1.初识Sentinel
1.1雪崩问题及解决方案
微服务调用链路中的某个服务故障,引起整个链路中的所有微服务都不可用,这就是雪崩。
解决雪崩问题的常见方式有四种:
1.超时处理:设定超时时间,请求超过一定时间没有响应就返回错误信息,不会无休止等待。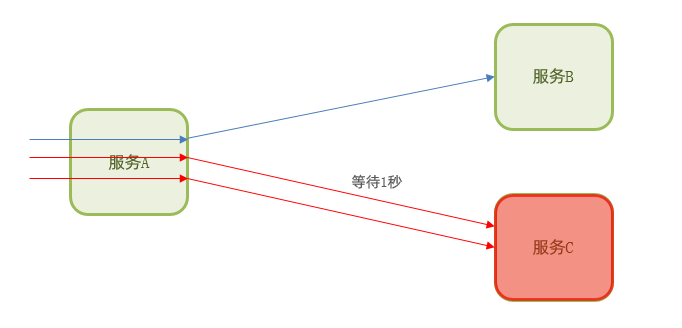
2.舱壁模式:限定每个业务能使用的线程数,避免耗尽整个tomcat的资源,因此也叫线程隔离。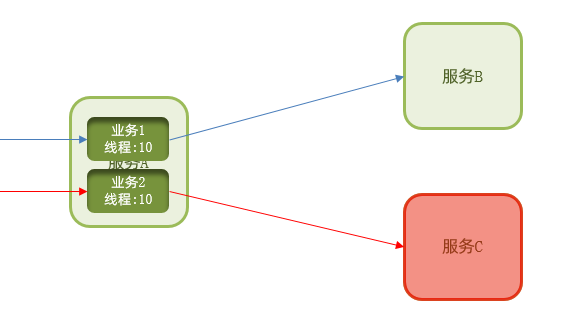
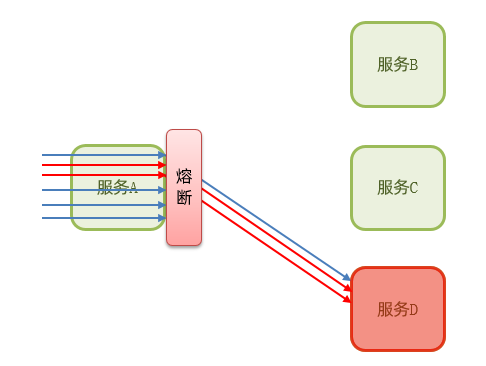
3.熔断降级:由断路器统计业务执行的异常比例,如果超出阈值则会熔断该业务,拦截访问该业务的一切请求。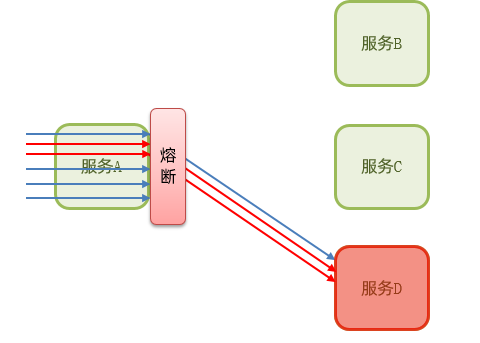
4.流量控制:限制业务访问的QPS,避免服务因流量的突增而故障。
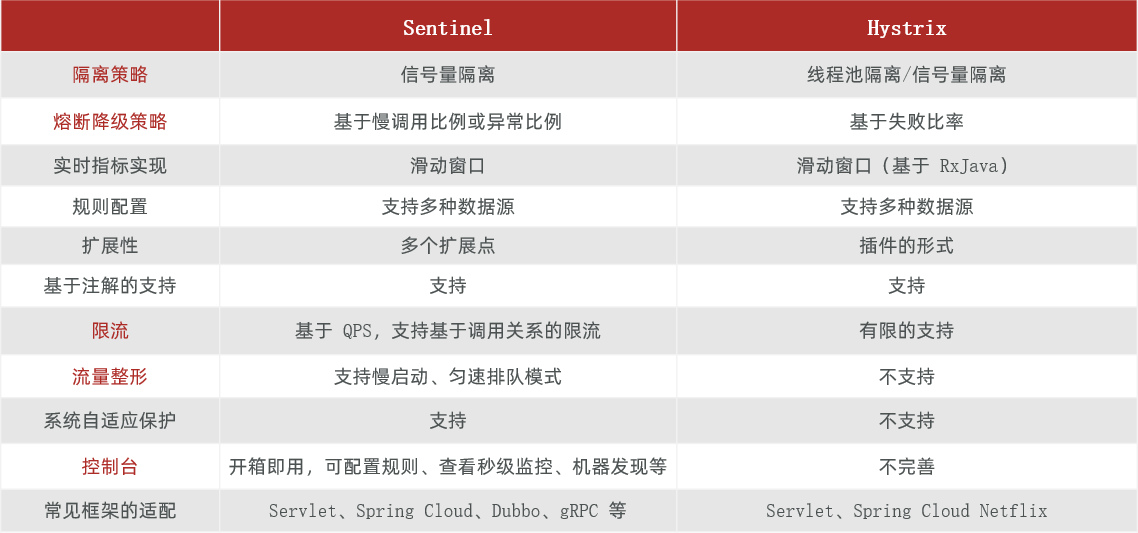
1.2服务保护技术对比
1.3安装Sentinel控制台
sentinel官方提供了UI控制台,方便我们对系统做限流设置。大家可以在GitHub下载
1.将其拷贝到一个你能记住的非中文目录,然后运行命令:
2.然后访问:localhost:8080 即可看到控制台页面,默认的账户和密码都是sentinel
3.如果要修改Sentinel的默认端口、账户、密码,可以通过下列配置:
举例说明:
1.4微服务整合Sentinel
要使用Sentinel肯定要结合微服务,这里我们使用SpringCloud实用篇中的cloud-demo工程。
项目结构如下: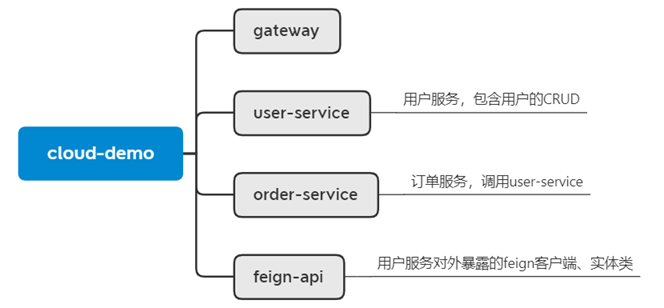
我们在order-service中整合Sentinel,并且连接Sentinel的控制台,步骤如下:
1.引入sentinel依赖:
<!--sentinel--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId></dependency>
2.配置控制台地址:
spring:cloud:sentinel:transport:dashboard: localhost:8080
2.限流规则
2.1簇点链路
簇点链路:就是项目内的调用链路,链路中被监控的每个接口就是一个资源。默认情况下sentinel会监控SpringMVC的每一个端点(Endpoint),因此SpringMVC的每一个端点就是调用链路中的一个资源。
流控、熔断等都是针对簇点链路中的资源来设置的,因此我们可以点击对应资源后面的按钮来设置规则: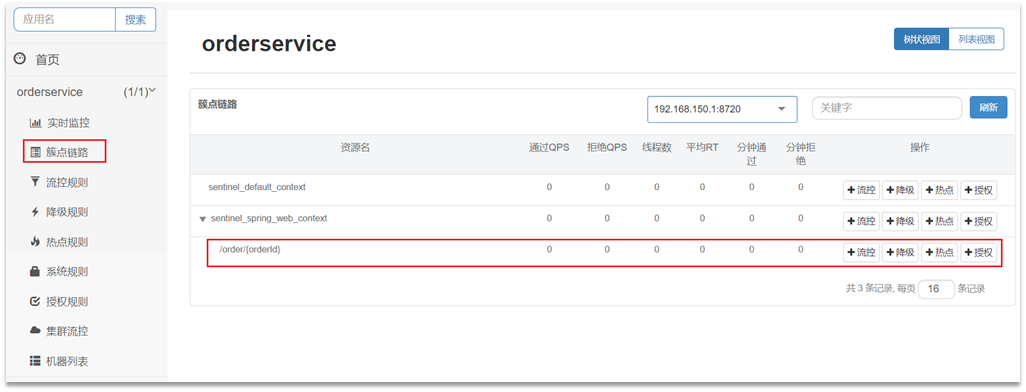
点击资源/order/{orderId}后面的流控按钮,就可以弹出表单。表单中可以添加流控规则,如下图所示: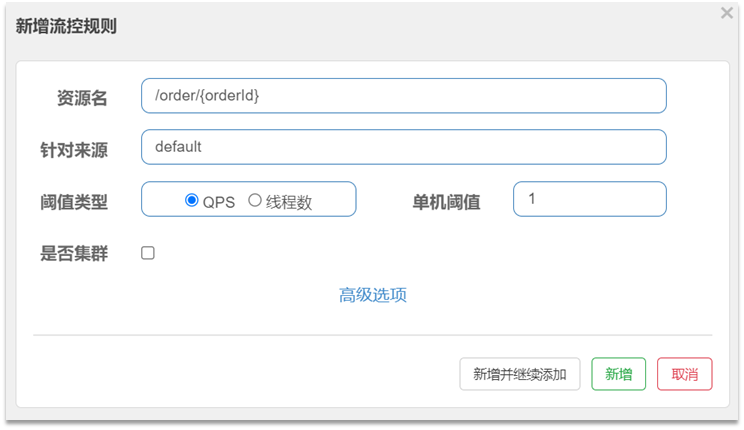
含义是限制 /order/{orderId}这个资源的单机QPS为1,即每秒只允许1次请求,超出的请求会被拦截并报错
2.2流控模式
在添加限流规则时,点击高级选项,可以选择三种流控模式:
•直接:统计当前资源的请求,触发阈值时对当前资源直接限流,也是默认的模式
•关联:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
•链路:统计从指定链路访问到本资源的请求,触发阈值时,对指定链路限流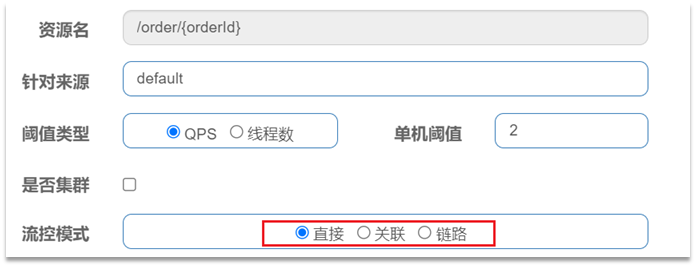
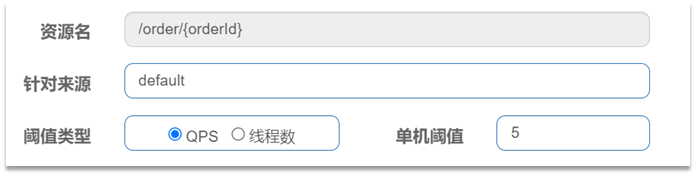
