5.3.1 独立的列
指索引列不能是表达式的一部分, 也不能是函数的参数.
不能使用 actor_id 列的索引:
SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
另一个常见的错误:
SELECT ... WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col) <= 10;
5.3.2 前缀索引和索引选择性
- 索引的选择性: 基数 cardinality 与数据表记录的总数的比值
- MySQL 不允许索引 BLOB, TEXT, 很长的 VARCHAR, 必须使用前缀索引
原始分布:

计算完整列的选择性:

不同前缀长度的选择性:

不要以为 sel4 就够了:

创建索引:
ALTER TABLE sakila.city_demo ADD KEY (city(7));
前缀索引的缺点:
- 无法在前缀索引列上使用 ORDER BY, GROUP BY
- 无法使用覆盖索引
5.3.3 多列索引
索引合并:
- 一定程度上可以使用表上的多个单列索引来定位指定的行
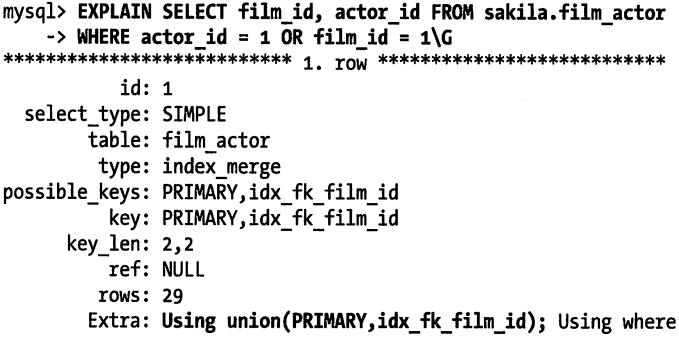
5.3.4 选择合适的索引列顺序

- 可能需要根据那些运行频率最高的查询来调整索引列的顺序
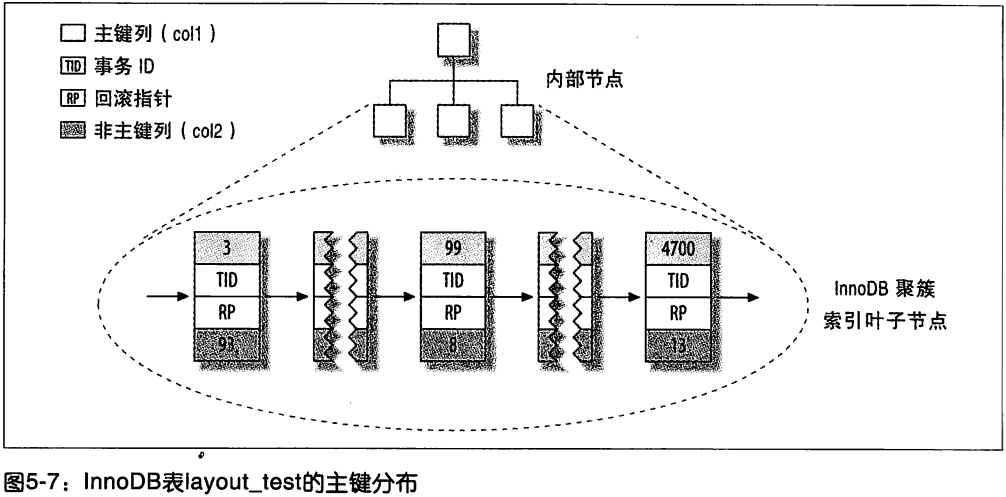
5.3.5 聚簇索引
索引组织表 index-organized table.
叶子页包含了行的全部数据, 节点页只包含了索引列:

