- 每日反馈
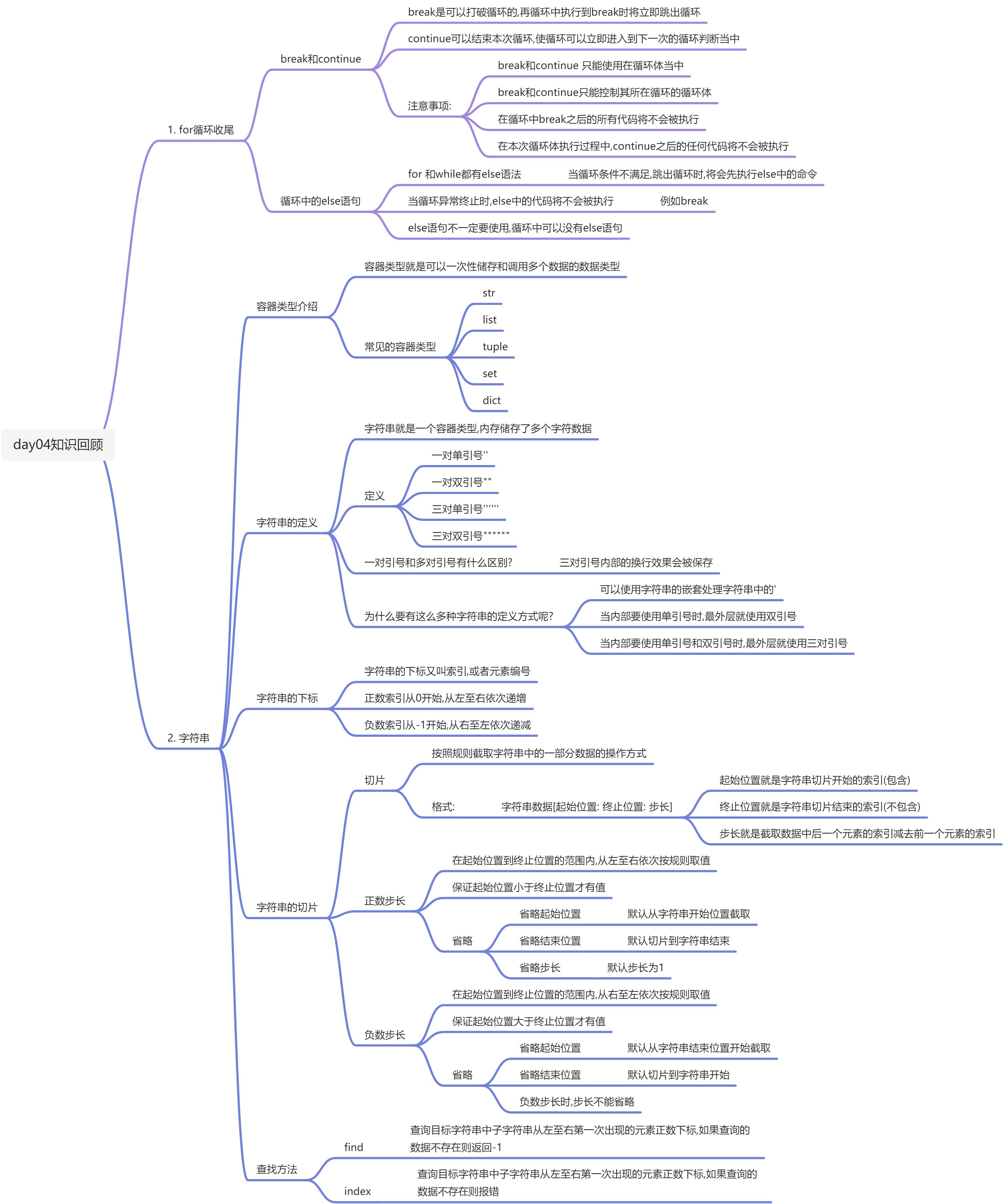
- day04知识回顾
- 0-今日知识内容
- 01-字符串替换-replace[熟练使用]
- replace() 替换方法:用于替换目标字符串中的指定字符串
- 格式: 字符串数据.replace(old(旧字符串), new(新字符串), count(指定替换次数))
- 需求1: 将字符串中所有的o都替换为 ,如果不填写替换次数,则默认将所有的o都替换为
- 需求2: 将字符串中的前三个o都替换为$符号
- 日过替换次数大于字符串总数,则将其全部替换且不会报错
- 需求3: 将字符串中所有的hello 替换为hi
- 注意:
- 1.替换前后字符数量可以不相等.
