结论
1)如果可以使用被驱动表的索引,join 语句还是有其优势的;
2)不能使用被驱动表的索引,只能使用 Block Nested-Loop Join 算法,这样的语句就尽量不要使用;
3)在使用 join 的时候,应该让小表做驱动表。
4)在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成之后,计算参与 join 的各个字段的总数据量,数据量小的那个表,就是“小表”,应该作为驱动表。
Join算法原理
Index Nested-Loop Join 算法的执行流程

Block Nested-Loop Join 算法的执行流程
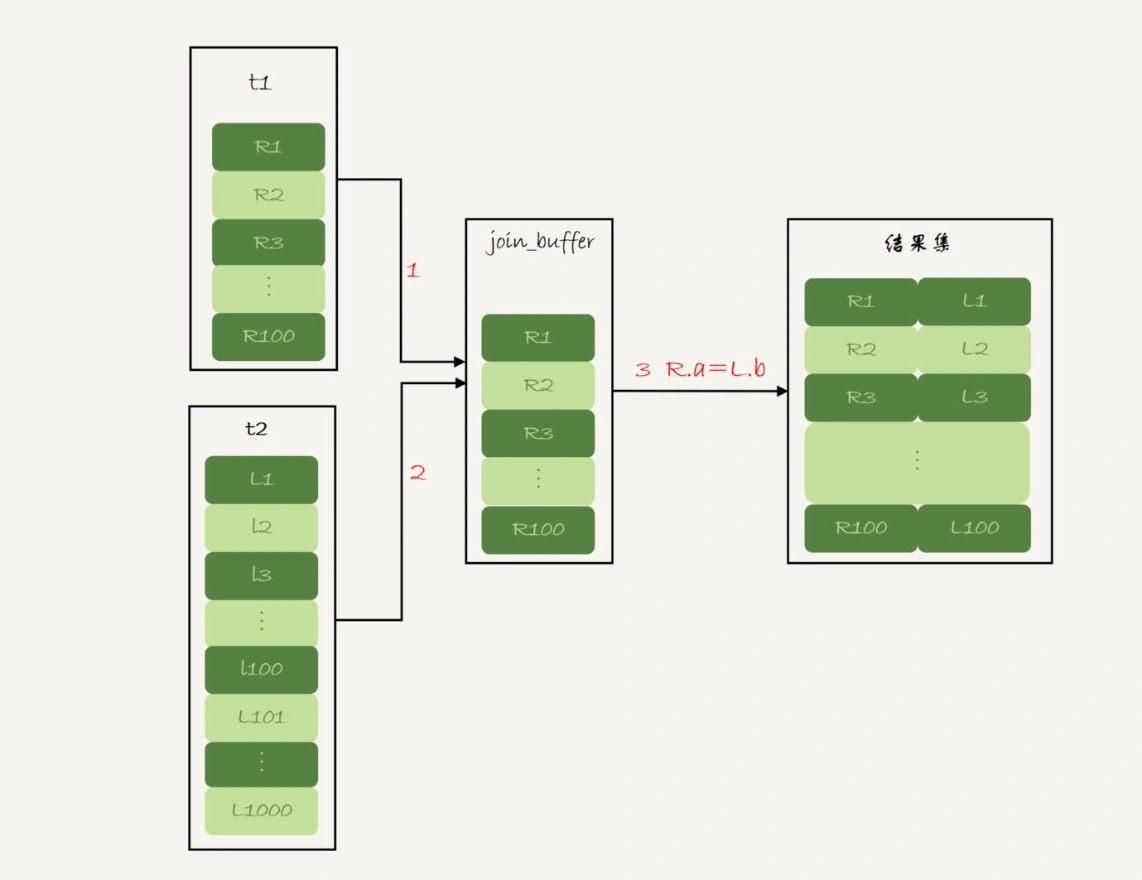
BNL算法的危害
- 可能会多次扫描被驱动表,占用磁盘IO资源
- 判断join条件需要执行M*N次对比,如果是大表就会占用非常多的CPU资源
- 可能会导致Buffer Pool的热数据淘汰,影响内存命中率
Block Nested-Loop Join — 两段

Join优化
MRR优化-Multi-Reange Read
大多数的数据都是按照主键id递增插入的,如果我们按照主键递增查询,对磁盘的读取就接近于顺序读,顺序读比随机读要节省性能。
回表查询的过程,是一行一行搜索主键索引的。
read_rnd_buffer:MySQL的随机读取缓冲区,大小由参数read_rnd_buffer_size控制。
MRR的设计思路:
- 根据普通索引a,找到满足条件的主键记录,将主键id放入read_rnd_buffer中
- 将read_rnd_buffer中的id进行递增排序
- 排序后的id数组,一次到主键id索引中查记录,并返回结果。
- 如果过程中read_rnd_buffer放满了,就会限制性步骤2和3,然后清空read_rnd_buffer,然后循环执行。


针对NLJ的优化——Batch Key Access(依赖于MRR)
针对于NLJ(Index Nested-Loop Join)的优化。
NLJ被驱动表上使用到了索引,参照上面MRR的解释,如果一行行的从驱动表中取数据进行匹配就会造成随机访问,所有将驱动表中的数据取一部分放入join buffer中排序,提现顺序性的优势。
针对BNL的优化——BNL转BKA
- 在被驱动表建立索引,将BNL转成BKA。
对于不常用的表或者列加索引浪费资源,不适合加索引,可以使用临时表来存放被驱动的数据。
在业务代码中通过Hash取代Join
select * from t1;取得表 t1 的全部 1000 行数据,在业务端存入一个 hash 结构,比如 C++ 里的 set、PHP 的数组这样的数据结构。
- select * from t2 where b>=1 and b<=2000; 获取表 t2 中满足条件的 2000 行数据。
- 把这 2000 行数据,一行一行地取到业务端,到 hash 结构的数据表中寻找匹配的数据。满足匹配的条件的这行数据,就作为结果集的一行。
理论上,这个过程会比临时表方案的执行速度还要快一些。如果你感兴趣的话,可以自己验证一下。

若有收获,就点个赞吧
0 人点赞
