原理介绍
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
架构各模块介绍
- Lucence Directory:是lucene的框架服务发现以及选主 ZenDiscovery: 用来实现节点自动发现,还有Master节点选取,假如Master出现故障,其它的这个节点会自动选举,产生一个新的Master。
- Plugins:插件可以通过自定的方式扩展加强Elasticsearch的基本功能,比如可以自定义类型映射,分词器,本地脚本,自动发现等。
- Scripting:使用脚本语言可以计算自定义表达式的值,比如计算自定义查询相关度评分。支持的脚本语言有groovy,js,mvel(1.3.0废弃),python等。
- Disovery:该模块主要负责集群中节点的自动发现和Master节点的选举。节点之间使用p2p的方式进行直接通信,不存在单点故障的问题。Elasticsearch中,Master节点维护集群的全局状态,比如节点加入和离开时进行shard的重新分配。
- River:代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中。
- Gateway:模块用于存储es集群的元数据信息。
- Zen Discovery:zen发现机制是elasticsearch默认的内建模块。它提供了多播和单播两种发现方式,能够很容易的扩展至云环境。zen发现机制是和其他模块集成的,例如所有节点间通讯必须用trasport模块来完成。
核心概念
- 集群(Cluster): ES集群是一个或多个节点的集合,它们共同存储了整个数据集,并提供了联合索引以及可跨所有节点的搜索能力。多节点组成的集群拥有冗余能力,它可以在一个或几个节点出现故障时保证服务的整体可用性。集群靠其独有的名称进行标识,默认名称为“elasticsearch”。节点靠其集群名称来决定加入哪个ES集群,一个节点只能属一个集群。
- 节点(node): 一个节点是一个逻辑上独立的服务,可以存储数据,并参与集群的索引和搜索功能, 一个节点也有唯一的名字,群集通过节点名称进行管理和通信。
- 主节点:主节点的主要职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。稳定的主节点对集群的健康是非常重要的。虽然主节点也可以协调节点,路由搜索和从客户端新增数据到数据节点,但最好不要使用这些专用的主节点。一个重要的原则是,尽可能做尽量少的工作。对于大型的生产集群来说,推荐使用一个专门的主节点来控制集群,该节点将不处理任何用户请求。
- 数据节点:持有数据和倒排索引。
- 客户端节点:它既不能保持数据也不能成为主节点,该节点可以响应用户的情况,把相关操作发送到其他节点;客户端节点会将客户端请求路由到集群中合适的分片上。对于读请求来说,协调节点每次会选择不同的分片处理请求,以实现负载均衡。部落节点:部落节点可以跨越多个集群,它可以接收每个集群的状态,然后合并成一个全局集群的状态,它可以读写所有节点上的数据。
- 索引(Index): ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。索引由其名称(必须为全小写字符)进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。一个ES集群中可以按需创建任意数目的索引。
- 文档类型(Type):类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。一般来说,类型就是为那些拥有相同的域的文档做的预定义。例如,在索引中,可以定义一个用于存储用户数据的类型,一个存储日志数据的类型,以及一个存储评论数据的类型。类比传统的关系型数据库领域来说,类型相当于“表”。
- 文档(Document) :文档是Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,基于JSON格式进行表示。文档由一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。相当于数据库的“记录”。
- Mapping: 相当于数据库中的schema,用来约束字段的类型,不过 Elasticsearch 的 mapping 可以自动根据数据创建ES中,所有的文档在存储之前都要首先进行分析。用户可根据需要定义如何将文本分割成token、哪些token应该被过滤掉,以及哪些文本需要进行额外处理等等。
- 分片(shard) :ES的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,这每一个物理的Lucene索引称为一个分片(shard)。每个分片其内部都是一个全功能且独立的索引,因此可由集群中的任何主机存储。创建索引时,用户可指定其分片的数量,默认数量为5个。
- Shard有两种类型:primary和replica,即主shard及副本shard。Primary shard用于文档存储,每个新的索引会自动创建5个Primary shard,当然此数量可在索引创建之前通过配置自行定义,不过,一旦创建完成,其Primary shard的数量将不可更改。Replica shard是Primary Shard的副本,用于冗余数据及提高搜索性能。每个Primary shard默认配置了一个Replica shard,但也可以配置多个,且其数量可动态更改。ES会根据需要自动增加或减少这些Replica shard的数量。ES集群可由多个节点组成,各Shard分布式地存储于这些节点上。ES可自动在节点间按需要移动shard,例如增加节点或节点故障时。简而言之,分片实现了集群的分布式存储,而副本实现了其分布式处理及冗余功能。
创建索引
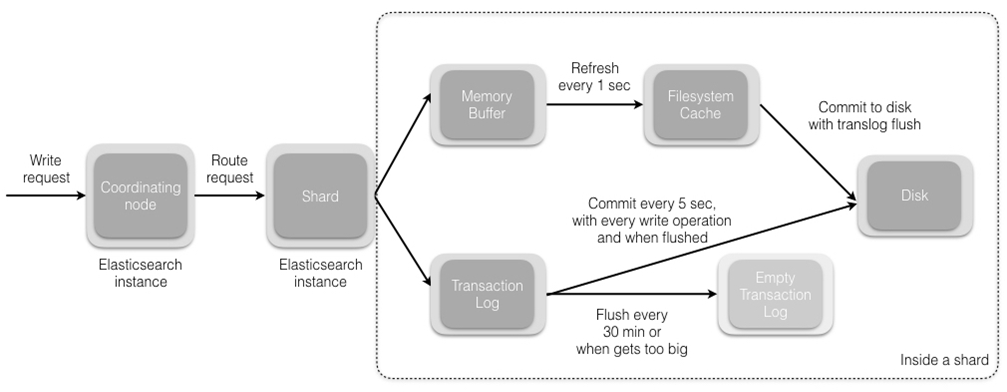
- 过程
当分片所在的节点接收到来自协调节点的请求后,会将该请求写入translog,并将文档加入内存缓存。如果请求在主分片上成功处理,该请求会并行发送到该分片的副本上。当translog被同步到全部的主分片及其副本上后,客户端才会收到确认通知。内存缓冲会被周期性刷新(默认是1秒),内容将被写到文件系统缓存的一个新段(segment)上。虽然这个段并没有被同步(fsync),但它是开放的,内容可以被搜索到。每30分钟,或者当translog很大的时候,translog会被清空,文件系统缓存会被同步。这个过程在Elasticsearch中称为冲洗(flush)。在冲洗过程中,内存中的缓冲将被清除,内容被写入一个新段。段的fsync将创建一个新的提交点,并将内容刷新到磁盘。旧的translog将被删除并开始一个新的translog。 - ES如何做到实时检索?
