MySQL 最大的特性是它的存储引擎架构:
- 处理和存储分离的设计
1.1 MySQL 逻辑架构
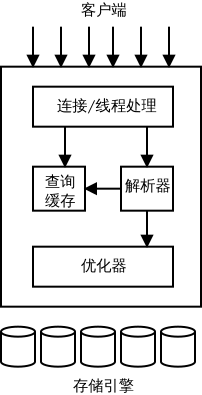
图1-1: MySQL 服务器逻辑架构图
- 第一层架构
- 连接处理
- 授权认证
- 安全
- 第二层架构
- 核心服务功能
- 查询解析
- 分析
- 优化
- 缓存
- 内置函数
- 跨存储引擎功能
- 存储过程
- 触发器
- 视图
- 核心服务功能
- 第三层架构
- 存储引擎, 负责数据的存储, 提取
- 存储引擎 API 包含几十个底层函数
- 不同的存储引擎不会相互通信
- 存储引擎不会解析 SQL (InnoDB 是个例外)
- 存储引擎, 负责数据的存储, 提取
1.1.1 连接管理与安全性
- 服务器会负责缓存线程, 因此不需要为每一个新建的连接创建或者销毁线程
- SSL, X.509 认证
- 检查操作权限 (select…)
1.1.2 优化与执行
- 解析查询
- 创建内部数据结构 (解析树)
- 优化
- 重写查询
- 决定表的读取顺序
- 选择索引
- 用户提供提示 (hint) 优化器, 影响决策
- 请求优化器解释优化过程, 使用户知道服务器如何进行优化
- 存储引擎影响优化器的决策
如果查询缓存中有, 那么从缓存中取.
1.2 并发控制
本章讨论两个层面的并发控制:
- 服务器层
- 存储引擎层
本章只简要讨论 MySQL 如何控制并发读写:
- 锁
1.2.1 读写锁
- 共享锁和排他锁, 即读锁和写锁
- 大多数时候, MySQL 锁的内部管理都是透明的
1.2.2 锁粒度
让锁定的对象更有选择性.
- 尽量只锁定需要修改的部分
- 更细的控制是对数据片加锁
- 锁也占用资源
锁策略, 就是在锁的开销和数据的安全性之间寻求平衡.
- 表锁, 开销最小
- 行级锁, 可以最大程度支持并发处理, 同时带来了最大的锁开销
- 只在存储引擎层实现
1.3 事务
事务就是一组原子性的 SQL 查询. 其内部语句, 要么全部执行, 要么全部执行失败.
ACID 测试:
- 原子性 atomicity, 事务不能被分割
- 一致性 consistency, 数据库状态要么不变, 要么到下一状态
- 隔离性 isolation, 事务在提交前, 对其他事务不可见
- 持久性 durability, 一旦事务提交, 其所做的修改就会永久保存到数据库中
1.3.1 隔离级别
SQL 标准定义了四种隔离级别, 每种存储引擎实现的隔离级别不同.
- READ UNCOMMITTED (未提交读)
- 事务中的修改, 即使没有提交, 对其他事务也都是可见的
- 事务可以读取未提交的数据, 称为脏读
- 性能上不会比其他级别好
- 一般很少使用
- READ COMMITTED (提交读)
- 大多数数据库默认该级别, 但 MySQL 不是
- 事务只能看到已提交的修改
- 也叫做不可重复读 (nonrepeatable read), 同一个事务中, 两次同样的查询可能会得到不同的结果
- REPEATABLE READ ( 可重复读)
- 是 MySQL 的默认级别
- 解决脏读问题. 我认为这里的脏读比上面的脏读含义大, 该脏读也解决了 READ COMMITTED 中的情形
- 该级别无法解决幻读 (Phantom Read) 问题
- SERIALIZABLE (可串行化)
- 强制事务串行执行
- 每一行都加锁
- 会导致大量超时和锁争用
- 很少使用该级别
表1-1: ANSI SQL 隔离级别
| 隔离级别 | 脏读可能性 | 不可重复读可能性 | 幻读可能性 | 加锁读 |
|---|---|---|---|---|
| READ UNCOMMITTED | Yes | Yes | Yes | No |
| READ COMMITTED | No | Yes | Yes | No |
| REPEATABLE READ | No | No | Yes | No |
| SERIALIZABLE | No | No | No | yes |
1.3.2 死锁
多个事务同时锁定同一资源, 也会产生死锁.
- 死锁检测
- 死锁超时机制
- 超时后放弃锁请求
InnoDB 目前处理死锁的方法是, 将持有最少行级排他锁的事务进行回滚.
锁的行为和顺序是和存储引擎相关的. 死锁的产生有双重原因:
- 真正的数据冲突
- 由于存储引擎的实现方式. 同样的语句, 有的存储引擎会死锁, 有的不会
1.3.3 事务日志
存储引擎只修改数据在内存中的拷贝, 再把该行为记录到事务日志中. 提高事务的效率.
