1. awk简介
awk是一种名字怪异的语言,支持模式扫描和处理
awk不仅仅时linux系统中的一个命令,而且是一种编程语言,可以用来处理数据和生成报告(excel)。处理的数据可以是一个或多个文件,可以是来自标准输入,也可以通过管道获取标准输入,awk可以在命令行上直接编辑命令进行操作,也可以编写成awk程序来进行更为复杂的运用。本章主要讲解awk命令的运用。
awk环境
[root@xmh ~]# awk --versionGNU Awk 4.0.2Copyright (C) 1989, 1991-2012 Free Software Foundation.
2. awk格式
awk指令是由模式,动作,或者模式和动作的组合组成。
1、模式既pattern,可以类似理解成sed的模式匹配,可以由表达式组成,也可以是两个正斜杠之间的正则表达式。比如NR==1,这就是模式,可以把他理解为一个条件。
2、动作即action,是由在大括号里面的一条或多条语句组成,语句之间使用分号隔开。比如awk使用格式: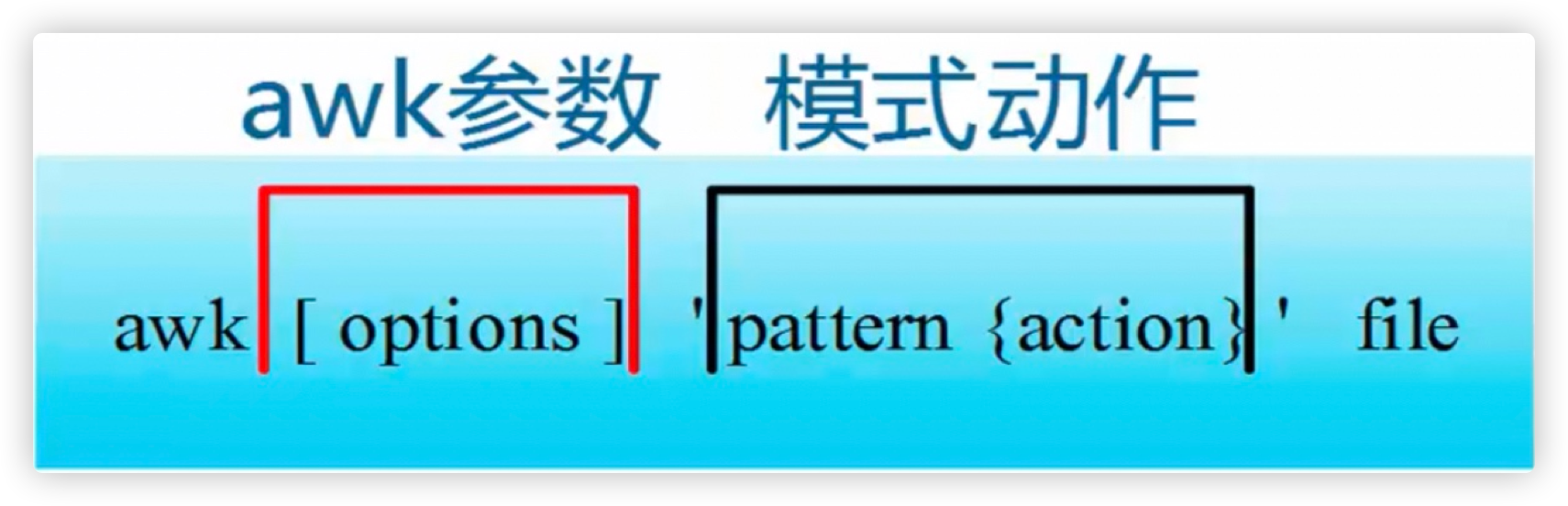
awk处理的内容可以来自标准输入(<),一个或多个文本文件或管道。

3. awk执行过程
awk模式和动作的语法:
1、Pattern和{Action}需要用单引号引起来,防止shell作解释。
2、Pattern是可选的。如果不指定,awk将处理输入文件中的所有记录。如果指定一个模式,awk则只处理匹配指定的模式的记录。
3、{Action}为awk命令,可以是单个命令,也可以多个命令。整个Action(包括里面的所有命令)都必须放在{ 和 }之间。
4、Action必须被{ }包裹,没有被{ }包裹的就是Patern
5、file要处理的目标文件
1.单模式单动作
//取/etc/passwd文件内容的第2行到第6行的第一列[root@xmh ~]# awk -F ":" 'NR>=2 && NR<=6{print NR,$1}' /etc/passwd2 bin3 daemon4 adm5 lp6 sync命令解释:-F #指定分隔符为冒号,相当于以":"为菜刀,进行字段的切割。NR>=2 && NR<=6 #这部分表示模式,是一个条件,表示取第2行到第6行。{print NR,$1} #这部分表示动作,表示要输出的 NR行号和$1第一列
2.单模式
//只有模式没有动作(这里没有条件,awk会对每一行都处理)[root@xmh ~]# awk -F ":" 'NR>=2 && NR<=6' /etc/passwdbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sbin/nologinlp:x:4:7:lp:/var/spool/lpd:/sbin/nologinsync:x:5:0:sync:/sbin:/bin/sync