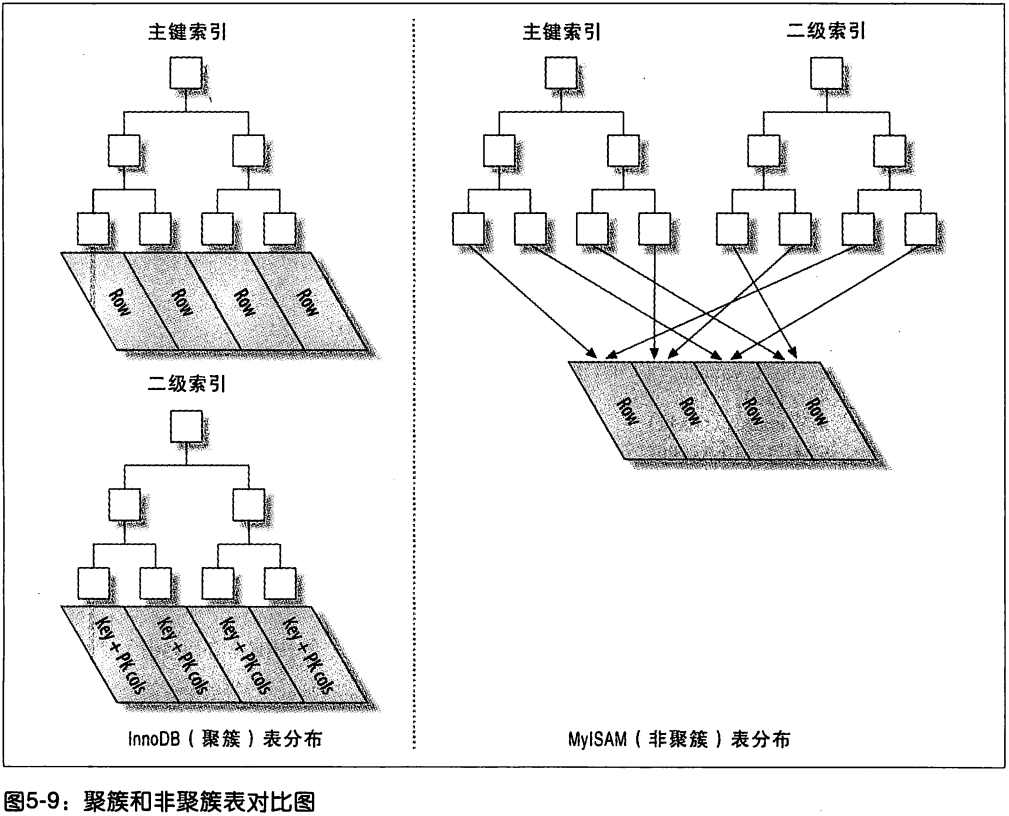
聚集的数据的优点:
- 减少 I/O
- 不用回表
- 可以使用覆盖索引
聚簇索引的缺点:
- 如果数据都在内存中, 访问的顺序没那么重要了
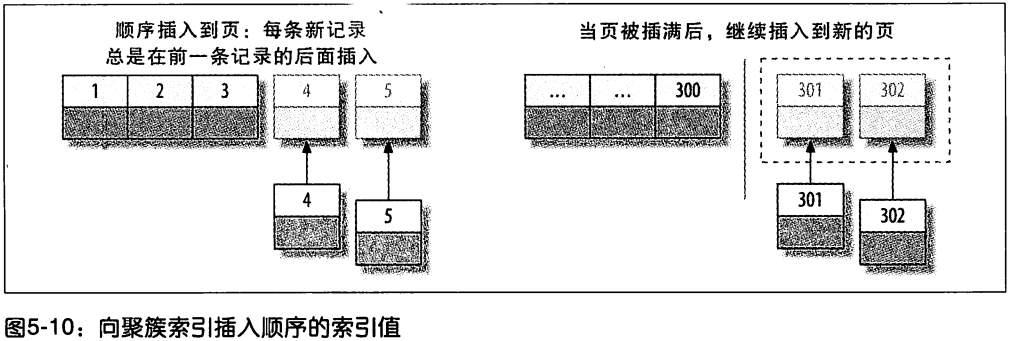
- 插入速度严重依赖于插入顺序 (应该是保持数据的顺序的意思)
- 更新聚簇索引列的代价很高
- 页分裂 (碎片?)
- 可能导致全表扫描变慢