- 2.如果旧字符串在目标字符串中不存在,则不会进行替换也不会报错
- 3. 进行replace替换时,原数据没有发生任何变化,而是产生了一个新的字符串.如果不使用,也不用变量进行接收,则新产生的字符串就消失了.
- 03-字符串的应用[熟悉]
- 04-字符串方法的补充[了解]
- 05-字符串中数据的判断方法[了解]
- 06-列表的定义及下标[熟练使用]
- 07-列表的遍历[熟练使用]
- 08-列表的增操作[掌握]
- 列表中可以对于元素进行增删改查操作,所以同一个列表在不用的时间点,列表中元素的个数,元素的值均可能不相同
- 定义一个列表
- append(元素值) 将元素值追加到列表的末尾,一次只能添加一个数据元素
- 给列表追加元素时,并没有新的数据容器产生,而是在原数据的基础上进行了修改
- print(list1.append(4)) # None 在python中None代表空类型,表示没有任何数据.
- TypeError: list.append() takes exactly one argument (2 given)
- 一次只能追加一个元素,否则报错
- list1.append(5,6)
- extend(容器类型数据) 将数据容器中的每一个元素依次追加到列表末尾,可以一次追加多个数据
- 给列表扩展数据的时候不会产生新的数据容器,而是在原数据容器中进行修改
- print(list1.extend(‘abc’)) # None
- extend会将容器类型数据遍历,依次将每一个元素追加
- append追加数据时,会将容器类型作为一个数据元素追加到列表末尾
- 注意: extend括号内,只能填写容器类型数据
- TypeError: ‘int’ object is not iterable(可遍历)
- list1.extend(1)
- list1.extend(‘1’) # 哪怕字符串中只有一个元素,也是容器类型数据
- list1.extend(‘’) # 哪怕容器类型为空也不会报错
- print(list1) # [1, 2, 3, 4, ‘a’, ‘b’, ‘c’, ‘abc’, ‘1’]
- insert(索引位置, 元素值) 将元素添加到指定的索引位置
- 需求: 在下标为2的位置插入一个数字5
- 插入数据后,下标为2的位置数据改变为5,原来下标为2及其之后的数据向后移动一位,下标统一+1
- 注意:
- 1.insert插入的下标必须符合下标连续的要求,如果插入的位置远大于列表下标范围,则自动插入到列表末尾
- 2.insert不安全, append 和extend 不会影响插入数据之前的元素的索引值,但是insert可能会影响
- 3.insert在开发中使用场景少于append,因为绝大多数情况下列表储存的数据量巨大,我们不需要控制其顺序
- 10-列表的删除操作[掌握]
- 11-列表的修改操作[掌握]
- 12-列表的逆转和排序[熟悉]
- 13-列表的嵌套[熟悉]
- 作业
- 作业提交
- 文件链接
每日反馈
| 老师太棒了 |
|---|
day04知识回顾
0-今日知识内容
- 字符串
- replace替换
- split拆分
- 字符串的判断方法
- 字符串的其他常用方法
- 列表
- 列表的定义
- 列表的增
- 列表的删
- 列表的改
- 列表的查
- 元组
需求1: 将字符串中所有的o都替换为 ,如果不填写替换次数,则默认将所有的o都替换为
print(str1.replace(‘o’, ‘‘)) # hell pythn hell bigdata hell 传智 hell 中国!!!!
需求2: 将字符串中的前三个o都替换为$符号
print(str1.replace(‘o’, ‘$’, 3)) # hell$ pyth$n hell$ bigdata hello 传智 hello 中国!!!!
日过替换次数大于字符串总数,则将其全部替换且不会报错
print(str1.replace(‘o’, ‘%’, 50)) # hell% pyth%n hell% bigdata hell% 传智 hell% 中国!!!!
需求3: 将字符串中所有的hello 替换为hi
print(str1.replace(‘hello’, ‘hi’)) # hi python hi bigdata hi 传智 hi 中国!!!!
注意:
1.替换前后字符数量可以不相等.
