Storm通信机制
Worker间的通信经常需要通过网络跨节点进行,Storm使用ZeroMQ或Netty(0.9以后默认使用)作为进程间通信的消息框架。
Worker进程内部通信:不同worker的thread通信使用LMAX Disruptor来完成。
不同topologey之间的通信,Storm不负责,需要自己想办法实现,例如使用kafka等
worker进程间通信
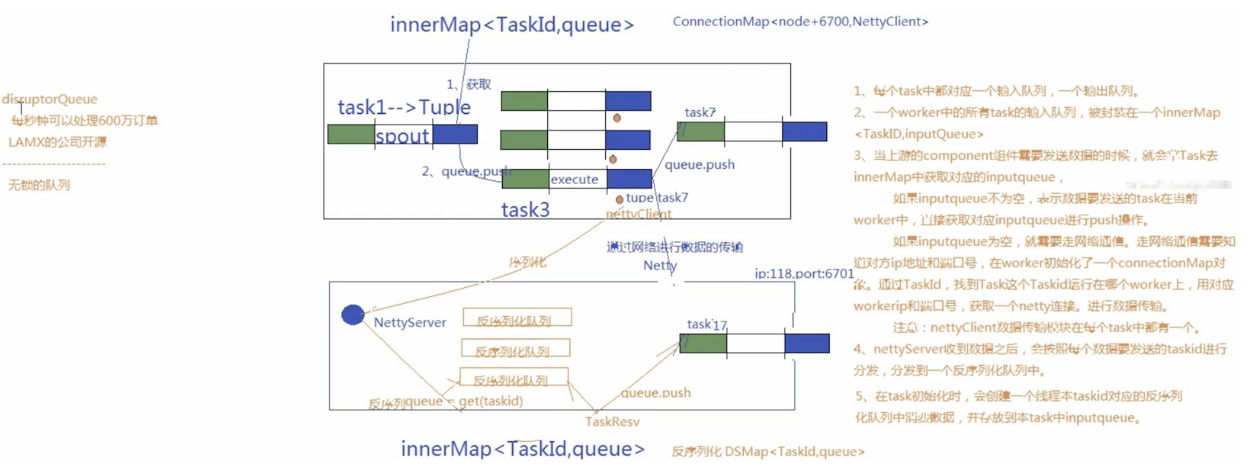
worker进程间消息传递机制,消息的接收和处理的大概流程见下图
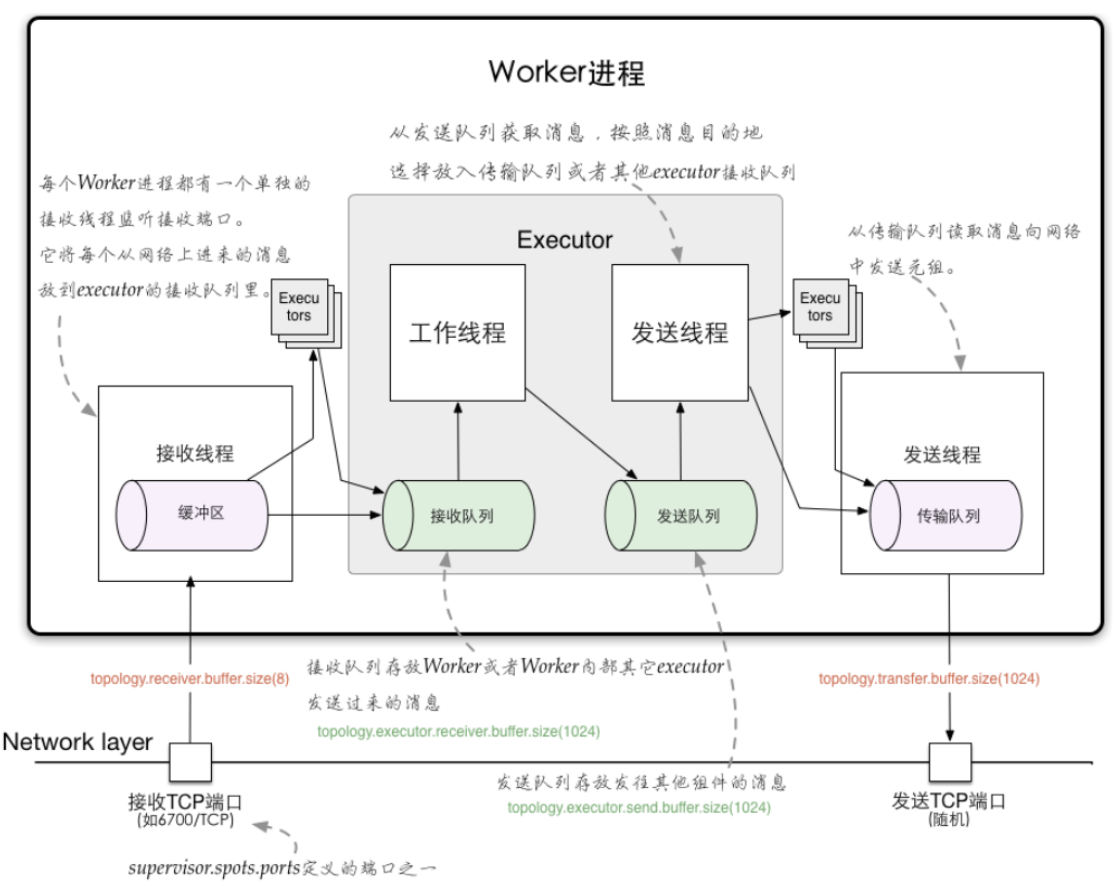
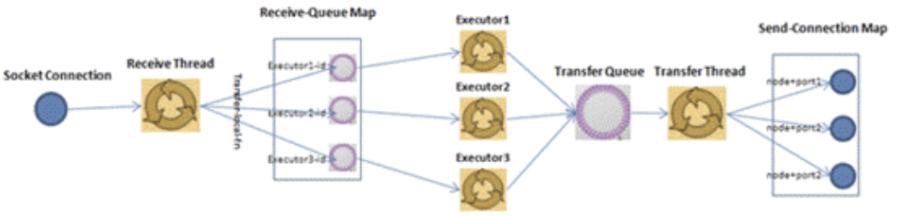
- 对于worker进程来说,为了管理流入和传出的消息,每个worker进程有一个独立的接收线程(一个worker进程运行一个专用的接收线程来负责将外部发送过来的消息移动到对应的executor线程的incoming-queue中)(对配置的TCP端口supervisor.slots.ports进行监听);
对应Worker接收线程,每个worker存在一个独立的发送线程(transfer-queue的大小由参数topology.transfer.buffer.size来设置。transfer-queue的每个元素实际上代表一个tuple的集合),它负责从worker的transfer-queue(transfer-queue的大小由参数topology.transfer.buffer.size来设置)中读取消息,并通过网络发送给其他worker - 每个executor有自己的incoming-queue(executor的incoming-queue的大小用户可以自定义配置)和outgoing-queue(executor的outgoing-queue的大小用户可以自定义配置)。
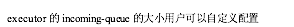 Worker接收线程将收到的消息通过task编号传递给对应的executor(一个或多个)的incoming-queues;
Worker接收线程将收到的消息通过task编号传递给对应的executor(一个或多个)的incoming-queues;