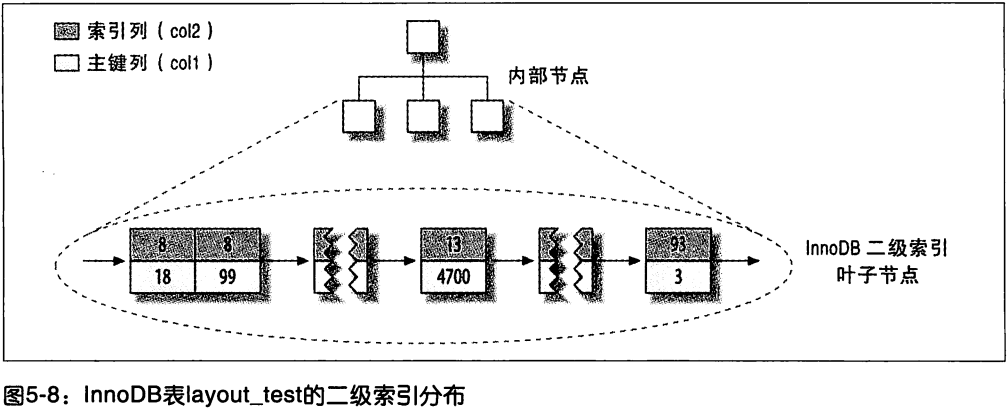
- 二级索引可能比想象的要更大, 因为包含主键列
- 二级索引需要回表 (保存主键值, 而不是位置指针)
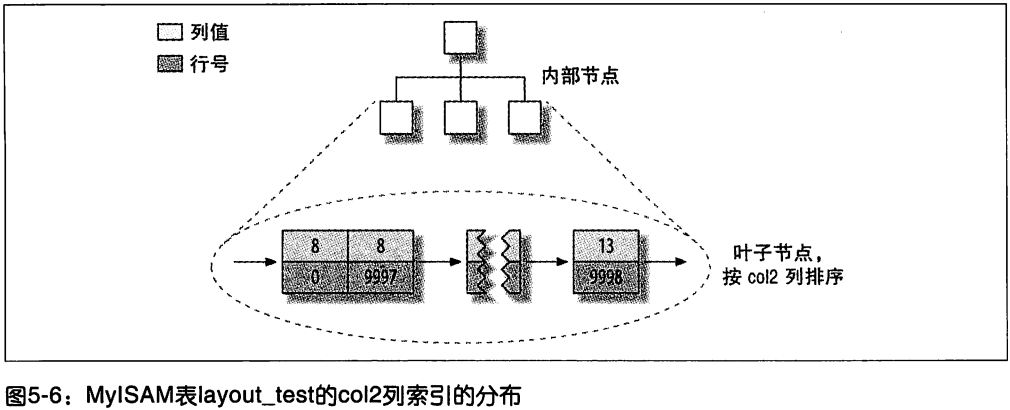
InnoDB 和 MyISAM 的数据分布对比
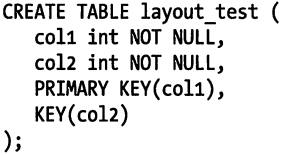
MyISAM 按照数据插入的顺序存储在磁盘上:
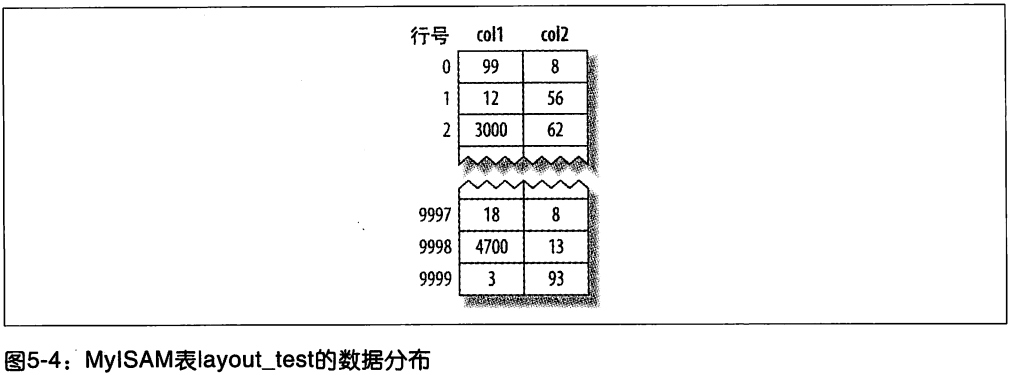
