交叉验证
是用来观察模型的稳定性的一种方法(评估模型的优劣性),我们将数据划分为n份,依次使用其中一份作为测试集,其他n-1份 作为训练集,多次计算模型的精确性来评估模型的平均准确程度。训练集和测试集的划分会干扰模型的结果,因此 用交叉验证n次的结果求出的平均值,是对模型效果的一个更好的度量。
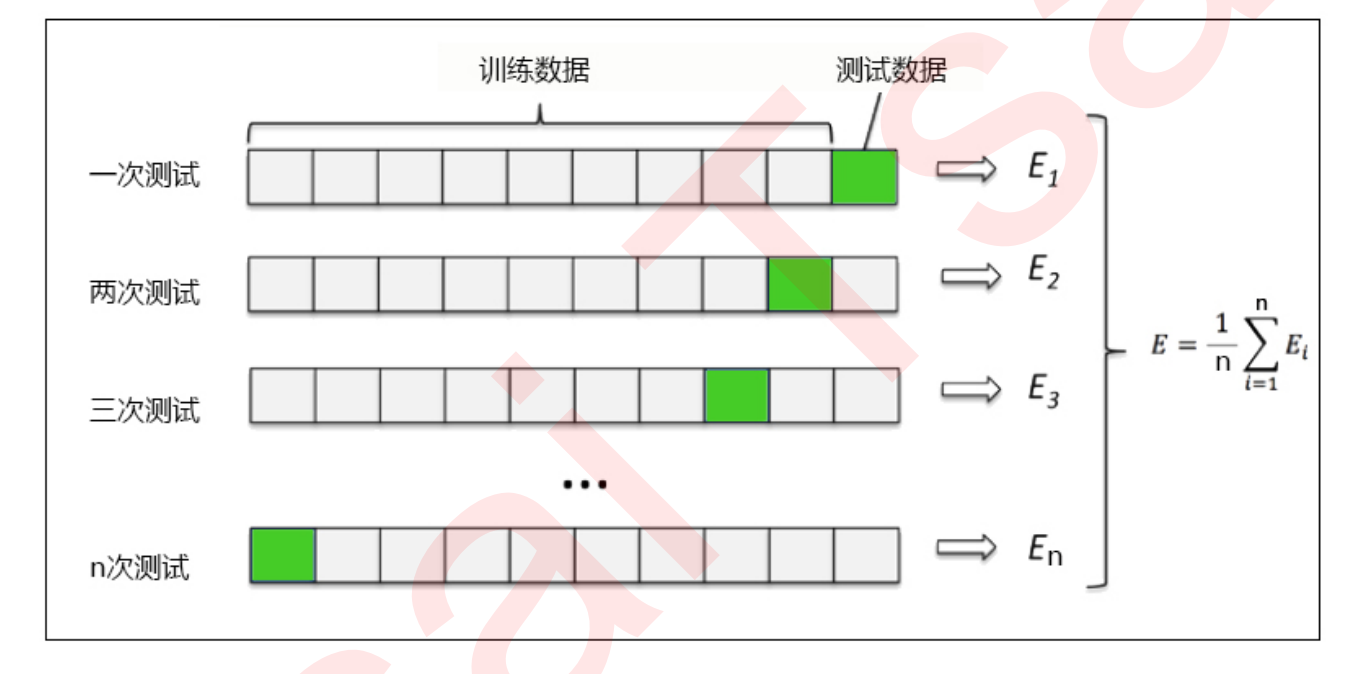
使用效果:我们在画学习曲线的时候可以使用交叉验证协助我们调参找出最佳模型。
使用方式:
from sklearn.model_selection import cross_val_score #导库cross_val_score(regressor, boston.data, boston.target, cv=10,scoring = "neg_mean_squared_error")#以波士顿数据集在回归树上的应用为例#scoring: 交叉验证最重要的就是他的验证方式,选择不同的评价方法,会产生不同的评价结果。#cv为交叉验证的次数
scoring的指标: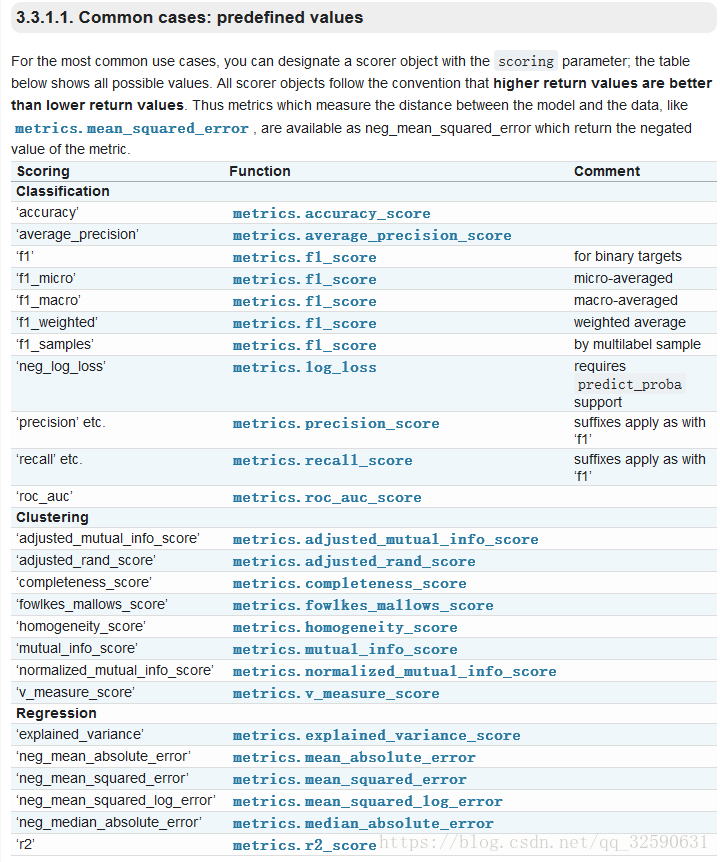
学习曲线
在进行调参的时候,有些参数过于复杂或者我们没有办法手动计算出的时候,利用学习曲线寻找最佳参数是一个很不错的手段哦~最简单的学习曲线代码如下,一般先进行广泛搜索,再进一步细化学习曲线。
score = []for i in range():once = cross_val_score(RFC_,x,y,cv=5).mean()score.append(once)plt.figure(figsize=[20,5])plt.plot(range(),score)plt.xticks(range())plt.show()
训练集和测试集分数比较,观察模型的拟合情况
def plot_learning_curve(estimator,title, X, y,ax=None, #选择子图ylim=None, #设置纵坐标的取值范围cv=None, #交叉验证n_jobs=None #设定索要使用的线程):from sklearn.model_selection import learning_curveimport