机器学习中,我们构建好一个模型后,最重要的就是对其进行评估,所以模型评估指标对于sklearn来说十分的重要,所以,我总结了有关于sklearn的模型评估指标的内容:
- 回归(regressor)
1.mean squared error - 均方误差
均方误差在实验的过程中经常遇到,首先,先上百度图解: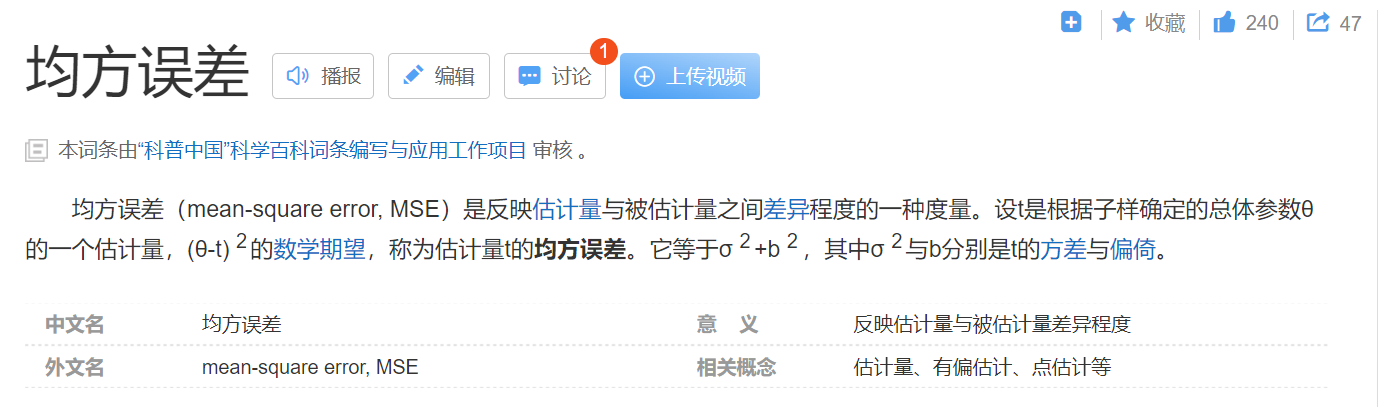
均方误差为预测值与真实值上的差异程度,我们常常运用于测试集的检验,记为MSE。MSE是衡量“平均误差”的一种较方便的方法,MSE可以评价数据的变化程度。
评估指标:MSE的值越小,说明预测模型描述实验数据具有更好的精确度。
from sklearn.meries import mean_squared_error as MSEMSE(ypreds,y)
使用场景:均方误差其实就是线性回归的损失函数,线性回归的时候我们的目的就是让这个损失函数最小。那么模型做出来了,我们把损失函数丢到测试集上去看看损失值就好了。最后,均方误差在交叉验证中一般为负均方误差(neg_mean_square_error),所以不要因为返回一个负数值就害怕啦!!
- Root Mean Squard Error - 均方根误差(标准误差)
标准误差是均方误差的算术平方根。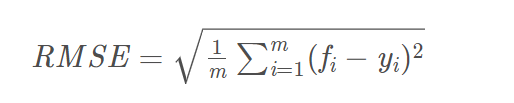
它的意义在于开个根号后,误差的结果就与数据是一个级别的,可以更好地来描述数据。标准误差对一组测量中的特大或特小误差反映非常敏感,所以,标准误差能够很好地反映出测量的精密度。这正是标准误差在工程测量中广泛被采用的原因。
from sklearn.metrics import mean_absolute_error
- R-squared - R2
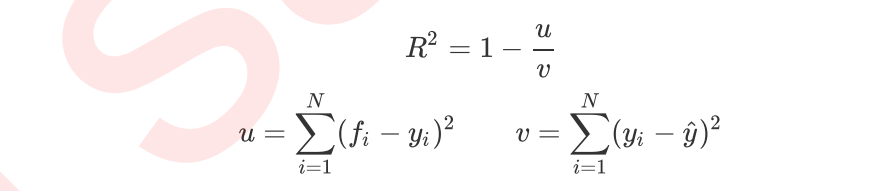
_R_2介于0~1之间,越接近1,回归拟合效果越好,一般认为超过0.8的模型拟合优度比较高。
- 分类(decision)
- accuracy_score - 准确率
准确率accuracy_score可以说是sklearn中最常见的模型评分指标,简称为acc,公式为: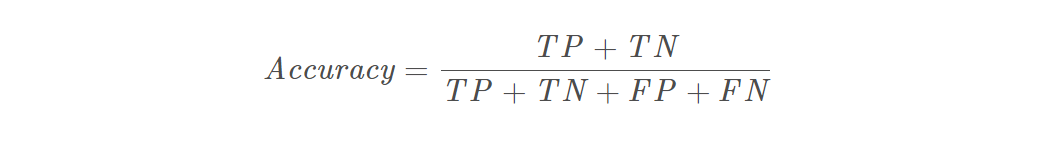
网上常常定义acc为:分类准确率分数是指所有分类正确的百分比。分类准确率这一衡量分类器的标准比较容易理解,但是它不能告诉你响应值的潜在分布,并且它也不能告诉你分类器犯错的类型。
很多人第一次看到这句话的时候都不知道这句话是什么意思,什么是响应值的潜在分布,什么是分类器犯错的类型,在这里我说一下自己的大概理解:准确值只能检测出一个样本里面分对了多少,比如一个简单的二分类测试样本,苹果有100个梨子有80个,而测试集给出的结果是80个苹果100个梨子,那么样本的acc则为(80+80 )/ (100+80)=8 / 9 ,但是通过这个参数我们不会知道,有分别有多少个苹果多少个梨子被分错了(只知道分错的苹果和梨子个数加起来有20个,占了九分之一)。
import numpy as npfrom sklearn.metrics import accuracy_scorey_pred = [0, 2, 1, 3]y_true = [0, 1, 2, 3]accuracy_score(y_true, y_pred)#输出的结果为0.5accuracy_score(y_true, y_pred, normalize=False)#输出的结果为2#normalize:默认值为True,返回正确分类的比例;如果为False,返回正确分类的样本数
使用场景:如果我们追求的是样本模型的准确率和泛化能力,就使用acc为评估指标。