每个executor有单独的线程分别来处理spout/bolt的业务逻辑,业务逻辑输出的中间数据会存放在outgoing-queue中,当executor的outgoing-queue中的tuple达到一定的阀值,executor的发送线程将批量获取outgoing-queue中的tuple,并发送到transfer-queue中。 - 每个worker进程控制一个或多个executor线程,用户可在代码中进行配置。其实就是我们在代码中设置的并发度个数
worker进程间通信分析
- Worker接受线程通过网络接受数据,并根据Tuple中包含的taskId,匹配到对应的executor;然后根据executor找到对应的incoming-queue,将数据存发送到incoming-queue队列中。
- 业务逻辑执行现成消费incoming-queue的数据,通过调用Bolt的execute(xxxx)方法,将Tuple作为参数传输给用户自定义的方法
- 业务逻辑执行完毕之后,将计算的中间数据发送给outgoing-queue队列,当outgoing-queue中的tuple达到一定的阀值,executor的发送线程将批量获取outgoing-queue中的tuple,并发送到Worker的transfer-queue中
- Worker发送线程消费transfer-queue中数据,计算Tuple的目的地,连接不同的node+port将数据通过网络传输的方式传送给另一个的Worker。
另一个worker执行以上步骤1的操作
worker进程间技术
Netty
Netty是一个NIO client-server(客户端服务器)框架,使用Netty可以快速开发网络应用,例如服务器和客户端协议。Netty提供了一种新的方式来使开发网络应用程序,这种新的方式使得它很容易使用和有很强的扩展性。Netty的内部实现时很复杂的,但是Netty提供了简单易用的api从网络处理代码中解耦业务逻辑。Netty是完全基于NIO实现的,所以整个Netty都是异步的。
书籍:Netty权威指南
ZeroMQ
ZeroMQ是一种基于消息队列的多线程网络库,其对套接字类型、连接处理、帧、甚至路由的底层细节进行抽象,提供跨越多种传输协议的套接字。ZeroMQ是网络通信中新的一层,介于应用层和传输层之间(按照TCP/IP划分),其是一个可伸缩层,可并行运行,分散在分布式系统间。
ZeroMQ定位为:一个简单好用的传输层,像框架一样的一个socket library,他使得Socket编程更加简单、简洁和性能更高。是一个消息处理队列库,可在多个线程、内核和主机盒之间弹性伸缩。ZMQ的明确目标是“成为标准网络协议栈的一部分,之后进入Linux内核”。
