数据样本
i am jdxiai am xjdi am jdxiai am jelly
jar包
<dependency><groupId>org.apache.storm</groupId><artifactId>storm-core</artifactId><!--<scope>provided</scope>--><version>0.9.5</version></dependency>
安装log4j
数据获取
BaseRichSpout类是ISpout接口和IComponent接口的一个简便的实现
open方法中接收三个参数
- conf包含了storm配置信息的map.
- TopologyContext对象提供了topology中组件的信息
- SpoutOutputCollector对象提供了发射tuple的方法
package com.learnstorm;import backtype.storm.spout.SpoutOutputCollector;import backtype.storm.task.TopologyContext;import backtype.storm.topology.OutputFieldsDeclarer;import backtype.storm.topology.base.BaseRichSpout;import backtype.storm.tuple.Fields;import org.apache.commons.lang.StringUtils;import java.io.*;import java.util.ArrayList;import java.util.List;import java.util.Map;//数据获取public class MyLocalFileSpout extends BaseRichSpout {//控制数据输出private SpoutOutputCollector collector;//读取数据的private BufferedReader bufferedReader;//初始化方法@Overridepublic void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {this.collector = collector;try {//定义这个去读取数据this.bufferedReader = new BufferedReader(new FileReader(new File("/Users/jdxia/Desktop/MyFile/i.txt")));} catch (FileNotFoundException e) {e.printStackTrace();}}//storm流式计算的特征就是数据一条一条的处理// while(true) {// this.nextTuple();// }//这个方法会被循环调用@Overridepublic void nextTuple() {//每被调用一次就会发送一条数据出去try {//读取一行String line = bufferedReader.readLine();//如果不是空的话if (StringUtils.isNotBlank(line)) {List<Object> arrayList = new ArrayList<Object>();//把数据放到ArrayList中arrayList.add(line);//把数据发出去collector.emit(arrayList);}} catch (IOException e) {e.printStackTrace();}}//定义下我的输出@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {declarer.declare(new Fields("juzi"));}}
数据截取
BaseBasicBolt是IComponent和IBolt接口的一个简便实现
BaseBasicBolt中还有个prepare()方法,是bolt初始化的时候调用的
package com.learnstorm;import backtype.storm.topology.BasicOutputCollector;import backtype.storm.topology.OutputFieldsDeclarer;import backtype.storm.topology.base.BaseBasicBolt;import backtype.storm.tuple.Fields;import backtype.storm.tuple.Tuple;import backtype.storm.tuple.Values;//相当于map-->world,1//业务逻辑//对句子进行切割public class MySplitBolt extends BaseBasicBolt {//处理函数@Overridepublic void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {//1.数据如何获取,用tuple获取,tuple是List数据结构,消息传输的基本单元//强转为string,juzi是上一步定义的String juzi = (String) tuple.getValueByField("juzi");//2.进行切割String[] strings = juzi.split(" ");//3.发送数据for (String word : strings) {//我们之前用ArrayList存储,这边怎么变为Values//可以看下Values的源码,他是继承了ArrayList,他存的时候用了一个循环//values对象帮我们生成个listbasicOutputCollector.emit(new Values(word, 1));}}//定义下我的输出//单词world和他的次数@Overridepublic void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {outputFieldsDeclarer.declare(new Fields("word", "num"));}}
单词统计
这里面用到了HashMap.这是可序列化的
如果spout或者bolt在序列化之前,(比如在构造函数中生成)实例化了任何无法序列化的实例变量,在进行序列化的时候会抛出NotSerialiableException
当topology发布时,所有的bolt和spout组件首先进行序列化,然后发布到网络中.
通常情况下最好在构造函数中对基本数据类型和可序列化的对象进行赋值和实例化,在prepare()方法中对不可序列化的对象进行实例化
bolt中可以加入cleanup()方法,这个方法在IBolt中定义.storm在终止一个Bolt之前会调用这个方法.通常情况下cleanup会用来释放bolt占用的资源
当在集群中运行的时候,cleanup是不可靠的,不能保证会执行
package com.learnstorm;import backtype.storm.topology.BasicOutputCollector;import backtype.storm.topology.OutputFieldsDeclarer;import backtype.storm.topology.base.BaseBasicBolt;import backtype.storm.tuple.Tuple;import java.util.HashMap;import java.util.Map;//打印public class MyWordCountAndPrintBolt extends BaseBasicBolt {private Map<String, Integer> wordCountMap = new HashMap<String, Integer>();//处理函数@Overridepublic void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {//根据之前定义的word和num//强转为stringString word = (String) tuple.getValueByField("word");Integer num = (Integer) tuple.getValueByField("num");//1.查看单词对应的value是否存在Integer integer = wordCountMap.get(word);if (integer == null || integer.intValue() == 0) {//如果不存在就直接放入新的wordCountMap.put(word, num);} else {//如果之前已经有了,就把对应统计加上wordCountMap.put(word, integer.intValue() + num);}System.out.println(wordCountMap);}//不需要定义输出字段了@Overridepublic void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {}//终止bolt会调用这个方法@Overridepublic void cleanup() {}}
任务描述
这边写的是本地提交到集群
package com.learnstorm;import backtype.storm.Config;import backtype.storm.LocalCluster;import backtype.storm.StormSubmitter;import backtype.storm.generated.AlreadyAliveException;import backtype.storm.generated.InvalidTopologyException;import backtype.storm.generated.StormTopology;import backtype.storm.topology.TopologyBuilder;public class StormTopologyDriver {public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException {//1. 描述任务TopologyBuilder topologyBuilder = new TopologyBuilder();//任务的名字自己定义topologyBuilder.setSpout("mySpout", new MyLocalFileSpout());//shuffleGrouping和前一个任务关联.shuffleGrouping可以连接多个任务topologyBuilder.setBolt("bolt1", new MySplitBolt()).shuffleGrouping("mySpout");topologyBuilder.setBolt("bolt2", new MyWordCountAndPrintBolt()).shuffleGrouping("bolt1");//2. 任务提交//提交给谁?提交什么内容?Config config = new Config(); //Config类实际上是继承HashMap//设置在几个work上运行,也就是在几个jvm中运行,如果不指定,默认是在一个work中// config.setNumWorkers(2);StormTopology stormTopology = topologyBuilder.createTopology();//本地模式LocalCluster localCluster = new LocalCluster();localCluster.submitTopology("wordCount", config, stormTopology);//这种是集群模式// StormSubmitter.submitTopology("worldCount1", config, stormTopology);}}
提交到集群
如果是提交到集群上面,那么storm的storm-core的作用域就要改下
<scope>provided</scope>
表示集群上提供了这个jar包,
然后maven对项目打包,上传到服务器上,执行
storm jar 上传的jar包 主类名称
然后我们在ui界面上看
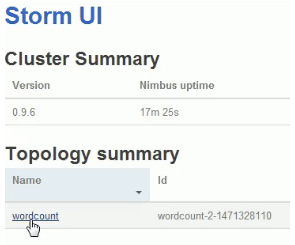
点进去看
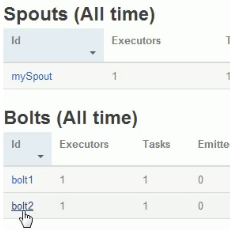
统计信息打印在bolt2上
查看下bolt2在那台机器上
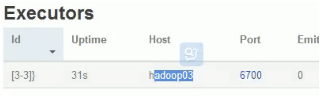
hadoop03的6700端口上
到这台机器上的storm的logs目录
目录下有个worker-6700.log查看下这个日志

若有收获,就点个赞吧
0 人点赞
