understand object and its name
- More accurately predict the performance and memory usage of your code.
- Write faster code by avoiding accidental copies, a major source of slow code.
- Better understand R’s functional programming tools.
```r
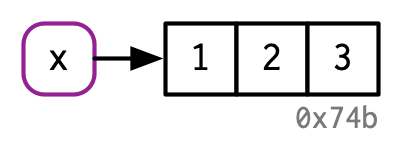
x <- c(1, 2, 3)
以上面的代码为例,这个代码坐了什么事情?
他创建了一个对象叫做X,这个对象包含了1,2,3
实际上她应该是坐了两件事,他创建了一个对象,c(1,2,3),然后把这个对象命名为了x
<br />以上面的图片为例如果是数据框修改<br />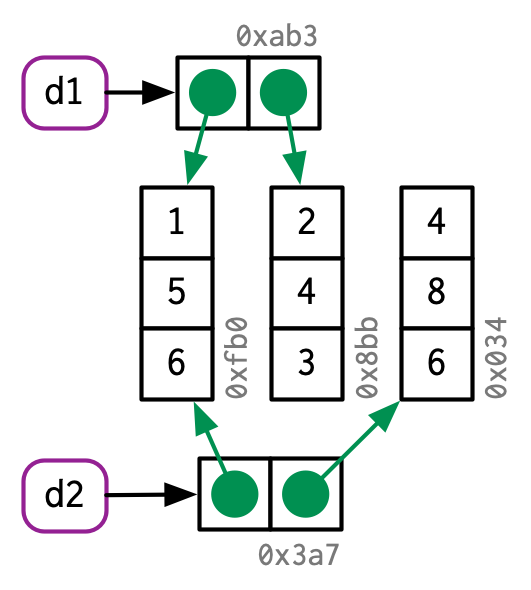<br />这表明列修改,只会修改某一列<br />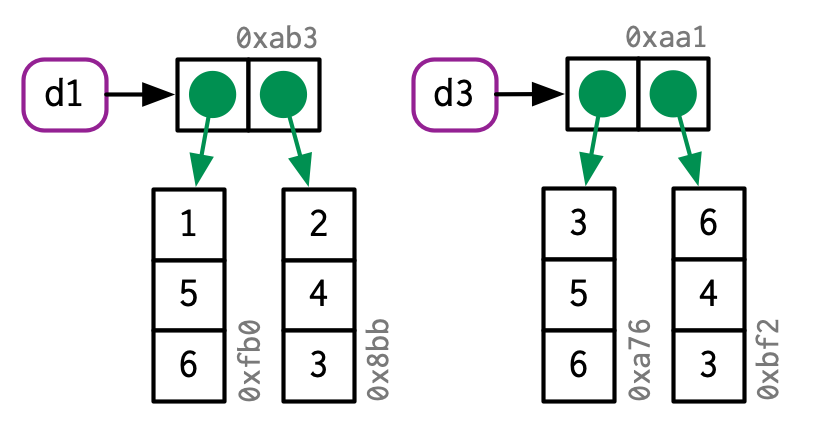<br />如果修改的是行,则每一行都会修改<a name="qZHMg"></a>## 对象的大小列表的元素是对值的引用,因此列表的大小可能比您预期的要小得多:```rx <- runif(1e6)obj_size(x)#> 8,000,048 By <- list(x, x, x)obj_size(y)#> 8,000,128 B## y仅比X大 80 字节,x这是一个包含三个元素的空列表的大小obj_size(list(NULL, NULL, NULL))#> 80 B
由于 R 使用全局字符串池,字符向量占用的内存比您预期的要少:重复一个字符串 100 次并不会使它占用 100 倍的内存。
banana <- "bananas bananas bananas"obj_size(banana)#> 136 Bobj_size(rep(banana, 100))#> 928 B
R 不是存储序列中的每个数字,而是存储第一个和最后一个数字。这意味着每个序列,无论有多大,都是相同的大小
obj_size(1:3)#> 680 Bobj_size(1:1e3)#> 680 Bobj_size(1:1e6)#> 680 Bobj_size(1:1e9)#> 680 B
就地修改
修改 R 对象通常会创建一个副本。有两个例外:
- 具有单个绑定的对象获得了特殊的性能优化。
- 环境,一种特殊类型的对象,总是在原地修改。 ```r v <- c(1, 2, 3)
v[[3]] <- 4
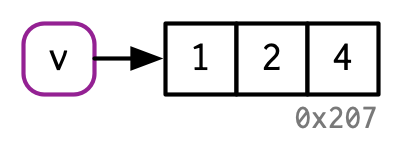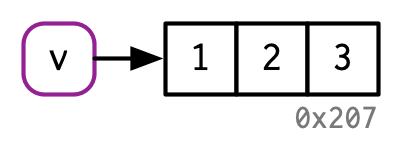<br />可见v还是绑定于0x207这里有个for 循环速度的问题:不太懂```rx <- data.frame(matrix(runif(5 * 1e4), ncol = 5))medians <- vapply(x, median, numeric(1))for (i in seq_along(medians)) {x[[i]] <- x[[i]] - medians[[i]]}#> tracemem[0x7f80c429e020 -> 0x7f80c0c144d8]:#> tracemem[0x7f80c0c144d8 -> 0x7f80c0c14540]: [[<-.data.frame [[<-#> tracemem[0x7f80c0c14540 -> 0x7f80c0c145a8]: [[<-.data.frame [[<-#> tracemem[0x7f80c0c145a8 -> 0x7f80c0c14610]:#> tracemem[0x7f80c0c14610 -> 0x7f80c0c14678]: [[<-.data.frame [[<-#> tracemem[0x7f80c0c14678 -> 0x7f80c0c146e0]: [[<-.data.frame [[<-#> tracemem[0x7f80c0c146e0 -> 0x7f80c0c14748]:#> tracemem[0x7f80c0c14748 -> 0x7f80c0c147b0]: [[<-.data.frame [[<-#> tracemem[0x7f80c0c147b0 -> 0x7f80c0c14818]: [[<-.data.frame [[<-#> tracemem[0x7f80c0c14818 -> 0x7f80c0c14880]:#> tracemem[0x7f80c0c14880 -> 0x7f80c0c148e8]: [[<-.data.frame [[<-#> tracemem[0x7f80c0c148e8 -> 0x7f80c0c14950]: [[<-.data.frame [[<-#> tracemem[0x7f80c0c14950 -> 0x7f80c0c149b8]:#> tracemem[0x7f80c0c149b8 -> 0x7f80c0c14a20]: [[<-.data.frame [[<-#> tracemem[0x7f80c0c14a20 -> 0x7f80c0c14a88]: [[<-.data.frame [[<-# 如果像上诉一样循环速度很慢y <- as.list(x)cat(tracemem(y), "\n")#> <0x7f80c5c3de20>for (i in 1:5) {y[[i]] <- y[[i]] - medians[[i]]}#> tracemem[0x7f80c5c3de20 -> 0x7f80c48de210]:#但如果这样循环,速度是很快的???why
Unbinding and the garbage collector

若有收获,就点个赞吧
0 人点赞
