分析整体思路
为了帮助你直观地理解大数据量对集群稳定性的影响,我首先将为你写入大量数据,构造一个 db 大小为 14G 的大集群。然后通过此集群为你分析 db 大小的各个影响面,db 大小影响面如下图所示。
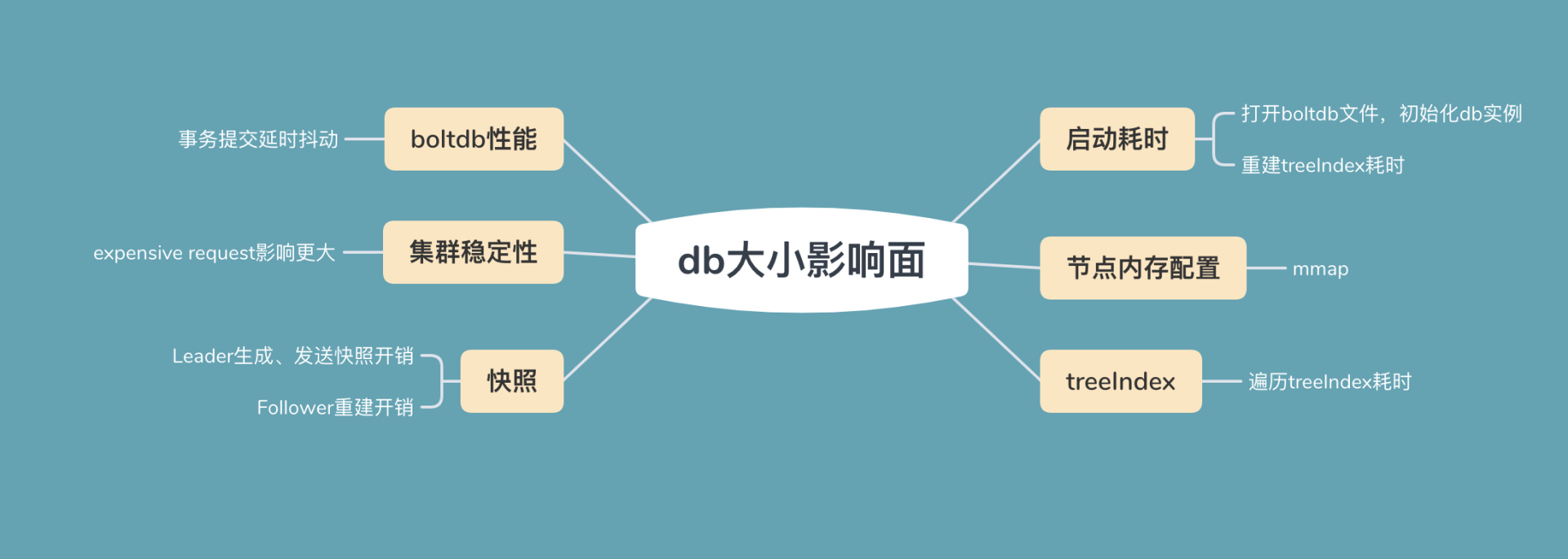
- 启动耗时。etcd 启动的时候,需打开 boltdb db 文件,读取 db 文件所有 key-value 数据,用于重建内存 treeIndex 模块。因此在大量 key 导致 db 文件过大的场景中,这会导致 etcd 启动较慢。
- 节点内存配置。etcd 在启动的时候会通过 mmap 将 db 文件映射内存中,若节点可用内存不足,小于 db 文件大小时,可能会出现缺页文件中断,导致服务稳定性、性能下降。
- treeIndex 索引性能。因 etcd 不支持数据分片,内存中的 treeIndex 若保存了几十万到上千万的 key,这会增加查询、修改操作的整体延时。
- boltdb 性能。大 db 文件场景会导致事务提交耗时增长、抖动
- 集群稳定性。大 db 文件场景下,无论你是百万级别小 key 还是上千个大 value 场景,一旦出现 expensive request 后,很容易导致 etcd OOM、节点带宽满而丢包。
- 快照。当 Follower 节点落后 Leader 较多数据的时候,会触发 Leader 生成快照重建发送给 Follower 节点,Follower 基于它进行还原重建操作。较大的 db 文件会导致 Leader 发送快照需要消耗较多的 CPU、网络带宽资源,同时 Follower 节点重建还原慢。
构造大集群
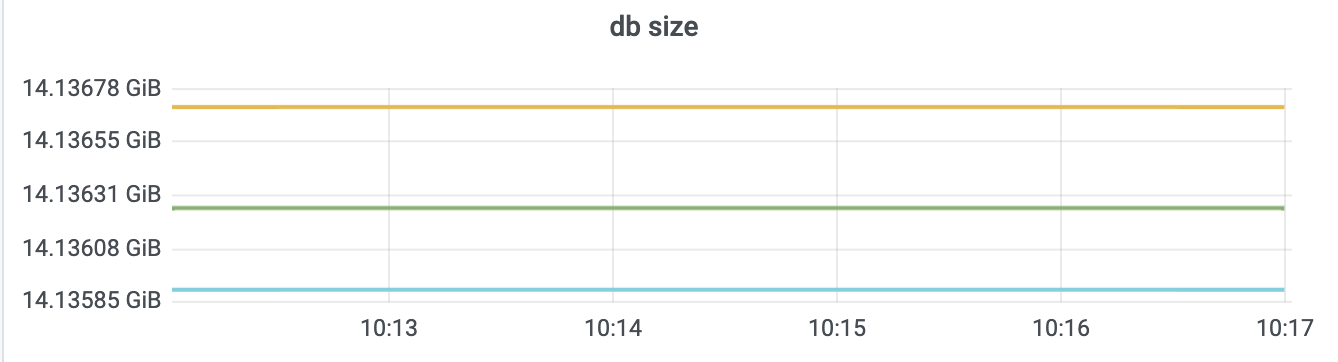
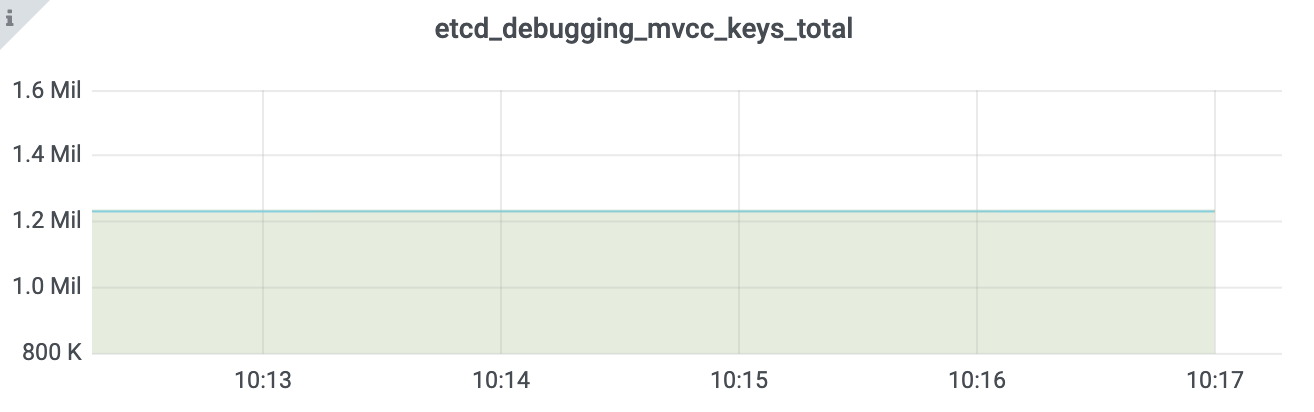
