什么是API?
API就是Application programming interface。
API封装方式
当然API还可以从封装方式来区分。
:::tips 主要是两个流派:一派是基于REST,一派是基于RPC。
REST是用HTTP封装,而RPS往往用自定义的协议封装。 :::
REST这一派衍生出了GraphQL,而RPC这一派衍生出了gRPC。
REST API的问题
既然要写GraphQL,就需要明白它的前辈REST。
REST有几种操作,POST是写新数据,GET是读数据,PUT是改数据,DELETE是删数据。
还有一些不常用的,比如PATCH、HEAD什么的,一般不用。
这几种操作都是基于HTTP协议的,而且很好理解。
REST这些操作往往界限很模糊。比如写新数据、改数据、删数据,这三个就往往分不清楚。
一个真实例子
一个真实的例子:点赞。我原来写雅虎评论区的API的时候,就为这个头疼过。点赞有很多种实现方法。
比如我可以全用POST。写一条新的“赞”,POST一个“赞”上去。如果我想把赞变成踩呢?那就POST一个“踩”。如果我想取消点赞,那就再POST一个取消。
还有一种实现方式,就是全用PUT。所有人对所有评论默认状态是“不赞不踩”,这个状态是中性的。如果我要点赞,那就把我“不赞不踩”的状态改成“赞”。点“踩”也是一个道理。
如果取消,就再改回“不赞不踩”。
当然有人还会认为取消“赞”应该用DELETE,因为要删数据。
总结一下,光点赞的实现就有四种方法:
- 所有操作都用POST
- 所有操作都用PUT
- 点赞点踩用POST,取消用DELETE
- 点赞点踩用PUT,取消用DELETE
我在雅虎写API的时候,用的就是第四种。结果前端工程师有时候会搞不清楚,以为我用的是第一种。点赞这么简单的API,就有四种方法实现,更复杂的API就更难理解了。
有的API对数据修改很多,既需要写一些新的,也需要改一下旧的,最后还要删一下重复的。这设计起来就太乱了。
API还有一个问题,就是冗余信息过多。
比如我要看一篇新闻报道,那我就做一个GET,GET到的东西有:
标题新闻机构(比如新华社)新闻类别(比如体育、财经)新闻图片摘要(一两句话概括)文本新闻视频记者发布时间新闻链接原始链接
但问题是这些东西往往有很多都用不到,比如这个界面:

它只有标题、图片、新闻机构,这么多response field用三个就行。
再看这个:

这个需要五个:标题、新闻类别(财经)、新闻机构、摘要、图片。
哪怕我只需要三五个response field,我都要用API拿到全部11个数据。浪费流量?
还有一个问题,就是拼装Post Body很累。
比如我想发一条评论,post body就可以大概写成:
{"text": "我一句话不说,这是坠吼的。","authorId": "prc386","contextId": "news_id_123456","sendFrom": "Android","created": 1582861688}
这么个JSON其实就是一个长长的字符串,每次我要发评论,我都得拼装这么个东西。
如果我可以用模板+变量就好了,也就是说我存一个固定的模板
{"text": $1,"authorId": $2,"contextId": $3,"sendFrom": $4,"created": $5}
然后我只需要把$1、$2、$3这些变量设好就行了。REST目前不支持这么做,只能用一些别的library来实现。
这些都是作为前端工程师的烦心事,后端工程师表示我其实也很难啊,我的麻烦更多。
比如验证,每一个传过来的request parameter都需要看是不是合法的。
比如上面的sendFrom这个field,必须得是一种手机的操作系统。前端要是不小心说这个用户评论是从收音机里发出来的我不能接受。每一个field都得验证是不是合法的,一共二十多个field我验证二十多遍。虽然这些验证方法都可以写成library减少重复代码,但是还是很麻烦。
设计API的时候,往往会用这么一种思路,就是每一个endpoint对应一种resource。
API既然是读数据写数据的工具,那么我按照数据的种类把API分成几个endpoint。
博客文章就是一种resource,我搞一个/v1/news,这个endpoint有POST、PUT、GET、DELETE这么几个操作。
博客评论是/v1/comments,同样也是上面四种操作。
博客评论区可以点赞,这就是/v1/vote。
博客、评论、和点赞,这三者其实有依存关系。你不能没有文章光发评论,你也不能没有评论向空气点赞。
所以dependency flow就是:news -> comments -> votes。
但是如果光看三个endpoint,你是看不明白这个关系的。
GraphQL的解决方案
GraphQL把上面这些问题都解决了,解决的方法就是定了这么几个规矩:
- 不需要GET、POST、PUT、DELETE这么多动作,一切简化为读和写;
- Response不会一次给全部数据(用的时候要什么,服务器就返回什么);
- PostBody可以加入variable;
- 写API之前先写Schema,一切数据都得定义类型;
- 数据Dependency必须确立好,这样Resource结构一目了然;
GraphQL定义
GraphQL = Graph Query Language
:::tips GraphQL是一种规范,它不是一种实现。 :::
实现
- Apollo 提供了丰富的后端实现(node支持:express、koa、hapi、restify等框架)和前端(React、RN、Angular、IOS、Android等)实现。