3.多个模式和动作
//多模式实现取/etc/passwd文件内容第1行和最后一行的第一列[root@xmh ~]# awk -F ":" 'NR==1{print NR,$1} NR==2{print NR,$NF}' /etc/passwd1 root2 /sbin/nologin命令解释(这里有多个条件与动作的组合):NR==1 #表示条件,行号(NR)等于1的条件满足的时候,执行{print NR,$1}动作,输出行号与第一列。NR==2 #表示条件,行号(NR)等于2的条件满足的时候,执行{print NR,$NF}动作,输出行号与最后一列
4. AWK基本使用
实例文件
[root@xmh ~]# cat passwd.xmhroot x 0 0 root /root /bin/bashbin x 1 1 bin /bin /sbin/nologindaemon x 2 2 daemon /sbin /sbin/nologinadm x 3 4 adm /var/adm /sbin/nologinlp x 4 7 lp /var/spool/ldp /sbin/nologinsync x 5 0 sync /sbin /bin/syncshutdown x 6 0 shutdown /sbin /sbin/shutdownhalt x 7 0 halt /sbin /sbin/haktmail x 8 12 mail /var/spool/,ail /sbin/nologinuucp x 10 14 uucp /var/spool/uucp /sbin/nologin
1.这个文件仅包含十行文件,我们使用下面的命令:
//打印行号大于或等于第2的内容
[root@xmh ~]# awk 'NR>=2{print $0}' passwd.xmh
//那如果行号大于或者等于15尼?没有任何结果,因为条件是当行号大于或者等于15,才执行$0
[root@xmh ~]# awk 'NR>=15{print $0}' passwd.xmh
命令说明:
条件NR>=2 #表示行号大于等于2时候,才执行{print $0}显示整行,如果。
awk是通过一行一行的处理文件,这条命令中包含模式部分(条件)和动作部分(动作),awk将处理模式(条件)指定的行
2.直接显示{print “ “}大括号里的双引号里的内容
[root@xmh ~]# awk 'BEGIN{print "123456"}'
123456
[root@xmh ~]# awk 'BEGIN{print "Hello World!"}'
Hello World!