首先,我通过一系列如下benchmark命令,向一个 8 核 32G 的 3 节点的集群写入 120 万左右 key。key 大小为 32,value 大小为 256 到 10K,用以分析大 db 集群案例中的各个影响面。
./benchmark put --key-size 32 --val-size 10240 --total1000000 --key-space-size 2000000 --clients 50 --conns 50
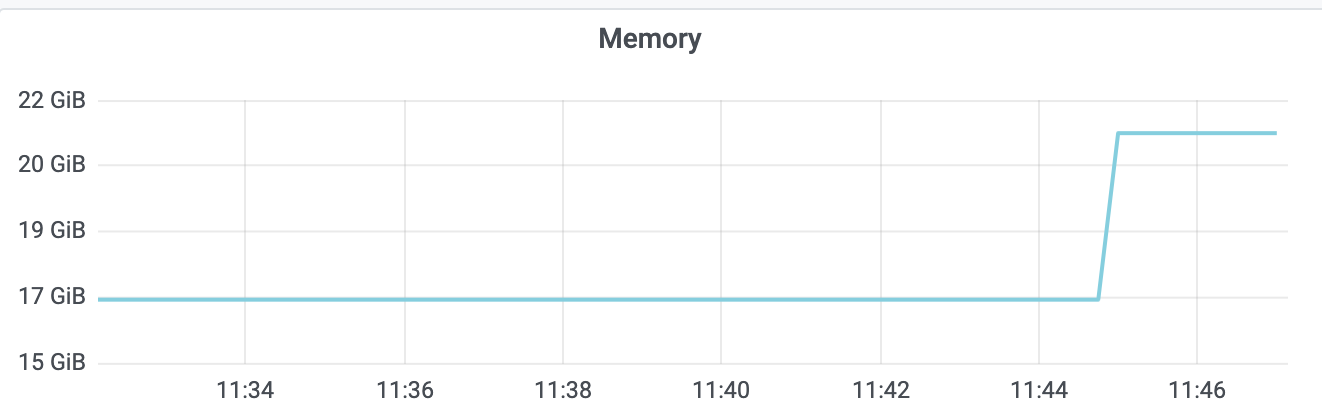
执行完一系列 benchmark 命令后,db size 达到 14G,总 key 数达到 120 万,其监控如下图所示:
启动耗时
在如上的集群中,我通过 benchmark 工具将 etcd 集群 db 大小压测到 14G 后,在重新启动 etcd 进程的时候,如下日志所示,你会发现启动比较慢,为什么大 db 文件会影响 etcd 启动耗时呢?
2021-02-15 02:25:55.273712 I | etcdmain: etcd Version: 3.4.92021-02-15 02:26:58.806882 I | etcdserver: recovered store from snapshot at index 21000902021-02-15 02:26:58.808810 I | mvcc: restore compact to 10000022021-02-15 02:27:19.120141 W | etcdserver: backend quota 26442450944 exceeds maximum recommended quota 85899345922021-02-15 02:27:19.297363 I | embed: ready to serve client requests
通过对 etcd 启动流程增加耗时统计,我们可以发现核心瓶颈主要在于打开 db 文件和重建内存 treeIndex 模块。
