租约(Lease)
什么是 Lease
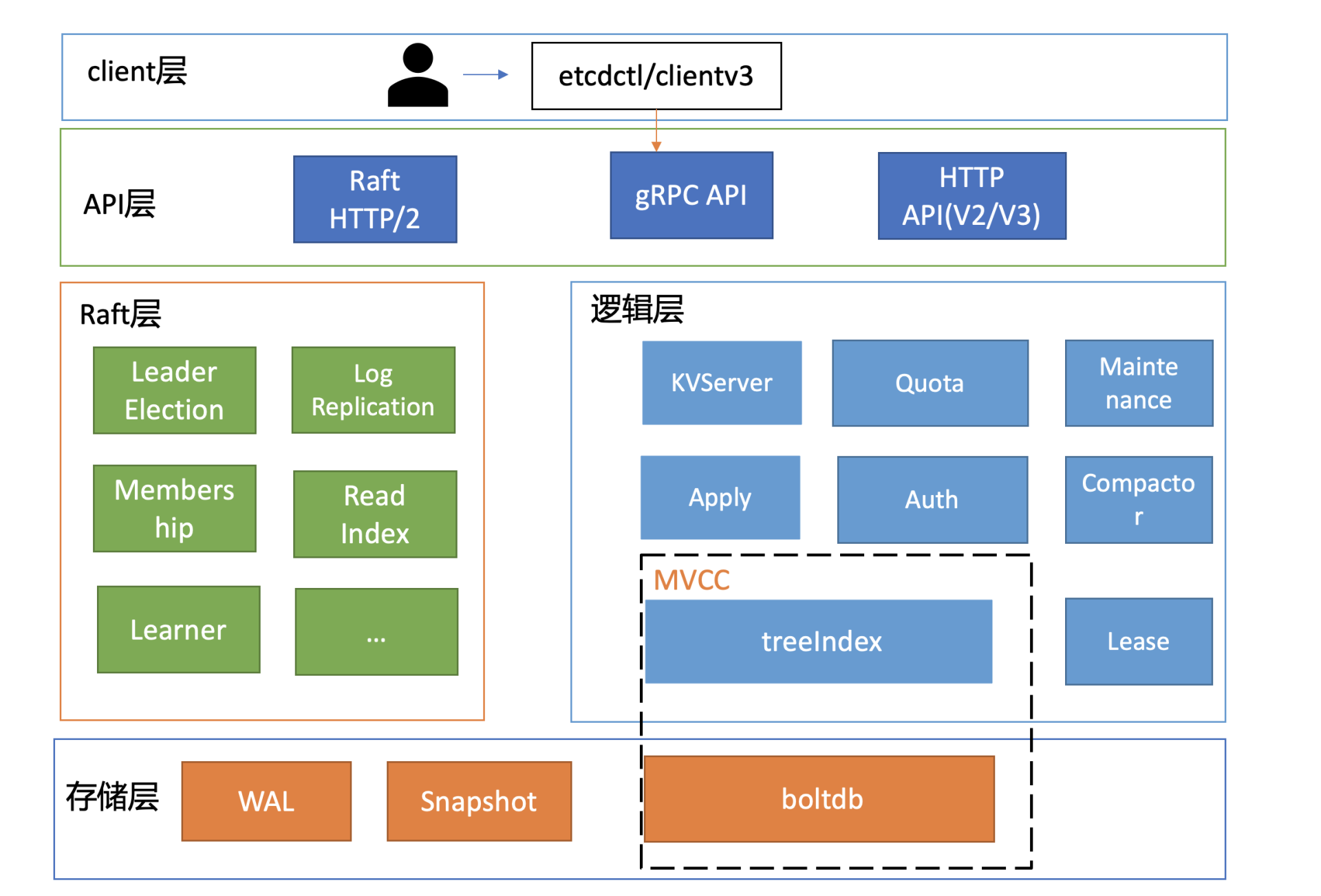
Leader 选举本质是要解决什么问题呢?