评估指标:acc越接近于1,模型的准确率越高
- recall_score - 召回率
召回率recall一直是和精确率acc混淆的一个模型评估指标,在后面我会进行详细的分析。
公式:召回率 =提取出的想要的信息条数 /样本中的信息条数。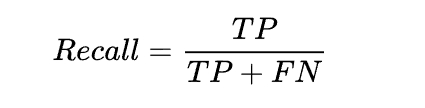
我的片面理解:就是所有想要的条目有多少被检索出来了。(不去计较分对分错)
召回率与准确率的不同之处可以用一个例子来解释:给你一群人,比如100个,你用模型挑出来20个认为这20个可能患前列腺癌症,但是,过了几天,经过专业医生诊断,确诊,你这20个病人里面只有18个是真正预测对了,那你的准确率就是18/20=90%,但是发现你还漏了5个,你的召回率就是18/(18+5)=78%,而你的目的肯定是漏掉的越少越好,所以你要关注召回率,提高78%,越高越好,同时你的准确率也要看,比如你把100个人都预测为前列腺癌症,召回率肯定是23/23=100%,但是你的准确率就是23/100=23%。
看完这个例子是不是恍然大悟,召回率只想看到它想要的被预测出来多少,就算是错的,只要包含起来就好了,其实召回率相当于读于一个类的准确率,而准确率的对象则是整个样本。如果有基础的小伙伴也知道,recall和acc对应的就是混淆矩阵中的计算公式。
- Confusion Matrix - 混淆矩阵
混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总。其中矩阵的行表示真实值,矩阵的列表示预测值。
- 我们先举一个混淆矩阵的例子:
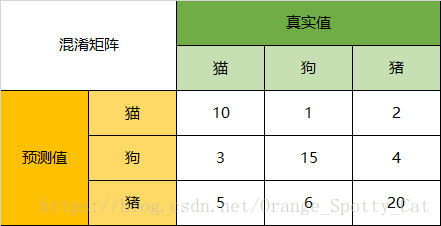
Accuracy(准确率):在总共66个动物中,我们一共预测对了10 + 15 + 20=45个样本,所以准确率(Accuracy)=45/66 = 68.2%。
接下来的参数都是对一类而言的,故可以转化为二分类的问题: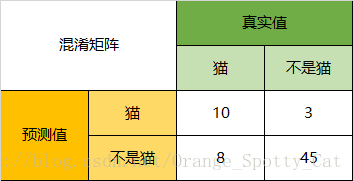
Precision(精确度):66只动物里有13只是猫,但是其实这13只猫只有10只预测对了。模型认为是猫的13只动物里,有1条狗,两只猪。所以,Precision(猫)= 10/13 = 76.9%
Recall(召回率):以猫为例,在总共18只真猫中,我们的模型认为里面只有10只是猫,剩下的3只是狗,5只都是猪。这5只八成是橘猫,能理解。所以,Recall(猫)= 10/18 = 55.6%
Specificity:以猫为例,在总共48只不是猫的动物中,模型认为有45只不是猫。所以,Specificity(猫)= 45/48 = 93.8%。
注意:虽然在45只动物里,模型依然认为错判了6只狗与4只猫,但是从猫的角度而言,模型的判断是没有错的。
F1-Score:通过公式,可以计算出,对猫而言,F1-Score=(2 0.769 0.556)/( 0.769 + 0.556) = 64.54%
可以看出,很多评估指标都是通过混淆矩阵进行计算的
- 概念:
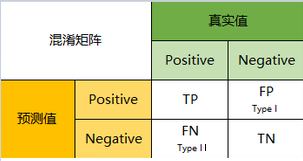
由二分类地情况可以对标到任何混淆矩阵,在涉及精度或者召回的时候,其实是以类为主的,这时候就可以把要计算的类这一行看成真实值1,其他行看成真实值=0,列也是如此。
下面是计算公式进行参考:
准确度(Accuracy) = (TP+TN) / (TP+TN+FN+TN)
精确度(precision, 或者PPV, positive predictive value) = TP / (TP + FP)
