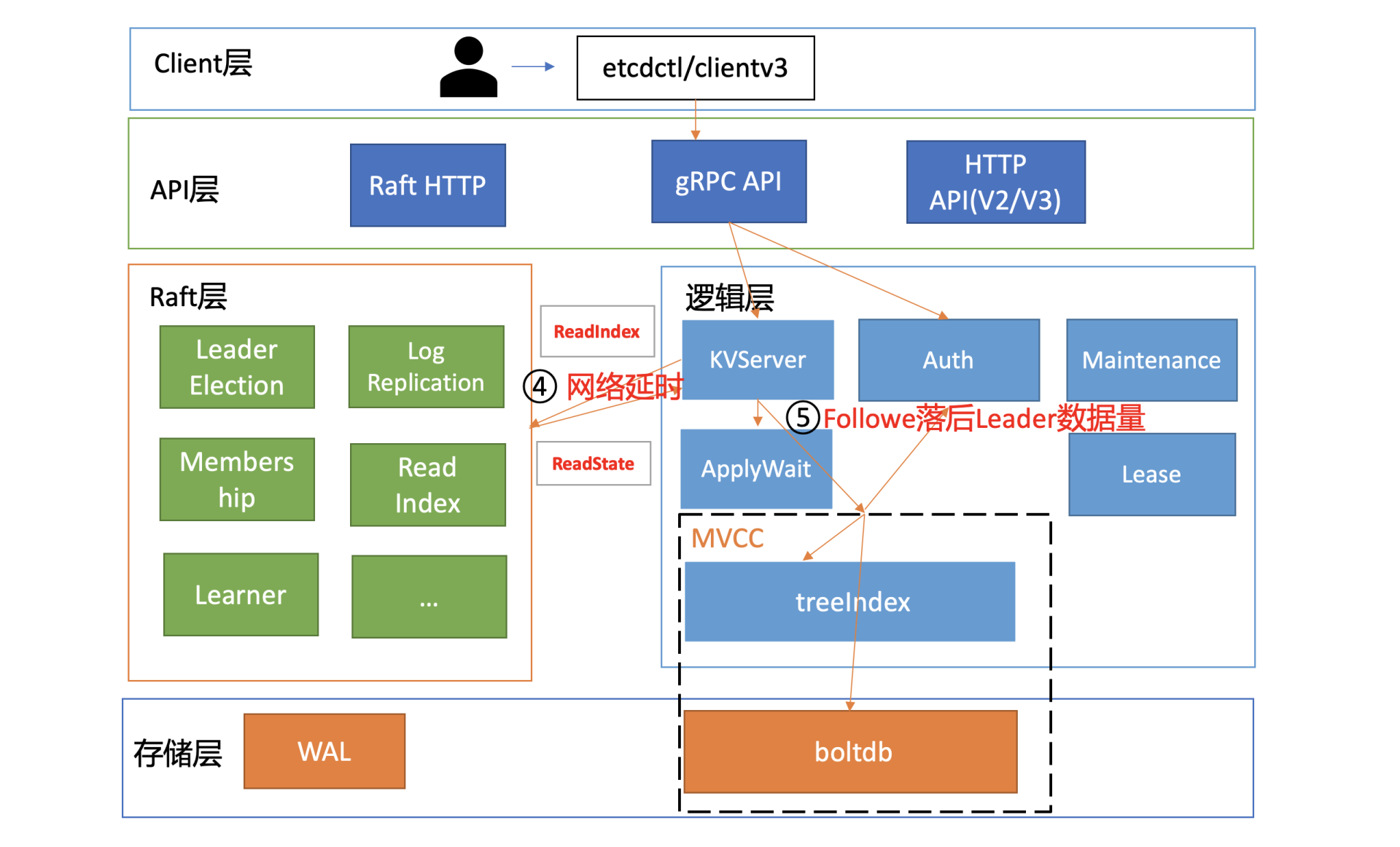
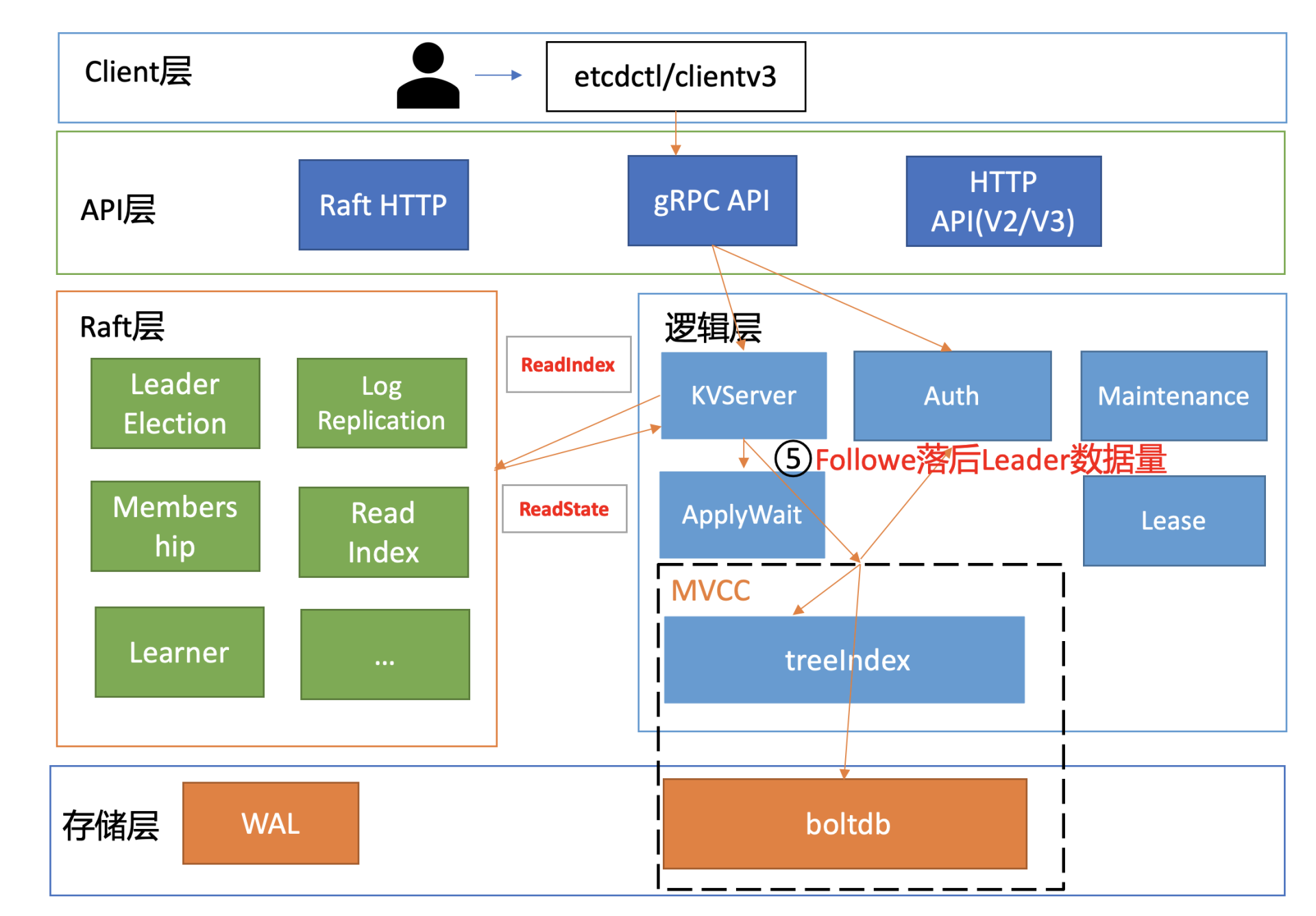
性能分析链路
在下图中,我为你总结了一个开启密码鉴权场景的读性能瓶颈分析链路图,并在每个核心步骤数字旁边,标出了影响性能的关键因素。我之所以选用密码鉴权的读请求为案例,是因为它使用较广泛并且请求链路覆盖最全,同时它也是最容易遇到性能瓶颈的场景。
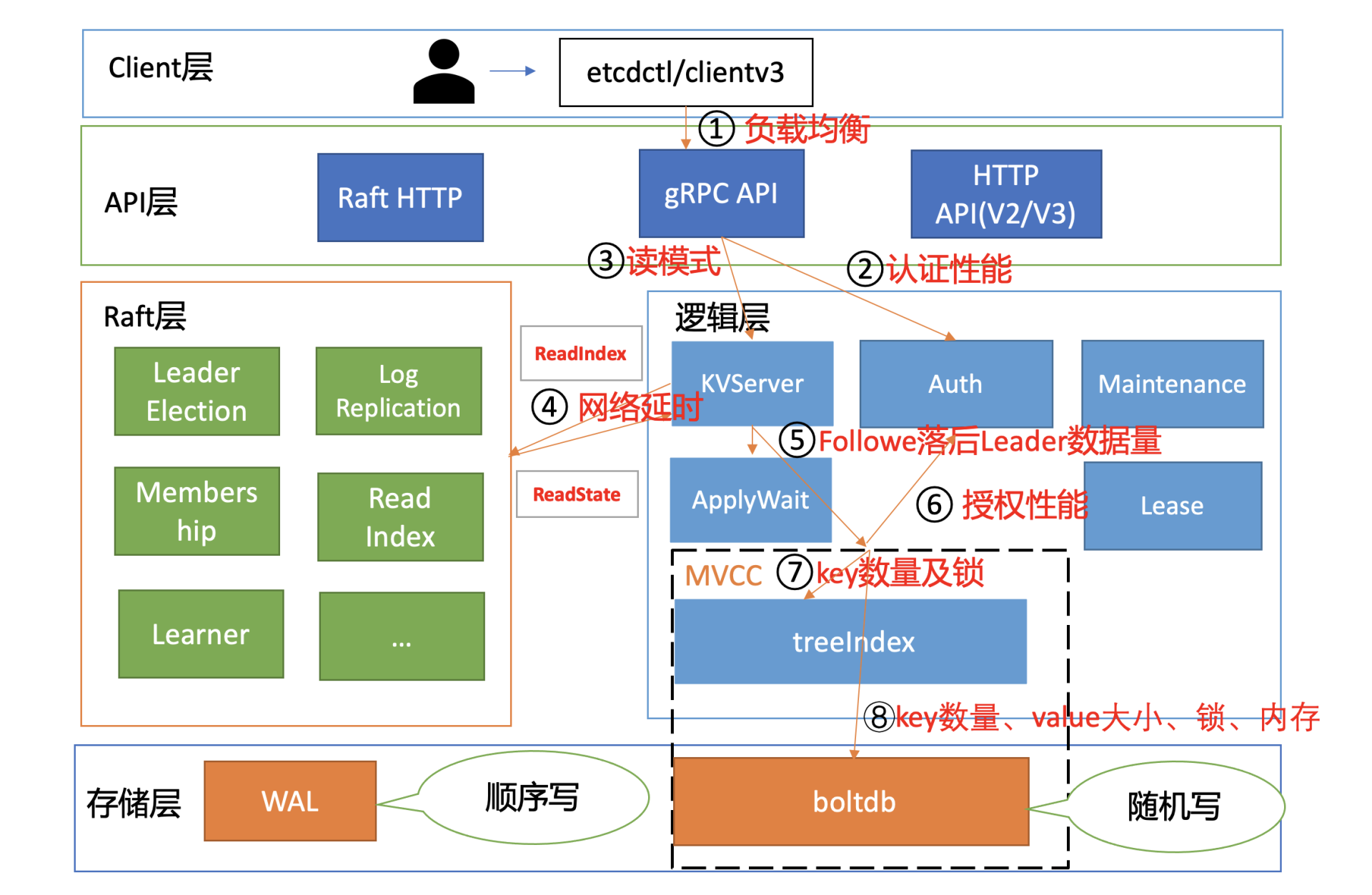
负载均衡
- 在 etcd 3.4 以前,client 为了节省与 server 节点的连接数,clientv3 负载均衡器最终只会选择一个 sever 节点 IP,与其建立一个长连接。
- 在 etcd 3.4 后,引入了 Round-robin 负载均衡算法,它通过轮询的方式依次从 endpoint 列表中选择一个 endpoint 访问 (长连接),使 server 节点负载尽量均衡
选择合适的鉴权
client 是如何向 sever 请求校验用户名、密码正确性的呢?
- client 是通过向 server 发送 Authenticate RPC 鉴权请求实现密码认证的,也就是图中的流程二。

- 根据我们05介绍的密码认证原理,server 节点收到鉴权请求后,它会从 boltdb 获取此用户密码对应的算法版本、salt、cost 值,并基于用户的请求明文密码计算出一个 hash 值。
- 在得到 hash 值后,就可以对比 db 里保存的 hash 密码是否与其一致了。如果一致,就会返回一个 token 给 client。 这个 token 是 client 访问 server 节点的通行证,后续 server 只需要校验“通行证”是否有效即可,无需每次发起昂贵的 Authenticate RPC 请求。
那这个 Authenticate 接口究竟有多慢呢?