提示:使用BEGIN模块的话就不需要后面追加文件来输出显示需要的内容了
//如果接文件打印双引号里内容的话,那么文件中里有多少行内容,就会根据双引号里的内容打印多少行内容
[root@xmh ~]# awk '{print "xmh"}' num1.txt
xmh
xmh
xmh
xmh
5. AWK BEGIN模块
BEGIN模块再awk读取文件之前就执行,一般用来定义我们的内置变量(预定义变量,eg:FS,RS),可以输出表头(类似excel表格名称)给内容变量赋值等,需要注意的是BEGIN模式后面要接跟一个action操作块,包含在大括号内。awk必须在输入文件进行任何处理前先执行BEGIN里的动作(action)。我们可以不要任何输入文件,就可以对BEGIN模块进行测试,因为awk需要先执行完BEGIN模式,才对输入文件做处理。BEGIN模式常常被用来修改内置变量ORS,RS,FS,OFS等值。
1.在读取文件之前,输出提示性信息(表头)
[root@xmh ~]# awk 'BEGIN{print "username","UID"} {print $0}' passwd.xmh |head -3
username UID #表头信息
root x 0 0 root /root /bin/bash
bin x 1 1 bin /bin /sbin/nologin
2.BEGIN特殊性质,做计算和变量赋值
[root@xmh ~]# awk 'BEGIN{print 10/3}'
3.33333
[root@xmh ~]# awk 'BEGIN{print 10+10}'
20
[root@xmh ~]# awk 'BEGIN{print 2*3}'
6
[root@xmh ~]# awk 'BEGIN{a=1;b=2;print a,b}'
1 2
[root@xmh ~]# awk 'BEGIN{a=1;b=2;print a,b,a+b}'
1 2 3
6. AWK记录分隔符
awk对每个要处理的输入数据认为都是具有格式和结构的,而不仅仅是一堆字符串。默认情况下,每一行内容都是一条记录,并以换行符分隔(\n)结束。

- awk默认情况下每一行都是一个记录(record)
RS既record separator输入的时候记录分隔符,每一行是怎么没的,表示每个记录输入的时候的分隔符,既行与行之间如何分隔。NR既number of record记录行号,表示当前正在处理的记录(行)的号码。- ORS既output record separator 输出的时候记录分隔符
awk使用内置变量RS来存放输入记录分隔符,RS表示的是输入的记录分隔符,这个值可以通过BEGIN模块重新定义修改
Note:分隔符语法:awk ‘BEGIN{RS=”XX”}{print XX}’ file.txt
1.打印文本内容每行的行号
[root@xmh ~]# awk '{print NR,$0}' /etc/passwd |head -5
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
2.使用分隔符为”/”,行与行之间用/分割,然后再输出结果
[root@xmh ~]# awk 'BEGIN{RS="/"}{print NR,$0}' /etc/passwd |head -5
1 root:x:0:0:root:
2 root:
3 bin
4 bash
bin:x:1:1:bin: #awk把文件当做一个连续的字符串,恰巧里面\n符号,
3.将下面文本内容,用a和b作为换行符
//实例文件
[root@xmh ~]# cat num1.txt
