个散列函数算法),用这个唯一的值当做数据标识符,如果重复则去重,如果不重复,则保存并根据哈希排序,取用数据时也根据哈希取用
交换数据位置
num1 = 10 num2 = 20
需求: 将num1 和num2进行位置互换
方法一: 引入空值变量(临时变量)
temp = num1 num1 = num2 num2 = temp
print(num1) print(num2)
print(‘-‘ * 30)
方法二: 组包和拆包
num1, num2 = num2, num1 print(num1) print(num2)
首先将等号右侧的num2,num1中的数据读取出来,组包为一个元组
将等号右侧的元组,解包依次赋值给等号左侧的变量
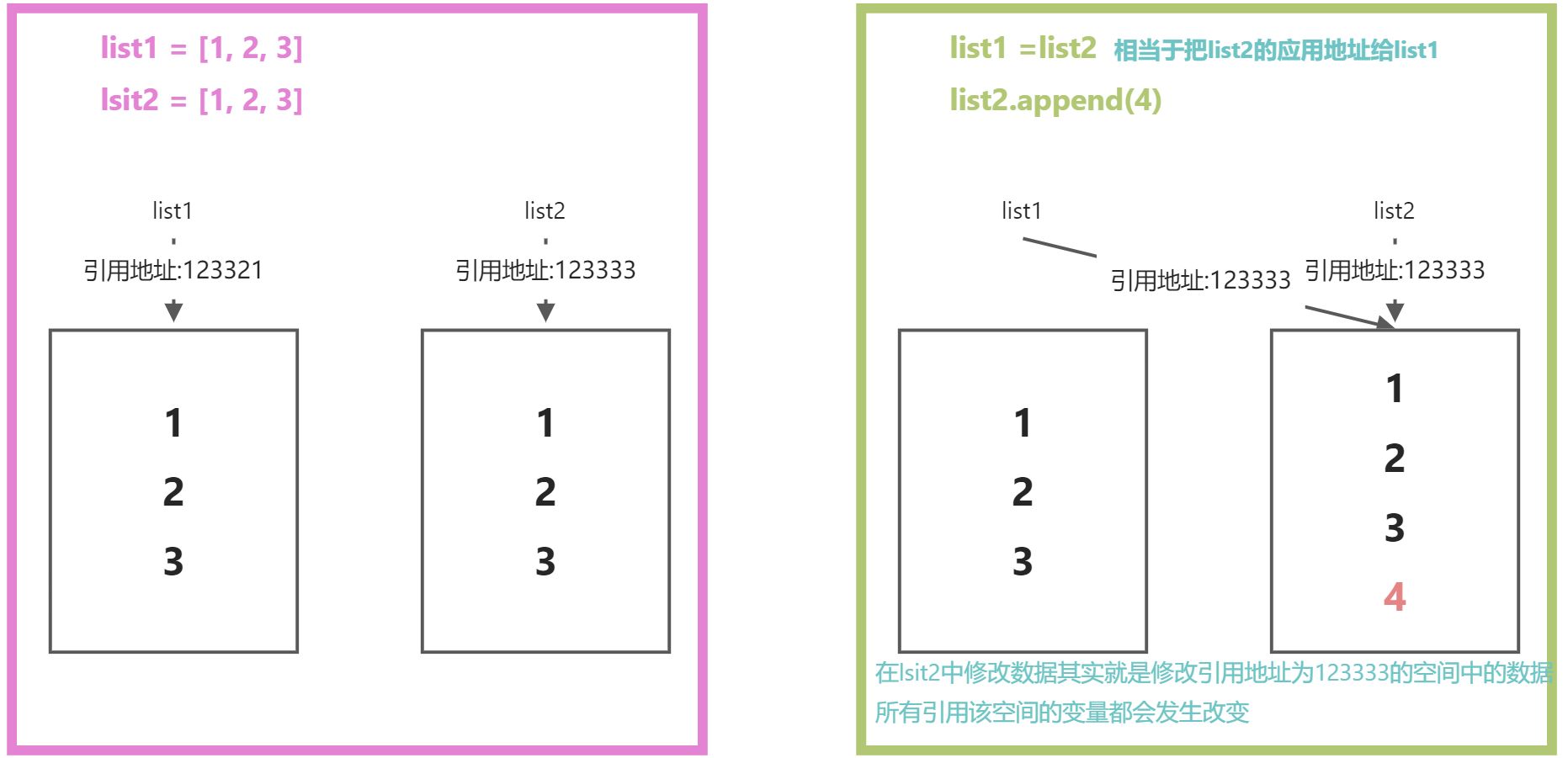
<a name="edKNk"></a># 02-引用[掌握]```python# 引用: 其实引用就是变量和数据之间的一种关联关系# 例如:a=1 此时我们将数据1,赋值给了a, a就引用了1# 数据赋值给变量,变量和数据建立的关联关系,我们就说这个变量引用了这个数据# a = 1# b = 1# 思考: a ,b 引用的是同一个数据么?# list1 = [1, 2, 3]# list2 = [1, 2, 3]# 思考: list1, 和list2,引用的是同一个数据么?# 我们要学习怎样判断数据相同??? 通过id(数据的唯一标识) 或者叫做引用地址# 1.数据类型相同,一定是同一个数据么? 不一定# print('123', 'abc')# 2.数据的值相同,一定是同一个数据么? 不一定print(True == 1) # True# 3.数据的值相同,数据类型也相同,他们一定是同一个数据么? 不一定list1 = [1, 2, 3]list2 = [1, 2, 3]# 在lsit1中追加一个4list1.append(4)# 修改list1,list2无变化,说明此时list1和list2不是同一个数据(不是同一块内存空间)print(list1) # [1, 2, 3, 4]print(list2) # [1, 2, 3]# 4.