Flink支持多种安装模式
- local(本地):单机模式,一般本地开发调试使用
- StandAlone 独立模式:Flink自带集群,自己管理资源调度,生产环境也会有所应用
- Yarn模式:计算资源统一由Hadoop YARN管理,生产环境应用较多
StandAlone
flink中缺少hadoop的依赖jar包,下载相关jar(flink-shaded-hadoop-2-uber-2.8.3-10.0.jar),导入lib包下即可
https://flink.apache.org/zh/downloads.html
进入 conf 目录中root@box1:/opt/flink-1.14.4/lib # lsflink-csv-1.14.4.jar flink-table_2.12-1.14.4.jarflink-dist_2.12-1.14.4.jar log4j-1.2-api-2.17.1.jarflink-json-1.14.4.jar log4j-api-2.17.1.jarflink-shaded-hadoop-2-uber-2.8.3-10.0.jar log4j-core-2.17.1.jarflink-shaded-zookeeper-3.4.14.jar log4j-slf4j-impl-2.17.1.jar
- 修改
flink/conf/flink-conf.yaml文件 :
里面还有一些重要的参数配置jobmanager.rpc.address: box1
其中的关系如下:假设集群中有一台master,k台slave节点。
Flink-conf.yaml中有两个重要的参数:
- taskmanager.numberOfTaskSlots,The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
- parallelism.default,The parallelism used for programs that did not specify and other parallelism.
前者指定了每个taskmanager提供的slot个数,后者的指定的程序默认的并行度。两者之间的关系为:
否则程序运行时候将不会得到足够多的slot而报错。
总之就是,slot提供资源,越多越好,并行度不能超过slot总上限。
Flink中每一个worker(TaskManager)都是一个JVM进程,它可能会在独立的线程上执行一个Task。为了控制一个worker能接收多少个task(这里的task可以理解为上文里面经过合并后subtask的数量),worker通过Task Slot来进行控制(一个worker至少有一个Task Slot)。
每个task slot表示TaskManager拥有资源的一个固定大小的子集。假如一个TaskManager有三个slot,那么它会将其管理的内存分成三份给各个slot。资源slot化意味着一个task将不需要跟来自其他job的task竞争被管理的内存,取而代之的是它将拥有一定数量的内存储备。需要注意的是,这里不会涉及到CPU的隔离,slot目前仅仅用来隔离task的受管理的内存。
Flink中slot数量代表了所有最高能支持的subtask数量。也就是整个任务的最高并发度,但是并不代表一个线程的概念(可见上图),内部也是可以启动很多线程的。
每一个任务的并行能力是多少就是靠着slot的数量来看的
- 默认taskmanager.numberOfTaskSlots=1, numberOfTaskSlots指的是每个TM上有多少slots。也即是TM所拥有的最大并行能力,默认为1,可以手动配置更改。
- parallelism.default 为默认并行度,默认为1,指的是job提交时默认的并行度是多少,简单理解就是一个是动态的能力 ,而taskmanager.numberOfTaskSlots参数则是提交job执行时静态的能力 ,就像我有10成功力(taskmanager.numberOfTaskSlots),用3成功力(parallelism.default )就可以使出铁砂掌kill掉一个对手,那我非要用10成功力干嘛呢,但是如果对面是3个对手,这时不免要使用全部的10成功力来出招。
- 修改
flink/conf/slaves文件 ```sql root@box1:/opt/flink-1.14.4/conf # cat masters box1:8081
root@box1:/opt/flink-1.14.4/conf # cat ./slaves box2 box3
3. 分发给另外两台机子```sqlscp -r ./flink-1.14.4 box2:/opt/scp -r ./flink-1.14.4 box3:/opt/
- 启动 :
访问 http://localhost:8081可以对 flink 集群和任务进行监控管理root@box1:/opt/flink-1.14.4 # ./bin/start-cluster.shStarting cluster.Starting standalonesession daemon on host box1.Starting taskexecutor daemon on host box1.
web上部署
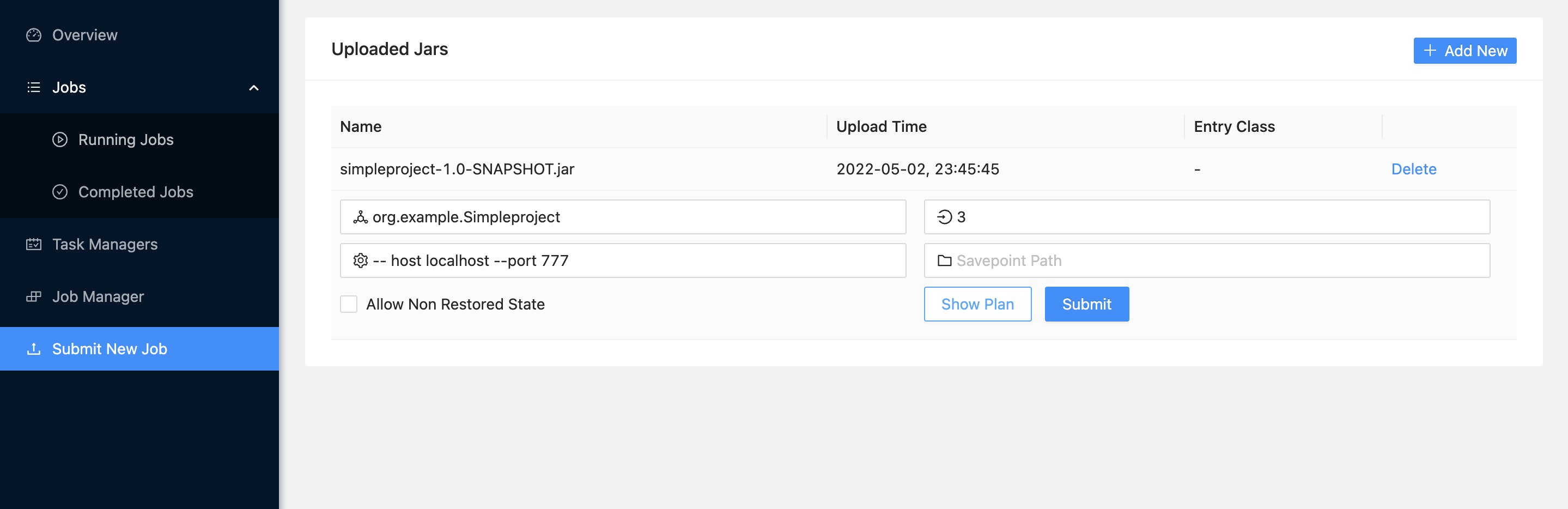
命令行部署
./flink run -c com.study.wc.StreamWordCount –p 2FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host lcoalhost –port 7777
取消
# 查看flink list -aflink list# 取消flink cancel 任务id