1 2 3 a 5 6 7 b 8 9
[root@xmh ~]# awk 'BEGIN{RS="a|b"}{print NR,"num1:"$1,"num2:"$2,"num3:"$3}' num1.txt
1 num1:1 num2:2 num3:3
2 num1:5 num2:6 num3:7
3 num1:8 num2:9 num3:
7. AWK的$0
awk中$0表示整行,其实awk使用$0来表示整条记录。
另外,awk对每一行的记录号都有一个内置变量NR来保存,每处理完一条记录,NR的值就会自动+1
1.NR记录行号
[root@xmh ~]# awk 'NR>=2 && NR<=5{print NR,$0}' /etc/passwd
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
2.按单词出现频率降序排序(计算文件中每个单词的重复数量)
//题目创建方法
[root@xmh ~]# sed -r '1,10s#[^a-zA-Z]+# #g' /etc/passwd |head -5 >./count.txt
[root@xmh ~]# cat count.txt
root x root root bin bash
bin x bin bin sbin nologin
daemon x daemon sbin sbin nologin
adm x adm var adm sbin nologin
lp x lp var spool lpd sbin nologin
//方法一,设置RS分隔符为空格
[root@xmh ~]# awk 'BEGIN{RS=" "}{print $0}' count.txt |sort |uniq -c |sort -rn
//方法二,将文件里的所有空格替换成换行符"\n"
[root@xmh ~]# cat count.txt |tr " " "\n" |sort |uniq -c |sort -rn
//方法三,grep 所有连续的字符,grep -o 让他们排成一列
[root@xmh ~]# grep -o "[a-zA-Z]\+" count.txt |sort|uniq -c |sort -rn
awk记录知识小结
- NR存放着每个记录的号(行号)读取新行时候会自动+1
- RS是输入数据的记录的分隔符,简单理解就是可以指定每个记录的结尾标志。
- RS作用就是表示一个记录的结束
- 当我们修改了RS的值,最好配合NR(行)来查看变化,也就是修改了RS的值通过NR查看结果,调试awk程序。ORS输出数据的记录的分隔符
8. AWK字段(区域)
每条记录都是由多个字段(field)组成的,默认情况下字段之间的分隔符是又空白符(即空格或制表符)来分割,并且将分隔符记录在内置变量FS中。每行记录的字段数保存在awk的内置变量NF中。
Note:awk使用内置变量FS来记录区域分隔符的内容,FS可以在命令行上通过
-F参数来更改,也可以通过BEGIN模块来更改。
实例文件
[root@xmh ~]# head -3 /etc/passwd >fs-example.txt
1.使用-F,指定分隔符为“:“,然后输出每行的行头和行未
[root@xmh ~]# awk -F ":" '{print $1,$NF}' fs-example.txt
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
2.使用BEGIN模块FS,指定分隔符“:“,然后输出$1和$NF(行尾)