给 /order/{orderId}这个资源设置流控规则,QPS不能超过 5。然后利用jemeter测试。
2.2.1流控模式-直接

2.2.2流控模式-关联
•关联模式:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
•使用场景:比如用户支付时需要修改订单状态,同时用户要查询订单。查询和修改操作会争抢数据库锁,产生竞争。业务需求是有限支付和更新订单的业务,因此当修改订单业务触发阈值时,需要对查询订单业务限流。
当/write资源访问量触发阈值时,就会对/read资源限流,避免影响/write资源。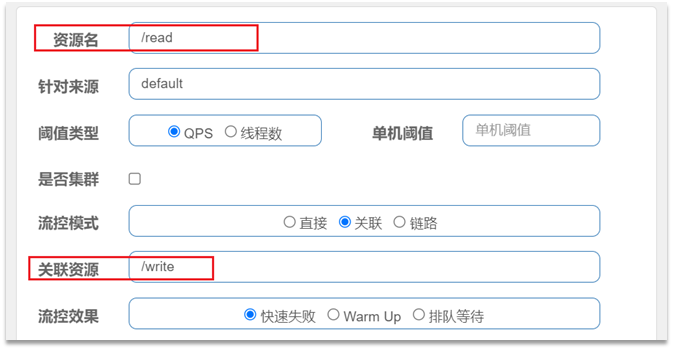
满足下面条件可以使用关联模式:
1.两个有竞争关系的资源
2.一个优先级较高,一个优先级较低
2.2.3流控模式-链路
链路模式:只针对从指定链路访问到本资源的请求做统计,判断是否超过阈值。
例如有两条请求链路:
• /test1 —>/common
• /test2 —>/common
需求:有查询订单和创建订单业务,两者都需要查询商品。针对从查询订单进入到查询商品的请求统计,并设置限流。
步骤:
1.在OrderService中添加一个queryGoods方法,不用实现业务
2.在OrderController中,改造/order/query端点,调用OrderService中的queryGoods方法
3.在OrderController中添加一个/order/save的端点,调用OrderService的queryGoods方法
4.给queryGoods设置限流规则,从/order/query进入queryGoods的方法限制QPS必须小于2
注意事项:
1.Sentinel默认只标记Controller中的方法为资源,如果要标记其它方法,需要@SentinelResource注解.