为了得到 Authenticate 接口的性能,我们做过这样一个测试:
- 压测集群 etcd 节点配置是 16 核 32G;
- 压测方式是我们通过修改 etcd clientv3 库、benchmark 工具,使 benchmark 工具支持 Authenticate 接口压测;
- 然后设置不同的 client 和 connection 参数,运行多次,观察结果是否稳定,获取测试结果。
最终的测试结果非常惊人。etcd v3.4.9 之前的版本,Authenticate 接口性能不到 16 QPS,并且随着 client 和 connection 增多,该性能会继续恶化。
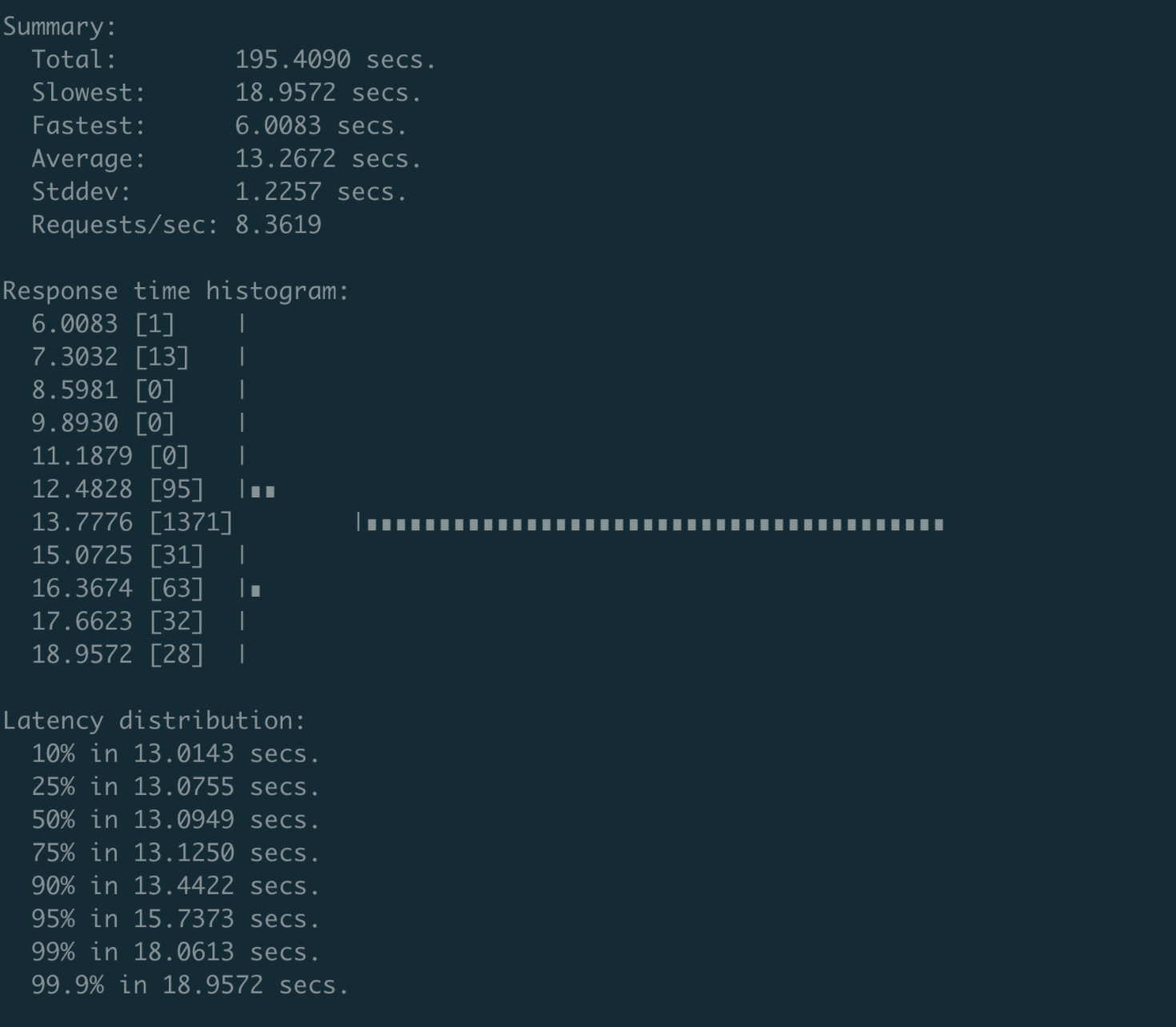
- 当 client 和 connection 的数量达到 200 个的时候,性能会下降到 8 QPS,P99 延时为 18 秒,如下图所示。
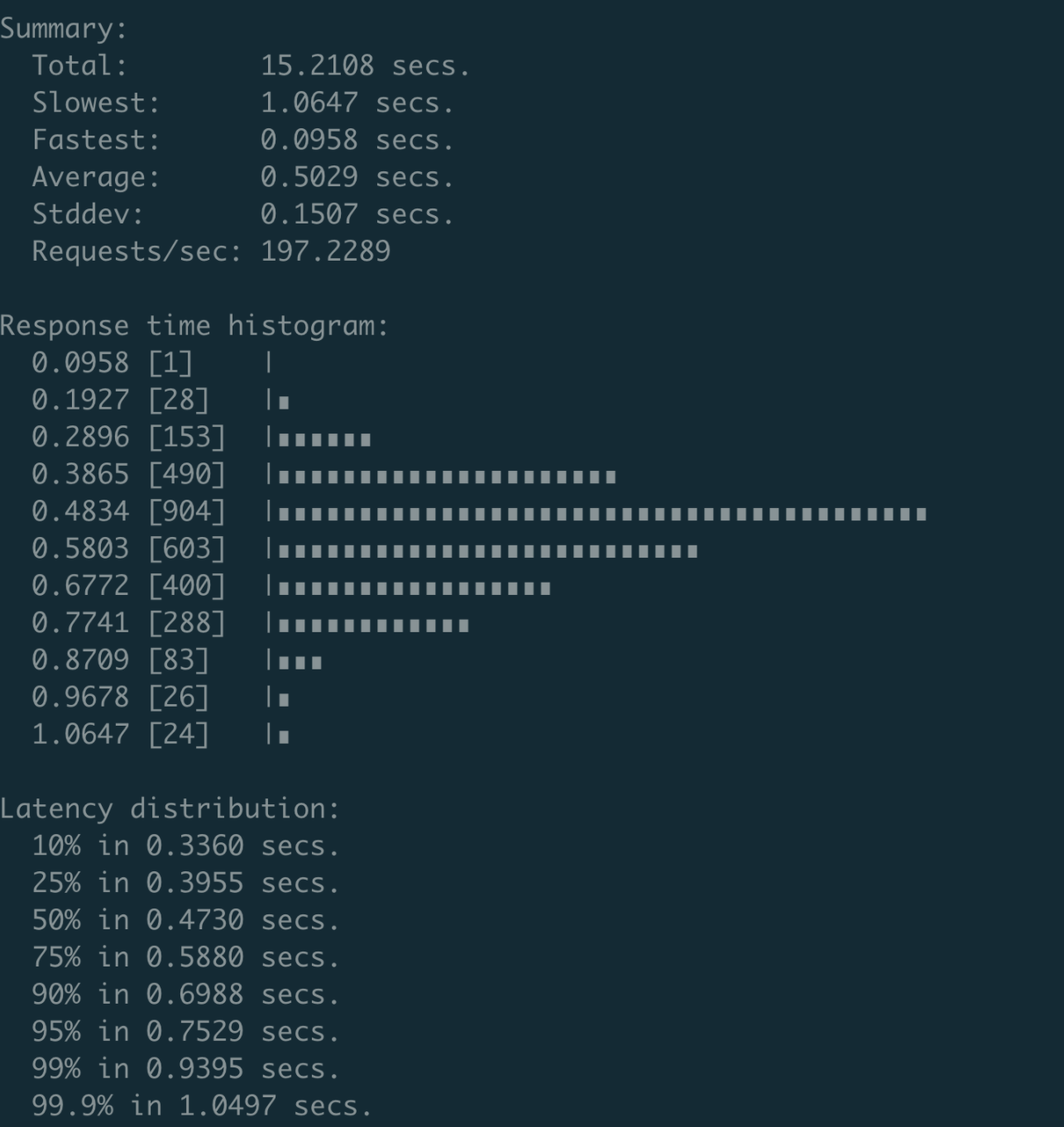
对此,我和小伙伴王超凡通过一个减少锁的范围 PR(该 PR 已经 cherry-pick 到了 etcd 3.4.9 版本),将性能优化到了约 200 QPS,并且 P99 延时在 1 秒内,如下图所示。
由于导致 Authenticate 接口性能差的核心瓶颈,是在于密码鉴权使用了 bcrpt 计算 hash 值,因此 Authenticate 性能已接近极限。
最令人头疼的是,Auenticate 的调用由 clientv3 库默默发起的,etcd 中也没有任何日志记录其耗时等。当大家开启密码鉴权后,遇到读写接口超时的时候,未详细了解 etcd 的同学就会非常困惑,很难定位超时本质原因。
