PySpark 是 Spark on Zeppelin上Python语言的入口 , Spark Interpreter 内部会创建 Python Shell, 在这个Python Shell 里会创建 Spark的各种变量 (包括SparkContext,SQLContext,SparkSession 等等)。需要注意的是PySpark里的各种变量背后对应的Java变量都是Scala Shell那边创建的,也就是说PySpark 和 Spark Scala Shell是共享通过一个 SparkContext,SQLContext 以及 SparkSession。Zeppelin已经为你创建了下面3个变量 (不要自己再创建这些Environment)
- sc (SparkContext),
- sqlContext (SQLContext)
- spark (SparkSession)
- z (ZeppelinContext)
配置PySpark
使用PySpark非常简单,只需要在Spark的interpreter里做以下配置就可以
- 设置 PYSPARK_PYTHON 和 PYSPARK_DRIVER_PYTHON 为python的可执行文件的路径(默认是用PATH里的python),因为有时候你的系统里可能安装了多个python版本,所以需要设置这两个配置(其实这两个配置是标准的 Spark 配置选项,不是zeppelin引入的配置选项)
使用PySpark
PySpark 在Zeppelin中有2种使用方式
- %spark.pyspark
- %spark.ipyspark
%spark.pyspark 最简单,除了上面的配置不需要做其他事情,但功能也相对比较弱,没法和jupyter里的python环境相比。%spark.ipyspark 功能就比较丰富,使用体验基本和jupyter里的python体验类似。
Python 段落执行顺序
同一时间只能有一个Python段落执行,Zeppelin是按照FIFO的顺序来执行Python段落。所以如果你的一个Python段落里正在跑一个Streaming作业的话,另外一个Scala段落只能等待(处于PENDING状态)。
IPySpark
%spark.ipyspark 功能比较强,和jupyter里的python环境类似,但是需要如下额外配置。
如果你没有安装anaconda,那么需要安装下面3个python库
pip install jupyterpip install grpciopip install protobuf
如果你已经安装了anaconda,那么只需要安装下面2个python库
pip install grpciopip install protobuf
当上面的这些库安装完之后,你就可以使用 %spark.ipyspark 了,除了基本的python执行环境外,还可以享用如下一些高级feature。需要注意的是,%spark.pyspark 会自动检查你是否已经安装了以上的ipyspark环境,如果已经安装了,那么就会自动启用ipyspark,也就是说 %spark.pyspark 会自动转化为 %spark.ipyspark。
1. 彩色高亮输出
%spark.pyspark 输出是纯文本文字,而%spark.ipyspark 输出是彩色的,更加醒目,如下图
2. IPython Magic语法糖支持
IPython语法糖是指以%开头的特殊语法,如下图所示
%spark.ipysparkrange?#timeit%timeit range(100)
3. Matplotlib 支持
Matplotlib的用法和在Jupyter变得一模一样,如下图
4. 更多Python可视化库的支持
除了Matplotlib之外,还能支持更多其他Python的可视化库,比如Bokeh, HvPlot, Pandas,Seaborn 等等,具体可以参考每个Python库的官方文档,在Zeppelin无需任何其他配置,按照官方用法就可以。Zeppelin自带的教程里有常见的Python可视化库的使用教程 Python Tutorial/2. IPython Visualization Tutorial
5. 更好的Code Completion支持
和Scala Shell的Code Completion一样,你只要按tab键就会显示当前环境下的code completion,比如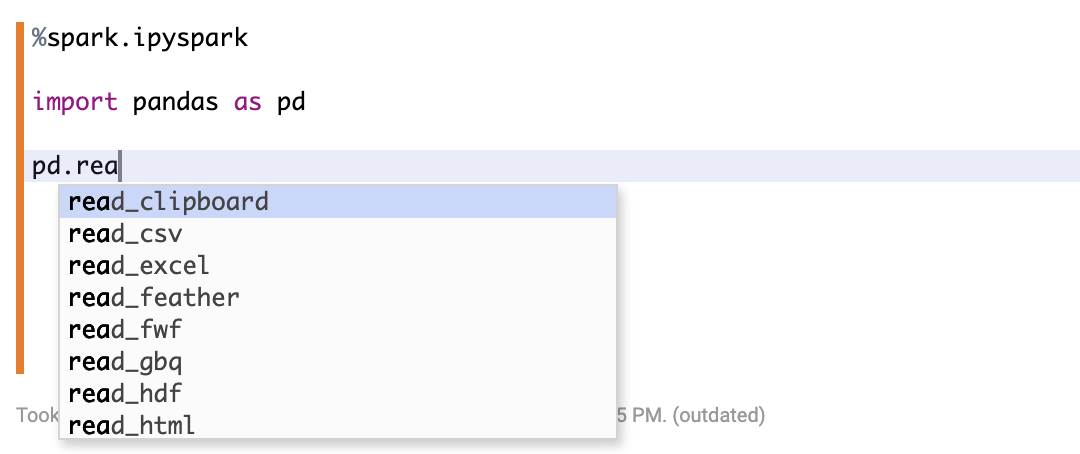
6. 运行Shell 命令
和Jupyter一样,你可以用下面这种方式来运行Shell 命令
7. 动态创建 Python 环境
调整Python环境对于用户来说是一个很普遍的需求,但是在hadoop集群的每个机器上都管理Python环境不太实际,Zeppelin提供了一个用conda的解决方案来动态选择Python runtime环境,具体可以参考Zeppelin自带的教程 Spark Tutorial/8. PySpark Conda Env in Yarn Mode
公众号 钉钉群



若有收获,就点个赞吧
0 人点赞