2.如果旧字符串在目标字符串中不存在,则不会进行替换也不会报错
print(str1.replace(‘study’, ‘hi’)) # hello python hello bigdata hello 传智 hello 中国!!!!
3. 进行replace替换时,原数据没有发生任何变化,而是产生了一个新的字符串.如果不使用,也不用变量进行接收,则新产生的字符串就消失了.
print(str1) # hello python hello bigdata hello 传智 hello 中国!!!!
<a name="jwzk6"></a># 02-字符串的拆分-split[熟练使用]```python# split() 将一个字符串,按照指定的分隔符,拆分为多个字符串,并保存到一个列表中的方法.# 格式: split(sep(指定分隔符), maxsplit(最大拆分次数))str1 = 'hello python hello bigdata hello 传智 hello 中国!!!!'# 需求1: 将str1以空格为分隔符,拆分为多个字符串并保存到列表中print(str1.split(' ')) # ['hello', 'python', 'hello', 'bigdata', 'hello', '传智', 'hello', '中国!!!!']# 需求2: 将str1以o为分隔符,拆分为多个字符串并保存到列表中print(str1.split('o')) # ['hell', ' pyth', 'n hell', ' bigdata hell', ' 传智 hell', ' 中国!!!!']# 1.以谁为分隔符,谁就消失了# 2.不指定最大拆分次数,默认拆完# 需求3: 将str以空格进行拆分,拆分为4部分,并保存到列表中# 分析: 拆分为四部分要拆几次? maxsplit要填写几?3次print(str1.split(' ', 3)) # ['hello', 'python', 'hello', 'bigdata hello 传智 hello 中国!!!!']# 指定拆分次数后,将从左至右按照分隔法进行拆分指定的次数# 需求4: 如果我再split的括号中什么也不写,最终将按照什么分隔符进行拆分呢?print(str1.split()) # ['hello', 'python', 'hello', 'bigdata', 'hello', '传智', 'hello', '中国!!!!']# 默认以空白为分割符进行拆分:(python中的空白包含空格, \t, \n,以及他们的组合)str2 = '传 智\t \n 教育\n'# 使用空格为分隔符拆分数据, 有几个分隔符,就会拆分为分隔符+1份# print(str2.split(' ')) # ['hello', 'python', 'hello', 'bigdata', 'hello', '传智', 'hello', '中国!!!!']# split中什么也不行进行拆分print(str2.split()) # ['传', '智', '教育']# 在开发中我们绝大多数情况下都使用的是其默认的分隔方式,很少指定分隔符.
03-字符串的应用[熟悉]
# 需求: 输入一个文件名称,根据扩展名判断该文件是否为txt格式文件
#分析:txt格式文件的文件名中,结尾一定是.txt
# 1.获取用户输入的文件名称:
file_name = input('请输入您要判断的文件名称:')
# 2.获取结尾的字符
# 方法一: 切片
end_word = file_name[-4:]
print(end_word)
# 方法二: split
end_word = file_name.split('.')
print(end_word[-1])
# 3.判断其是否为txt格式文件
if end_word == '.txt':
print('该文件是txt文件')
else:
print('该文件不是txt文件')
练习: 有如下字符串,将所有的o的位置输出,并替换为a
# 有如下字符串,将所有的o的位置输出,并替换为a
str1 = 'hello python'
# while
start = -1
while True:
start = str1.find('o', start + 1)
if start == -1:
print('查询结束')
break
else:
print(start)
# str1的替换,需要放在循环体之外,因为替换时一次性将所有的o都替换为了a
# 如果卸载内部,要控制其替换的次数
str1 = str1.replace('o', 'a', 1)
# str1 = str1.replace('o', 'a')
print(str1)
# for
for i in range(len(str1)):
# 对于字符串长度的range进行遍历,则获取的是字符串的每一个索引
if str1[i] == 'o':
print(i)
str1 = str1.replace('o', 'a')
print(str1)
04-字符串方法的补充[了解]
# 1. strip 去除字符串左右两侧的指定字符
str1 = '111111hello python11111'
