1. Redis管理命令
//查看当前的全局状态信息127.0.0.1:6379> info//查看当前的内存状态信息127.0.0.1:6379> info memory//查看当前的会话状态信息127.0.0.1:6379> CLIENT LIST//杀掉会话,指定需要杀的会话地址和端口127.0.0.1:6379> CLIENT KILL 127.0.0.1:47896//查看所有配置信息127.0.0.1:6379> CONFIG GET *//查看当前的key数量127.0.0.1:6379> DBSIZE//清空0-15的库中的所有数据,包括持久化127.0.0.1:6379> FLUSHALL//进入redis的库,默认有16个库,index从0-15127.0.0.1:6379> SELECT 1//清空当前库的数据127.0.0.1:6379> FLUSHDB//监控实时操作的指令127.0.0.1:6379> MONITOR//关闭当前redis服务127.0.0.1:6379> SHUTDOWN//将当前数据保存127.0.0.1:6379> save
2. Redis数据类型
2.1. Redis数据类型简介
key键:自定义名称
value值:多种数据类型的存储模式
数据类型如下表:
| 数据类型 | 描述 | 实例 |
|---|---|---|
| String | 最基本的类型,可以存储任何形式的字符串 | name “zhangsan” |
| Hash | 字典类型,最接近表结构的类型 | stu {id:101,name:zhangsan} |
| List | 列表类型,简单的字符串列表,按照插入顺序排序 | wechat (v1,v2,v3),下标索引:0 1 2 |
| Set | 集合类型,集合是通过哈希表实现的 | set [m1,m2,m3],下标索引:0 1 2 |
| Sorted set | 有序类型 | zset1 [socre m1,score m2,score m3] |
2.2. Redis数据类型应用场景
- String(基础类型)
- 应用场景:非常基本的键值对存储
- 计数器
- 互联网:点击量,访问量,关注量等
- 网页游戏应用:血量,蓝量等
- HASH类型(字典类型)
- 应用场景:最接近于MySQL表结构的数据类型
- 存储部分变更的数据,如用户信息等。
- List(列表类型)
- 应用场景:朋友圈,新浪等应用
- 在Redis中我们的最新微博ID使用了常驻缓存,这是一直更新的。
但是做了限制不能超过5000个ID,因此获取ID的函数会一直询问Redis。
只有在start/count参数超出了这个范围的时候,才需要去访问数据库。
系统不会像传统方式那样“刷新”缓存,Redis实例中的信息永远是一致的。
SQL数据库(或是硬盘上的其他类型数据库)只是在用户需要获取“很远”的数据时才会.被触. 发,而主页或第一个评论页是不会麻烦到硬盘上的数据库了。
- Set(集合类型)
- 应用场景:在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。