@SentinelResource("goods")public void queryGoods() {System.err.println("查询商品");}
2.Sentinel默认会将Controller方法做context整合,导致链路模式的流控失效,需要修改application.yml。
spring:cloud:sentinel:web-context-unify: false # 关闭context整合
2.2.4流控模式-总结
•直接:对当前资源限流
•关联:高优先级资源触发阈值,对低优先级资源限流。
•链路:阈值统计时,只统计从指定资源进入当前资源的请求,是对请求来源的限流。
2.3流控效果
流控效果是指请求达到流控阈值时应该采取的措施,包括三种:
•快速失败:达到阈值后,新的请求会被立即拒绝并抛出FlowException异常。是默认的处理方式。
•warm up:预热模式,对超出阈值的请求同样是拒绝并抛出异常。但这种模式阈值会动态变化,从一个较小值逐渐增加到最大阈值。
•排队等待:让所有的请求按照先后次序排队执行,两个请求的间隔不能小于指定时长。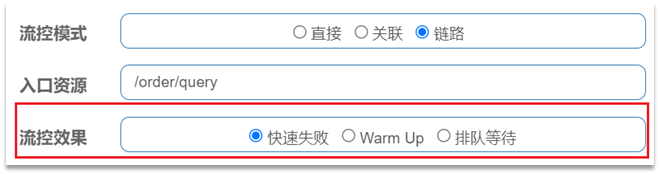
2.3.1预热模式
warm up也叫预热模式,是应对服务冷启动的一种方案。请求阈值初始值是 threshold / coldFactor,持续指定时长后,逐渐提高到threshold值。而coldFactor的默认值是3.
设置QPS的threshold为10,预热时间为5秒,然后在5秒后逐渐增长到10.
2.3.2排队等待
当请求超过QPS阈值时,快速失败和warm up 会拒绝新的请求并抛出异常。而排队等待则是让所有请求进入一个队列中,然后按照阈值允许的时间间隔依次执行。后来的请求必须等待前面执行完成,如果请求预期的等待时间超出最大时长,则会被拒绝。QPS = 5,意味着每200ms处理一个队列中的请求;timeout = 2000,意味着预期等待超过2000ms的请求会被拒绝并抛出异常。
2.4热点参数限流
之前的限流是统计访问某个资源的所有请求,判断是否超过QPS阈值。而热点参数限流是分别统计参数值相同的请求,判断是否超过QPS阈值。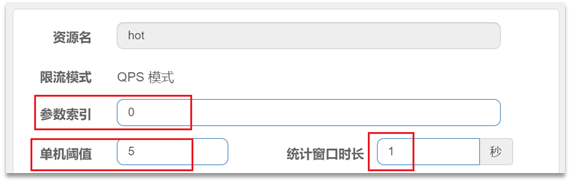
