服务追踪的作用
- 快速定位请求失败的原因
- 优化系统瓶颈
- 记录链路上的消耗
- 优化链路调用
- 减少服务依赖
- 避免跨数据中心
- 生成网络拓扑
- 透明传输数据
- 携带一些数据,在各服务间传递
- A/B 测试
服务追踪系统原理
服务追踪系统的鼻祖,Google 发布的一篇的论文 Dapper, a Large-Scale Distributed Systems Tracing Infrastructure。
核心理念就是调用链:通过一个全局唯一的 ID 将分布在各个服务节点上的同一次请求串联起来,从而还原原有的调用关系,可以追踪系统问题、分析调用数据并统计各种系统指标。
可以说后面的诞生各种服务追踪系统都是基于 Dapper 衍生出来的,比较有名的有 Twitter 的 Zipkin、阿里的鹰眼、美团的 MTrace 等。
基本概念
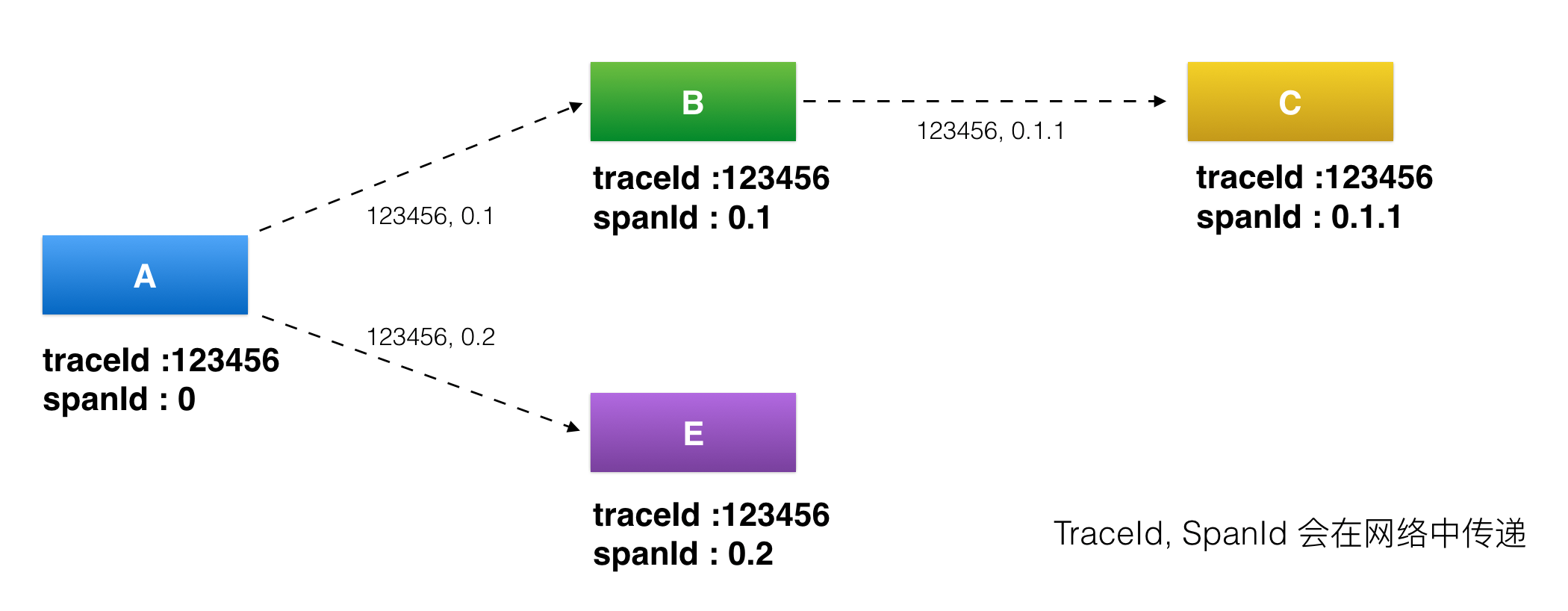
- traceId: 全局请求 id
- spanId: 层次 id
- annotation: 业务自定义埋点数据
应该将整个请求链路看成树状或图状.
服务追踪系统实现
服务追踪系统的架构
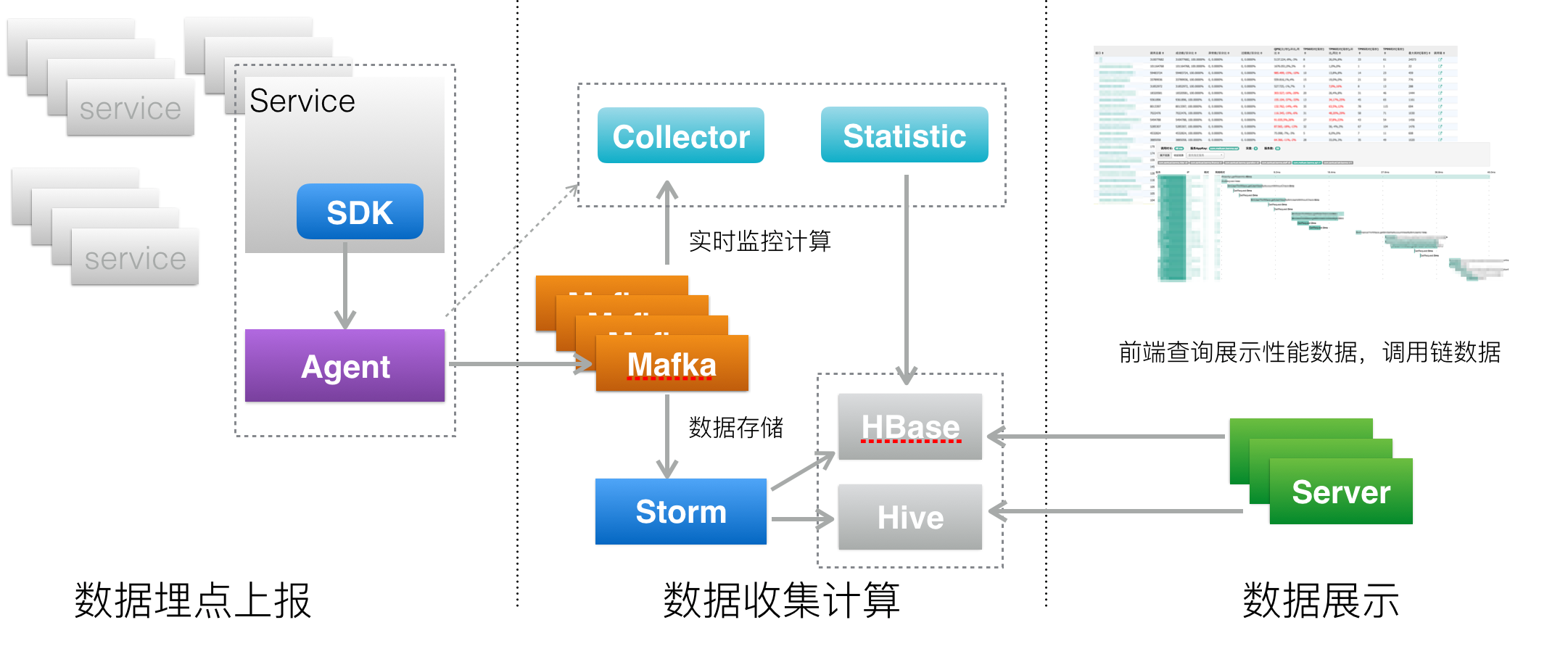
服务追踪系统可以分为三层:
- 数据采集层,负责数据埋点并上报。
- 数据处理层,负责数据的存储与计算。
- 数据展示层,负责数据的图形化展示。
1. 数据采集层
数据埋点的流程:

以红色方框里圈出的 A 调用 B 的过程为例,一次 RPC 请求可以分为四个阶段:
- CS(Client Send)阶段 : 客户端发起请求,并生成调用的上下文。
- SR(Server Recieve)阶段 : 服务端接收请求,并生成上下文。
- SS(Server Send)阶段 : 服务端返回请求,这个阶段会将服务端上下文数据上报,下面这张图可以说明上报的数据有:traceId=123456,spanId=0.1,appKey=B,method=B.method,start=103,duration=38。
- CR(Client Recieve)阶段 : 客户端接收返回结果,这个阶段会将客户端上下文数据上报,上报的数据有:traceid=123456,spanId=0.1,appKey=A,method=B.method,start=103,duration=38。

想要理解上图需要关注数据上报点 (SS, CR) 在哪, 和服务可能同时会是 SS, CR.
2. 数据处理层
- 实时计算需求
- Storm, Spark Streaming
- OLTP 数据仓库
- HBase
- 离线计算需求
- MapReduce
- Spark
3. 数据展示层
- 调用链路图
- 服务整体情况
- 每一层的情况

- 调用拓扑图

若有收获,就点个赞吧
0 人点赞