- Redis还为集合提供了求交集、并集、差集等操作,可以非常方便的实现如共同关注、共同喜好、二度好友等功能,对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。
- Sorted set(有序集合)
- 应用场景:排行榜应用
- 这个需求与上面需求的不同之处在于,前面操作以时间为权重,这个是以某个条件为权重,比如按顶的次数排序,这时候就需要我们的sorted set出马了,将你要排序的值设置成sorted set的score,将具体的数据设置成相应的value,每次只需要执行一条ZADD命令即可。
3. Redis数据类型操作
3.1. 字符串
计数学应用(以粉丝量举例子)
//在前端网页中点击一次关注,在redis后端就会执行一次incr,
127.0.0.1:6379> incr fensi #这里的fensi只是key值的命名
(integer) 1
127.0.0.1:6379> incr fensi
(integer) 2
127.0.0.1:6379> get fensi
"2"
//在前端网页中取消关注,在redis后端就会执行一次decr,
127.0.0.1:6379> decr fensi
(integer) 1
127.0.0.1:6379> decr fensi
(integer) 0
//甚至可以直接在Redis中指定增量粉丝的数量
127.0.0.1:6379> incrby fensi 10000
(integer) 10000
127.0.0.1:6379> get fensi
"10000"
//指定粉丝数量进行范围删除
127.0.0.1:6379> decrby fensi 10000
(integer) 0
参数解释:
incr #每执行一次计数就自增+1
decr #每执行一次计数就自减-1
incrby #指定增加计数的范围
decrb y#指定减少计数的范围
3.2. 哈希
//定义单个值
127.0.0.1:6379> hset zs name zhangsan
(integer) 1
//一个key值中定义多个列,id、name、age、gender
127.0.0.1:6379> hmset student id 101 name zhangsan age 20 gender male
OK
//获取key值中的多个列
127.0.0.1:6379> hmget student id name age gender
1) "101"
2) "zhangsan"
3) "20"
4) "male"
参数解析:
heset #定义一个键值中的单个值
hmset #定义一个键值中的多个列(多个值)
hmget #获取一个键值中的多个值
小扩展:
MySQL中city表中前10行数据,灌入到redis中
mysql> select * from t1;
+----+----------+-----+--------+
| id | name | age | gender |
+----+----------+-----+--------+
| 1 | zhangsan | 20 | male |
| 2 | lisi | 19 | male |
