传统数据处理架构
事务处理
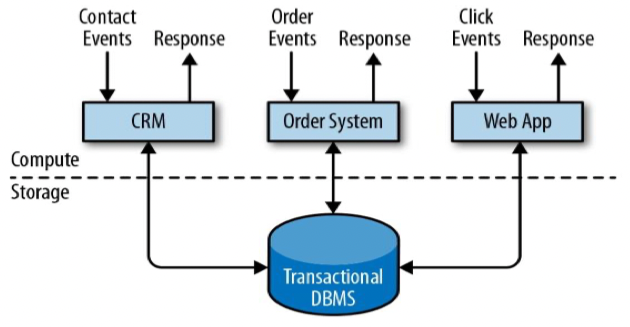
分析处理
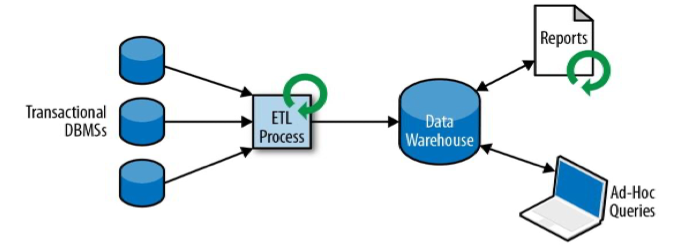
有状态的流式处理
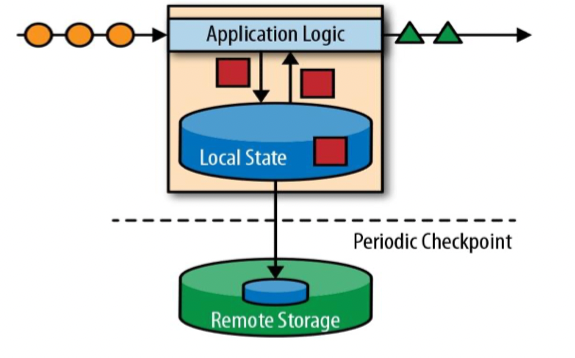
流处理的演变
lambda架构

流处理的演变
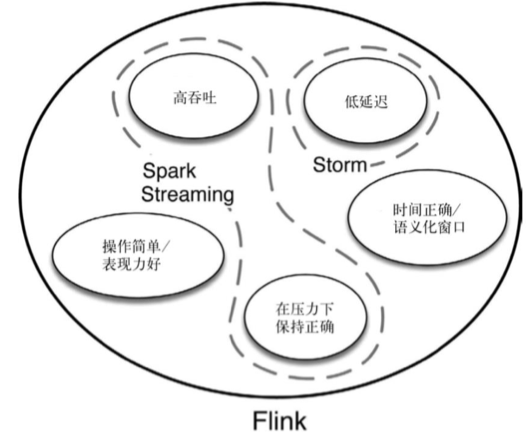
流处理与批处理
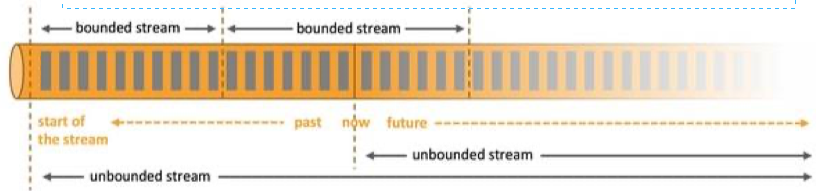
Flink 专注于无限流处理,有限流处理是无限流处理的一种特殊情况
无限流处理:
- 输入的数据没有尽头,像水流一样源源不断
- 数据处理从当前或者过去的某一个时间 点开始,持续不停地进行
有限流处理:
- 从某一个时间点开始处理数据,然后在另一个时间点结束
输入数据可能本身是有限的(即输入数据集并不会随着时间增长),也可能出于分析的目的被人为地设定为有限集(即只分析某一个时间段内的事件)Flink封装了DataStream API进行流处理,封装了DataSet API进行批处理。同时,Flink也是一个批流一体的处理引擎,提供了Table API / SQL统一了批处理和流处理
flink的主要特点
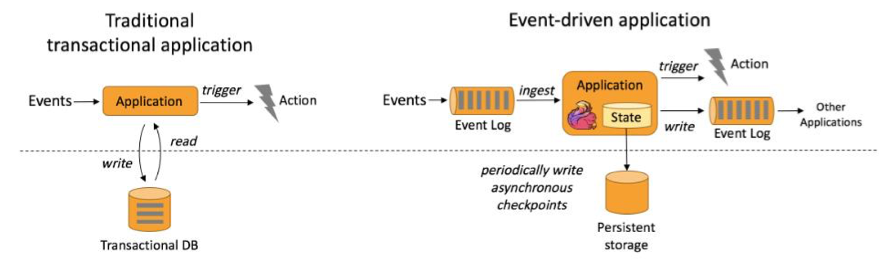
事件驱动(Event-driven)
基于流的世界观
在 Flink 的世界观中,一切都是由流组成的
离线数据是有界的流
- 实时数据是一个没有界限的流
其他特点
- 支持事件时间(event-time)和处理时间(processing-time)语义
- 精确一次(exactly-once)的状态一致性保证
- 低延迟,每秒处理数百万个事件,毫秒级延迟
- 与众多常用存储系统的连接
-
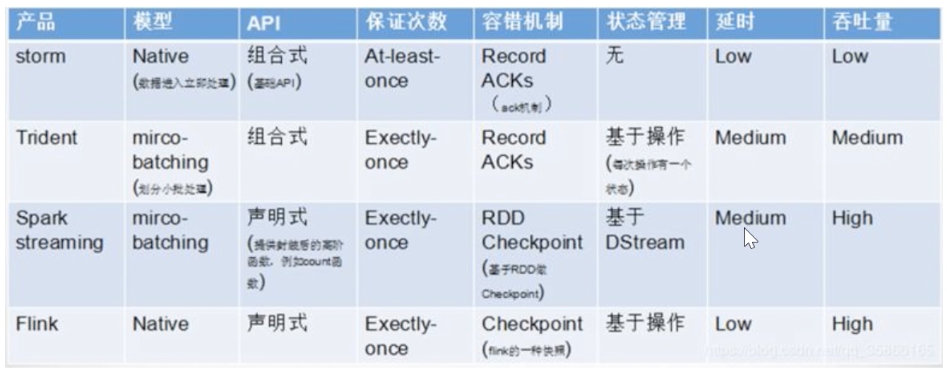
Flink vs Spark Streaming
流(stream)和微批(micro-batching)