怎样判断两个变量中保存的是同一个数据呢??? 内存地址相同# 在python中将内存地址进行了包装,引入了引用地址的概念,也就是id 是使用内存地址计算出的一个十进制唯一标识# 所以我们可以通过id判断两个变量引用的是同一块内存空间中的数据# 获取引用地址的方式 是idlist3 = [1, 2, 3]list4 = [1, 2, 3]# 此时两个变量引用数据的id 不一致,所以不是同一数据print(id(list3)) # 2048152991808print(id(list4)) # 2048150426816print('-' * 50)list5 = list3# list3 和list5 引用地址相同,保存的是同一个数据# 每次运行引用地址均会变化,因为内存地址每次运行程序都会随机分配print(list5, id(list5)) # 1317693971008print(list3, id(list3)) # 1317693971008list3.append(4)# 修改list3, list5也会变化 且引用地址依然相同print(list5, id(list5)) # [1, 2, 3, 4] 2320438422016print(list3, id(list3)) # [1, 2, 3, 4] 2320438422016# 结论:# 1. 两个变量保存相同的引用地址,则变量一定引用同一数据,# 2. 两个变量引用地址相同,修改其中一个变量内存空间中的数据,另外一个也发生变化# 3. 判断两个引用地址是否相同,可以使用id 相等,也可以使用is 关键字print(list3 is list5) # Trueprint(list3 is list4) # False
03-参数传递和赋值都是进行引用地址的传递[理解]
当我使用=号进行赋值时,引用地址可能会发生变化,当我不使用等号时,所有的操作都不会修改引用地址.