| 3 | wangwu | 19 | male |
+----+----------+-----+--------+
mysql> select concat("hmaset stu_",name," id ",id," name ",name," age ",age," gender ",gender) from t1;
+----------------------------------------------------------------------------------+
| concat("hmaset stu_",name," id ",id," name ",name," age ",age," gender ",gender) |
+----------------------------------------------------------------------------------+
| hmaset stu_zhangsan id 1 name zhangsan age 20 gender male |
| hmaset stu_lisi id 2 name lisi age 19 gender male |
| hmaset stu_wangwu id 3 name wangwu age 19 gender male |
+----------------------------------------------------------------------------------+
3 rows in set (0.00 sec)
3.3. 列表
例子:朋友圈应用
//定义五个key值,每天发一次朋友圈,一共发五天
127.0.0.1:6379> lpush wechat "today is 1"
(integer) 1
127.0.0.1:6379> lpush wechat "today is 2"
(integer) 2
127.0.0.1:6379> lpush wechat "today is 3"
(integer) 3
127.0.0.1:6379> lpush wechat "today is 4"
(integer) 4
127.0.0.1:6379> lpush wechat "today is 5"
(integer) 5
//显示所有最新的到历史的朋友圈数据从上往下排序
127.0.0.1:6379> lrange wechat 0 -1
1) "today is 5"
2) "today is 4"
3) "today is 3"
4) "today is 2"
5) "today is 1"
参数解释:
lpush #定义key值
lrange #获取key值
3.4. 集合
//定义lxl和jnl的各自好友
127.0.0.1:6379> sadd lxl pg1 pg2 baoqiang masu marong
(integer) 5
127.0.0.1:6379> sadd jnl baoqiang baobeier huosiyan matianyu
(integer) 3
//获取lxl和jnl的好友列表