召回(recall, 或者敏感度,sensitivity,真阳性率,TPR,True Positive Rate) = TP / (TP + FN)
F1-值(F1-score) = 2TP / (2TP+FP+FN)
可以看出,混淆矩阵是很多评估指标计算的媒介,可以很清晰明了地反映过程,接下来我们就继续探索没有提到地另外两个评估指标:精度和F-1值。
- precision - 精确度(精度)
精确度也是sklearn一个很实用的评估指标。数学公式为: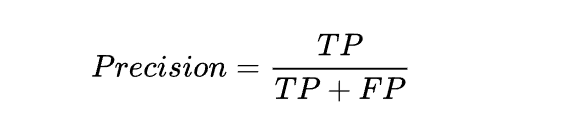
TP+FP 表示了全部判定为Positive的结果数目,而其中的 TP 则是不论判定结果还是事实上均为Positive的数目。精确度衡量的是,单次判定为Positive的结果,其正确的概率是多少。
可能有人对于精确率accary,精确度precision和召回率recall又觉得有些混淆,再举一个非常鲜明的例子:
精确率就是全都对,精度就是找得对,召回率就是找得全。
精确率 好人坏人都要分清楚
精度(查准率)不冤枉一个好人
召回率(查全率)不放过一个坏人
精度和召回率的使用指标:要按情况来进行选取:例如我现在要统计出泰坦尼克号数据集中的幸存者的个数,我要的就是精度,不管你什么其他原因,我要精确地知道一个人是死的是活的;或者一个师兄和我说他做过一个项目,要求的是找出在一大堆从B站中爬出来的弹幕中找出新型的网络热词,要的也是精度,我不管你分多少出来,有没有把所有的网络热词提取出来,但是如果给出了,给出的一定要是网络热词,不可以分错!
学术上的问题 - F1分数的提出:
对于我们来说,肯定追求高精度和高召回率,但其实同时实现这两个目标是不可能的。为什么呢?
还是继续举个例子进行研究:
例如我们现在来研究一个关于有无患上心脏病的数据集,我们会有两种考虑:
1.我们希望完全避免患者患有心脏病的任何情况,但是我们的模型将其归类为没有心脏病,即旨在提高召回率。2.对于患者未患心脏病且我们的模型预测相反的情况,我们也希望避免对没有心脏病的患者进行治疗,即旨在提高准确率。
尽管我们确实追求高精度和高召回价值,但同时实现这两个目标是不可能的。例如,如果我们将模型更改为具有较高召回率的模型,则可能会检测到所有实际患有心脏病的患者,但最终可能会给许多未患心脏病的患者提供治疗。同样,如果我们以高精度为目标,以避免进行任何错误和不需要的治疗,那么最终会导致许多实际上患有心脏病的患者未经任何治疗。
所以,在需要两者均衡的情况下,我们需要一个新的评估指标来帮助我们实现这两个方面的这种,于是就有了我们的F1分数。
- F1 分数

F1分数有两种:
- Micro-F1,计算出所有类别总的Precision和Recall,然后计算F1。
- Macro-F1,计算出每一个类的Precison和Recall后计算F1,最后将F1平均。
from sklearn.metrics import f1_scorey_true = [0, 1, 2, 0, 1, 2]#真实值y_pred = [0, 2, 1, 0, 0, 1]#预测值print(f1_score(y_true, y_pred, average='macro')) # 0.26666666666666666print(f1_score(y_true, y_pred, average='micro')) # 0.3333333333333333print(f1_score(y_true, y_pred, average='weighted')) # 0.26666666666666666print(f1_score(y_true, y_pred, average=None)) # [0.8 0. 0. ]
[

若有收获,就点个赞吧
0 人点赞