代表的含义是:对hot这个资源的0号参数(第一个参数)做统计,每1秒相同参数值的请求数不能超过5。
在热点参数限流的高级选项中,可以对部分参数设置例外配置: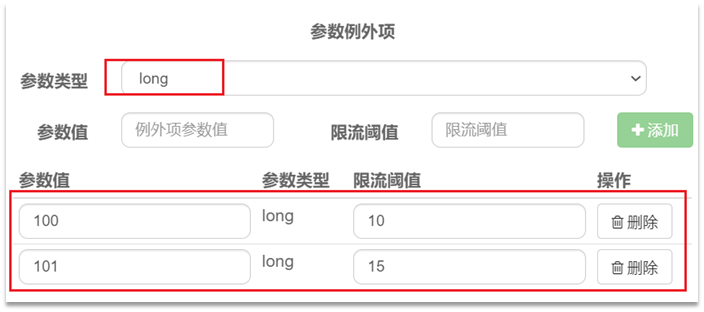
结合上一个配置,含义是对0号的long类型参数限流,每1秒相同参数的QPS不能超过5,有两个例外:
•如果参数值是100,则每1秒允许的QPS为10。
•如果参数值是101,则每1秒允许的QPS为15。注意事项:热点参数限流对默认的SpringMVC资源无效。
3.隔离和降级
虽然限流可以尽量避免因高并发而引起的服务故障,但服务还会因为其它原因而故障。而要将这些故障控制在一定范围,避免雪崩,就要靠线程隔离(舱壁模式)和熔断降级手段了。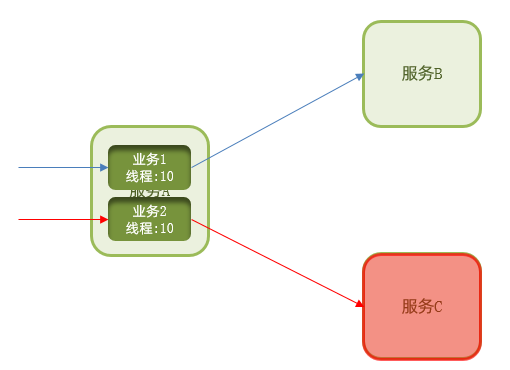
3.1Feign整合Sentinel
SpringCloud中,微服务调用都是通过Feign来实现的,因此做客户端保护必须整合Feign和Sentinel。
1.修改OrderService的application.yml文件,开启Feign的Sentinel功能。
feign:sentinel:enabled: true # 开启Feign的Sentinel功能
2.给FeignClient编写失败后的降级逻辑
①方式一:FallbackClass,无法对远程调用的异常做处理
②方式二:FallbackFactory,可以对远程调用的异常做处理
步骤一:在feing-api项目中定义类,实现FallbackFactory:
@Slf4jpublic class UserClientFallbackFactory implements FallbackFactory<UserClient> {@Overridepublic UserClient create(Throwable throwable) {// 创建UserClient接口实现类,实现其中的方法,编写失败降级的处理逻辑return new UserClient() {@Overridepublic User findById(Long id) {// 记录异常信息log.error("查询用户失败", throwable);// 根据业务需求返回默认的数据,这里是空用户return new User();}};}}