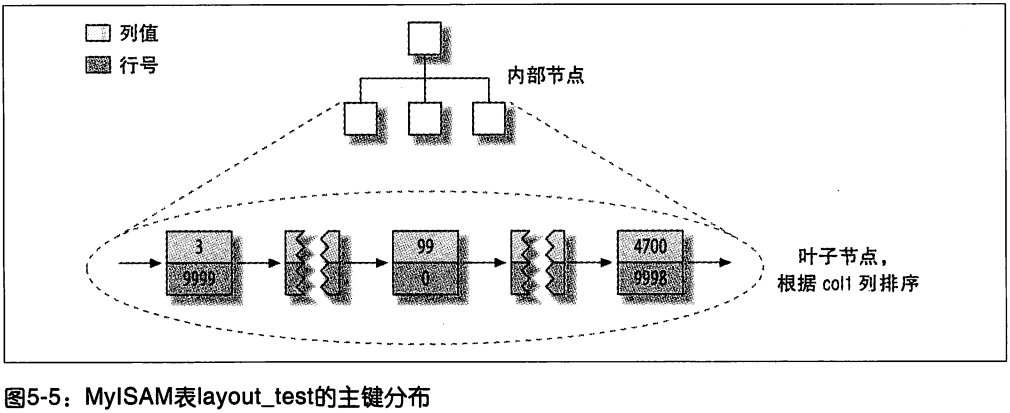
InnoDB 的数据分布:
在 InnoDB 表中按主键顺序插入行
从性能的角度考虑, 使用 UUID 作为聚簇索引会很糟糕:
- 插入变得完全随机
基准测试:
- 使用整数 ID 插入 userinfo 表
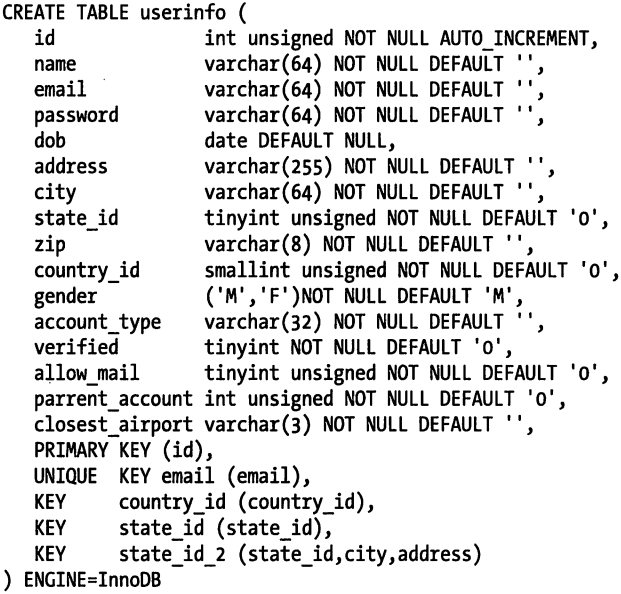
- 主键使用 UUID 的 userinfo_uuid 表