- Leader 的唯一性
- 主节点故障后,备节点应可快速感知到其异常,也就是活性(liveness)检测
实现活性检测主要有两种方案:
- 被动型检测,你可以通过探测节点定时拨测 Leader 节点,看是否健康,比如 Redis Sentinel。
- 主动型上报,Leader 节点可定期向协调服务发送”特殊心跳”汇报健康状态,若其未正常发送心跳,并超过和协调服务约定的最大存活时间后,就会被协调服务移除 Leader 身份标识。同时其他节点可通过协调服务,快速感知到 Leader 故障了,进而发起新的选举。
Lease 顾名思义,client 和 etcd server 之间存在一个约定,内容是 etcd server 保证在约定的有效期内(TTL),不会删除你关联到此 Lease 上的 key-value。
Lease 整体架构
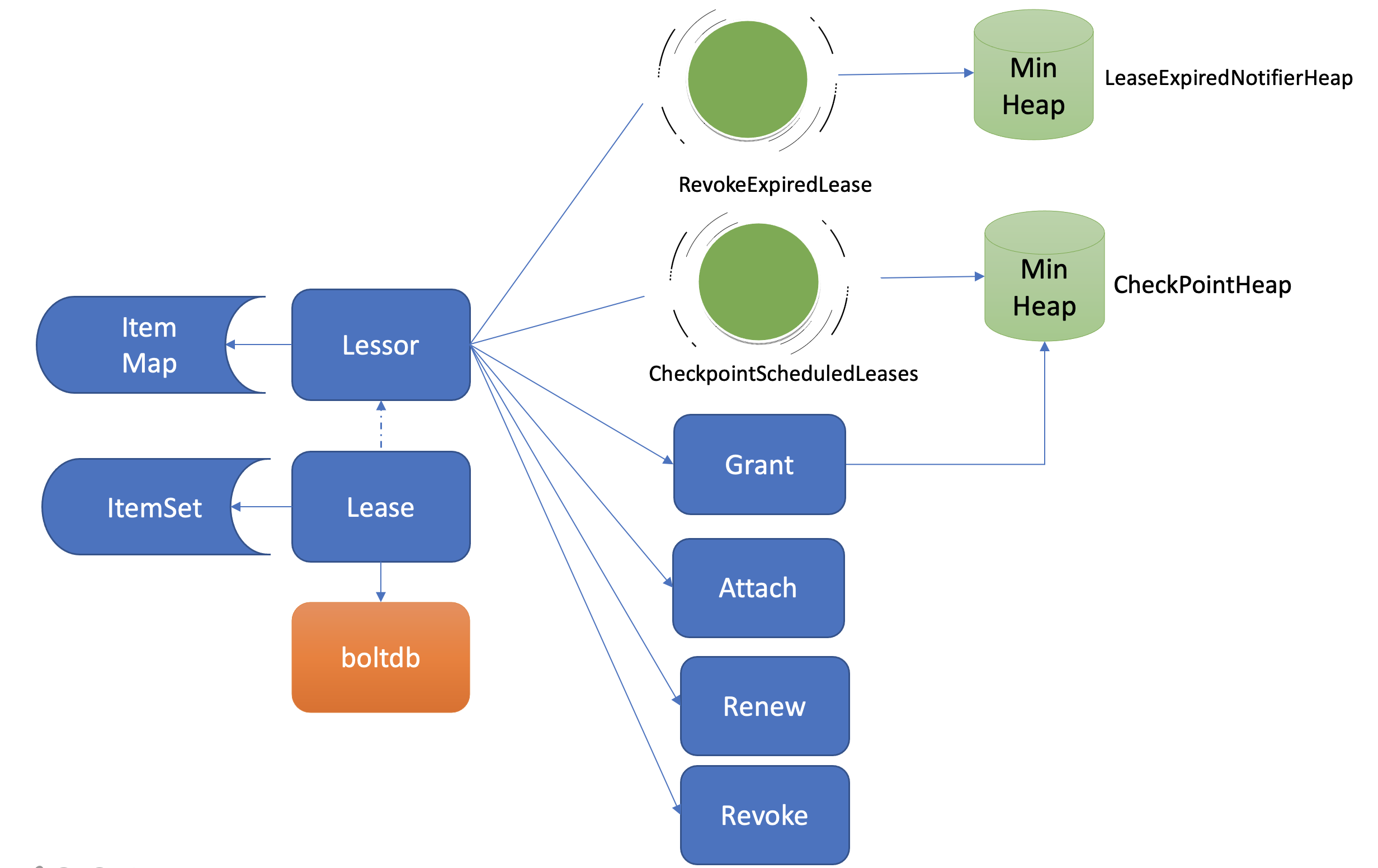
两个常驻 goroutine:
- RevokeExpiredLease 任务,定时检查是否有过期 Lease,发起撤销过期的 Lease 操作
- CheckpointScheduledLease,定时触发更新 Lease 的剩余到期时间的操作
Lessor 模块提供了 Grant、Revoke、LeaseTimeToLive、LeaseKeepAlive API 给 client 使用:
- Grant 表示创建一个 TTL 为你指定秒数的 Lease,Lessor 会将 Lease 信息持久化存储在 boltdb 中;
- Revoke 表示撤销 Lease 并删除其关联的数据;
- LeaseTimeToLive 表示获取一个 Lease 的有效期、剩余时间;
- LeaseKeepAlive 表示为 Lease 续期。
key 如何关联 Lease
- 创建 lease
# 创建一个TTL为600秒的lease,etcd server返回LeaseID$ etcdctl lease grant 600lease 326975935f48f814 granted with TTL(600s)# 查看lease的TTL、剩余时间$ etcdctl lease timetolive 326975935f48f814lease 326975935f48f814 granted with TTL(600s), remaining(590s)
创建 Lease 整体流程:
- 当 Lease server 收到 client 的创建一个有效期 600 秒的 Lease 请求后,会通过 Raft 模块完成日志同步,随后 Apply 模块通过 Lessor 模块的 Grant 接口执行日志条目内容。
Grant 接口流程:
- 首先 Lessor 的 Grant 接口会把 Lease 保存到内存的 ItemMap 数据结构中,然后它需要持久化 Lease,将 Lease 数据保存到 boltdb 的 Lease bucket 中,返回一个唯一的 LeaseID 给 client。
节点的健康指标数据如何关联到此 Lease 上呢?