- Relay
GraphQL基础概念
Schema
来自apollo 官方文档:
Every graph API is centered around its schema. You can think of a schema as a blueprint that describes all of your data’s types and their relationships. A schema also defines what data we can fetch through queries and what data we can update through mutations.
每一个graph api 都是以它的schema为中心的。你可以理解为一个schema作为描述你所有数据类型和它们关系的蓝图。 一个schema定义什么数据可以通过query取得,什么数据可以被mutation修改。
schema definition language (SDL)
语法:类似typescript
src/schema.js
schema将写在gql function中( 在两个backticks 下引号 中间,gql``)
const { gql } = require('apollo-server');const typeDefs = gql`# Your schema will go here`;module.exports = typeDefs;
:::tips typeDefs本质上是string,关键在于如何动态解析resolover。 :::
Query type
type Query {launches: [Launch]!launch(id: ID!): Launch# Queries for the current userme: User}
lanunches查询取得所有火箭将来的发射信息,返回一个Launch类型的array,且不能为null。(GraphQL 的所有类型支持默认为null。)- 定义一个
launch查询:通过ID取得一个launch信息(返回类型:Launch) - 定义一个
me查询:取得当前用户信息 (返回类型:User) - 在
me查询上面,是一个注释的例子
src/graphql/typeDefs.js
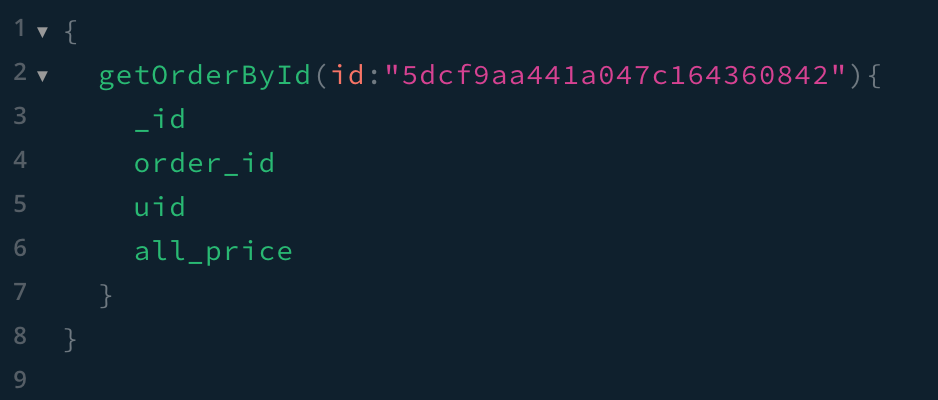
const { gql } = require('apollo-server-express');const typeDefs=gql`"订单表"type order{id:ID!order_id:String!uid:Inttrade_no:Stringall_price:Int}"订单明细表"type orderItem{id:ID!order_id:String!title:Stringprice:Intnum:Int}type Query{"获取订单"getOrders:[order]!"获取某个订单"getOrderById(id:ID!):order"获取订单明细"getOrderItems:[orderItem]!}`module.exports= typeDefs;
src/graphql/resolver/order.js
const orderModel = require('../../models/order');const orderResolver = {Query:{// getOrders:()=>{}async getOrders(){try{// 获取所有订单信息return await orderModel.find();}catch(err){throw new Error(err);}},async getOrderById(_,{id}){return await orderModel.findById(id);}}}module.exports = orderResolver;

Mutation type
Mutation type 是修改数据的入口点。GrpahQL mutation 的返回类型完全取决于你,但是我们推荐定义一个特殊返回类型为保证有一个正确的响应给客户端。
在大型项目中,推荐用 interface 抽象这些类型。
type TripUpdateResponse {success: Boolean!message: Stringlaunches: [Launch]}type Mutation {# if false, booking trips failed -- check errorsbookTrips(launchIds: [ID]!): TripUpdateResponse!# if false, cancellation failed -- check errorscancelTrip(launchId: ID!): TripUpdateResponse!login(email: String): String # login token}
Resolver 解析器 ⭐️ ⭐️
Resolvers provide the instructions for turning a GraphQL operation (a query, mutation, or subscription) into data. They either return the same type of data we specify in our schema or a promise for that data.