**
重建内存 treeIndex 的原理
我们知道 treeIndex 模块维护了用户 key 与 boltdb key 的映射关系,boltdb 的 key、value 又包含了构建 treeIndex 的所需的数据。因此 etcd 启动的时候,会启动不同角色的 goroutine 并发完成 treeIndex 构建。
- 首先是主 goroutine。它的职责是遍历 boltdb,获取所有 key-value 数据,并将其反序列化成 etcd 的 mvccpb.KeyValue 结构。核心原理是基于 etcd 存储在 boltdb 中的 key 数据有序性,按版本号从 1 开始批量遍历,每次查询 10000 条 key-value 记录,直到查询数据为空。
- 其次是构建 treeIndex 索引的 goroutine。它从主 goroutine 获取 mvccpb.KeyValue 数据,基于 key、版本号、是否带删除标识等信息,构建 keyIndex 对象,插入到 treeIndex 模块的 B-tree 中。
因可能存在多个 goroutine 并发操作 treeIndex,treeIndex 的 Insert 函数会加全局锁,如下所示。etcd 启动时只有一个构建 treeIndex 索引的 goroutine,因此 key 多时,会比较慢。之前我尝试优化成多 goroutine 并发构建,但是效果不佳,大量耗时会消耗在此锁上。
func (ti *treeIndex) Insert(ki *keyIndex) {
ti.Lock()
defer ti.Unlock()
ti.tree.ReplaceOrInsert(ki)
}
节点内存配置
etcd 进程重启完成后,在没任何读写 QPS 情况下,如下所示,你会发现 etcd 所消耗的内存比 db 大小还大一点。这又是为什么呢?如果 etcd db 文件大小超过节点内存规格,会导致什么问题吗?