- KV 模块的 API 接口提供了一个”—lease”参数,你可以通过如下命令,将 key node 关联到对应的 LeaseID 上。然后你查询的时候增加 -w 参数输出格式为 json,就可查看到 key 关联的 LeaseID。
$ etcdctl put node healthy --lease 326975935f48f818OK$ etcdctl get node -w=json | python -m json.tool{"kvs":[{"create_revision":24,"key":"bm9kZQ==","Lease":3632563850270275608,"mod_revision":24,"value":"aGVhbHRoeQ==","version":1}]}
看样子是为某个 key-value 设置一个超时时间.
流程图:

一个 Lease 关联的 key 集合是保存在内存中的,那么 etcd 重启时,是如何知道每个 Lease 上关联了哪些 key 呢?
- 答案是 etcd 的 MVCC 模块在持久化存储 key-value 的时候,保存到 boltdb 的 value 是个结构体(mvccpb.KeyValue), 它不仅包含你的 key-value 数据,还包含了关联的 LeaseID 等信息。因此当 etcd 重启时,可根据此信息,重建关联各个 Lease 的 key 集合列表。
如何优化 Lease 续期性能
在正常情况下,你的节点存活时,需要定期发送 KeepAlive 请求给 etcd 续期健康状态的 Lease,否则你的 Lease 和关联的数据就会被删除。
影响续期性能的因素:
- TTL 的大小
- Lease 数量
etcd v2 的 TTL 续期问题:
- 即使相同 TTL 的 key, 每个 key 都要创建一个 HTTP/1.x 连接
- 不支持多路复用
- 相同 TTL 无法复用
etcd v3 版本为了解决以上问题,提出了 Lease 特性,TTL 属性转移到了 Lease 上, 同时协议从 HTTP/1.x 优化成 gRPC 协议。
如何高效淘汰过期 Lease
淘汰过期 Lease 的工作由 Lessor 模块的一个异步 goroutine 负责。如下面架构图虚线框所示,它会定时从最小堆中取出已过期的 Lease,执行删除 Lease 和其关联的 key 列表数据的 RevokeExpiredLease 任务。
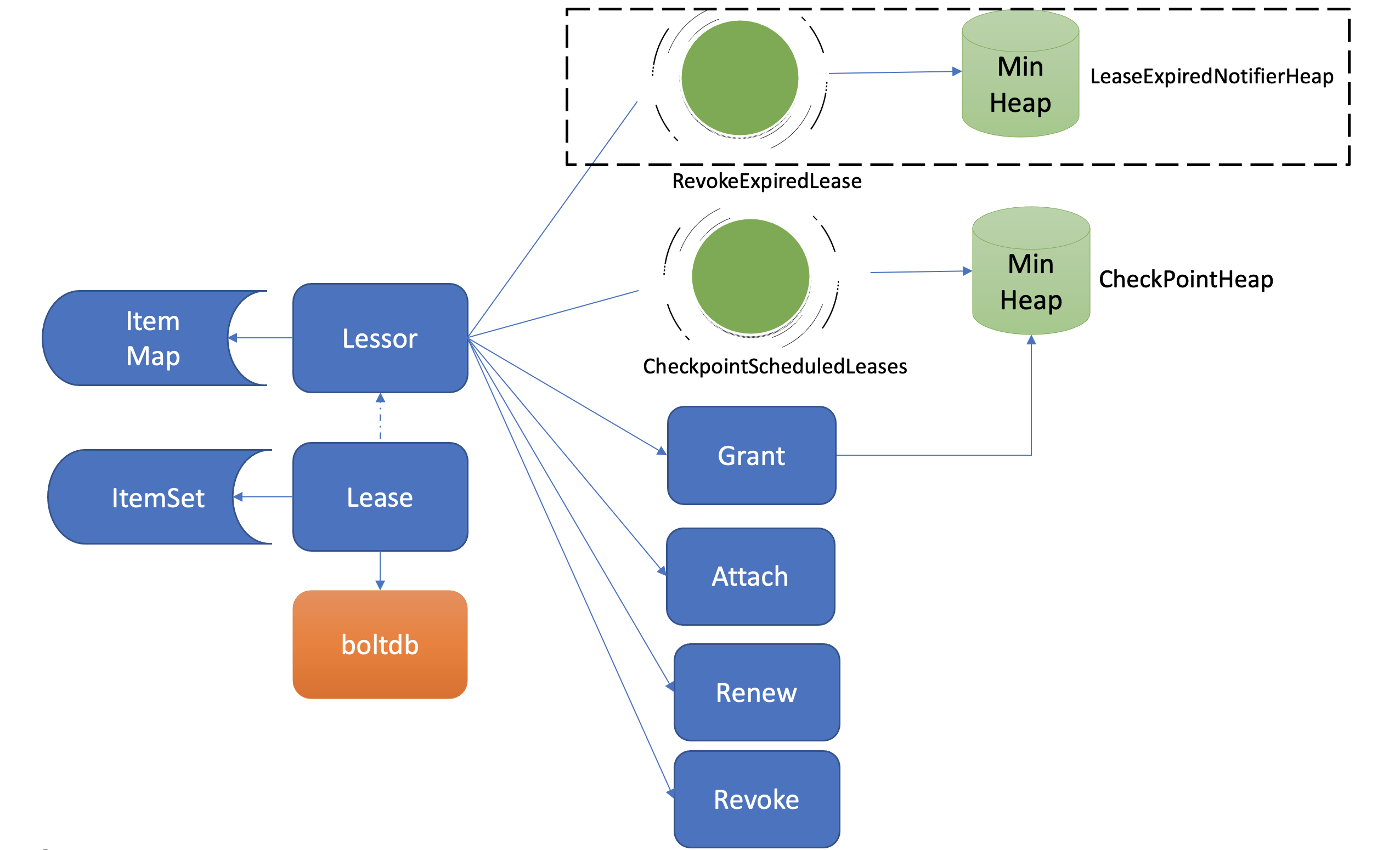