Resolvers 提供把一个 GraphQL operation (a query, mutation, or subscription)转换成数据的说明。
语法:
fieldName: (parent, args, context, info) => data;
(Resolver functions accept four arguments)
- parent: 一个对象,其中包含从解析器返回的父类型上的结果。
- args: 包含传递给字段的参数的对象
- context: 由GraphQL操作中的所有解析器共享的对象。我们使用上下文包含每个请求状态(例如身份验证信息)并访问我们的数据源。
- info: 关于操作执行状态的信息,仅在高级情况下才应使用
resolver的四个参数
- 第一个参数parent,是当前元素的父元素,顶级的schema的父元素称为root,大部分教程中用_代替。
- 第二个参数是params,也就是查询参数。
- 第三个参数是config,其中有一个参数dataSources我们过会儿需要用到。
- 第四个参数是context,它的入参是express的Request和Response,可以用来传入身份信息,进行鉴权等操作。
module.exports = {Query: {launches: (_, __, { dataSources }) =>dataSources.launchAPI.getAllLaunches(),launch: (_, { id }, { dataSources }) =>dataSources.launchAPI.getLaunchById({ launchId: id }),me: (_, __, { dataSources }) => dataSources.userAPI.findOrCreateUser()}};
const orderModel = require('../../models/order');const orderResolver = {Query:{// getOrders:()=>{}async getOrders(){try{// 获取所有订单信息return await orderModel.find();}catch(err){throw new Error(err);}},async getOrderById(_,{id}){return await orderModel.findById(id);}}}module.exports = orderResolver;
Graphql 数据类型 ⭐️ ⭐️
标量类型 (Scalar)
Int: 有符号的32位整数(没有number类型)Float: 有符号的双精度浮点值String: UTF‐8的字符串Boolean: 布尔ID: 常用于获取数据的唯一标志,或缓存的键值,它也会被序列化为String,但可读性差。
:::info 思考:id与_id的区别? :::
枚举类型 (Enum)
是标量类型的变体,不仅适用于可验证性,还提高了维护性,它同样被序列化为String。
定义形如:
type User{name: Stringsex: Stringintro: String}
以上定义了一个User对象,包含name(名字)、sex(性别)、intro(介绍)属性字段,而这些属性字段都是标量String类型,当然属性也可以是对象类型。
集合类型 (List)
集合只有List一种
type User{name: String!sex: Stringintro: Stringskills: [String]!}
对象类型 (Object)
验证用户
访问控制是几乎每个应用程序都必须在某个时候处理的功能。
遵循的步骤:
- ApolloServer每当GraphQL操作访问您的API时,实例对象的上下文函数就会与请求对象一起调用。使用此请求对象读取授权标头。
- 在上下文功能中验证用户。
- 用户通过身份验证后,将用户附加到上下文函数返回的对象。这使我们能够从我们的数据源和解析器中读取用户的信息,因此我们可以授权他们是否可以访问数据。
注意事项
- graphql 定义的schema因为最后是合并在一起的,因此注意不要重名。

若有收获,就点个赞吧
0 人点赞