matplotlib.pyplot as pltimport numpy as nptrain_sizes, train_scores, test_scores = learning_curve(estimator, X, y,shuffle=True,cv=cv,random_state=420,n_jobs=n_jobs)if ax == None:ax = plt.gca()else:ax = plt.figure()ax.set_title(title)if ylim is not None:ax.set_ylim(*ylim)ax.set_xlabel("Training examples")ax.set_ylabel("Score")ax.grid() #绘制网格ax.plot(train_sizes, np.mean(train_scores, axis=1), 'o-', color="r",label="Training score")ax.plot(train_sizes, np.mean(test_scores, axis=1), 'o-', color="g",label="Test score")ax.legend(loc="best")return axfrom sklearn.model_selection import KFold, cross_val_score as CVS, train_test_split as TTScv = KFold(n_splits=5, shuffle = True, random_state=42) #k折交叉验证模式plot_learning_curve(XGBR(n_estimators=100,random_state=420),"XGB",Xtrain,Ytrain,ax=None,cv=cv)plt.show()
网格搜索
网格搜索法是指定参数值的一种穷举搜索方法,通过将估计函数的参数通过交叉验证的方法进行优化来得到最优的学习算法。网格搜索的时间复杂度随着参数的增多呈指数级别增加!
网格搜索的代码其实没有太大的意义,我们完全可以自己使用for循环自行进行网格搜索。
**

若有收获,就点个赞吧
0 人点赞