[root@xmh ~]# awk 'BEGIN{FS=":"}{print $1,$NF}' fs-example.txt
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
3.awk在取区域的时候加逗号和不加逗号的区别
//实例文件
[root@xmh ~]# cat number.txt
1234.123123
324.5234
351.3451
//不加逗号,就是把所有参数之间原样输出
[root@xmh ~]# awk -F "." '{print $1$2}' number.txt
1234123123
3245234
3513451
//加了逗号,输出的时候会在$1和$2之间加上空格
[root@xmh ~]# awk -F "." '{print $1,$2}' number.txt
1234 123123
324 5234
351 3451
9. AWK的OFS
AWK中的OFS可以认为是在$n之间自定义添加值
1.在输出$1和$2的中间空格使用OFS变量来插入字符”####”
[root@xmh ~]# awk -F "[:/]" '{OFS="###"} {print $1,$2}' fs-example.txt
root###x
bin###x
daemon###x
2.将下面的数字的“.”点号,通过AWK替换成“*”
[root@xmh ~]# cat number.txt
1234.123123
324.5234
351.3451
[root@xmh ~]# awk -F "." '{OFS="*"} {print $1,$2}' number.txt
1234*123123
324*5234
351*3451
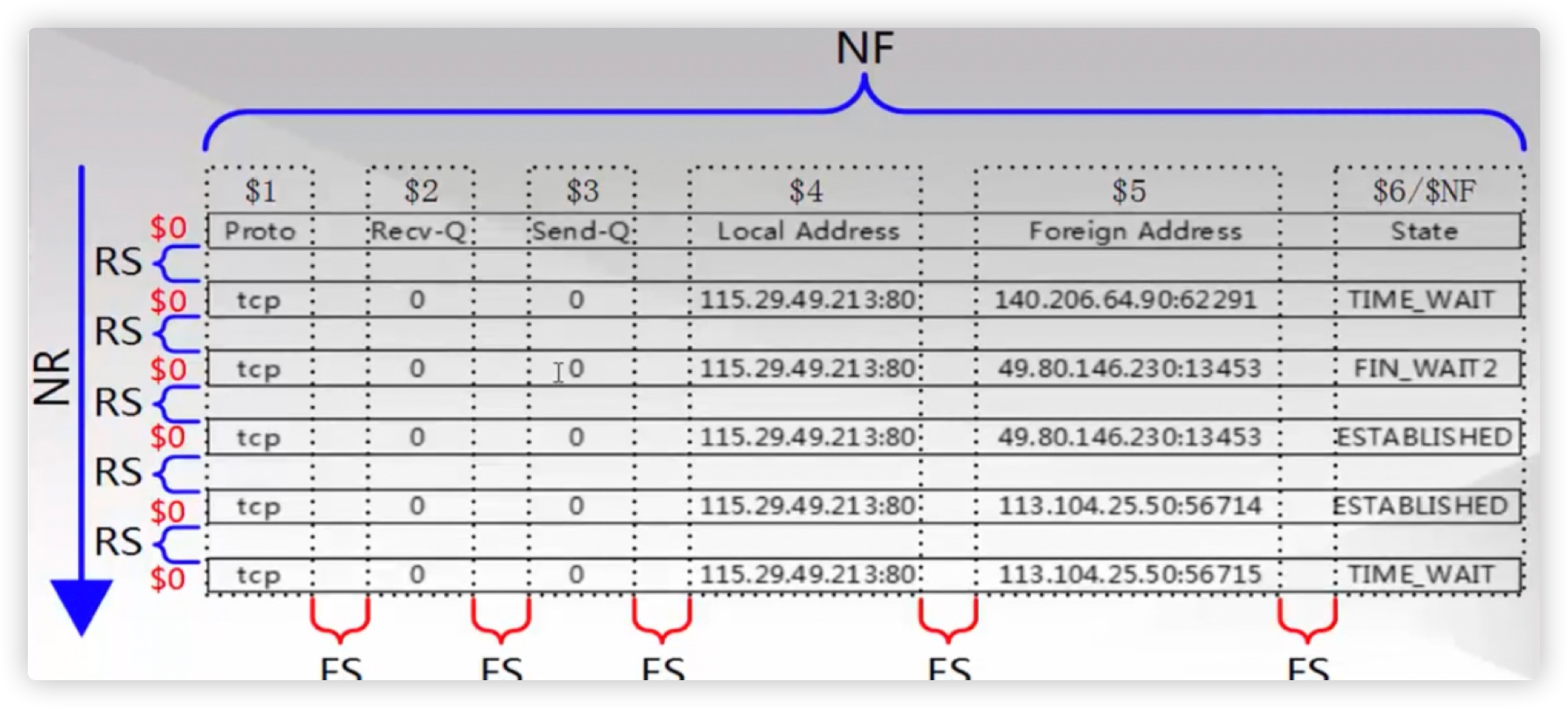
10. AWK的域与记录
小结:
- RS记录分隔符,表示每行的结束标志
- NR行号(记录号),F表示记录中的区域(列)数量,$NF取最后一个列(区域。)
- FS字段分隔符,每列的分隔标志或结束标志
- NF就是每行有多少列,每个记录中字段的数量
- $符号表示取某个列(字段),$1$2$NF
- 分隔符==>结束标识
- 记录与区域,你就对我们所谓的行与列,有了新的认识(RS,FS)
11. AWK正则表达式
awk同sed一样也可以通过模式匹配来对输入的文本进行匹配处理。说到模式匹配,肯定少不了正则表达式,awk也支持大量的正则表达式模式,大部分与sed支持的元字符类似, 而且正则表达式是玩转三剑客的必备工具
awk正则匹配操作符:
~ 用于对记录或区域的表达式进行匹配
!~ 用于表达与~相反的意思
注意:awk默认不支持元字符,需结合—posix参数
示例文件
[root@xmh ~]# cat passwd.xmh
root x 0 0 root /root /bin/bash
bin x 1 1 bin /bin /sbin/nologin
daemon x 2 2 daemon /sbin /sbin/nologin
adm x 3 4 adm /var/adm /sbin/nologin
lp x 4 7 lp /var/spool/ldp /sbin/nologin
sync x 5 0 sync /sbin /bin/sync
shutdown x 6 0 shutdown /sbin /sbin/shutdown
halt x 7 0 halt /sbin /sbin/hakt
mail x 8 12 mail /var/spool/,ail /sbin/nologin