步骤二:在feing-api项目中的DefaultFeignConfiguration类中将UserClientFallbackFactory注册为一个Bean:
@Beanpublic UserClientFallbackFactory userClientFallback(){return new UserClientFallbackFactory();}
步骤三:在feing-api项目中的UserClient接口中使用UserClientFallbackFactory:
@FeignClient(value = "userservice", fallbackFactory = UserClientFallbackFactory.class)public interface UserClient {@GetMapping("/user/{id}")User findById(@PathVariable("id") Long id);}
3.2线程隔离
线程隔离有两种方式实现:
•线程池隔离
•信号量隔离(Sentinel默认采用)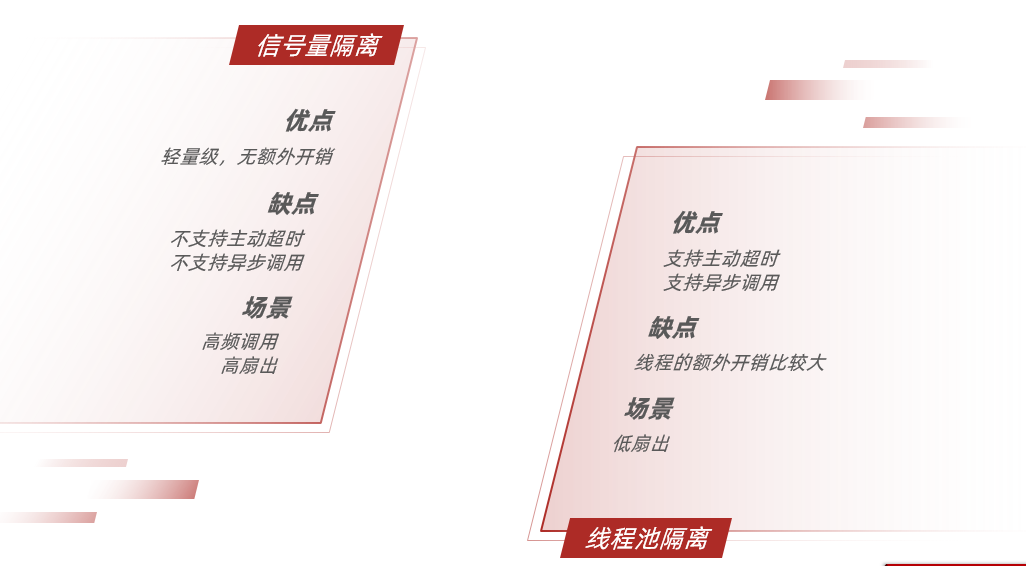
在添加限流规则时,可以选择两种阈值类型: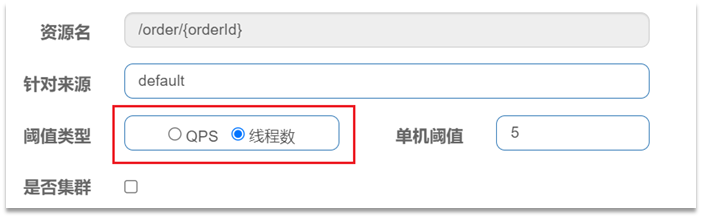
•QPS:就是每秒的请求数。
•线程数:是该资源能使用用的tomcat线程数的最大值。也就是通过限制线程数量,实现舱壁模式。
3.3熔断降级
熔断降级是解决雪崩问题重要手段。其思路是由断路器统计服务调用的异常比例、慢请求比例,如果超出阈值则会熔断该服务。而当服务恢复时,断路器会放行访问该服务的请求。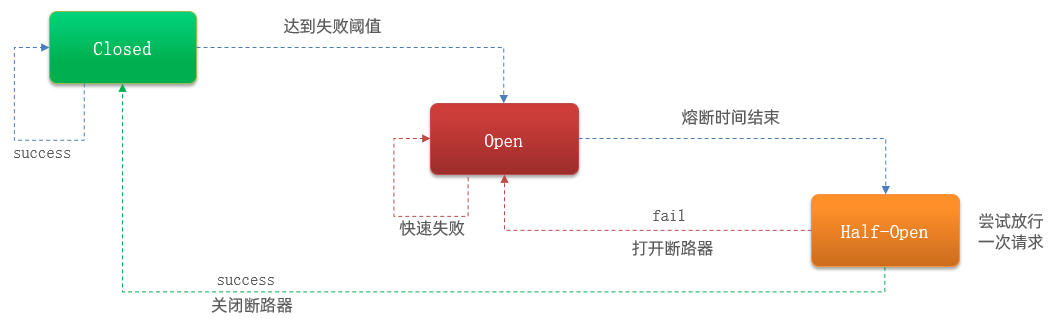
3.3.1熔断策略-慢调用
断路器熔断策略有三种:慢调用、异常比例、异常数
慢调用:业务的响应时长(RT)大于指定时长的请求认定为慢调用请求。在指定时间内,如果请求数量超过设定的最小数量,慢调用比例大于设定的阈值,则触发熔断。 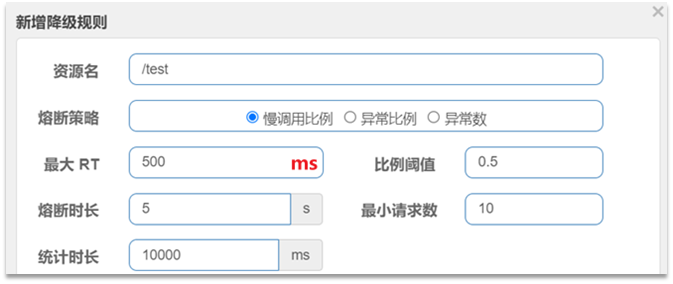