密码鉴权的性能如此差,可是业务又需要使用它,我们该怎么解决密码鉴权的性能问题呢?对此,我有三点建议。
- 第一,如果你的生产环境需要开启鉴权,并且读写 QPS 较大,那我建议你不要图省事使用密码鉴权。最好使用证书鉴权,这样能完美避坑认证性能差、token 过期等问题,性能几乎无损失。
- 第二,确保你的业务每次发起请求时有复用 token 机制,尽可能减少 Authenticate RPC 调用。
- 第三,如果你使用密码鉴权时遇到性能瓶颈问题,可将 etcd 升级到 3.4.9 及以上版本,能适当提升密码鉴权的性能。
选择合适的读模式
client 通过 server 的鉴权后,就可以发起读请求调用了,也就是我们图中的流程三。
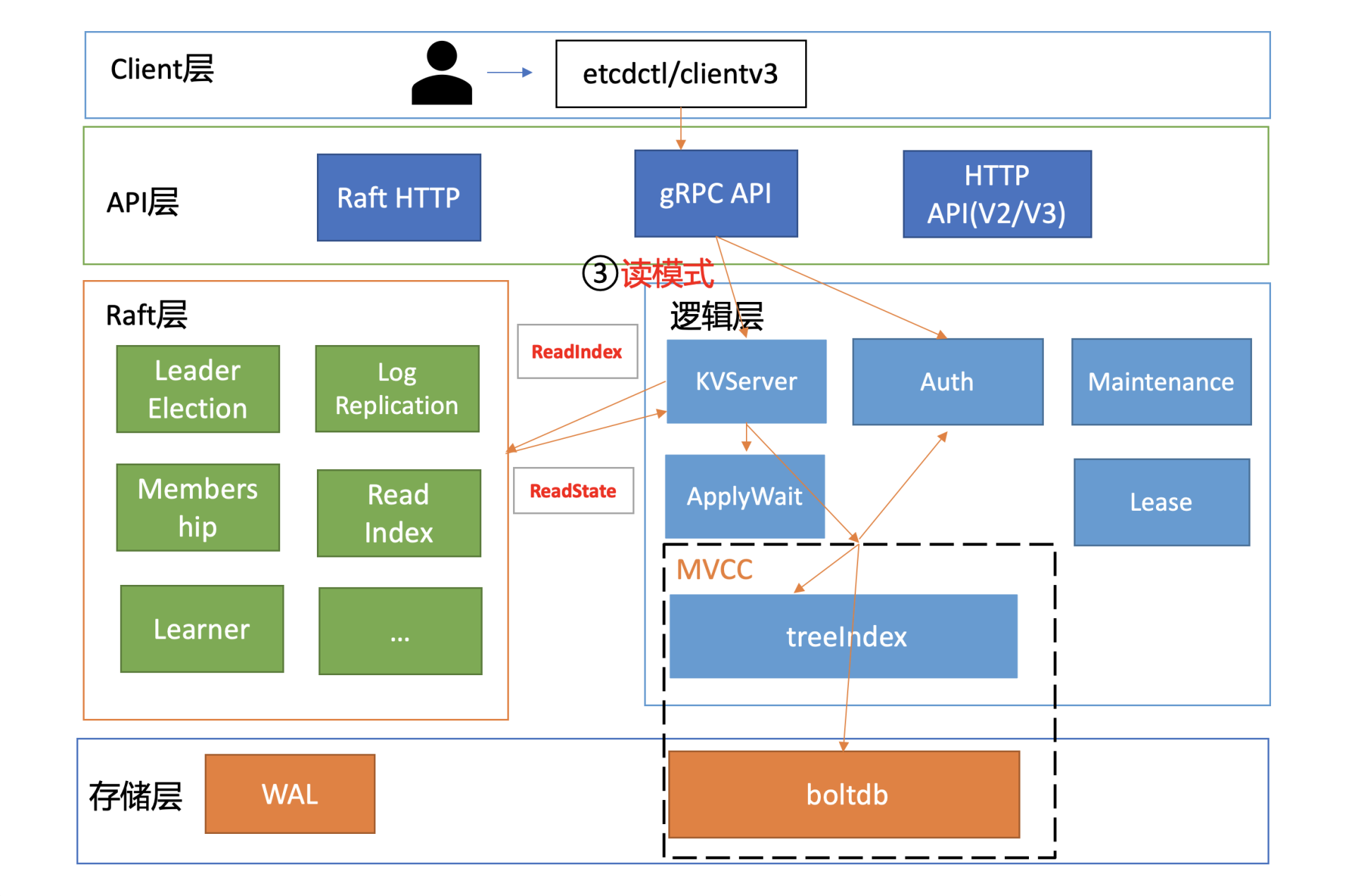
我们前面讲过 etcd 提供了串行读和线性读两种读模式。前者因为不经过 ReadIndex 模块,具有低延时、高吞吐量的特点;而后者在牺牲一点延时和吞吐量的基础上,实现了数据的强一致性读。
关于串行读和线性读的性能对比,下图我给出了一个测试结果,测试环境如下:
- 机器配置 client 16 核 32G,三个 server 节点 8 核 16G、SSD 盘,client 与 server 节点都在同可用区;
- 各节点之间 RTT 在 0.1ms 到 0.2ms 之间;
- etcd v3.4.9 版本;
- 1000 个 client。
执行如下串行读压测命令:
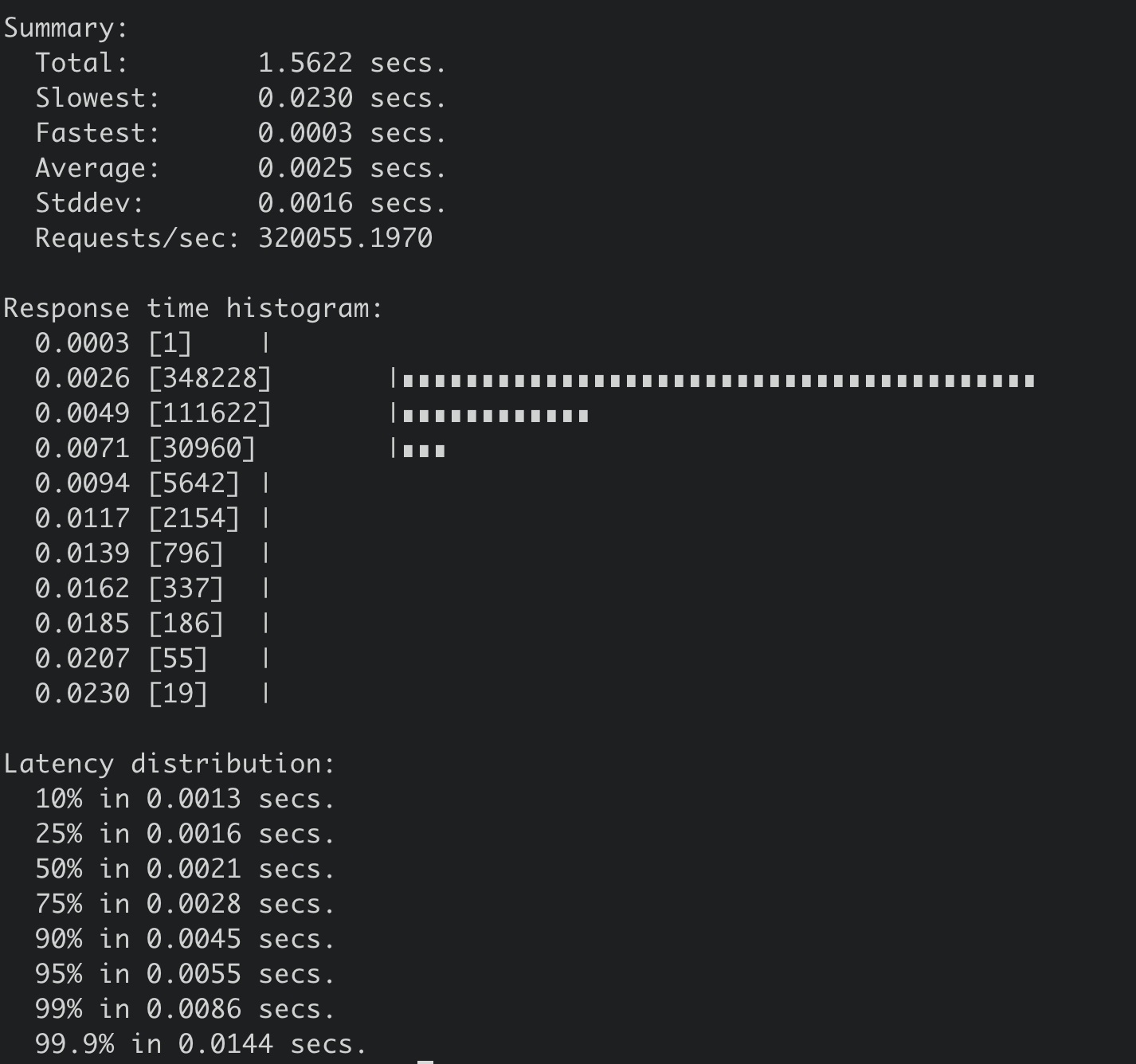
benchmark --endpoints=addr --conns=100 --clients=1000 \range hello --consistency=s --total=500000
得到串行读压测结果如下,32 万 QPS,平均延时 2.5ms。
执行如下线性读压测命令:
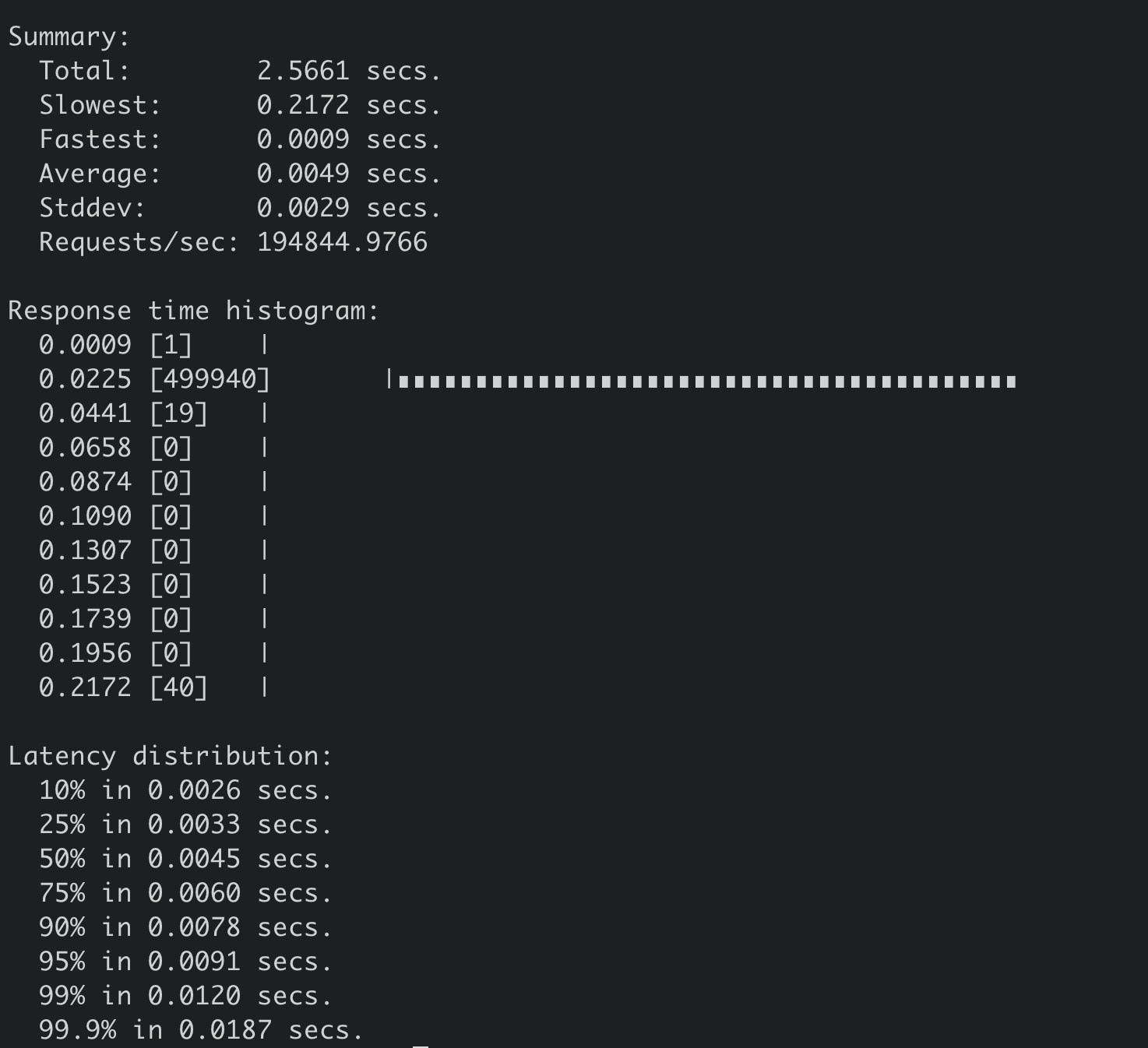
benchmark --endpoints=addr --conns=100 --clients=1000 \
range hello --consistency=l --total=500000
得到线性读压测结果如下,19 万 QPS,平均延时 4.9ms。
线性读实现机制、网络延时
了解完读模式对性能的影响后,我们继续往下分析。在我们这个密码鉴权读请求的性能分析案例中,读请求使用的是 etcd 默认线性读模式。线性读对应图中的流程四、流程五,其中流程四对应的是 ReadIndex,流程五对应的是等待本节点数据追上 Leader 的进度(ApplyWait)。
在早期的 etcd 3.0 版本中,etcd 线性读是基于 Raft log read 实现的。每次读请求要像写请求一样,生成一个 Raft 日志条目,然后提交给 Raft 一致性模块处理,基于 Raft 日志执行的有序性来实现线性读。因为该过程需要经过磁盘 I/O,所以性能较差。