uucp x 10 14 uucp /var/spool/uucp /sbin/nologin
1.取出以s开头的行
[root@xmh ~]# awk '/^s/' passwd.xmh
sync x 5 0 sync /sbin /bin/sync
shutdown x 6 0 shutdown /sbin /sbin/shutdow
2.输出特定的列
//匹配以r开头的行
[root@xmh ~]# awk '/^r/' passwd.xmh
root x 0 0 root /root /bin/bash
//匹配以c结尾的行
[root@xmh ~]# awk '/c$/' passwd.xmh
sync x 5 0 sync /sbin /bin/sync
//匹配第五列字符以h开头的行
[root@xmh ~]# awk '$5~/^h/' passwd.xmh
halt x 7 0 halt /sbin /sbin/hakt
3.取出出现一次或者两次字母7的字符
[root@xmh ~]# awk --posix '/7{1,2}/{print $0}' passwd.xmh
lp x 4 7 lp /var/spool/ldp /sbin/nologin
halt x 7 0 halt /sbin /sbin/hakt
4.ifconfig取IP
[root@xmh ~]# ifconfig eth0 |awk 'NR==2{print $2}'
10.0.0.200
12. AWK比较表达式
awk是一种编程语言,能够进行更为复杂的判断,当条件为真时候,awk就执行相关的action。主要是针对某一区域做出相关的判断,比如打印成绩在80分以上的行,这样就必须对这一区域做比较判断,下表列出了awk可以使用的关系运算符,可以用来比较数字字符串,还有正则表达式。当表达式为真时候,表达式结果1,否0,只有表达式为真,awk才执行相关的action
运算符(针对数字)
< 小于
<= 小于等于
== 等于
!= 不等于
>= 大于或等于
> 大于
示例文件
[root@xmh ~]# cat fs-example.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
1.演示”!=”
//匹配除第一行之外的所有内容
[root@xmh ~]# awk 'NR!=1{print NR,$0}' fs-example.txt
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
//匹配除第一二行之外的所有内容
[root@xmh ~]# awk 'NR!=1 && NR!=2 {print NR,$0}' fs-example.txt
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
2.打印出第三列数字为3-6的整行
[root@xmh ~]# awk '$3~/[3-6]/{print $0}' passwd.xmh
adm x 3 4 adm /var/adm /sbin/nologin
lp x 4 7 lp /var/spool/ldp /sbin/nologin
sync x 5 0 sync /sbin /bin/sync
shutdown x 6 0 shutdown /sbin /sbin/shutdown
3.打印第一列数字为1-3的整行
//示例文件
[root@xmh ~]# cat num3.txt
1 hello world
3 this is test
5 are you ok?