# 注意在strip括号内只能填写字符串信息
print(str1.strip('1')) # hello python
# 如果strip括号内什么也不写,则默认去除字符串左右两侧的空白(空格, \n , \t,以及他们的组合)
str2 = ' \n\tPython\t\t \n'
print(str2.strip()) # Python
# 2. 判断开头和结尾
# startswith 判断是否以....开头,结果是布尔型数据
# 需求: 判断str1是否以111开头
print(str1.startswith('111')) # True
print(str1.startswith('aaa')) # False
# endswith 判断是否以....结尾,结果是布尔型数据
print(str1.endswith('111')) # True
print(str1.endswith('222')) # False
# 3. 大小写转换
str3 = 'heLLo Python'
# upper() 将字符串中的字母转换为大写
print(str3.upper()) # HELLO PYTHON
# lower() 将字符串中的字母转换为小写
print(str3.lower()) # hello python
# 如果字符串中有非字母行数据则不发生变化,只能修改字母
str4 = '123abc一二三'
print(str4.upper()) # 123ABC一二三
# (了解)title() 将所有单词的首字母大写,其余字母变成小写
print(str3.title()) # Hello Python
# (了解)capitalize() 将字符串中的首字母大写,其余字母都小写
print(str3.capitalize()) # Hello python
# 4.获取字符串中指定子字符串出现的次数 count
# 计算str1中有多少个字符1
print(str1.count('1')) # 11
# 5.获取字符串的长度 len
# 计算str1中有多少个字符(元素)
print(len(str1)) # 23
# 等价于
print(str1.__len__()) # 23
# 注意:所有的方法,不要强行记忆,大概记忆一下,并且知道其功能,然后使用字符串.的形式自动提示即可.
练习: 计算1-1000中有多少个7
举例: 7 出现了一次, 17也是1次, 77就是两次 , 777就是三次
# 计算1-1000中7一共出现了多少次
# 分析1: 如果想判断1-1000中7出现的次数,先要获取1-1000这1000个数字 构造一个1-1000的容器
# for i in range(1, 1001):
# print(i)
# 分析2: 计算每个数字中7的个数,可以使用个位十位百位分别取值的形式,但是最简单的方法,就是将其转换为字符串然后统计字符7的格式
# for i in range(1, 1001):
# print(f'{i}中有{str(i).count("7")}个7')
# 分析3: 要定义一个累加器,将所有7的个数累加再一起计算出1-1000中有多少个7
sum1 = 0
for i in range(1, 1001):
sum1 += str(i).count("7")
print(f'1-1000中一共有{sum1}个7')
05-字符串中数据的判断方法[了解]
这里不需要背,大概有个印象,简单的使用几次记住了,复杂的我们会使用正则表达式匹配.
# 判断的就是字符串中的数据是什么类型
# 判断类型方法结果一定是布尔型数据
str1 = '10'
str2 = 'abc'
str3 = '$%$anc'
str4 = '10abc传智'
# isdigit 判断字符串中是否都为数字
print(str1.isdigit()) # True
print(str2.isdigit()) # False
print(str3.isdigit()) # False
print(str4.isdigit()) # False
print('-------------------')
# isalpha 判断字符串中是否都为字母
print(str1.isalpha()) # False
print(str2.isalpha()) # True
print(str3.isalpha()) # False
print(str4.isalpha()) # False
print('-------------------')
# isalnum 判断字符串内是否都为字母或数字
print(str1.isalnum()) # True
print(str2.isalnum()) # True
print(str3.isalnum()) # False 内部包含特殊字符,所以判断为false
print(str4.isalnum()) # True 中文也被判定为字母
print('-------------------')
# isspace判断字符串内容是否都为空白
print(str1.isspace()) # False
str5 = '\n\t '