etcd Lessor 主循环每隔 500ms 执行一次撤销 Lease 检查(RevokeExpiredLease),每次轮询堆顶的元素,若已过期则加入到待淘汰列表,直到堆顶的 Lease 过期时间大于当前,则结束本轮轮询。
获取到待过期的 LeaseID 后,Leader 是如何通知其他 Follower 节点淘汰它们呢?
- Lessor 模块会将已确认过期的 LeaseID,保存在一个名为 expiredC 的 channel 中,而 etcd server 的主循环会定期从 channel 中获取 LeaseID,发起 revoke 请求,通过 Raft Log 传递给 Follower 节点。
- 各个节点收到 revoke Lease 请求后,获取关联到此 Lease 上的 key 列表,从 boltdb 中删除 key,从 Lessor 的 Lease map 内存中删除此 Lease 对象,最后还需要从 boltdb 的 Lease bucket 中删除这个 Lease。
为什么需要 checkpoint 机制
etcd 早期版本为了优化性能,并未持久化存储 Lease 剩余 TTL 信息,因此重建的时候就会自动给所有 Lease 自动续期了。
若较频繁出现 Leader 切换,切换时间小于 Lease 的 TTL,这会导致 Lease 永远无法删除,大量 key 堆积,db 大小超过配额等异常。
为了解决这个问题,etcd 引入了检查点机制,也就是下面架构图中黑色虚线框所示的 CheckPointScheduledLeases 的任务。

- 一方面,etcd 启动的时候,Leader 节点后台会运行此异步任务,定期批量地将 Lease 剩余的 TTL 基于 Raft Log 同步给 Follower 节点,Follower 节点收到 CheckPoint 请求后,更新内存数据结构 LeaseMap 的剩余 TTL 信息。
- 另一方面,当 Leader 节点收到 KeepAlive 请求的时候,它也会通过 checkpoint 机制把此 Lease 的剩余 TTL 重置,并同步给 Follower 节点,尽量确保续期后集群各个节点的 Lease 剩余 TTL 一致性。
最后你要注意的是,此特性对性能有一定影响,目前仍然是试验特性。你可以通过 experimental-enable-lease-checkpoint 参数开启。
有个细节上的疑问: 如果对某个 Lease 续期, 图中的两个 Min Heap 是如何更新的? 这个应该是数据结构问题: 先 delete 后 push 可以参考 Go 中堆的 API: package heap

若有收获,就点个赞吧
0 人点赞