7 Hi good morning
9 How are you
[root@xmh ~]# awk '$1~/[1-3]/{print $0}' num3.txt
1 hello world
3 this is test
4.打印出对应第一列英文单词的整行
//示例文件
[root@xmh ~]# cat num4.txt
a apple
b banana
o orange
w watermelon
g grape
t tangerine
d durian
p passion fruit
//匹配第一列为a至c的整行
[root@xmh ~]# awk '$1~/[a-c]/{print $0}' num4.txt
a apple
b banana
//匹配第一列为a,t,p的整行
[root@xmh ~]# awk '$1~/[a,t,p]/{print $0}' num4.txt
a apple
t tangerine
p passion fruit
13. AWK范围模式
| pattern1 | to | patternl |
|---|---|---|
| 从哪里来 | 到 | 那里去 |
| 条件1 | 条件2 |
使用格式
awk '/start ois/,/end pos/{print $0}' passwd.xmh
awk '/start ois/,NR==XXX{print $0}' passwd.xmh
示例文件
[root@xmh ~]# cat passwd.xmh
root x 0 0 root /root /bin/bash
bin x 1 1 bin /bin /sbin/nologin
daemon x 2 2 daemon /sbin /sbin/nologin
adm x 3 4 adm /var/adm /sbin/nologin
lp x 4 7 lp /var/spool/ldp /sbin/nologin
sync x 5 0 sync /sbin /bin/sync
shutdown x 6 0 shutdown /sbin /sbin/shutdown
halt x 7 0 halt /sbin /sbin/hakt
mail x 8 12 mail /var/spool/,ail /sbin/nologin
uucp x 10 14 uucp /var/spool/uucp /sbin/nologin
1.从开头字符为adm到开头字符为shutdown之间的行
[root@xmh ~]# awk '/^adm/,/^shutdown/{print $0}' passwd.xmh
adm x 3 4 adm /var/adm /sbin/nologin
lp x 4 7 lp /var/spool/ldp /sbin/nologin
sync x 5 0 sync /sbin /bin/sync
shutdown x 6 0 shutdown /sbin /sbin/shutdown
14. AWK数组
awk提供了数组来存放一组相关的值。
awk是一种编程语言,肯定也支持数组的运用,但是又不同于c语言的数组。数组在awk中被称为关联数组,因为它的下标既可以是数字也可以是字符串。下标通常被称作key,并且与对应的数组元素的值关联。数组元素的key和值都存储在awk程序内部的一张表中,通过一定散列算法来存储,所以数组元素都不是按顺序存储的。打印出来的顺序也肯定不是按照一定的顺序,但是我们可以通过管道来对所需的数据再次操作来达到自己的效果。
//实例文件
http://www.etiantian.org/index.html
http://www.etiantian.org/1.html
http://post.etiantian.org/index.html
http://mp3.etiantian.org/index.html
http://www.etiantian.org/3.html
http://post.etiantian.org/2.html
[root@linux-node1 files]# awk -F "/+" '{array[$2]++}END{for(key in array)print key,array[key]}' url.txt url.txt
mp3.etiantian.org 1
www.etiantian.org 3
post.etiantian.org 2
15. AWK练习题
1.请打印出/etc/passwd 第一个域,并且在第一个域所有的内容前面加上”用户帐号:”
[root@xmh ~]# awk '{print "用户账号:",$0}' /etc/passwd |head -2
用户账号: root:x:0:0:root:/root:/bin/bash
用户账号: bin:x:1:1:bin:/bin:/sbin/nologin
2.请打印出/etc/passwd 第三个域和第四个域
[root@xmh ~]# awk -F ":" '{print $3"\t"$4}' /etc/passwd
3.匹配/etc/passwd 第三域大于100的显示出完整信息
[root@xmh ~]# awk -F ":" '{if($3>100)print $0}' /etc/passwd
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
polkitd:x:999:997:User for polkitd:/:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
xmh:x:1000:1000::/home/xmh:/bin/bash
nginx:x:997:995:Nginx web server:/var/lib/nginx:/sbin/nologin
4.统计secure文件中谁在破解你的密码(统计出破解你密码的ip地址出现的次数)
[root@xmh ~]# awk '/Failed/{a[$13]++}END{for(key in a)print key,a[key]}' /var/log/secure |sort -rn
[root@xmh ~]# awk '/Failed/{a[$(NF-3)]++}END{for(key in a)print key,a[key]}' /var/log/secure |sort -rn
[root@xmh ~]# awk '/Failed/{print $13}' /var/log/secure |sort -rn |uniq -c
5.统计access.log文件中网站一共使用了多少流量
统计总数较为简单
i=i+$10可以写为 i+=$10
i累计相加,然后再输出最后一个i的值即可
[root@xmh ~]# awk '{i=i+$10}END{print i}' /var/log/nginx/access_xiongminghao.log_2019-02-16
41393

若有收获,就点个赞吧
0 人点赞