- 追加事务日志是顺序 I/O, 比随机 I/O 快
- 内存中的数据慢慢刷回磁盘
- 这种机制称为预写式日志 (Write-Ahead Logging)
- 必要时, 存储引擎会根据日志恢复数据
1.3.4 MySQL 中的事务
MySQL 提供了两种事务型的存储引擎:
- InnoDB
- NDB Cluster
第三方事务型存储引擎:
- XtraDB
- PBXT
自动提交 (AUTOCOMMIT)
MySQL 默认采用自动提交模式. 每个查询都被当作一个事务执行提交操作.
mysql> SHOW VARIABLES LIKE 'AUTOCOMMIT';mysql> SET AUTOCOMMIT = 1;# 设置会话隔离级别mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMIT;
在事务中混合使用存储引擎
MySQL 的服务器层不管理事务, 事务是由下层的存储引擎实现的, 所以在同一个事务中, 使用多种存储引擎是不可靠的.
- 可以为每个表选择不同的存储引擎
- 在非事务型的表上操作时, MySQL 通常不会发出提醒, 也不会报错, 有时候只有回滚的时候才会发出警告
隐式和显式锁定
InnoDB 采用两阶段锁定协议.
MySQL 也支持 LOCK TABLES 和 UNLOCK TABLES, 这是在服务器层实现的, 不能替代事务处理.
1.4 多版本并发控制
多版本并发控制 (MVCC):
- 没有统一标准
- 行级锁变种
- 开销低
- 非阻塞的读
分类
- 乐观并发控制
- 悲观并发控制
MVCC 只在 REPEATABLE READ 和 READ COMMITED 两个隔离级别下工作.
1.5 MySQL 的存储引擎
.frm保存表的定义- 表的定义在 MySQL 服务层统一处理
# 查看 user 表相关信息# 书中给出了各字段的含义mysql> SHOW TABLE STATUS LIKE 'user' \G
1.5.1 InnoDB 存储引擎
InnoDB 是 MySQL 的默认事务型存储引擎.
- 处理大量短期事务. 很少回滚
- 优先使用 InnoDB
InnoDB 的历史
- 如果使用 MySQL 5.1, 建议使用 InnoDB plugin
InnoDB 概览
- 表空间 (tablespace)
- 默认隔离级别为 REPEATABLE READ
- 间隙锁 (next-key locking) 用来防止幻读
- InnoDB 表是基于聚簇索引建立的, 对主键查询有很高的性能, 但是二级索引必须包含主键列, 会导致其他索引变大
- InnoDB 的存储格式是平台独立的 (平台无关)
- 采用可预测性预读
- 建议阅读 InnoDB 官方手册的 “InnoDB 事务模型和锁” 一节
- 支持真正的热备份
1.5.2 MyISAM 存储引擎
在 MySQL 5.1 及其之前版本, MyISAM 是默认的存储引擎.
- 不支持事务和行级锁
- 崩溃后无法安全恢复
存储
- 数据文件
.MYD - 索引文件
.MYI
MyISAM 特性
- 加锁与并发
- 整张表
- 支持读时插入数据, 称为并发插入
- 修复
- 与事务恢复不同
- 索引特性
- 延迟更新索引键
MyISAM 压缩表
- 减少磁盘空间占用
MyISAM 性能
- 某些场景下性能很好
- 性能问题在于表锁
1.5.3 MySQL 内建的其他存储引擎
特殊用途的存储引擎:
- Archive 引擎
- Blackhole 引擎
- CSV 引擎
- Federated 引擎
- Memory 引擎
- Merge 引擎
- NDB 集群引擎
1.5.4 第三方存储引擎
- OLTP 类引擎
- 面向列的存储引擎
- 社区存储引擎
- Aria
- Groonga
- OQGraph
- Q4M
- SphinxSE
- Spider
- VPForMySQL
1.5.5 选择合适的引擎
大多数情况下, InnoDB 都是正确的选择.
- 事务
- 备份
场景:
- 日志型应用
- 只读或者大部分情况下只读的表
- 订单处理
- 电子公告牌和主题讨论论坛
- CD-ROM 应用
- 大数据量
1.5.6 转换表的引擎
将表的存储引擎换成另一种引擎.
ALTER TABLE
mysql> ALTER TABLE mytable ENGINE = InnoDB;
导出与导入
- mysqldump 工具, 修改 CREATE 后的存储引擎
创建与查询
1.6 MySQL 时间线 (Timeline)
- 3.23, 2001
- 4.0 2003
- 4.1 2005
- 5.0 2006
- 5.1 2008
- 5.5 2010, 质量最高
- 5.6
- 6.0 已经取消
1.7 MySQL 的开发模式
- GA
- GPL
- 插件
- 开源
1.8 总结
- MySQL 拥有分层架构, 存储引擎 API

若有收获,就点个赞吧
0 人点赞