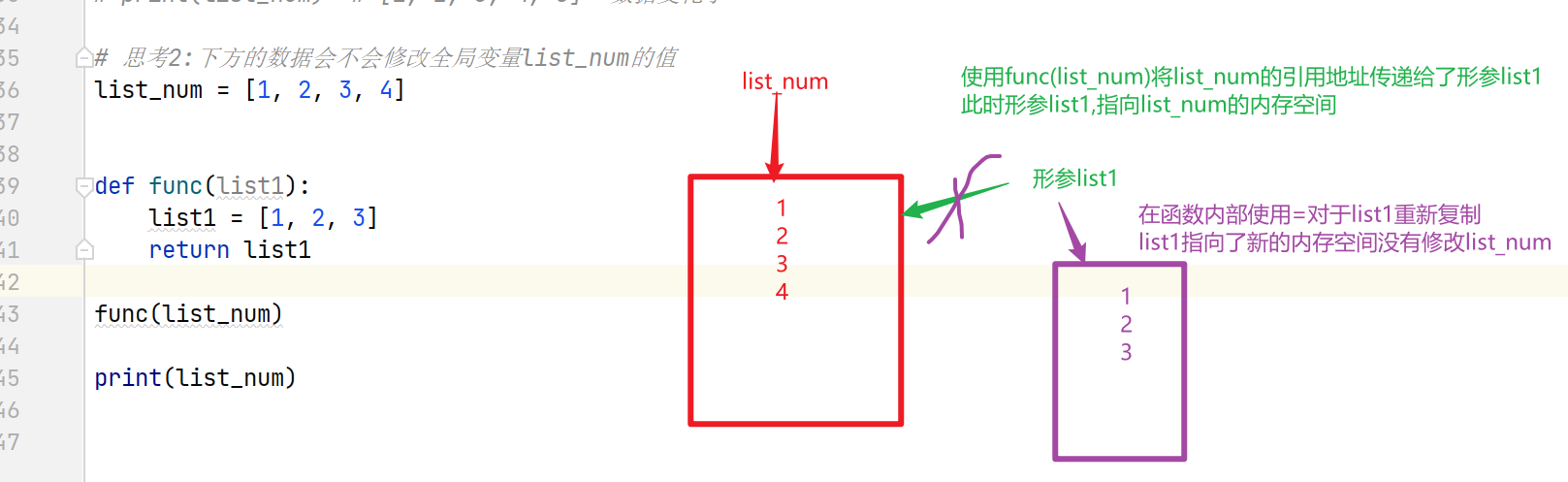
# 思考:list1 = [1, 2, 3]list2 = [1, 2, 3]list1.append(3)list2 = list1list1 = [1, 2, 3, 4]print(list1) # [1, 2, 3, 4]print(list2) # [1, 2, 3, 3]# 规律: 当我使用=号进行赋值时,引用地址可能会发生变化,当我不使用等号时,所有的操作都不会修改引用地址.# 使用等号赋值,其实就是将等号右侧的值或变量的引用地址赋值给变量,当我们调用变量时,系统会根据引用的值,查找到相对应的数据str1 = '123'str2 = '123'# 思考: str1 和str2 引用地址是否相同?# str数据类型内部空间中的数据不可修改,系统默认只要数据相同引用地址就想通,换句话说此时相同数据在内存中只保存了一份,节省系统性能.print(str1 is str2) # True# 思考1: 下方的数据会不会修改全局变量list_num的值list_num = [1, 2, 3, 4]def func(list1):list1.append(5)# 将list_num的引用地址传递给list1,则list1引用的内存空间和list_num一致,修改其值,lsit_num也变化func(list_num)print(list_num) # [1, 2, 3, 4, 5] 数据变化了# 思考2:下方的数据会不会修改全局变量list_num的值list_num = [1, 2, 3, 4]def func(list1):list1 = [1, 2, 3]return list1func(list_num)print(list_num)# 思考3: 下方的数据会不会修改全局变量list_num的值list_num = [1, 2, 3, 4]def func(list1):# 定义了一个和list_num同名的局部变量,无法修改全局变量的值,如果需要修改使用globallist_num = [1, 2, 3]func(list_num)print(list_num)# 思考: 为什么在思考1中不需要使用global就可以修改全局变量的值# 使用global修饰是为了证明我们使用的是全局变量,全局变量和局部变量的引用地址不相同# 但是思考1中,从头到尾没有修改引用地址,所以不需要使用global# 总结: 如果想在函数内部修改全局变量的引用地址需要使用gloabl 否则不需要

04-可变类型和不可变类型[理解]
如果可以修改内存空间中的数据那就是可变数据类型,反之就是不可变数据类型
如果不适用赋值符号,可以修改变量中的值,则该值储存的是可变数据类型,反之是不可变数据类型
# 不可变数据类型: 数据所在的内存空间中的数据不可被修改,则为不可变数据类型# 可变数据类型: 数据所在的内存空间中的数据可以被修改,则为可变数据类型# 可变数据类型: 可以进行数据空间的读写操作(增删改查)# 不可变数据类型: 只能进行数据空间的数据读取操作(查)# 可变数据类型: 列表,字典,集合# 不可变数据类型: 整型, 浮点型, 布尔值, 字符串, 元组# 怎样确定是在数据空间内修改了呢???# 我们使用任何方法,只要是不用赋值符号 可以将变量的值修改,就是在数据空间内修改了list1 = [1, 2, 3]list1.append(4)print(list1)str1 = '123'result = str1.replace('2', '4')print(str1)print(result)# 注意: 在内存中不可变数据类型如果值相同一般引用地址也相同list1 = [1, 2, 3]list2 = [1, 2, 3]print(list1 is list2) # Falsetuple1 = (1, 2, 3)tuple2 = (1, 2, 3)print(tuple1 is tuple2) # True# 举例: 不需要探讨为什么, 只需要知道有特例就可以了# print(id('1234'))# print(id('123' + str(4)))
05-函数解构(拓展)[了解]