为了解决 Raft log read 的线性读性能瓶颈,etcd 3.1 中引入了 ReadIndex。ReadIndex 仅涉及到各个节点之间网络通信,因此节点之间的 RTT 延时对其性能有较大影响。虽然同可用区可获取到最佳性能,但是存在单可用区故障风险。如果你想实现高可用区容灾的话,那就必须牺牲一点性能了。
磁盘 IO 性能、写 QPS
到了流程五,影响性能的核心因素就是磁盘 IO 延时和写 QPS。
如下面代码所示,流程五是指节点从 Leader 获取到最新已提交的日志条目索引 (rs.Index) 后,它需要等待本节点当前已应用的 Raft 日志索引,大于等于 Leader 的已提交索引,确保能在本节点状态机中读取到最新数据。
if ai := s.getAppliedIndex(); ai < rs.Index {
select {
case <-s.applyWait.Wait(rs.Index):
case <-s.stopping:
return
}
}
// unblock all l-reads requested at indices before rs.Index
nr.notify(nil)
而应用已提交日志条目到状态机的过程中又涉及到随机写磁盘,详情可参考我们03中介绍过 etcd 的写请求原理。
etcd 是一个对磁盘 IO 性能非常敏感的存储系统,磁盘 IO 性能不仅会影响 Leader 稳定性、写性能表现,还会影响读性能。线性读性能会随着写性能的增加而快速下降。如果业务对性能、稳定性有较大要求,我建议你尽量使用 SSD 盘。
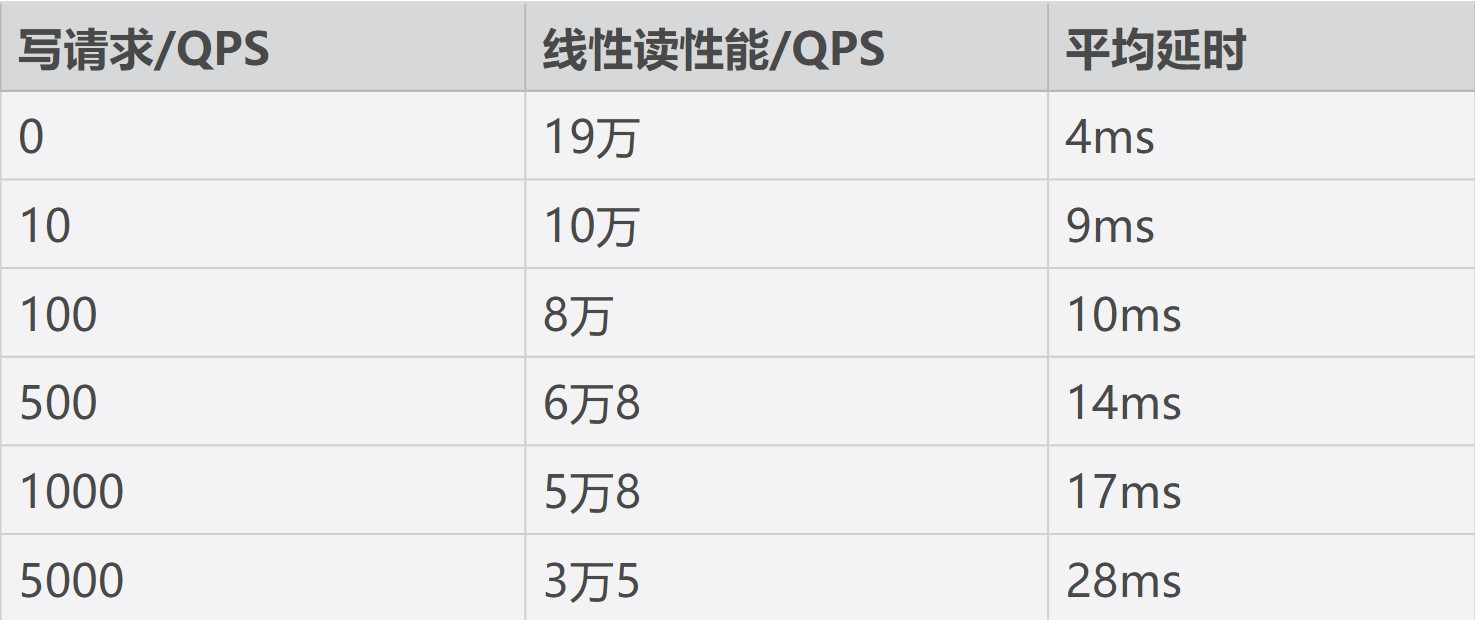
应该是指写请求量的增加?