RT超过500ms的调用是慢调用,统计最近10000ms内的请求,如果请求量超过10次,并且慢调用比例不低于0.5,则触发熔断,熔断时长为5秒。然后进入half-open状态,放行一次请求做测试。
需求:给 UserClient的查询用户接口设置降级规则,慢调用的RT阈值为50ms,统计时间为1秒,最小请求数量为5,失败阈值比例为0.4,熔断时长为5
提示:为了触发慢调用规则,我们需要修改UserService中的业务,增加业务耗时: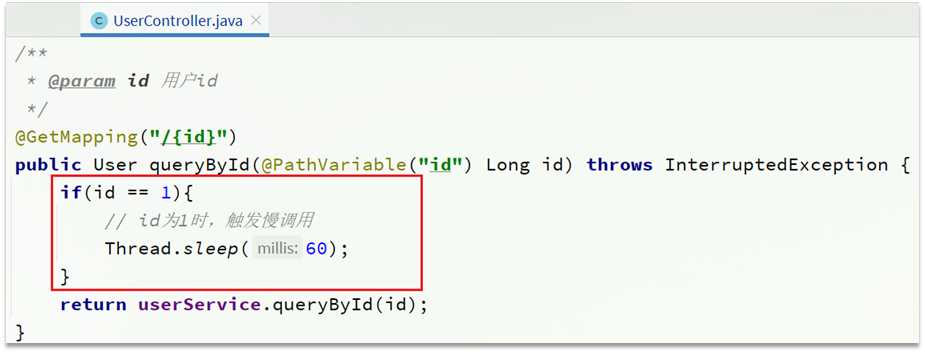
3.3.2熔断策略-异常比例、异常数
异常比例或异常数:统计指定时间内的调用,如果调用次数超过指定请求数,并且出现异常的比例达到设定的比例阈值(或超过指定异常数),则触发熔断。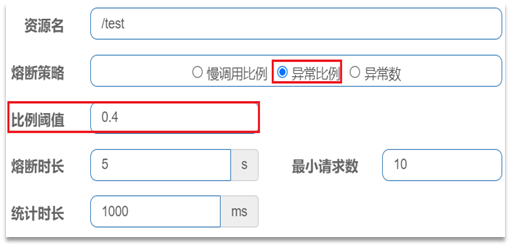
统计最近1000ms内的请求,如果请求量超过10次,并且异常比例不低于0.5,则触发熔断,熔断时长为5秒。然后进入half-open状态,放行一次请求做测试。
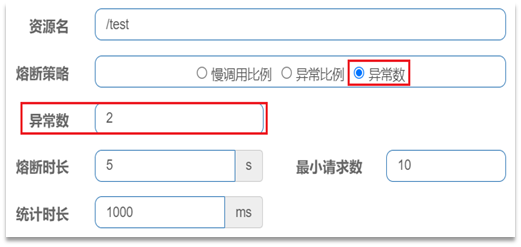
统计最近1000ms内的请求,如果请求量超过10次,并且异常数不低于2,则触发熔断,熔断时长为5秒。然后进入half-open状态,放行一次请求做测试。
需求:给 UserClient的查询用户接口设置降级规则,统计时间为1秒,最小请求数量为5,失败阈值比例为0.4,熔断时长为5s
提示:为了触发异常统计,我们需要修改UserService中的业务,抛出异常: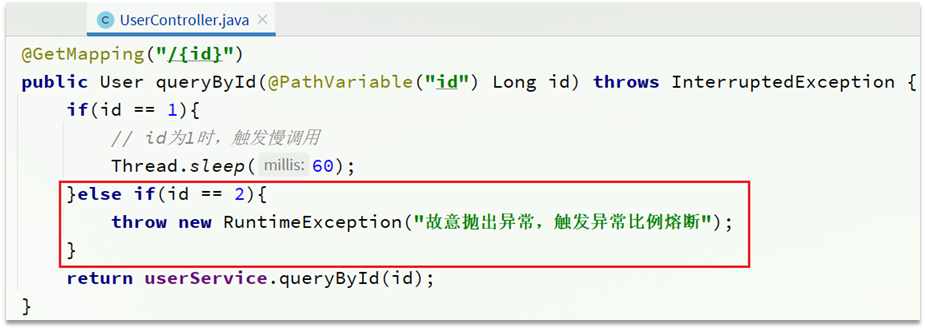
3.3.3熔断策略总结
•慢调用比例:超过指定时长的调用为慢调用,统计单位时长内慢调用的比例,超过阈值则熔断
•异常比例:统计单位时长内异常调用的比例,超过阈值则熔断
•异常数:统计单位时长内异常调用的次数,超过阈值则熔断
4.规则持久化
4.1规则管理模式
Sentinel的控制台规则管理有三种模式:
•原始模式:保存在内存
•pull模式:保存在本地文件或数据库,定时去读取
•push模式:保存在nacos,监听变更实时更新
4.1.1原始模式