# *代表什么??? 代表拆包list1 = [1, 2, 3]def func1(a, b, c):print(a + b + c)# 需求: 将list中的元素依次赋值给a, b, c# 方式一: 可以通过列表索引进行赋值# func1(list1[0], list1[1], list1[2])# 方式二: 优雅赋值 使用函数解构来进行赋值func1(*list1)# 等价于,* 就是讲容器外层的括号拆掉,将容器内的数据依次赋值给每一个形参(手动拆包)func1(1, 2, 3)# def func2(*args):# print(args)### func2(1, 2, 3, 4)## # 思考: 上述函数中*args = 1,2,3,4 args = (1,2,3,4)# ** 拆包两次dict1 = {'a': 1, 'b': 2, 'c': 3}def func1(a, b, c):print(a + b + c)# 如果使用* 对于字典进行解构# 拆一次: *dict1 >>> 'a','b','c'# func1(*dict1)# 拆两次: **dict1 >>> a = 1, b = 2, c = 3# 相当于关键字参数赋值func1(**dict1)def func3(**kwargs):print(kwargs)func3(a=1, b=2, c=3)
06-lambda表达式[掌握]
# lambda表达式是函数定义的一种特殊形式
# 我们也称其为匿名函数,定义格式和def即为不同,在定义函数时不需要指定函数名称.
# 格式: lambda 参数列表: 返回值
# 需求: 创建一个函数,输入两个数字, 通过计算返回两个数字的和
# def 定义:
def sum1(a, b):
return a + b
# 调用
print(sum1(1, 2)) # 3
# lambda 定义:
lambda a, b: a + b # 此时没有函数名称也就没有被保存,如果不使用,将会立即被释放掉
# 调用
# 方式1: 直接调用,不需要定义函数名称,但是只能调用一次,下一次使用需要重新定义lambda函数
# 格式:(lambda表达式)(实参1,实参2,....)
print((lambda a, b: a + b)(1, 2))
# 方式2:使用变量接收lambda表达式,并使用变量名称调用函数 可以使用多次
# 格式: 变量 = lambda表达式 >>>> 调用时 变量名(实参1, 实参2....)
sum2 = lambda a, b: a + b
print(sum2(1, 2))
print(sum2(4, 5))
print(sum2(4, 5) + sum2(1, 3))
# lambda表达式的应用场景
# 1.简化代码
# 2.可以当做参数进行传参(这种场景最常出现)
# 3.使用变量保存,将定义和使用放在一起可读性更高
# sort
list1 = [2, 3, 7, 4, 5, 9]
# 升序
list1.sort()
print(list1)
# 降序
list1.sort(reverse=True)
print(list1)
list2 = [(3, 4), (2, 1), (5, 3), (6, 2)]
# 需求: 自定义规则进行排序,让list2按照元组中下标为1的元组大小进行升序排列
# 举例: (3,4) > (5,3)
# 格式: 列表.sort(key=lambda 遍历每一个元素传递到这里: 根据什么规则进行排序) 根据自定义规则进行排序,规则一般是lambda表达式
# 解释: sort(key=lambda x: x[1]) 遍历列表, 每次将一个元素传入lambda中,用x接收,我么你返回一个数据,系统会根据我们返回数据的大小对于元素进行排序
list2.sort(key=lambda x: x[1])
print(list2) # [(2, 1), (6, 2), (5, 3), (3, 4)]