数据模型 spark 采用 RDD 模型,spark streaming 的 DStream 实际上也就是一组 组小批数据 RDD 的集合
- flink 基本数据模型是数据流,以及事件(Event)序列
运行时架构
- spark 是批计算,将 DAG 划分为不同的 stage,一个完成后才可以计算下一个
flink 是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理
和其他产品对比
Flink核心组成
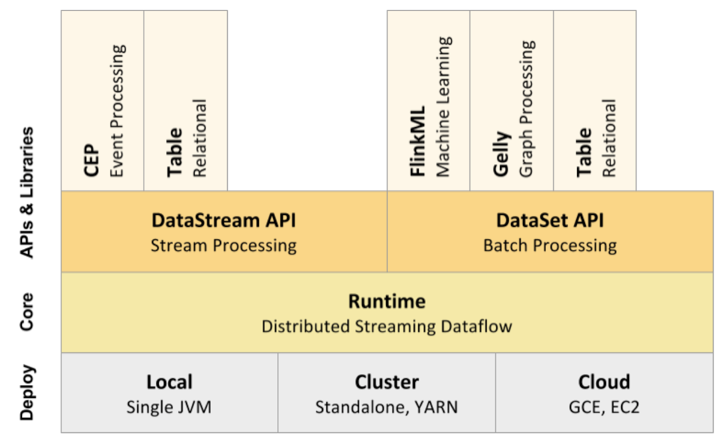
Deploy层:
- 可以启动单个JVM,让Flink以Local模式运行
- Flink也可以以Standalone 集群模式运行,同时也支持Flink ON YARN,Flink应用直接提交到YARN上面运行
- Flink还可以运行在GCE(谷歌云服务)和EC2(亚马逊云服务)
- Core层(Runtime):在Runtime之上提供了两套核心的API,DataStream API(流处理)和DataSet API(批处理)
- APIs & Libraries层:核心API之上又扩展了一些高阶的库和API
- CEP流处理
- Table API和SQL
- Flink ML机器学习库
- Gelly图计算

若有收获,就点个赞吧
0 人点赞