print(str5.isspace()) # True
# 还有很多判断我们自行尝试
str1.isascii() # 判断是否都为ascii码中的元素
str1.isidentifier() # 判断是否为标识符
str1.islower() # 判断是否都为小写
str1.isupper() # 判断是否都为大写
str1.isprintable() # 判断字符是否均可打印
str1.istitle() # 判断是否所有单词首字母大写
# 这里不需要背,大概有个印象,简单的使用几次记住了,复杂的我们会使用正则表达式匹配.
06-列表的定义及下标[熟练使用]
# 当我们要存储多个相同类型或相似含义的数据时,建议大家使用列表
# 在程序员看来,大于2个就是多个
# 列表定义的格式: 变量名 = [元素1, 元素2, 元素3....]
name_list = ['羽凡', '乃亮', '宝强']
print(name_list) # ['羽凡', '乃亮', '宝强']
print(type(name_list)) # <class 'list'>
# 如果我们要定义一个空列表
list1 = []
print(list1) # []
print(type(list1)) # <class 'list'>
# 在列表内可以不可以放多种不同数据类型的数据??? 列表中是可以的
# 虽然可以存储任意数据类型,但是我们使用列表时尽量存储相同数据类型,便于统一进行数据处理
list2 = ['123', 1, 11.2, False, [1, 2, 3]]
print(list2) # ['123', 1, 11.2, False, [1, 2, 3]]
# 列表的下标
# 列表的下标和字符串的使用方式完全一致,只不过字符串中存储的是字符信息,列表中可以存储任意信息
'''
'123' 1 11.2 False [1, 2, 3]
正数下标 0 1 2 3 4
负数下标 -5 -4 -3 -2 -1
'''
# 正数下标,从0开始从左至右依次递增
# 负数下标,从-1开始从右至左依次递减
# 需求: 获取11.2这个元素
print(list2[2]) # 11.2
print(list2[-3]) # 11.2
# 注意:在列表中使用索引值获取数据如果数据不存在将会报错
# IndexError: list index out of range 超出了list索引的范围
print(list2[7])
07-列表的遍历[熟练使用]
# 正常开发中,列表的数据都是成千上万的,我们要通过记住某一个索引值获取数据,非常艰难
# 所以我们进行数据处理,比对,清洗等,都需要进行遍历
# 列表的遍历可以使用两种方式:
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# for
for i in list1:
print(i)
print('------------------')
# while
# while循环需要循环变量来控制循环次数,我们可以让循环变量的值,就等于list1的索引值,由此取出list1中的每一个值
# 因为list1,的索引值从0开始,所以我们的循环变量起始值也为0
i = 0
# 我们的索引值到哪里结束呢??? 所引致的最大值 = 列表长度 - 1
# 因为list也可以使用len获取列表长度,所以我们让i < len(list)作为循环条件即可
while i < len(list1):
# 此时循环变量就是list1中的索引值
print(list1[i])
i += 1
# 注意: 在开发中凡是遍历容器,建议使用for循环
08-列表的增操作[掌握]
- append : 在列表的末尾追加一个元素
- extend : 在列表的末尾追加一个数据容器
- insert : 在列表的指定下标位置插入一个元素
```python列表中可以对于元素进行增删改查操作,所以同一个列表在不用的时间点,列表中元素的个数,元素的值均可能不相同
定义一个列表
list1 = [1, 2, 3]