# 如果不使用lambda怎么办?
def func1(x):
return x[0]
list2.sort(key=func1, reverse=True)
print(list2)
# lambda 并不是非用不可,但是建议掌握,如果别人书写,我们要能看懂
练习:
- 使用lambda表达式,随机传入任意多个数据,计算数据和,使用两种方式调用
- 使用lambda表达式,计算a和b中较大的值并返回结果(选做)
lambda 的缺点:
# 练习:
# 1. 使用lambda表达式,随机传入任意多个数据,计算数据和,使用两种方式调用
# def中可以使用的参数类型,在lambda中都可以使用
# 方式1: 直接调用
print((lambda *args: sum(args))(1, 2, 3, 4, 5))
# 方式2: 使用变量接收后调用
func1 = lambda *args: sum(args)
print(func1(1, 2, 3, 4, 5))
# 2. 使用lambda表达式,计算a和b中较大的值并返回结果(选做)
# 使用max函数
func2 = lambda a, b: max(a, b)
print(func2(3, 7)) # 7
# 三目运算
func3 = lambda a, b: a if a > b else b
print(func3(3, 7))
# lambda的缺点:
# 1.如果函数结构或者功能非常复杂,则无法使用lambda完成,使用lambda表达式创建的函数只能返回一个返回值,不能进行判断或者循环结构的书写
# 2.可读性较差,一般建议写过于复杂的lambda
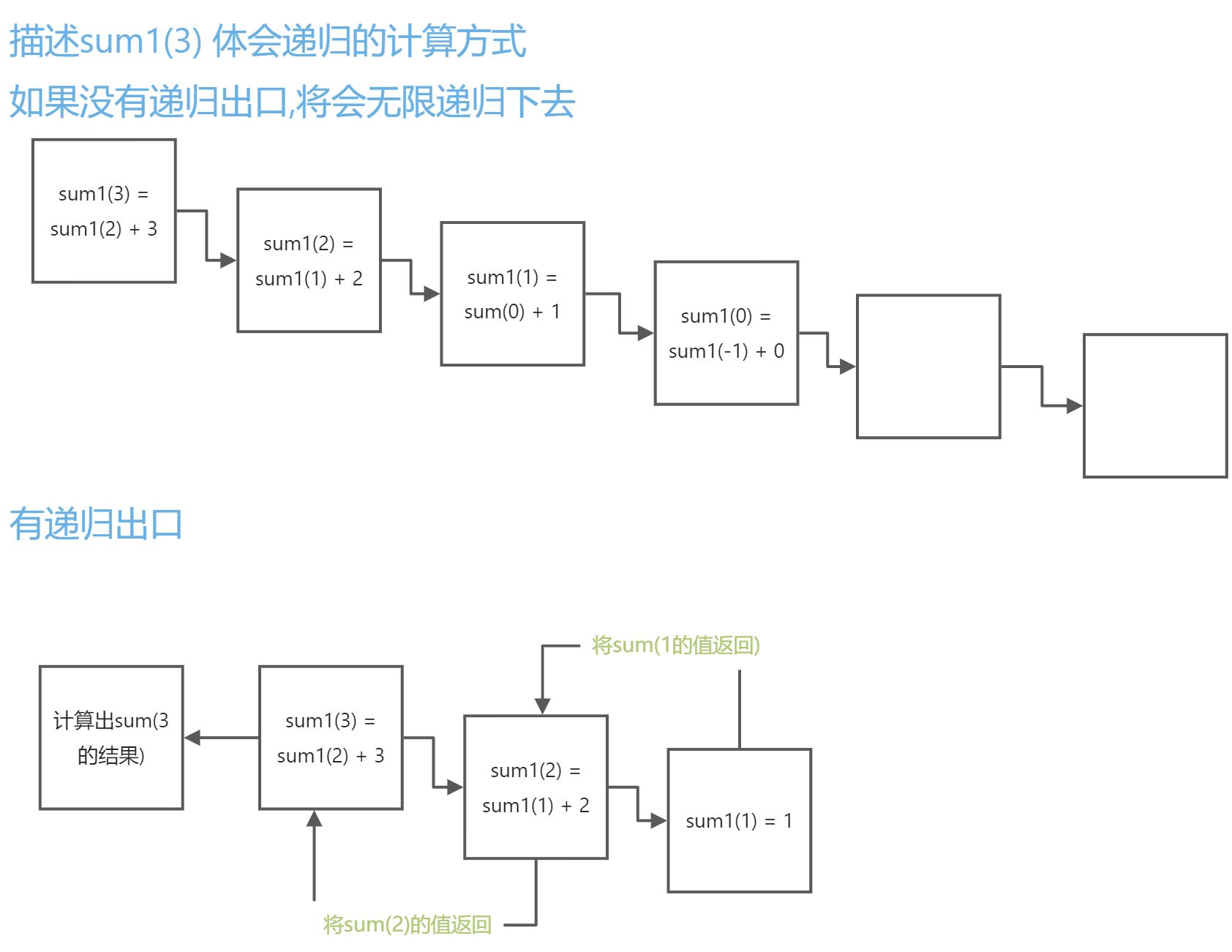
07-递归[了解]
