什么是分布式数据存储系统?
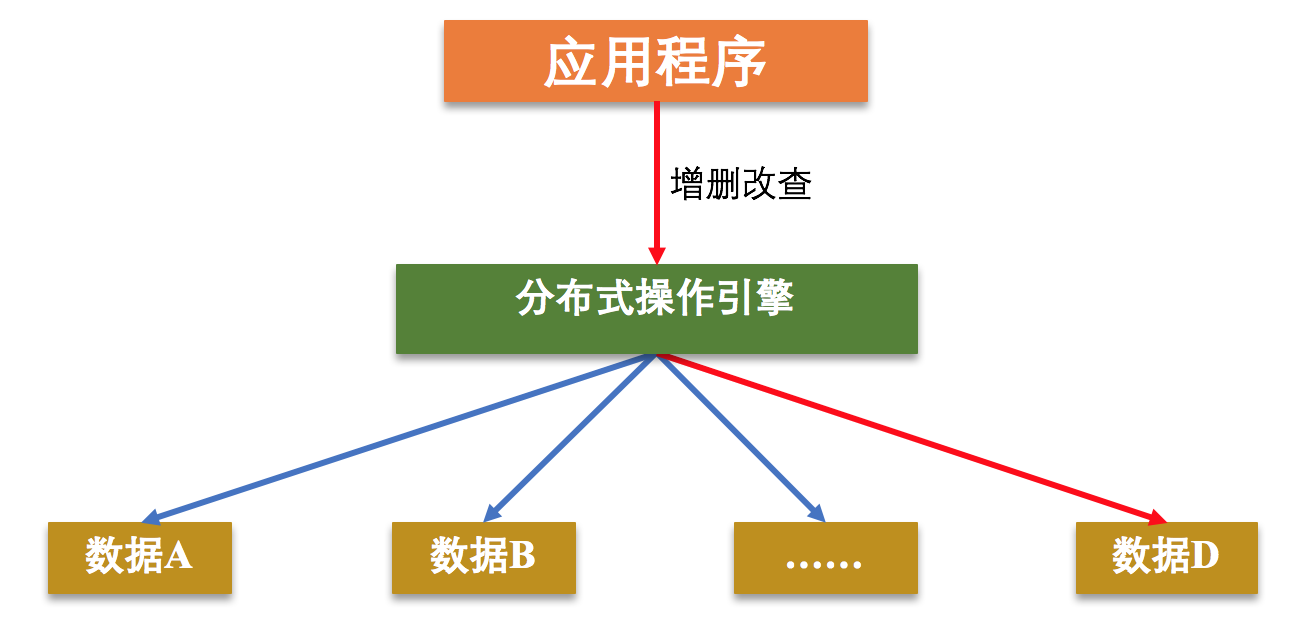
分布式存储系统的核心逻辑,就是将用户需要存储的数据根据某种规则存储到不同的机器上,当用户想要获取指定数据时,再按照规则到存储数据的机器里获取。
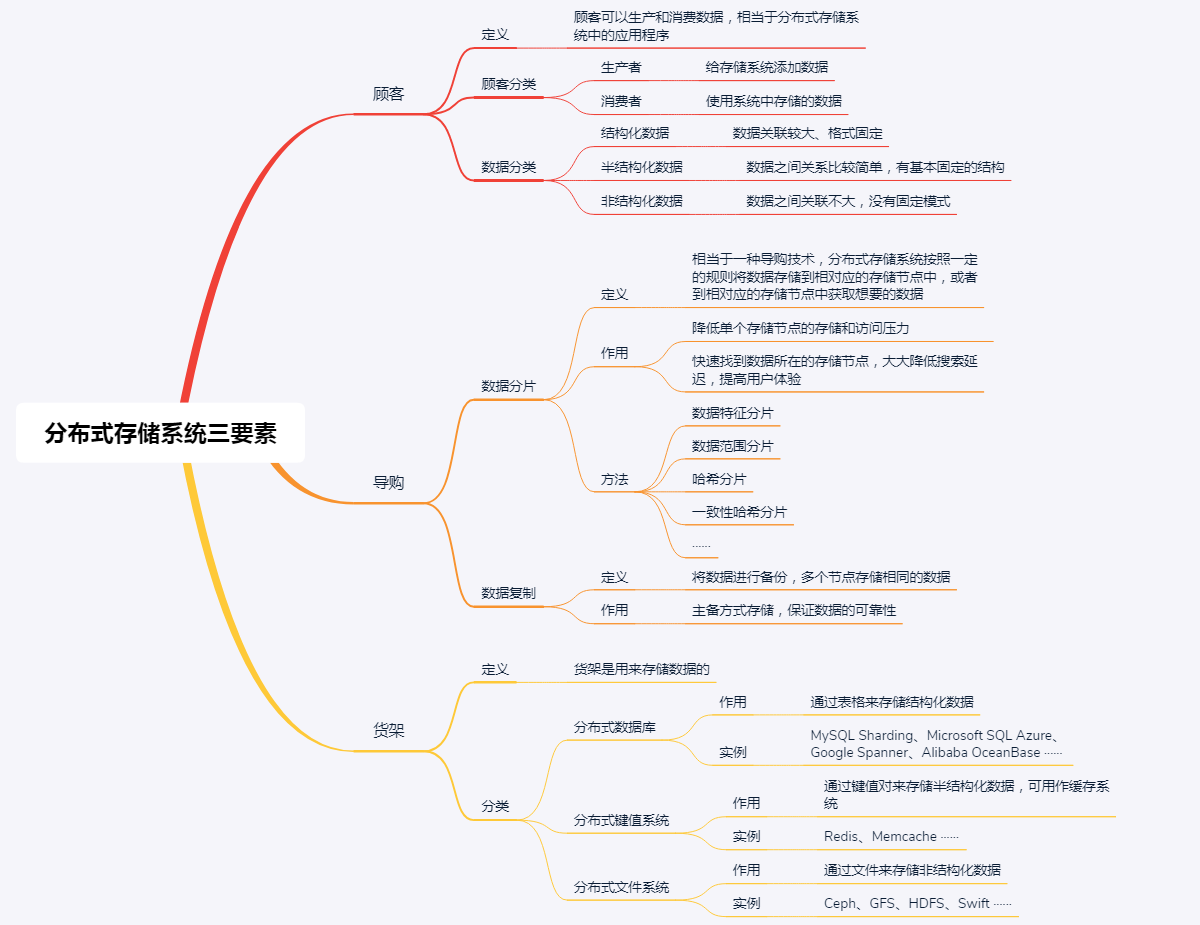
分布式数据存储系统三要素
- 数据生产者 / 消费者
- 数据索引
- 数据存储
顾客:生产和消费数据
数据通常被划分为三类:
- 结构化数据, 通常是指关系模型数据,其特征是数据关联较大、格式固定. 一般采用分布式关系数据库进行存储和查询
- 半结构化数据, 通常是指非关系模型的,有基本固定结构模式的数据,其特征是数据之间关系比较简单. 一般采用分布式键值系统进行存储和使用
- 非结构化数据, 指没有固定模式的数据,其特征是数据之间关联不大. 这种数据可以存储到文档中,通过 ElasticSearch(一个分布式全文搜索引擎)等进行检索
导购:确定数据位置