127.0.0.1:6379> sunion lxl jnl
1) "baoqiang"
2) "pg1"
3) "marong"
4) "masu"
5) "baobeier"
6) "huosiyan"
7) "matianyu"
8) "pg2"
//获取lxl和jnl拥有的共同好友
127.0.0.1:6379> sinter lxl jnl
1) "baoqiang"
//获取lxl跟jnl差异的好友
127.0.0.1:6379> sdiff lxl jnl
1) "pg2"
2) "marong"
3) "pg1"
4) "masu"
//获取jnl跟lxl差异的好友
127.0.0.1:6379> sdiff jnl lxl
1) "baobeier"
2) "huosiyan"
3) "matianyu"
参数解释:
sunion #取并集
sinter #取交集
sdiff #取差集
3.5. 有序集合
例子:歌曲排行榜
//定义五首歌曲
127.0.0.1:6379> zadd music 0 cbg 0 yy 0 tf 0 qs 0 yb
(integer) 5
//给对应的歌曲设置播放量,
127.0.0.1:6379> zincrby music 1000 cbg
"1000"
127.0.0.1:6379> zincrby music 10000 yy
"10000"
127.0.0.1:6379> zincrby music 100000 ft
"10000"
127.0.0.1:6379> zincrby music 1000000 qs
"10000"
127.0.0.1:6379> zincrby music 10 yy
"10000"
//给歌曲的播放量进行降序排列
127.0.0.1:6379> zrevrange music 0 -1 withscores
1) "qs"
2) "1000000"
3) "ft"
4) "100000"
5) "yy"
6) "10010"
7) "cbg"
8) "1000"
9) "yb"
10) "0"
11) "tf"
12) "0"
参数解释:
zadd #定义key值
zincrby #为key值的内容指定数值
zrevrange #获取key值排序显示
4. Redis发布订阅
Redis发布消息通常有两种模式:
- 队列模式
- 发布-订阅模式
消息队列的好处:
- 松耦合
- 易于扩展
生产消费模型: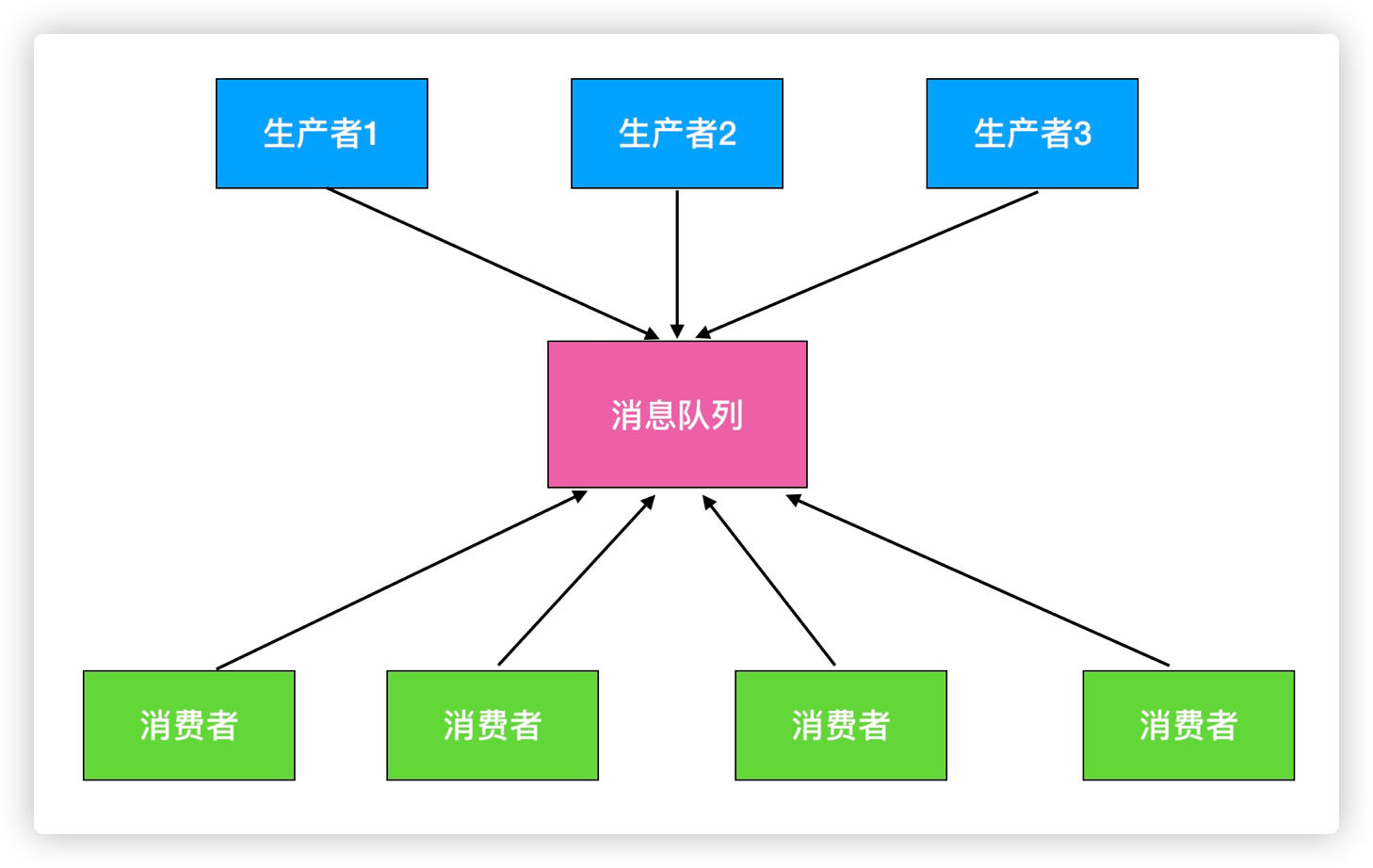
其实从Pub/Sub的机制来看,它更像是一个广播系统,多个Subscriber可以订阅多个Channel,多个Publisher可以往多个Channel中发布消息,可以简单的理解:
- Subscriber:收音机,可以收到多个频道,并以队列方式显示
- Publisher:电台,可以往不同的FM频道中发消息
- Channel:不同频率的FM频道
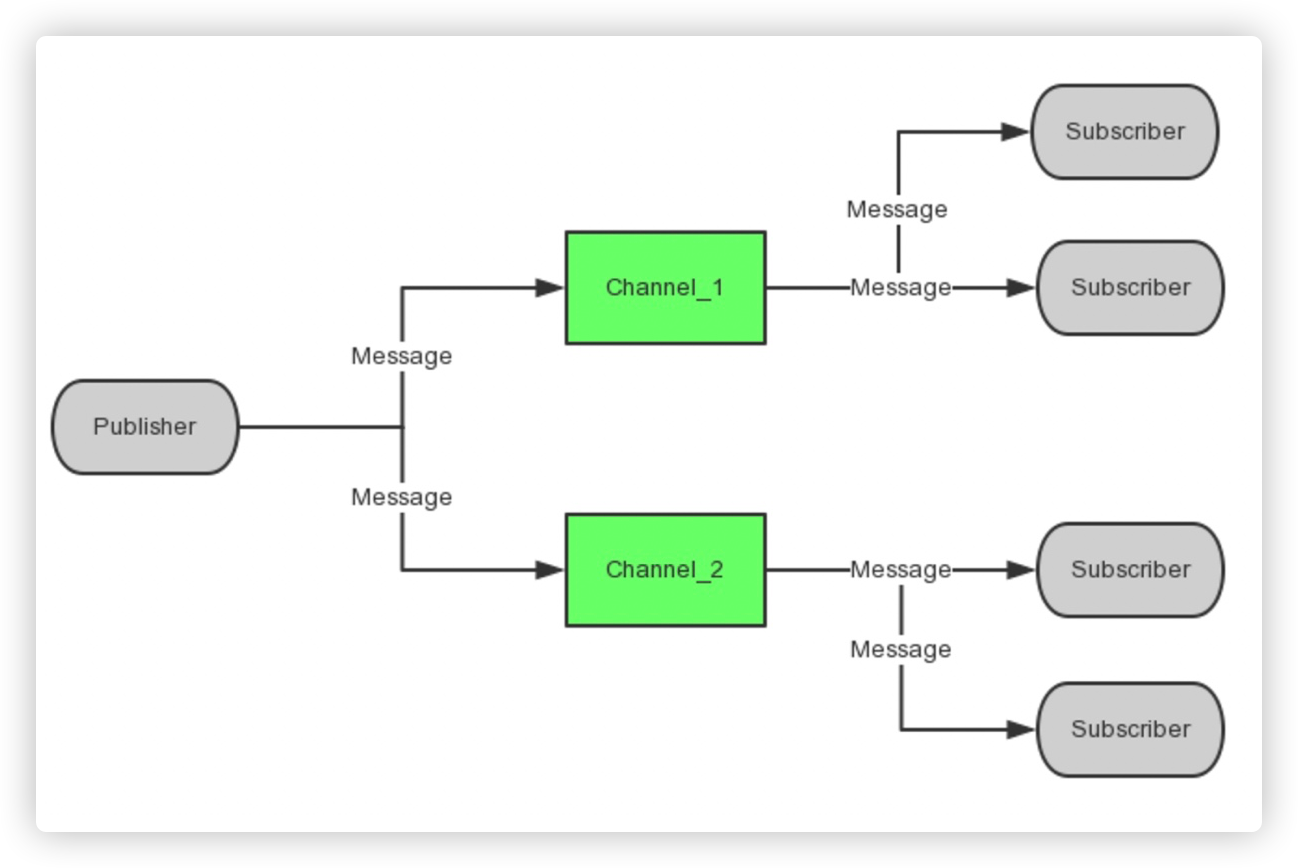
一个Publisher,多个Subscriber模型
如下图所示,可以作为消息队列或者消息管道。
主要应用:通知、公告