下表我给出了一个 8 核 16G 的三节点集群,在总 key 数只有一个的情况下,随着写请求增大,线性读性能下降的趋势总结(基于 benchmark 工具压测结果),你可以直观感受下读性能是如何随着写性能下降。
当本节点已应用日志条目索引大于等于 Leader 已提交的日志条目索引后,读请求就会接到通知,就可通过 MVCC 模块获取数据。
RBAC 规则数、Auth 锁
读请求到了 MVCC 模块后,首先要通过鉴权模块判断此用户是否有权限访问请求的数据路径,也就是流程六。影响流程六的性能因素是你的 RBAC 规则数和锁。
- 首先是 RBAC 规则数,为了解决快速判断用户对指定 key 范围是否有权限,etcd 为每个用户维护了读写权限区间树。基于区间树判断用户访问的范围是否在用户的读写权限区间内,时间复杂度仅需要 O(logN)。
- 另外一个因素则是 AuthStore 的锁。在 etcd 3.4.9 之前的,校验密码接口可能会占用较长时间的锁,导致授权接口阻塞。etcd 3.4.9 之后合入了缩小锁范围的 PR,可一定程度降低授权接口被阻塞的问题。
expensive request、treeIndex 锁
流程七,从 treeIndex 中获取整个查询涉及的 key 列表版本号信息。在这个流程中,影响其性能的关键因素是 treeIndex 的总 key 数、查询的 key 数、获取 treeIndex 锁的耗时。
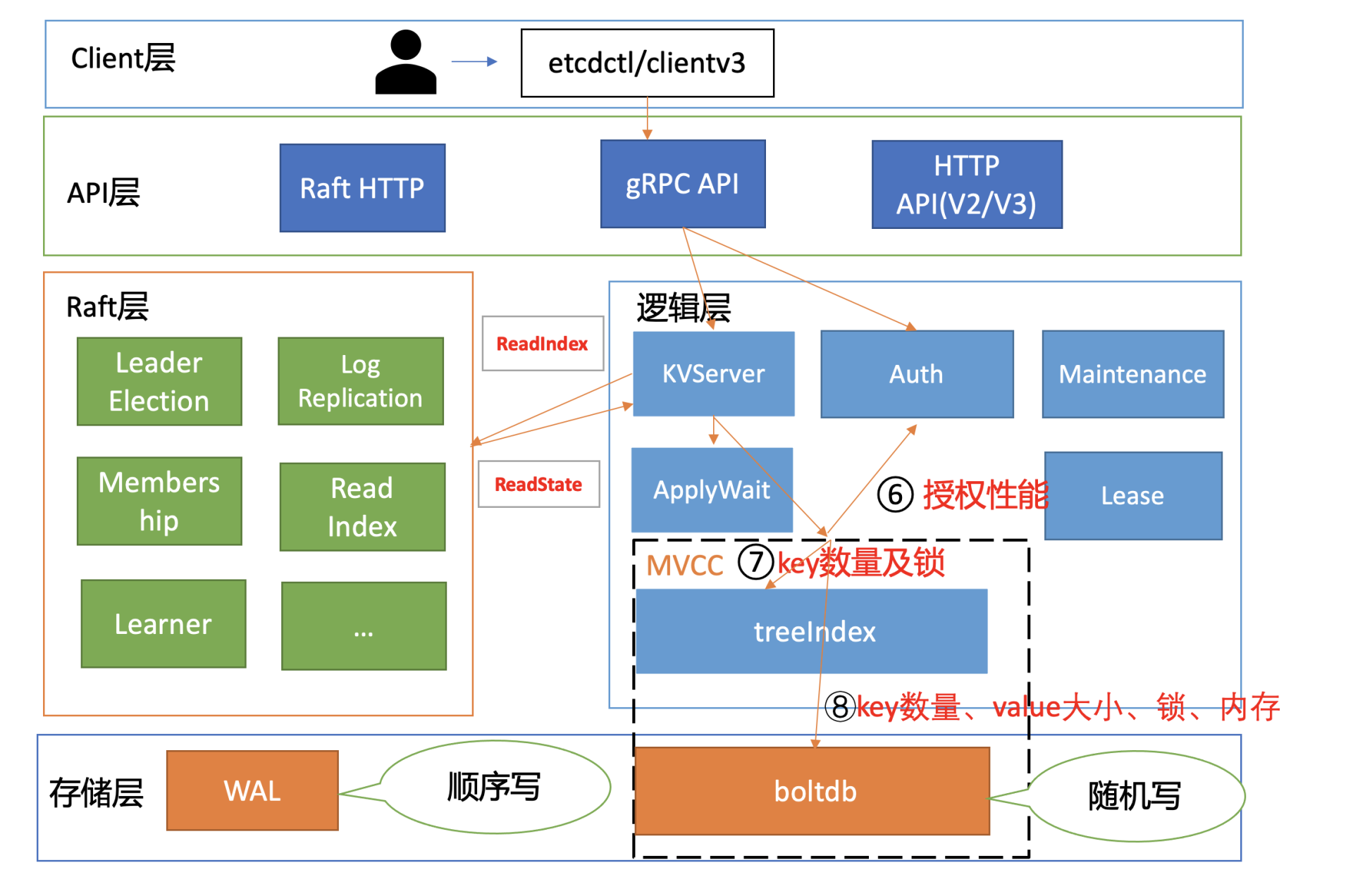
- treeIndex 中总 key 数过多会适当增大我们遍历的耗时
- 若要访问 treeIndex 我们必须获取到锁,但是可能其他请求如 compact 操作也会获取锁。早期的时候,它需要遍历所有索引,然后进行数据压缩工作。这就会导致其他请求阻塞,进而增大延时
查询 key 数较多等 expensive read request 时对性能的影响:
- 假设我们链路分析图中的请求是查询一个 Kubernetes 集群所有 Pod,当你 Pod 数一百以内的时候可能对 etcd 影响不大,但是当你 Pod 数千甚至上万的时候, 流程七、八就会遍历大量的 key,导致请求耗时突增、内存上涨、性能急剧下降。你可结合13db 大小、14延时、15内存三节一起看看,这里我就不再重复描述。
如果业务就是有这种 expensive read request 逻辑,我们该如何应对呢?
