与特定版本有关.
6.7.1 优化 COUNT() 查询
COUNT() 的作用
两种:
- 统计某个列值的数量 (不统计 NULL)
- 统计行数
- 当 MySQL 确认括号内的表达式值不可能为空时, 实际上就是在统计行数
COUNT(*)不扩展为所有列而直接统计所有的行数
关于 MyISAM 的神话
- 只有没有
WHERE条件的COUNT(*)才非常快 - 如果 MySQL 知道某列 col 不可能为 NULL, 那么会将
COUNT(col)优化为COUNT(*)
简单的优化
存储引擎为 MyISAM 时.
优化前:
- 需要扫描4097行

重写:
- 扫描行数减少到5行以内

EXPLAIN:

在同一个查询中统计同一个列的不同值的数量:
- 方法一
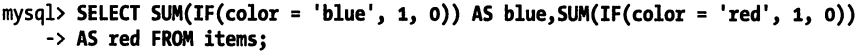
- 方法二

GROUP BY 应该也能实现.
使用近似值
- 利用 EXPLAIN 给出的近似值
- 省略 WHERE
- 删除 DISTINCT
更复杂的优化
- 索引覆盖扫描
- 增加汇总表
- 利用缓存系统
快速, 精确, 实现简单, 三者永远只能满足其二, 必须舍掉其中一个.
6.7.2 优化关联查询

6.7.3 优化子查询
- 尽量使用关联查询代替
6.7.4 优化 GROUP BY 和 DISTINCT
- 尽量使用有索引的列进行分组
效率差的查询:

效率高的查询:

优化 GROUP BY WITH ROLLUP
尽可能将 WITH ROLLUP 功能转移到应用程序中处理.
6.7.5 优化 LIMIT 分页
- 限制分页数量
- 优化大偏移量的性能
- 索引覆盖扫描, 根据需要做关联
优化前:

优化后:
- 延迟关联
- 优化的本质应该是避免多次回表, 使用延迟关联可以降低访问页面的数量

使用已知位置进行查询:

记录上次分页位置:

其他优化方法:
- 汇总表
- 关联冗余表
6.7.6 优化 SQL_CALC_FOUND_ROWS
- 使用该 hint, MySQL 始终扫描所有满足条件的行, 然后再抛弃不需要的行, 代价很高
- 将具体的页数换成 “下一页” 按钮
- 使用缓存
- 考虑使用 EXPLAIN 的 rows 列值作为结果集总数的近似值
- 索引覆盖扫描
6.7.7 优化 UNION 查询
- MySQL 总是通过创建并填充临时表的方式来执行 UNION 查询
- 在 UNION 的各子句中使用 WHERE, LIMIT, ORDER BY (每个子句都要写)
- 除非确实需要服务器消除重复行, 否则一定要使用
UNION ALL
6.7.8 静态查询分析

6.7.9 使用用户自定义变量

若有收获,就点个赞吧
0 人点赞