多个Publisher,一个Subscriber模型
可以将PubSub做成独立的HTTP接口,各应用程序作为Publisher向Channel中发送消息,Subscriber端收到消息后执行相应的业务逻辑,比如写数据库,显示等等。
主要应用:排行榜、投票、计数。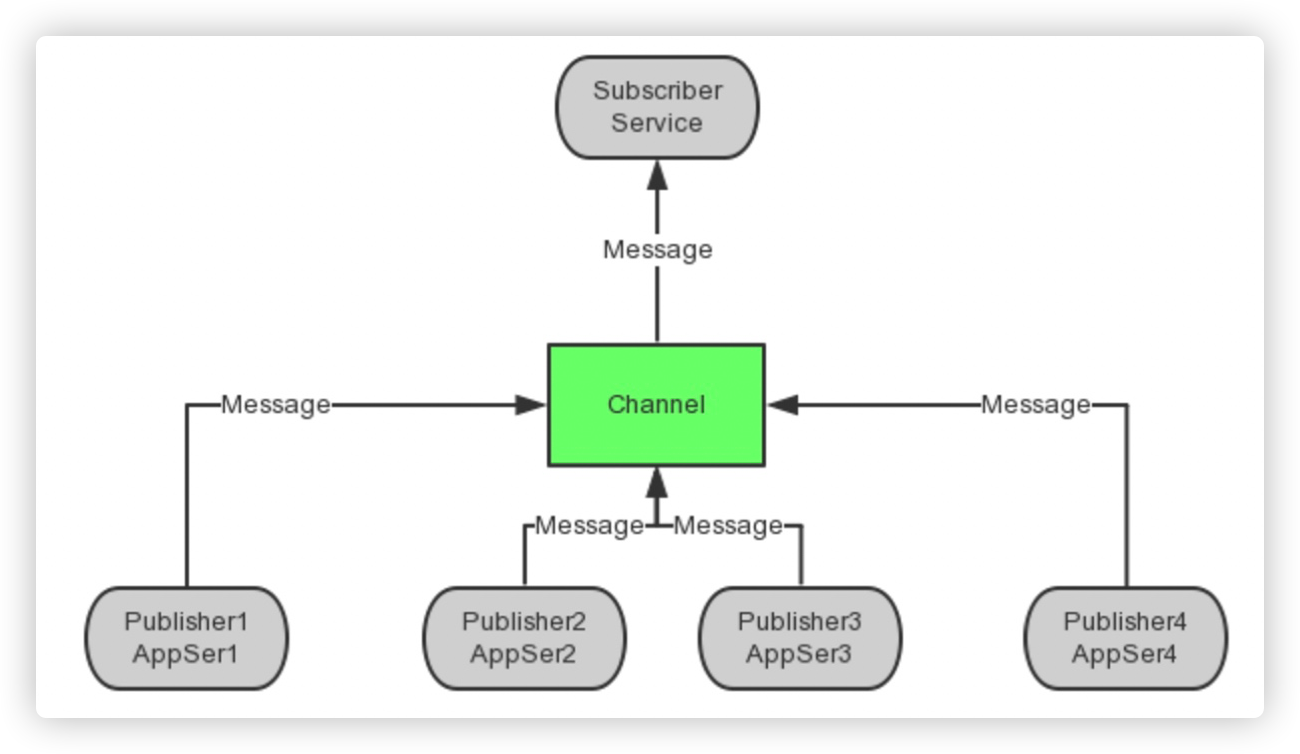
多个Publisher,多个Subscriber模型
故名思议,就是可以向不同的Channel中发送消息,由不同的Subscriber接收。
主要应用:群聊、聊天。
打开两个窗口,分别进入到redis-ctl
//订阅单个频道
127.0.0.1:6379> SUBSCRIBE fm1039
//订阅多个频道
127.0.0.1:6379> PSUBSCRIBE fm*
//发布者向指定的频道发送消息
127.0.0.1:6379> PUBLISH fm1039 "Traffic jam on the"
消息队列对比:
客户端在执行订阅命令之后进入了订阅状态,只能接收 SUBSCRIBE 、PSUBSCRIBE、 UNSUBSCRIBE 、PUNSUBSCRIBE 四个命令。 开启的订阅客户端,无法收到该频道之前的消息,因为 Redis 不会对发布的消息进行持久化。 和很多专业的消息队列系统(例如Kafka、RocketMQ)相比,Redis的发布订阅略显粗糙,例如无法实现消息堆积和回溯。但胜在足够简单,如果当前场景可以容忍的这些缺点,也不失为一个不错的选择。
5. Redis事务及锁
5.1. Redis事务机制
redis中的事务跟关系型数据库中的事务是一个相似的概念,但是有不同之处。关系型数据库事务执行失败后面的sql语句不在执行,而redis中的一条命令执行失败,其余的命令照常执行。
redis中开启一个事务是使用multi,相当于begin\start transaction,exec提交事务,discard取消队列命令(非回滚操作)。
| 说明 | MySQL | Redis |
|---|---|---|
| 开启 | start transact/begin | multi |
| 语句 | 普通SQL | 普通命令 |
| 失败 | rollback 回滚 | discard 取消 |
| 成功 | commit | exec |
事务命令
//开启事务功能,每次提交完事务,进行下一次事务都要执行该命令
127.0.0.1:6379> MULTI
//设置三个key值,#修改类的操作会先放在内存队列中
127.0.0.1:6379> set a 1
127.0.0.1:6379> set b 2
127.0.0.1:6379> set c 3
//提交事务
127.0.0.1:6379> exec
//取消事务
127.0.0.1:6379> discard
//取消 WATCH 命令对所有 key 的监视
127.0.0.1:6379> UNWATCH
//监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。
127.0.0.1:6379> WATCH key [key ...]
