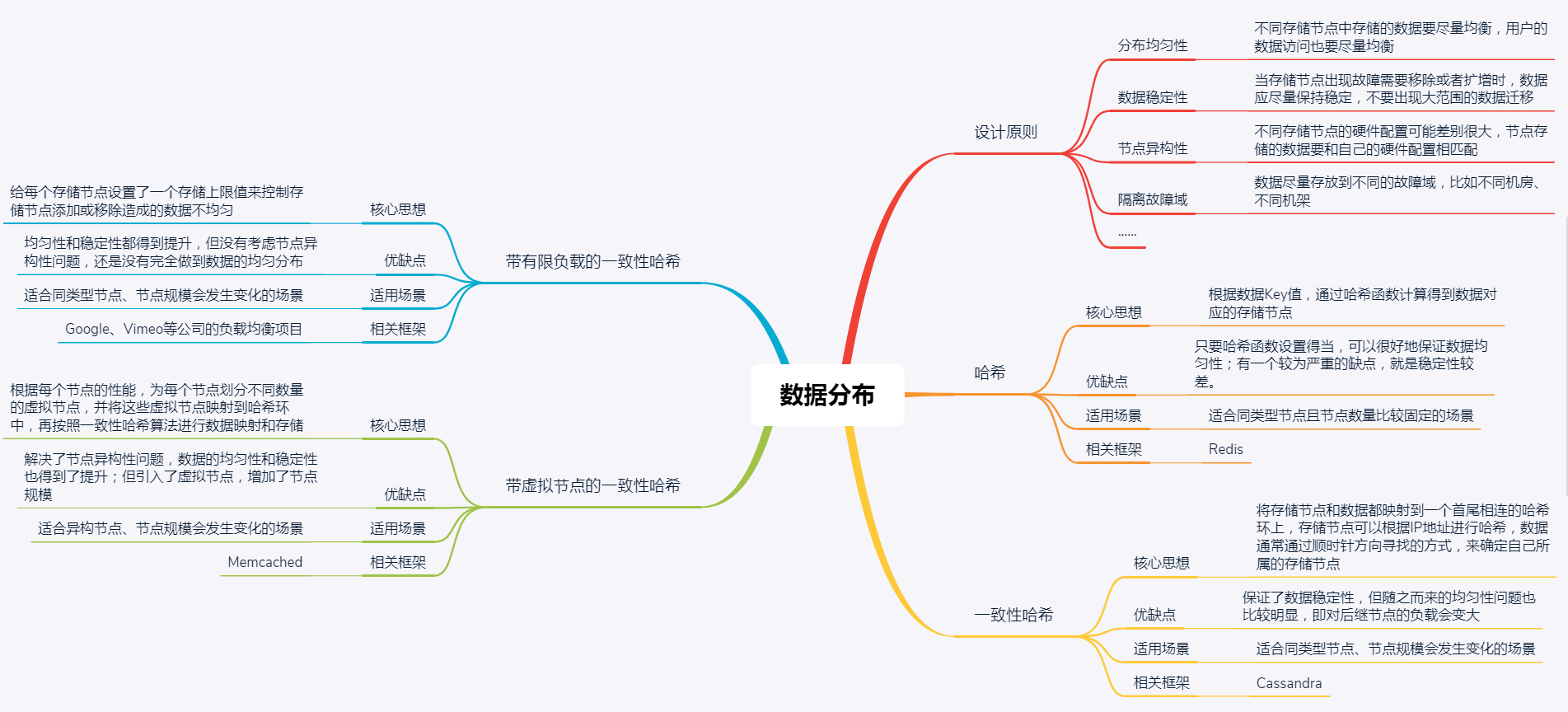
数据分布设计原则
常用
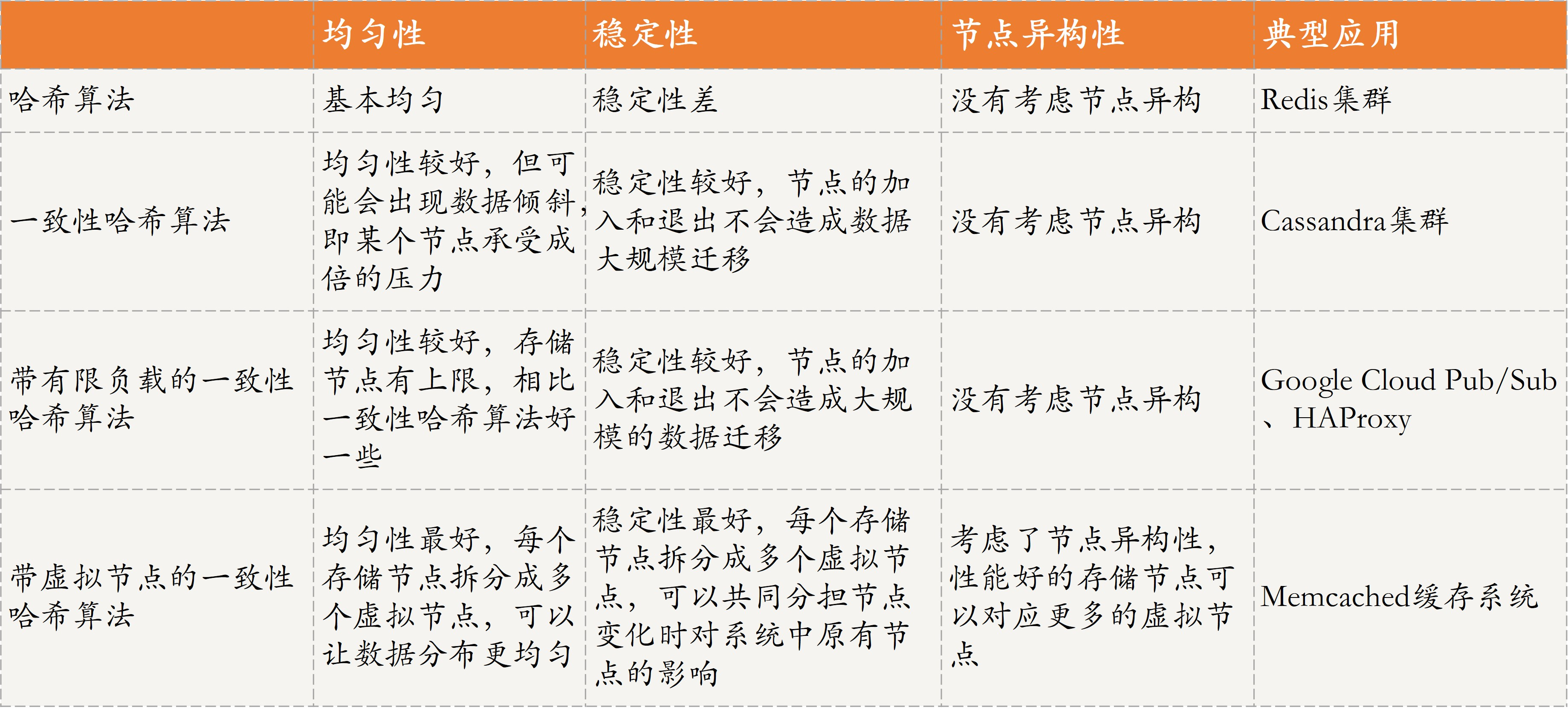
存储方案选型时,通常会考虑数据均匀、数据稳定和节点异构性这三个维度。
数据均匀的维度:
- 不同存储节点中存储的数据要尽量均衡,避免让某一个或某几个节点存储压力过大,而其他节点却几乎没什么数据。
- 用户访问也要做到均衡,避免出现某一个或某几个节点的访问量很大,但其他节点却无人问津的情况。
数据稳定的维度:
- 当存储节点出现故障需要移除或者扩增时,数据按照分布规则得到的结果应该尽量保持稳定,不要出现大范围的数据迁移。
节点异构性的维度:
- 不同存储节点的硬件配置可能差别很大。比如,有的节点硬件配置很高,可以存储大量数据,也可以承受更多的请求;但,有的节点硬件配置就不怎么样,存储的数据量不能过多,用户访问也不能过多。
其他
隔离故障域:
- 一个好的数据分布算法,应该为每个数据映射一组存储节点,这些节点应该尽量在不同的故障域,比如不同机房、不同机架等。
性能稳定性:
- 数据存储和查询的效率要有保证,不能因为节点的添加或者移除,造成存储或访问性能的严重下降。
数据分布方法
- 哈希
- 一致性哈希 (减少数据迁移)
- 带有限负载的一致性哈希 (限制每个节点的存储容量)
- 带虚拟节点的一致性哈希 (考虑不同节点的异构-性能)
对比
数据分片&数据分区
数据分片和数据分区是两个不同的概念,且属于分布式存储系统中不同角色的技术,前者是实现“导购”的关键技术,后者是“货架”相关的技术,不可直接等同。
总结

若有收获,就点个赞吧
0 人点赞