append(元素值) 将元素值追加到列表的末尾,一次只能添加一个数据元素
给列表追加元素时,并没有新的数据容器产生,而是在原数据的基础上进行了修改
print(list1.append(4)) # None 在python中None代表空类型,表示没有任何数据.
list1.append(4) # 在列表的末尾追加元素4
TypeError: list.append() takes exactly one argument (2 given)
一次只能追加一个元素,否则报错
list1.append(5,6)
print(list1) # [1, 2, 3, 4]
print(‘—————————‘)
extend(容器类型数据) 将数据容器中的每一个元素依次追加到列表末尾,可以一次追加多个数据
给列表扩展数据的时候不会产生新的数据容器,而是在原数据容器中进行修改
print(list1.extend(‘abc’)) # None
extend会将容器类型数据遍历,依次将每一个元素追加
list1.extend(‘abc’) print(list1) # [1, 2, 3, 4, ‘a’, ‘b’, ‘c’]
append追加数据时,会将容器类型作为一个数据元素追加到列表末尾
list1.append(‘abc’) print(list1) # [1, 2, 3, 4, ‘a’, ‘b’, ‘c’, ‘abc’]
注意: extend括号内,只能填写容器类型数据
TypeError: ‘int’ object is not iterable(可遍历)
list1.extend(1)
list1.extend(‘1’) # 哪怕字符串中只有一个元素,也是容器类型数据
list1.extend(‘’) # 哪怕容器类型为空也不会报错
print(list1) # [1, 2, 3, 4, ‘a’, ‘b’, ‘c’, ‘abc’, ‘1’]
insert(索引位置, 元素值) 将元素添加到指定的索引位置
list2 = [1, 2, 3, 4]
需求: 在下标为2的位置插入一个数字5
list2.insert(2, 5)
插入数据后,下标为2的位置数据改变为5,原来下标为2及其之后的数据向后移动一位,下标统一+1
print(list2) # [1, 2, 5, 3, 4]
注意:
1.insert插入的下标必须符合下标连续的要求,如果插入的位置远大于列表下标范围,则自动插入到列表末尾
list2.insert(7, 1) print(list2)
2.insert不安全, append 和extend 不会影响插入数据之前的元素的索引值,但是insert可能会影响
3.insert在开发中使用场景少于append,因为绝大多数情况下列表储存的数据量巨大,我们不需要控制其顺序
<a name="BWdr0"></a>
# 09-列表的查询操作[掌握]
```python
# 查询列表中的元素
# 定义一个列表
list1 = [1, 2, 3, 4, 3, 2, 1]
# 1. 使用索引值查询
# 需求: 获取 4
print(list1[3]) # 4
# 2. index(元素) 查询指定元素在列表中从左至右第一次出现位置的正数索引,如果不存在则报错
# 查询4所在位置的索引
print(list1.index(4)) # 3
# 查询2所在位置的下标, 获取的是从左至右第一次出现位置的索引值
print(list1.index(2)) # 1
# 如果我们查询的内容不存在,则会报错
# ValueError: 5 is not in list
# print(list1.index(5))
# 查询时,可以通过起始(包含)和终止(不包含)位置限定查询范围,
print(list1.index(3, 3, 8)) # 4
# 注意: 在列表中没有find方法
# AttributeError: 'list' object has no attribute 'find'
# print(list1.find(4))
# 3. count(元素) 查询指定元素在列表中出现的次数
print(list1.count(2)) # 2