控制台配置的规则直接推送到Sentinel客户端,也就是我们的应用。然后保存在内存中,服务重启则丢失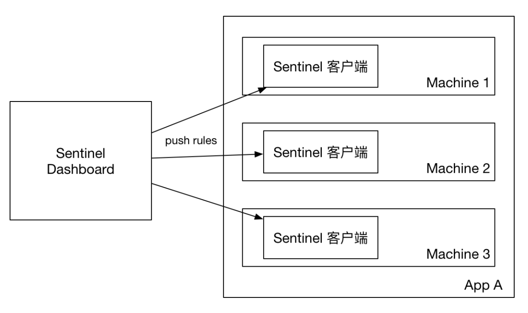
4.1.2pull模式
控制台将配置的规则推送到Sentinel客户端,而客户端会将配置规则保存在本地文件或数据库中。以后会定时去本地文件或数据库中查询,更新本地规则。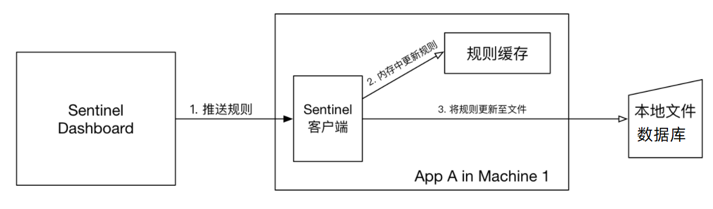
4.1.3push模式
控制台将配置规则推送到远程配置中心,例如Nacos。Sentinel客户端监听Nacos,获取配置变更的推送消息,完成本地配置更新。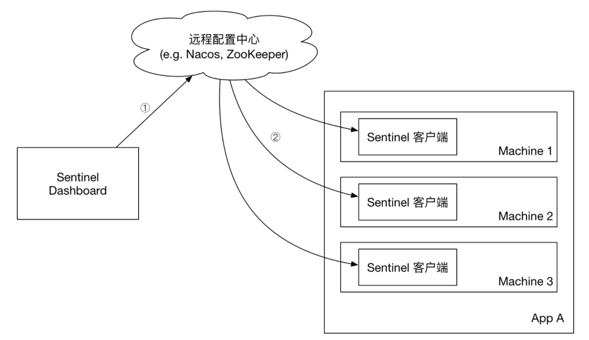
4.2实现push模式
push模式实现最为复杂,依赖于nacos,并且需要改在Sentinel控制台。整体步骤如下:
1.修改order-service服务,使其监听Nacos配置中心
2.修改Sentinel-dashboard源码,配置nacos数据源
3.修改Sentinel-dashboard源码,修改前端页面
4.重新编译、打包-dashboard源码
修改OrderService,让其监听Nacos中的sentinel规则配置。
具体步骤如下:
4.2.1.引入依赖
在order-service中引入sentinel监听nacos的依赖:<dependency><groupId>com.alibaba.csp</groupId><artifactId>sentinel-datasource-nacos</artifactId</dependency>
4.2.2.配置nacos地址
在order-service中的application.yml文件配置nacos地址及监听的配置信息:spring:cloud:sentinel:datasource:flow:nacos:server-addr: localhost:8848 # nacos地址dataId: orderservice-flow-rulesgroupId: SENTINEL_GROUPrule-type: flow # 还可以是:degrade、authority、param-flow
4.2.3修改sentinel-dashboard源码

若有收获,就点个赞吧
0 人点赞