使用 UUID 作主键的缺点:


5.3.6 覆盖索引
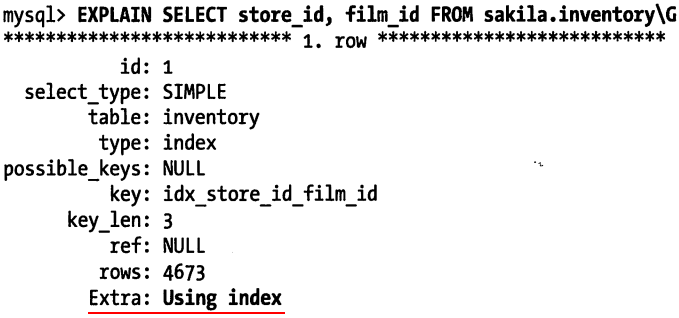

假设索引覆盖了 WHERE 条件中的字段, 但不是整个查询涉及的字段. 如果条件为假 (false), MySQL5.5 和更早的版本也总是会回表.
无法使用覆盖索引:
- 没有任何索引覆盖该查询
- 不能匹配
%开头的字符串匹配 - MySQL 可以使用
WHERE中的索引进行优化
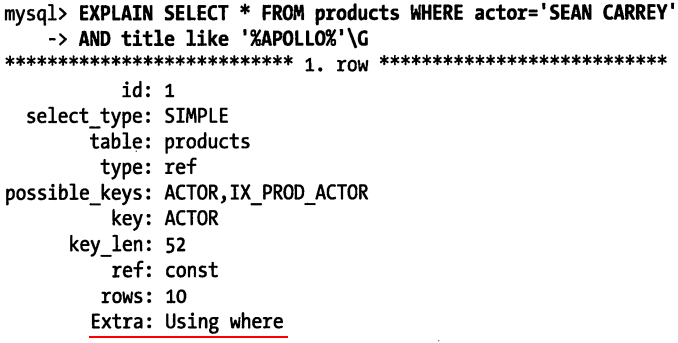
优化:
- 延迟关联 deferred join
- 先将索引扩展为
(artist, title, prod_id), 然后重写查询- 不知道是不是写错了? artist, actor

三种数据集, 总行数都是100万:
- Sean Carrey 出演, 30000部, 20000部包含
- Sean Carrey 出演, 30000部, 40部包含
- Sean Carrey 出演, 50部, 10部包含


因为二级索引的叶子节点上有主键值, 所以这意味着 InnoDB 的二级索引可以有效利用这些 “额外” 的主键来覆盖查询:
last_name上有索引
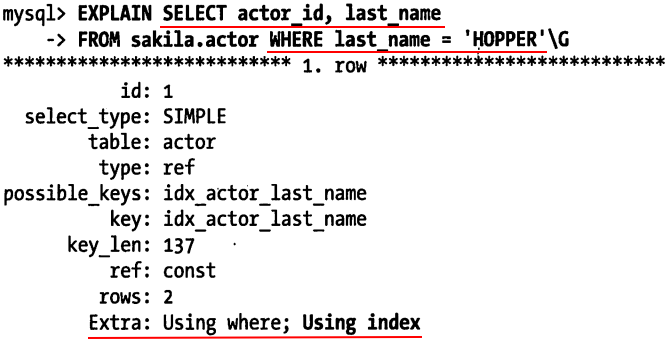

5.3.7 使用索引扫描来做排序
两种方式生成有序结果:
- 做排序
- 按索引顺序扫描
explain 出来的 type 的值为 index, 则说明 MySQL 使用了索引扫描.
- 如果不能覆盖所需全部列, 那么每扫一行就回一次表 (随机 I/O)
当索引列的顺序和 ORDER BY 子句的顺序完全一致, 并且所有列的排序方向都一样时, MySQL 才能够使用索引来排序.
- 如果查询需要关联多张表, 则只有当 ORDER BY 子句引用的字段全部为第一个表时, 才能使用索引做排序
- 需要满足最左前缀
前导列为常量时, 可以不满足最左前缀的要求:
- DDL


5.3.8 压缩 (前缀压缩) 索引
MyISAM 使用前缀压缩来减少索引的大小, 从而让更多的索引可以放入内存中.
5.3.9 冗余和重复索引
重复索引:
- 在相同的列上按照相同的顺序创建的相同类型的索引
冗余索引:
- 如果创建了索引 (A,B), 再创建索引 (A) 就是冗余索引
扩展已有的索引会导致其变得太大, 从而影响性能.
索引越多, 插入速度会越慢:
5.3.10 未使用的索引
完全是累赘.
5.3.11 索引和锁
索引可以让查询锁定更少的行.
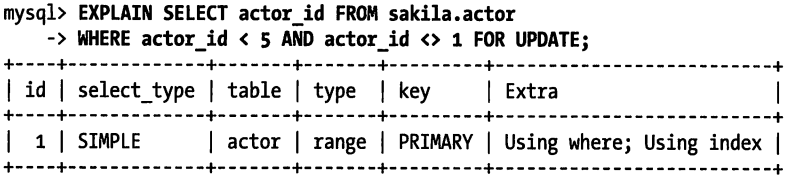
Using where表示 MySQL 服务器将存储引擎返回行以后再应用 WHERE 过滤条件

若有收获,就点个赞吧
0 人点赞