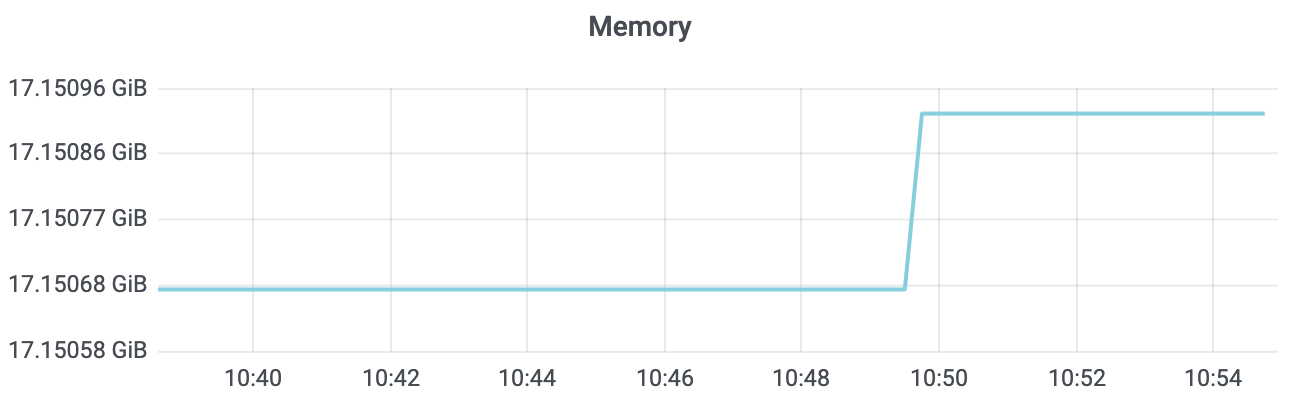
- 由于 etcd 调用 boltdb Open API 的时候,设置了 mmap 的 MAP_POPULATE flag,它会告诉 Linux 内核预读文件,将 db 文件内容全部从磁盘加载到物理内存中。
- 因此在你节点内存充足的情况下,启动后你看到的 etcd 占用内存,一般是 db 文件大小与内存 treeIndex 之和。
- 当你的 db 文件大小超过节点内存配置时,若你查询的 key 所相关的 branch page、leaf page 不在内存中,那就会触发主缺页中断,导致读延时抖动、QPS 下降。
为了保证 etcd 集群性能的稳定性,我建议你的 etcd 节点内存规格要大于你的 etcd db 文件大小。
treeIndex
当我们往集群中写入了一百多万 key 时,此时你再读取一个 key 范围操作的延时会出现一定程度上升,这是为什么呢?我们该如何分析耗时是在哪一步导致的?
在 etcd 3.4 中提供了 trace 特性,它可帮助我们定位、分析请求耗时过长问题。不过你需要特别注意的是,此特性在 etcd 3.4 中,因为依赖 zap logger,默认为关闭。你可以通过设置 etcd 启动参数中的 —logger=zap 来开启。
开启之后,我们可以在 etcd 日志中找到类似如下的耗时记录:
{
"msg":"trace[331581563] range",
"detail":"{range_begin:/vip/a; range_end:/vip/b; response_count:19304; response_revision:1005564; }",
"duration":"146.432768ms",
"steps":[
"trace[331581563] 'range keys from in-memory treeIndex' (duration: 95.925033ms)",
"trace[331581563] 'range keys from bolt db' (duration: 47.932118ms)"
]
此日志记录了查询请求”etcdctl get —prefix /vip/a”。它在 treeIndex 中查询相关 key 耗时 95ms,从 boltdb 遍历 key 时 47ms。主要原因还是此查询涉及的 key 数较多,高达一万九。
boltdb 性能
当 db 文件大小持续增长到 16G 乃至更大后,从 etcd 事务提交监控 metrics 你可能会观察到,boltdb 在提交事务时偶尔出现了较高延时,那么延时是怎么产生的呢?