# 递归不需要同学们掌握,只是有个概念就可以了
# 递归是一种算法:
# 算法: 将数学知识转换为编程代码用于实现某种功能的思想.
# 需求: 计算1-100的累加和
"""
f(1) = 1
f(2) = 1 + 2 = f(1) + 2
f(3) = 1 + 2 + 3 = f(2) + 3
f(4) = 1 + 2 + 3 + 4 = f(3) + 4
....
f(n) = 1 + 2 + 3.... + n = f(n-1) + n
最终规律: f(n) = f(n-1) + n 初中二年级
"""
# 使用该规律书写函数
# def sum1(n):
# """计算1-n的累加和"""
# return sum1(n-1) + n
#
# # RecursionError: maximum recursion depth exceeded
# # 递归时,我们会在函数体内部调用函数本身,如果没有明确的跳出条件,将会无限递归下去,就会报错
#
# sum1(100)
# 如果我们不希望无限递归下去,则可以在指定的条件下设置递归出口,结束递归
def sum1(n):
"""计算1-n的累加和"""
if n == 1:
return 1
return sum1(n - 1) + n
print(sum1(100)) # 5050
# 注意: 开发中尽量不要使用递归
# 1.递归效率极低
# 2.递归的业务场景不常见
# 3.极易出错
08-文件介绍[了解]
# 文件就是保存在磁盘上的,需要重复使用的数据或功能,我们将其称为文件.
# word excel 都是文件. 我们根据文件的扩展名不同区分文件的类型.
# 思考: 变量是文件么? 不是,因为其不再磁盘中而是在内存中.
# 文件的读写操作本质: 说的就是从文件中读取数据,加载到内存中,再从内存中向磁盘写入数据.
# 现实中使用windows读写文件的步骤:
# 1.打开文件
# 2.读写文件
# 3.关闭文件
# 使用代码读写文件的步骤相同:
# 1.打开文件
file = open('python.txt', 'r', encoding='utf8')
# 2.读写文件
print(file.read())
# 3.关闭文件
file.close()
09-文件的读取操作[掌握]
"""
步骤:
1.打开文件
格式: 变量 = open(文件路径, 读写模式, 指定编码集) 这个函数会返回一个file对象,需要使用变量接收
2.读取文件
格式:
文件对象.read(n)
文件对象.readline()
文件对象.readlines()
3.关闭文件
格式: 文件对象.close() 文件关闭后不能再继续操作
"""
# 1.打开文件 如果我们希望读取到文件,读写模式就是写入模式 用 r代表
# encoding 指定编码集
file = open('python.txt', 'r', encoding='utf8')
# 被读取的文件必须存在,不存在就报错
# FileNotFoundError: [Errno 2] No such file or directory: 'bigdata.txt'
# file = open('bigdata.txt', 'r', encoding='utf8')
# 2.读取文件内容
# 读取方式1:文件对象.read(n)
# 如果read的括号内什么也不写,则默认将所有数据都读取出来
# content = file.read()
# 如果再read的括号内填写数字,则为当前读取的最大字符数
# 如果我们打开一次文件,多次使用read进行读取,将会沿着上一次读取的位置继续向后读取
# content = file.read(3)
# print(content) # 花谢花
# content = file.read(3)
# print(content) # 飞花满
# 读取方式2:文件对象.readline()
# 使用readline一次读取一行数据,下一次读取,会按照这一次读取到的位置继续向下读取
# content = file.readline()
# print(content)
# content = file.readline()
# print(content)
# 读取方式3:文件对象.readlines()
# 将所有的数据全部读取出来,每一行作为一个元素,放入到列表中
content = file.readlines()
print(content) # ['花谢花飞花满天,\n', '红消香断有谁怜.']
