引言
“物以类聚,人以群分”
根据“近邻”来判断事物类别
通过人工智能根据事物的“邻居”自动判断事物地类别
K-近邻分类与K-均值聚类这两个人工智能算法采用了这种思想
区别在于近邻的类别是否已知
K-近邻分类
定义
KNN,已知一批数据集(训练数据集)及对应的分类标签,要为一批没有分类标签的测试数据预测其分类标签
将测试数据集中的样本和训练数据集中的所有样本计算“距离”,找出距离最近的前K个训练样本
测试样本的预测类别就是这k个训练样本中出现次数最多的那个类别
- 计算距离
- 按照距离对训练样本排序
- 找出前K个
- 计算各类别出现的频率
- 选择频率出现最高的那个
knn算法不会形成模型函数,线性回归拟合一个线性函数,逻辑斯蒂分类拟合一个逻辑斯蒂函数
线性回归和逻辑斯蒂分类的计算代价花在训练阶段的模型拟合,拟合好后对测试数据的预测花费的时间代价小
knn算法没有训练阶段,时间花费在测试数据和所有训练样本计算距离上
编码
定义其“距离”的计算方法: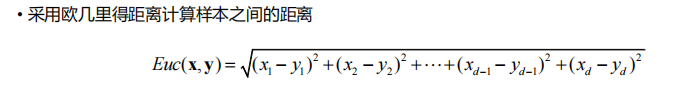
定义了一个K近邻分类函数knn_classifier()、有四个参数:
• 待预测的输入样例input
• 训练数据trains
• trains所对应的类别标签classes
• k值大小
不同的K值会导致不同的分类结果
“暴力法”:计算输入样本与每一个训练样本的距离,只适用于训练样本集较小时,也叫“线性扫描法”
距离度量
除了欧式距离,还有Lp距离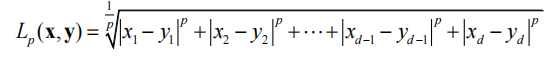
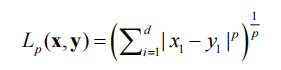
x和y是两个有d个特征的样本,p>=1
p=2,就是欧式距离
p=1,就是曼哈顿距离(两点在x轴和y轴上的差距之和)
p=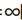 ,变成各个坐标距离的最大值
,变成各个坐标距离的最大值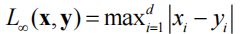
不同的距离度量方法所确定的最近邻居是不同的
余弦相似度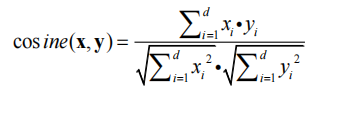
用向量空间中两个向量夹角的余弦值作为衡量两个样本间差异的大小
K值选择
如果选择较小K值,只有与输入样本较近的样本才起作用,其它训练样例会因为距离远而没有“投票权”,其缺点是预测结果对近邻的样例非常敏感,如果近邻恰巧是噪声,预测会出错,因此K值减小意味着容易发生过拟合
如果选择较大的K值,具有“投票权”的训练样例数量会增多,可能导致与输入样本不怎么相似的训练样例也会起作用,使得预测发生错误
如果K=M(训练样本总数量),则无论输入样例是什么,都将简单地预测为训练样本集中样本数量最多的那个类别
K值一般取较小数值,可通过多次实验确定较好K值
分类决策规则
- K近邻分类最常用的决策规则是“多数表决法”
- 即由K个最靠近的训练样例中的多数类决定输入样例的类别
- 邻居的投票权重还可以根据距离进行加权
- 越近的邻居所起的作用越大
- 距离远的邻居的投票权重就小一些
基于sklearn实现
类名:sklearn.neighbors.NearestNeighbors
创建NearestNeighbors对象时,指定n_neighbors,metric,algorithm参数
拟合模型,使用model.fit(traindata)
对测试样本进行预测,distances, indices=model.kneighbors(testData),其中distances是K个最近邻训练样本到输入样本的距离,indices是对应样本在训练集中的下标优缺点分析
优点:简单容易实现 精度高 适用于多分类
K-均值聚类
引言
- 也叫K-Means聚类,是一种“无监督”的机器学习方法
- 无监督学习,指不存在有人工标签的训练样本情况下进行机器学习
- 人工标签是一种很强的“监督”信息,获取成本昂贵
聚类:将相似的对象组成相同的类,使同类的对象之间距离尽可能小
定义
K均值聚类是基于划分样本集合的聚类算法
• 没有人工标记的类别标签
• 在计算过程中根据样本间的距离将样本集划分为K个子集
• 每个子集代表一个类别,每个类别有一个“中心”,这个中心的“坐标”是所有属于该类别的样本的平均值;
• 样本与类别的距离可以通过计算样本与类别中心的距离得到,每个样本所属的类别是与该样本最近的类别
K均值聚类算法是一个动态迭代直至收敛的过程

自定义编码实现
设置K值为2,加载数据并设置各类初始中心点坐标
K均值聚类的时间复杂度是O(iter_countmk*d)
scikit-learn实现KMeans
传统的K-均值算法对应的类是KMeansfrom sklearn.cluster import KMeansmodel = KMeans ( n_clusters, max_iter = 300, n_init = 10, init = "k-means++", algorithm = "auto" )
n_clusters:K值,一般需要多试一些值以获得较好的聚类效果
max_iter:最大迭代次数,默认值是300
n_init:用不同初始化聚簇“中心”运行算法的次数,默认值是10
init: 即初始值选择的方式,默认“k-means++”
k-均值聚类一定会收敛。

若有收获,就点个赞吧
0 人点赞