print(list1.count(4)) # 1
# 4.in / not in 判断元素是否在/不在列表中
# 格式: 元素 in 容器 判断该元素是否在列表中
print(4 in list1) # True 证明4在list1当中
print(8 in list1) # False 证明8不在list1当中
print(4 not in list1) # False 证明4在list1当中
print(8 not in list1) # True 证明8不在list1当中
# 注意: 所有的查询操作,不会影响原数据的值
10-列表的删除操作[掌握]
所有数据存储工具中,删除操作都是危险的,一定要慎重
# 列表的删除操作,指的是对列表中元素的删除
list1 = [1, 2, 3, 4, 5, 4, 3]
# 1. remove() 根据指定的元素值,删除列表中的元素,删除时,只删除从左至右第一次出现的该元素
# 格式: 列表.remove(要删除的元素值)
list1.remove(5)
# remove不会产生新的数据容器,会在原数据上修改
print(list1) # [1, 2, 3, 4, 4, 3]
list1.remove(3)
# remove只会删除从左至右第一次遇到的目标元素
print(list1) # [1, 2, 4, 4, 3]
# 如果被删除的数据,在列表中不存在,则会报错
# ValueError: list.remove(x): x not in list
# list1.remove(9)
# print(list1)
# 2. pop() 根据指定的索引,删除列表中的元素,删除时会将被删除的数据返回(产生了一个新的数据)
# 格式: 列表.pop(要删除元素的索引值)
value = list1.pop(3)
# 删除指定索引的数据后,原数据会发生变化
print(list1) # [1, 2, 4, 3]
# pop后可以获取被删除的数据的值
print(value) # 4
# 3. clear()
# 清空列表,得到一个空列表
list1.clear()
print(list1) # []
# 4.del操作
# del操作是一个公共方法
# 需求: 删除列表中下标为2的元素
# 格式: del 要删除的数据
list2 = [1, 2, 3, 4]
del list2[2]
print(list2) # [1, 2, 4]
# 注意:
# 1. 在开发中pop 和remove 都不安全,会修改原数据的其余元素索引值
# 2. del操作删除数据,不建议使用,其功能比较强大甚至可以将列表整体删除
# del list2
# NameError: name 'list2' is not defined
# 此时list2已经被删除,或者说从内存中释放了
# print(list2)
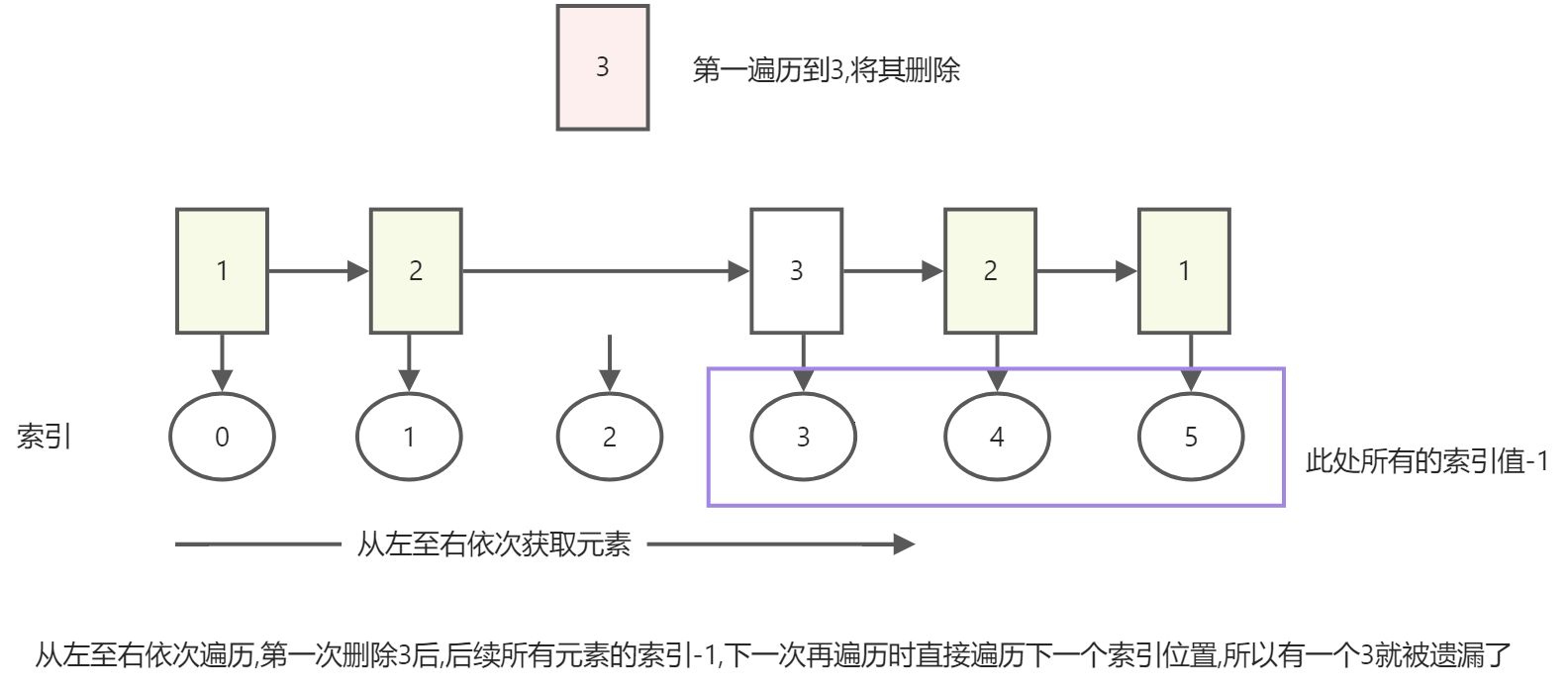
练习: 使用循环,将list1中的所有的3删除
list1 = [1, 2, 3, 3, 2, 1]
# 练习: 使用循环,将list1中的所有的3删除
list1 = [1, 2, 3, 3, 2, 1]
# for i in list1:
# if i == 3:
# list1.remove(i)
#
# print(list1) # [1, 2, 3, 2, 1]
# 为什么删不掉呢? 因为在删除过程中,元素索引发生了变化,导致遍历是有数据遗漏
# 如果想解决这个问题: 有两个思路:
# 1.遍历数据时,不依赖于索引
# ValueError: list.remove(x): x not in list
# 有多少个3,就删除多少次
for i in range(list1.count(3)):
list1.remove(3)
print(list1)
# 2.删除数据的列表和遍历数据的列表不是同一个列表
list2 = list1[:]
for i in list2:
if i == 3:
list1.remove(3)
print(list1)