# 3.文件关闭
file.close()
# 为什么要关闭文件??
# 1.理论每一个进程只能开启1024个文件,如果不关闭迟早占满.
# 2.如果file对象使用结束后程序也结束了,资源不会立即释放,需要等待一段时间.
# 3.如果不关闭,文件句柄就释放不掉,文件不能删除或移动
# 4.如果不关闭文件,当系统资源占满时会选择已经很久不用的资源自动关闭,此时可能会造成文件损坏.
# 注意:
# 1.打开文件要关闭
# 2.在开发中read应用的最多,readline偶尔用, readlines 几乎不用
练习: 自己写一个文件读取代码, 创建一个txt格式文件, 内部书写一首诗,并读取出来
10-文件的写入操作[掌握]
"""
步骤:
1.打开文件
格式: 变量 = open(文件路径, 读写模式, 指定编码集) 这个函数会返回一个file对象,需要使用变量接收,写入模式是w
2.写入文件
格式:
文件对象.write(要写入的内容)
文件对象.writelines(列表(内部为字符串数据))
3.关闭文件
格式: 文件对象.close() 文件关闭后不能再继续操作
"""
# 1.文件打开
# 解释:我们文件读取的时候使用的是utf8编码,所以我们文件写入的时候也必须使用这个编码.
# 当我们使用w模式打开文件时,原数据将会被清空,等待你写入新的数据内容
# file = open('python.txt', 'w', encoding='utf8')
# 思考:如果文件不存在,我们执行写入命令会怎样? 不会报错,会新建指定文件名称的文件
file = open('bigdata.txt', 'w', encoding='utf8')
# 2.写入数据
# 写入方式1:write(写入内容)
# file.write('欲渡黄河冰塞川,将等太行雪满山')
# 写入方式2:writelines(写入内容)
# 这种方式使用场景不多,一般是配合readlines进行使用
file.writelines(['花谢花飞花满天,\n', '红消香断有谁怜.'])
# 问题:此处能否进行读取????
# io.UnsupportedOperation: not readable
# 写入模式下,无法读取数据,同理读取模式下也无法写入数据
# print(file.read())
# 3.关闭文件
file.close()
# 如果文件关闭了还能够写入数据么?
# ValueError: I/O operation on closed file.
# 不能操作一个已经关闭的文件
# file.write('传智播客')
11-文件的追加操作[掌握]
文件的追加操作和写入操作基本一致, 唯一不同的,就是追加模式下不会清空源数据,而是在原来的数据末尾继续追加数据.
"""
步骤:
1.打开文件
格式: 变量 = open(文件路径, 读写模式, 指定编码集) 这个函数会返回一个file对象,需要使用变量接收,追加模式是a
2.写入文件
格式:
文件对象.write(要写入的内容)
文件对象.writelines(列表(内部为字符串数据))
3.关闭文件
格式: 文件对象.close() 文件关闭后不能再继续操作
"""
# 1.文件打开
# 问题: 打开文件时,文件不存在会怎么样? 会新建文件
# file = open('chuanzhi.txt', 'a', encoding='utf8')
# 文件存在时数据会被清空么? 不会,原数据依然存在
file = open('chuanzhi.txt', 'a', encoding='utf8')
# 2.追加数据
# AttributeError: '_io.TextIOWrapper' object has no attribute 'append'
# a模式下没有append方法,我们还是用wirite进行写入
# file.append('举头望明月,低头思故乡.')
# 操作方式1: write 一次写入一个字符串信息
# 追加模式下,不会覆盖原来的数据内容,而是在原数据的末尾追加新的字符串信息.
# file.write('举头望明月,低头思故乡.')
# 操作方式2: writelines 一次写入一个字符串列表
file.writelines(['传智教育好,\n', '工作真好找\n', '如果找不到\n', '陪你学到老'])
# 追加模式可以读取数据么? 不能
# io.UnsupportedOperation: not readable
# print(file.read())
# 3.关闭文件
file.close()
作业
提交你认为自己做的最好的一天笔记
作业提交
文件链接
百度云盘: 链接:https://pan.baidu.com/s/13TqhouBQ8h1lP2VFtQHgMw 提取码:lh3d
阿里云盘:「python+大数据79期基础」等文件 https://www.aliyundrive.com/s/G6iPqGFQgfJ

若有收获,就点个赞吧
0 人点赞