在10介绍 boltdb 的原理时,我和你分享了 db 文件的磁盘布局,它是由 meta page、branch page、leaf page、free list、free 页组成的。同时我给你介绍了 boltdb 事务提交的四个核心流程,分别是 B+ tree 的重平衡、分裂,持久化 dirty page,持久化 freelist 以及持久化 meta data。
- 事务提交延时抖动的原因主要是在 B+ tree 树的重平衡和分裂过程中,它需要从 freelist 中申请若干连续的 page 存储数据,或释放空闲的 page 到 freelist。
- freelist 后端实现在 boltdb 中是 array。当申请一个连续的 n 个 page 存储数据时,它会遍历 boltdb 中所有的空闲页,直到找到连续的 n 个 page。因此它的时间复杂度是 O(N)。若 db 文件较大,又存在大量的碎片空闲页,很可能导致超时。
- 同时事务提交过程中,也可能会释放若干个 page 给 freelist,因此需要合并到 freelist 的数组中,此操作时间复杂度是 O(NLog N)。
为了优化 boltdb 事务提交的性能,etcd 社区在 bbolt 项目中,实现了基于 hashmap 来管理 freelist。通过引入了如下的三个 map 数据结构(freemaps 的 key 是连续的页数,value 是以空闲页的起始页 pgid 集合,forwardmap 和 backmap 用于释放的时候快速合并页),将申请和释放时间复杂度降低到了 O(1)。
freelist 后端实现可以通过 bbolt 的 FreeListType 参数来控制,支持 array 和 hashmap。在 etcd 3.4 版本中目前还是 array,未来的 3.5 版本将默认是 hashmap。
freemaps map[uint64]pidSet // key is the size of continuous pages(span),value is a set which contains the starting pgids of same size
forwardMap map[pgid]uint64 // key is start pgid,value is its span size
backwardMap map[pgid]uint64 // key is end pgid,value is its span size
另外在 db 中若存在大量空闲页,持久化 freelist 需要消耗较多的 db 大小,并会导致额外的事务提交延时。
**
若未持久化 freelist,bbolt 支持通过重启时扫描全部 page 来构造 freelist,降低了 db 大小和提升写事务提交的性能(但是它会带来 etcd 启动延时的上升)。此行为可以通过 bbolt 的 NoFreelistSync 参数来控制,默认是 true 启用此特性。
集群稳定性
db 文件增大后,另外一个非常大的隐患是用户 client 发起的 expensive request,容易导致集群出现各种稳定性问题。
- 本质原因是 etcd 不支持数据分片,各个节点保存了所有 key-value 数据,同时它们又存储在 boltdb 的一个 bucket 里面。当你的集群含有百万级以上 key 的时候,任意一种 expensive read 请求都可能导致 etcd 出现 OOM、丢包等情况发生。
有哪些 expensive read 请求会导致 etcd 不稳定性呢?