- 首先我们可以尽量减少 expensive read request 次数,在程序启动的时候,只 List 一次全量数据,然后通过 etcd Watch 机制去获取增量变更数据。比如 Kubernetes 的 Informer 机制,就是典型的优化实践。
- 其次,在设计上评估是否能进行一些数据分片、拆分等,不同场景使用不同的 etcd prefix 前缀。比如在 Kubernetes 中,不要把 Pod 全部都部署在 default 命名空间下,尽量根据业务场景按命名空间拆分部署。即便每个场景全量拉取,也只需要遍历自己命名空间下的资源,数据量上将下降一个数量级。
- 再次,如果你觉得 Watch 改造大、数据也无法分片,开发麻烦,你可以通过分页机制按批拉取,尽量减少一次性拉取数万条数据。
- 最后,如果以上方式都不起作用的话,你还可以通过引入 cache 实现缓存 expensive read request 的结果,不过应用需维护缓存数据与 etcd 的一致性。
大 key-value、boltdb 锁
大 key-value:
- etcd 设计上定位是个小型的元数据存储,它没有数据分片机制,默认 db quota 只有 2G,实践中往往不会超过 8G,并且针对每个 key-value 大小,它也进行了大小限制,默认是 1.5MB。
- 大 key-value 非常容易导致 etcd OOM、server 节点出现丢包、性能急剧下降等
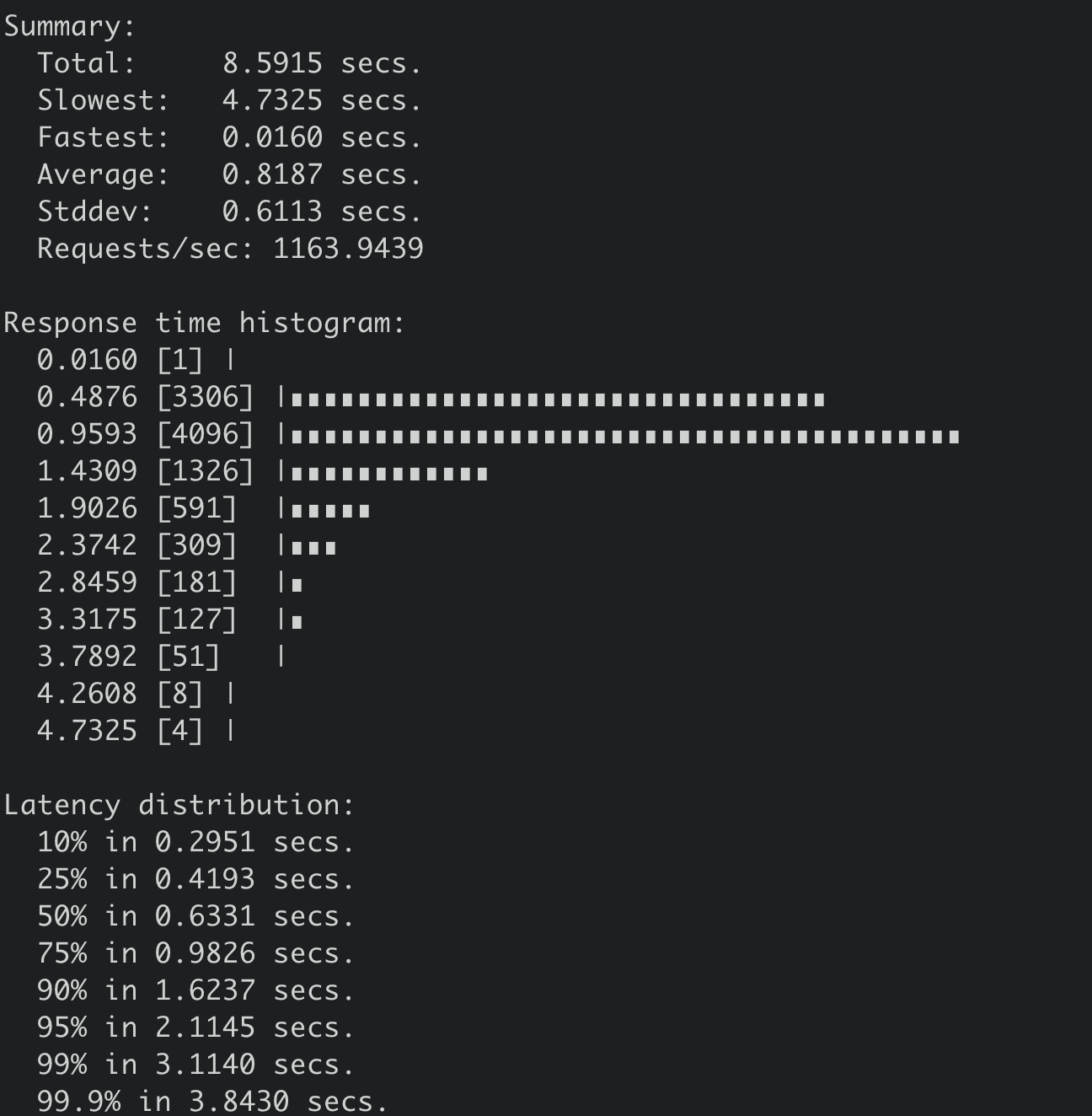
那么当我们往 etcd 集群写入一个 1MB 的 key-value 时,它的线性读性能会从 17 万 QPS 具体下降到多少呢?
我们可以执行如下 benchmark 命令:
benchmark --endpoints=addr --conns=100 --clients=1000 \
range key --consistency=l --total=10000
得到其结果如下,从下图你可以看到,读取一个 1MB 的 key-value,线性读性能 QPS 下降到 1163,平均延时上升到 818ms,可见大 key-value 对性能的巨大影响。
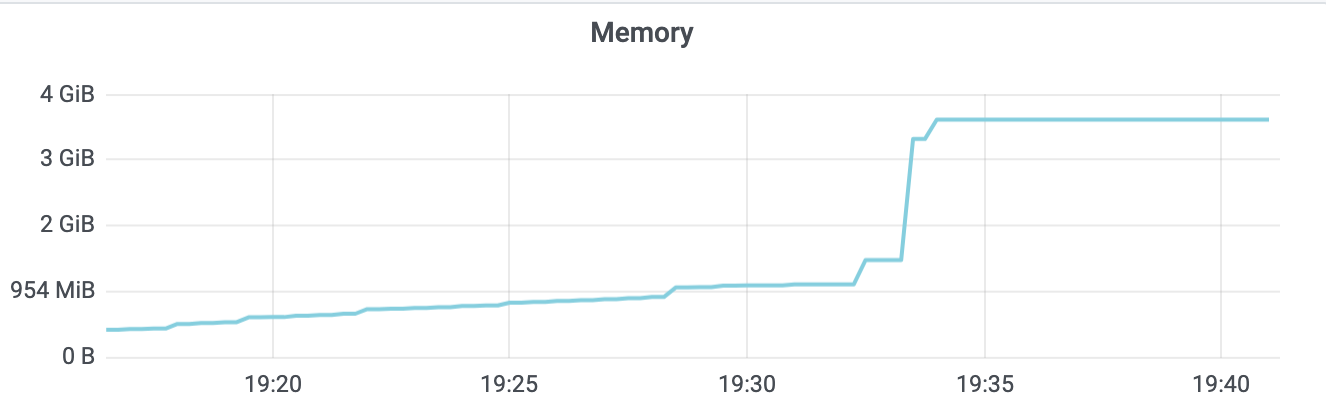
同时,从下面的 etcd 监控图上你也可以看到内存出现了突增,若存在大量大 key-value 时,可想而知,etcd 内存肯定暴涨,大概率会 OOM。
锁:
- etcd 为了提升 boltdb 读的性能,从 etcd 3.1 到 etcd 3.4 版本,分别进行过几次重大优化,在下一节中我将和你介绍。

若有收获,就点个赞吧
0 人点赞