# 在删除和插入数据时都会对元素索引值产生影响,开发时我们要注意这种影响造成的问题.
11-列表的修改操作[掌握]
# 列表中可以使用元素索引对于元素的值进行修改
list1 = ['羽凡', '乃亮', '宝强']
# 需求: 将乃亮改为小强
# 格式: 列表[索引] = 新值
list1[1] = '小明'
print(list1) # ['羽凡', '小明', '宝强']
# 注意: 要修改位置的索引必须存在,否则报错
# IndexError: list assignment index out of range
list1[4] = '小芳'
12-列表的逆转和排序[熟悉]
# 逆转 : 列表中的元素前后互换位置,数据镜像移动
list1 = [1, 7, 5, 8, 4, 3]
# 需求:逆转该列表 例如 [1,2,3] >>> [3,2,1]
# reverse() 逆转列表
list1.reverse()
print(list1) # [3, 4, 8, 5, 7, 1]
# 逆转的另外一种方式叫做切片
print(list1[::-1]) # [1, 7, 5, 8, 4, 3]
# 注意: reverse是在原数据上进行逆转的,执行完成后,源数据改变,切片不修改原数据,而是产生了一个新的逆转后的列表
# 排序
# sort() 可以直接对于列表中的元素进行排序
# 格式: 列表.sort() 升序排序,默认从小到大
# 列表.sort(reverse=True) 降序排序,从大到小
# 需求1: 对于list1升序排序
list1.sort()
print(list1) # [1, 3, 4, 5, 7, 8]
# 需求2: 对于list1降序排序
list1.sort(reverse=True)
print(list1) # [8, 7, 5, 4, 3, 1]
# 注意: 如果要对列表进行排序,则列表中的数据必须可以比较大小,否则会报错(sort函数的底层使用了比较大小的运算)
list2 = ['小明', 1, 2, 3]
# TypeError: '<' not supported between instances of 'int' and 'str'
# list2.sort()
# print(list2)
# TypeError: '>' not supported between instances of 'int' and 'str'
# print(1 > 'abc')
# 字母和数字间没有办法比较大小,则没办法排序
# 字符串类型数据排序根据字符串大小的比较规则进行排序
list3 = ['Tom', 'Bob', 'Rose']
list3.sort()
print(list3)
13-列表的嵌套[熟悉]
# 列表的嵌套,就是在列表中存储子列表的方式
# 议案最外层的列表,我们叫做一级列表,一级列表内的列表叫做二级列表,以此类推
school_names = [['北京大学', '清华大学'], ['南开大学', '天津大学'], ['复旦大学', '河北大学']]
# 一级列表: [['北京大学', '清华大学'], ['南开大学', '天津大学'], ['复旦大学', '河北大学']]
# 一级列表中有几个元素? 3个:
# 0: ['北京大学', '清华大学']
# 1: ['南开大学', '天津大学']
# 2: ['复旦大学', '河北大学']
# 二级列表: ['北京大学', '清华大学'] ['南开大学', '天津大学'] ['复旦大学', '河北大学']
# 每一个二级列表都有2个元素,下标分别是0,1
# 需求: 要查找到南开大学
# 第一步: 先获取南开大学所在的二级列表
print(school_names[1]) # ['南开大学', '天津大学']
# 第二步: 获取该二级列表中的南开大学
print(school_names[1][0]) # 南开大学
# 获取复旦大学
print(school_names[2][0]) # 复旦大学
# 原则: 多级列表的处理,只需要从外向内依次一层一层的获取数据,不要跨级查找,永远不会出错
# 易错:
list1 = [[[1, 2], [3, 4], [5, 6]]]
# 需求: 获取4
print(list1[0][1][1]) # 4
# 列表嵌套的遍历
# 一般列表嵌套我们要进行遍历时,也会使用循环的嵌套
# 需求: 打印所有学校的名称
# 外层循环对于以及列表进行遍历, 获取所有的二级列表
for item in school_names:
# 内层循环对于二级列表进行遍历,获取所有的大学名称
for school in item:
print(school)
作业
04_字符串作业.md
04_字符串答案.md
05_列表作业.md
05_列表答案.md
作业提交
文件链接
百度云盘: 链接:https://pan.baidu.com/s/13TqhouBQ8h1lP2VFtQHgMw 提取码:lh3d
阿里云盘:「python+大数据79期基础」等文件 https://www.aliyundrive.com/s/G6iPqGFQgfJ

若有收获,就点个赞吧
0 人点赞