查看计算结果
注意:如果输出到控制台,应该在 taskmanager 下查看;如果 计算结果 输出到文 件, 同样 会保存到 taskmanage 的机器下, 不会在 jobmanage 下
yarn部署
以 Yarn 模式部署 Flink 任务时, 要求 Flink 是有 Hadoop 支持的版本, Hadoop 环境需要保证版本在 2.2 以上, 并且集群中安装有 HDFS 服务. flink的lib目录下有hadoop的包
Flink 提供了两种在 yarn 上运行的模式,分别为 Session-Cluster 和 Per-Job-Cluster模式
Session-cluster 模式

Session-Cluster 模式需要先启动集群, 然后再提交作业, 接着会向 yarn 申请一块空间后, 资源永远保持不变。 如果资源满了, 下一个作业就无法提交, 只能等到 yarn 中的其中一个作 业执行完成后, 释放了资源, 下个作业才会正常提交。 所有作 业共享 Dispatcher 和 ResourceManager ;
共享资源;适合规模小执行时间短的作业
在 yarn 中初始化一个 flink 集群, 开辟指定的资源, 以后提交任务都向这里提 交。 这个 flink 集群会常驻在 yarn 集群中, 除非手工停止。
Per-Job-Cluster 模式

一个 Job 会对应一个集群,每提交一个作业会根据自身的情况,都会单独向 yarn 申请资源, 直到作业执行完成, 一个作业的失败与否并不会影响下一个作业的正常 提交和运行。独享 Dispatcher 和 ResourceManager ,按需接受资源申请;适合规模大 长时间运行的作业
每次提交都会创建一个新的 flink 集群,任务之间互相独立,互不影响,方便管 理。 任务执行完成之后创建的集群也会消失

若有收获,就点个赞吧
0 人点赞