5.2. Redis锁机制
举例:我正在买票
Ticket -1 , money -100
而票只有1张, 如果在我multi之后,和exec之前, 票被别人买了,即ticket变成0了.
我该如何观察这种情景,并不再提交
悲观的想法:
世界充满危险,肯定有人和我抢, 给ticket上锁, 只有我能操作. [悲观锁]
乐观的想法:
没有那么人和我抢,因此,我只需要注意,有没有人更改ticket的值就可以了 [乐观锁]
redis乐观锁实现(模拟买票)
//发布一张票
set ticket 1
//窗口1:
watch ticket
multi
set ticket 0 1---->0
//窗口2:
multi
set ticket 0
exec
//窗口1:
exec
6. Redis迁移键
有时候我们需要将部分数据由一个Redis迁移到另一个Redis(例如:从生产环境迁移到测试环境),Redis目前提供了move、dump+restore、migrate 三组迁移键的方法,它们的使用场景各不相同,下面分别介绍
6.1. move
命令基本格式:
move key db
move命令用于在Redis内部进行数据迁移,Redis内部可以有多个数据库,彼此在数据上是相互隔离的。
move key db 就是把指定的键从源数据库移动到目标数据库中,该功能不建议在生产环境中使用,该命令读者知道即可。
172.16.1.21:6379> select 1
OK
172.16.1.21:6379[1]> set hello world
OK
// 将key:hello 从db1移动到db2
172.16.1.21:6379[1]> move hello 2
(integer) 1
172.16.1.21:6379[1]> get hello
(nil)
// 切换到db2 查看key:hello
172.16.1.21:6379[1]> select 2
OK
172.16.1.21:6379[2]> get hello
"world"
3.2. dump+restore
命令基本格式:
dump key
restore key ttl value
dump+restore 这对组合能够实现在不同的Redis实例之间进行数据迁移,整个迁移过程分两步骤:
1)在源Redis上,dump命令会将键值序列化,格式采用RDB(Redis的一种持久化备份数据格式)格式。
2)在目标Redis上,restore明理路将上面序列化的值进行转换复原,其中ttl参数代表过期时间,如果ttl=0代表没有过期时间。
注意:
- 整个迁移过程并非原子性的,而是通过客户端分布完成。
- 迁移过程中是开启了两个客户端连接,所以dump的结果并不是在源Redis传输给目标Redis
1.在源Redis上执行dump
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> dump hello
"\x00\x05world\t\x00\xc9#mH\x84/\x11s"
2.在目标Redis上执行restore
172.16.1.21:6380> get hello
(nil)
172.16.1.21:6380> restore hello 0 "\x00\x05world\t\x00\xc9#mH\x84/\x11s"
OK
172.16.1.21:6380>
172.16.1.21
:6380> get hello
"world"
6.3. migrate
migrate host port key | destination-db time [COPY] [REPLACE] [KEYS key]
# 参数说明:
host:目标Redis IP地址
port:目标Redis 端口
key:迁移的键,可多个
destination-db:目标Redis的数据库索引,例如要迁移到10号数据库,这里就写10
timeout:迁移的超时时间(单位为毫秒)
[copy]:如果添加此选项,迁移后并不删除源键
[replace]:如果添加此选项,migrate不管目标Redis是否存在该键都会 正常迁移进行数据覆盖
[keys key[key...]]:迁移多个键,例如要迁移key1、key2、key3,此处填 写"keys key1 key2 key3"
migrate命令就是真正的在Redis实例间(TCP/IP)进行数据迁移的。
实际上migrate命令是将dumo、restore、del三个命令进行组合,从而简化了操作流程。
migrate具有原子性,而且从Redis3.0.6版本以后已经支持迁移多个键的 功能,有效地提高了迁移效率。
下面演示migrate命令,源Redis IP:172.16.1.21:6379、目标Redis IP:172.16.1.21:6380
1.源redis有键hello,目标redis没有
172.16.1.21:6379> migrate 172.16.1.21 6380 hello 0 1000
OK
2.源redis和目标redis都有键hello
172.16.1.21:6379> get hello
"redis"
172.16.1.21:6380> get hello
"world"
如果没有添加replace选项,因为目标Redis也存在该Key,就会直接报错,添加replace后就算目标Redis存在该key也直接覆盖
172.16.1.21:6379> migrate 172.16.1.21 6380 hello 0 1000
(error) ERR Target instance replied with error: BUSYKEY Target key name already exists.