worker内部通信技术(Disruptor)
Disruptor是什么
- 简单理解:Disruptor是一个Queue。Disruptor是实现了“队列”的功能,而且是一个有界队列。而队列的应用场景自然就是“生产者-消费者”模型。
- 在JDK中Queue有很多实现类,包括不限于ArrayBlockingQueue、LinkBlockingQueue,这两个底层的数据结构分别是数组和链表。数组查询快,链表增删快,能够适应大多数应用场景。
- 但是ArrayBlockingQueue、LinkBlockingQueue都是线程安全的。涉及到线程安全,就会有synchronized、lock等关键字,这就意味着CPU会打架。
- Disruptor一种线程之间信息无锁的交换方式(使用CAS(Compare And Swap/Set)操作)
Disruptor主要特点
- 没有竞争=没有锁=非常快。
- 所有访问者都记录自己的序号的实现方式,允许多个生产者与多个消费者共享相同的数据结构。
- 在每个对象中都能跟踪序列号(ring buffer,claim Strategy,生产者和消费者),加上神奇的cache line padding,就意味着没有为伪共享和非预期的竞争
Disruptor核心技术点
Disruptor可以看成一个事件监听或消息机制,在队列中一边生产者放入消息,另外一边消费者并行取出处理.
底层是单个数据结构:一个ring buffer。
每个生产者和消费者都有一个次序计算器,以显示当前缓冲工作方式。
每个生产者消费者能够操作自己的次序计数器的能够读取对方的计数器,生产者能够读取消费者的计算器确保其在没有锁的情况下是可写的。
核心组件
- Ring Buffer 环形的缓冲区,负责对通过 Disruptor 进行交换的数据(事件)进行存储和更新。
- Sequence 通过顺序递增的序号来编号管理通过其进行交换的数据(事件),对数据(事件)的处理过程总是沿着序号逐个递增处理。
- RingBuffer底层是个数组,次序计算器是一个64bit long 整数型,平滑增长

- 接受数据并写入到脚标31的位置,之后会沿着序号一直写入,但是不会绕过消费者所在的脚标。
- Joumaler和replicator同时读到24的位置,他们可以批量读取数据到30
- 消费逻辑线程读到了14的位置,但是没法继续读下去,因为他的sequence暂停在15的位置上,需要等到他的sequence给他序号。如果sequence能正常工作,就能读取到30的数据

若有收获,就点个赞吧
0 人点赞