数据分片技术,是指分布式存储系统按照一定的规则将数据存储到相对应的存储节点中,或者到相对应的存储节点中获取想要的数据,这是一种很常用的导购技术。这种技术,一方面可以降低单个存储节点的存储和访问压力;另一方面,可以通过规定好的规则快速找到数据所在的存储节点,从而大大降低搜索延迟,提高用户体验。
货架:存储数据
- 分布式数据库,通过表格来存储结构化数据,方便查找。常用的分布式数据库有 MySQL Sharding、Microsoft SQL Azure、Google Spanner、Alibaba OceanBase 等。
- 分布式键值系统,通过键值对来存储半结构化数据。常用的分布式键值系统有 Redis、Memcache 等,可用作缓存系统。
- 分布式存储系统,通过文件、块、对象等来存储非结构化数据。常见的分布式存储系统有 Ceph、GFS、HDFS、Swift 等。
存储介质的选择:
- 磁盘存储量大,但 IO 开销大,访问速度较低,常用于存储不经常使用的数据。比如,电商系统中,排名比较靠后或购买量比较少、甚至无人购买的商品信息,通常就存储在磁盘上。
- 内存容量小,访问速度快,因此常用于存储需要经常访问的数据。比如,电商系统中,购买量比较多或排名比较靠前的商品信息,通常就存储在内存中。
总结

若有收获,就点个赞吧
0 人点赞