172.16.1.21:6379> migrate 172.16.1.21 6380 hello 0 1000 replace
OK
3.源Redis批量迁移多个键
// 批量添加多个键
172.16.1.21:6379> mset key1 value1 key2 value2 key3 value3
OK
// 完成多键迁移
172.16.1.21:6379> migrate 172.16.1.21 6380 "" 0 5000 keys key1 key2 key3
OK
7. 渐进式遍历
Redis2.8版本后,提供了一个新的命令 scan ,它能够有效解决keys命令存在的问题, scan 采用渐进式遍历的方式来解决keys命里排可能带来的阻塞问题,每次执行 scan 命令的时间复杂度是0(1),但是真正需要实现keys的功能,就需要执行多次 scan 。
每一次执行 scan ,就是只扫描一个字典中的一部分键,直到将字典中的所有键遍历完毕scan 语法格式:
scan cursor [match pattern] [count number]
curos:必要参数,游标,第一次遍历从0开始,每次遍历完都会返回当前游标的值,直到游标的值为0,表示遍历结束,
match pattern:可选参数,模式匹配,和keys的模式匹配很类似
count number:可选参数,表明每次要遍历的键个数,默认 值是10,此参数可以适当增大
添加测试键值对
127.0.0.1:6379[1]> mset a a b b c c d d e e f f g g h h i i j j k k l l n n m m o o
执行 scan
# 第一次执行scan 0,返回结果有两个部分,一个部分是26就是下一次scan需要的cursor,第二部分就是10个键
127.0.0.1:6379[1]> scan 0
1) "21"
2) 1) "h"
2) "m"
3) "d"
4) "o"
5) "j"
6) "k"
7) "c"
8) "i"
9) "b"
10) "e"
# 执行新的 scan 21, 得到结果cursor变为0,说明所有的键都已被遍历过了
127.0.0.1:6379[1]> scan 21
1) "0"
2) 1) "g"
2) "t1"
3) "l"
4) "a"
5) "n"
6) "f"
除了scan以外,Redis还提供了 hscan、sscan、zscan来解决hgetall、smembers、zrange
可能产生的阻塞问题,它们的用法和scan基本类似。
8. pipeline
pipeline 顾名思义 流水线,redis中提供了批量操作的命令,但是并不是所有的数据类型都支持批量操作,如果我需要执行N条命令,而且该类型又不支持批量操作,那么这时候每次发送一条命令,就需要发送N次,会消耗大量的网络IO资源,pipeline 是将一组命令发送给redis,进入队列,然后redis会按照顺序执行命令。
大部分时候都是用redis客户端来实现pipeline
import redis
import time
rds_cli = redis.StrictRedis(host="127.0.0.1", db=1)
with rds_cli.pipeline(transaction=False) as p:
start = time.time()
p.sadd('seta', 1).sadd('setb', 2).sadd('setc', 3).sadd('setd', 4).sadd('sete', 5).hset("a", "k1", "v1")
p.execute()
print(time.time() - start)
原生批量命令和pipeline的区别:
- 原生批量命令是原子的,Pipeline是非原子的。
- 原生批量命令是一个命令对应多个key,Pipeline支持多个命令。
- 原生批量命令是Redis服务端支持实现的,而Pipeline需要服务端和客户端的共同实现。
虽然pipeline非常好用,但是也不能不无节制的使用,命令过多,reids服务端执行起来会阻塞,而客户端也需要等待返回结果,所以如果命令特别多的情况下建议把多个命令进行拆分执行。

若有收获,就点个赞吧
0 人点赞