- 首先是简单的 count only 查询。如下图所示,当你想通过 API 统计一个集群有多少 key 时,如果你的 key 较多,则有可能导致内存突增和较大的延时。
在 etcd 3.5 版本之前,统计 key 数会遍历 treeIndex,把 key 追加到数组中。然而当数据规模较大时,追加 key 到数组中的操作会消耗大量内存,同时数组扩容时涉及到大量数据拷贝,会导致延时上升。
- 其次是 limit 查询。当你只想查询若干条数据的时候,若你的 key 较多,也会导致类似 count only 查询的性能、稳定性问题。
原因是 etcd 3.5 版本之前遍历 index B-tree 时,并未将 limit 参数下推到索引层,导致了无用的资源和时间消耗。优化方案也很简单,etcd 3.5 中我提的优化 PR 将 limit 参数下推到了索引层,实现查询性能百倍提升。
- 最后是大包查询。当你未分页批量遍历 key-value 数据或单 key-value 数据较大的时候,随着请求 QPS 增大,etcd OOM、节点出现带宽瓶颈导致丢包的风险会越来越大。
- 第一,etcd 需要遍历 treeIndex 获取 key 列表。若你未分页,一次查询万级 key,显然会消耗大量内存并且高延时。
- 第二,获取到 key 列表、版本号后,etcd 需要遍历 boltdb,将 key-value 保存到查询结果数据结构中。如下 trace 日志所示,一个请求可能在遍历 boltdb 时花费很长时间,同时可能会消耗几百 M 甚至数 G 的内存。随着请求 QPS 增大,极易出现 OOM、丢包等。etcd 这块未来的优化点是实现流式传输。
{
"level":"info",
"ts":"2021-02-15T03:44:52.209Z",
"caller":"traceutil/trace.go:145",
"msg":"trace[1908866301] range",
"detail":"{range_begin:; range_end:; response_count:1232274; response_revision:3128500; }",
"duration":"9.063748801s",
"start":"2021-02-15T03:44:43.145Z",
"end":"2021-02-15T03:44:52.209Z",
"steps":[
"trace[1908866301] 'range keys from in-memory index tree' (duration: 693.262565ms)",
"trace[1908866301] 'range keys from bolt db' (duration: 8.22558566s)",
"trace[1908866301] 'assemble the response' (duration: 18.810315ms)"
]
}
快照
大 db 文件最后一个影响面是快照。它会影响 db 备份文件生成速度、Leader 发送快照给 Follower 节点的资源开销、Follower 节点通过快照重建恢复的速度。
我们知道 etcd 提供了快照功能,帮助我们通过 API 即可备份 etcd 数据。当 etcd 收到 snapshot 请求的时候,它会通过 boltdb 接口创建一个只读事务 Tx,随后通过事务的 WriteTo 接口,将 meta page 和 data page 拷贝到 buffer 即可。
- 随着 db 文件增大,快照事务执行的时间也会越来越长,而长事务则会导致 db 文件大小发生显著增加。
快照的另一大作用是当 Follower 节点异常的时候,Leader 生成快照发送给 Follower 节点,Follower 使用快照重建并追赶上 Leader。此过程涉及到一定的 CPU、内存、网络带宽等资源开销。
同时,若快照和集群写 QPS 较大,Leader 发送快照给 Follower 和 Follower 应用快照到状态机的流程会耗费较长的时间,这可能会导致基于快照重建后的 Follower 依然无法通过正常的日志复制模式来追赶 Leader,只能继续触发 Leader 生成快照,进而进入死循环,Follower 一直处于异常中。
**
精选留言
fran712
请问老师:
etcd的数据容量是直接查看数据目录的大小?还是通过prometheus等监控手段查看?还是通过API或命令查看?
作者回复: 一般我们都是通过prometheus采集etcd metrics,配置grafana视图查看的,db 大小的metrics是这个etcd_debugging_mvcc_db_total_size_in_bytes
雾雾glu
请教一下老师:
看到阿里贡献的 cncf 博客中提到了,优化了算法后可以将存储提升至 100G: https://www.cncf.io/blog/2019/05/09/performance-optimization-of-etcd-in-web-scale-data-scenario/#Conclusion
但是在官方文档中,还是写着的是 8G,不确定这个数据是否是最新的?
作者回复: 目前依然是8G,阿里提的PR就是文中说的使用hashmap来管理boltdb freelist, 它解决了boltdb文件特别大(>20G)场景下的freelist管理瓶颈。除了boltdb本身瓶颈,文中我给出了很多其他影响面,比如etcd启动耗时,一个14G,100万的key就启动接近2分钟,还有expensive request对大数据量etcd集群影响特别大, 因为etcd存储的key-value数据都是在一个bucket里面,目前etcd没有任何QoS机制,一旦不小心发起一个遍历大量key的查询就容易出现各种稳定性问题了。

若有收获,就点个赞吧
0 人点赞