由于在buffer中的索引片先同步到文件系统缓存,再刷写到磁盘,因此在检索时可以直接检索文件系统缓存,保证了实时性。这一步刷到文件系统缓存的步骤,在 Elasticsearch 中,是默认设置为 1 秒间隔的,对于大多数应用来说,几乎就相当于是实时可搜索了。不过对于 ELK 的日志场景来说,并不需要如此高的实时性,而是需要更快的写入性能。我们可以通过 /_settings接口或者定制 template 的方式,加 refresh_interval 参数。 - 当segment从文件系统缓存同步到磁盘时发生了错误怎么办? 数据会不会丢失?
由于Elasticsearch 在把数据写入到内存 buffer 的同时,其实还另外记录了一个 translog日志,如果在这期间故障发生时,Elasticsearch会从commit位置开始,恢复整个translog文件中的记录,保证数据的一致性。等到真正把 segment 刷到磁盘,且 commit 文件进行更新的时候, translog 文件才清空。这一步,叫做flush。同样,Elasticsearch 也提供了 /_flush 接口。 - 索引数据的一致性通过 translog 保证,那么 translog 文件自己呢?
Elasticsearch 2.0 以后为了保证不丢失数据,每次 index、bulk、delete、update 完成的时候,一定触发刷新translog 到磁盘上,才给请求返回 200 OK。这个改变在提高数据安全性的同时当然也降低了一点性能。
检索文档
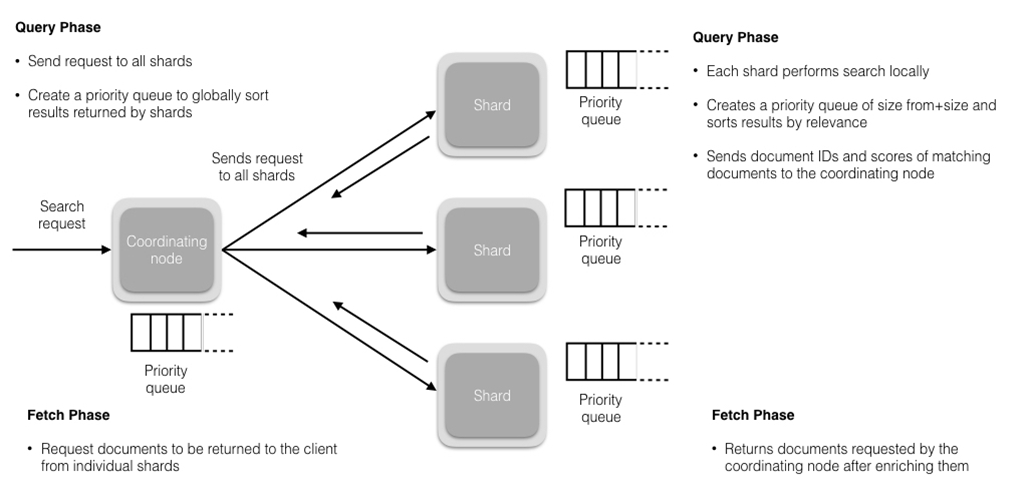
- 搜索相关性
相关性是由搜索结果中Elasticsearch打给每个文档的得分决定的。默认使用的排序算法是tf/idf(词频/逆文档频率)。词频衡量了一个词项在文档中出现的次数 (频率越高 == 相关性越高),逆文档频率衡量了词项在全部索引中出现的频率,是一个索引中文档总数的百分比(频率越高 == 相关性越低)。最后的得分是tf-idf得分与其他因子比如(短语查询中的)词项接近度、(模糊查询中的)词项相似度等的组合。
更新删除索引
- 删除和更新也都是写操作。但是Elasticsearch中的文档是不可变的,因此不能被删除或者改动以展示其变更。那么,该如何删除和更新文档呢?
- 磁盘上的每个段都有一个相应的.del文件。当删除请求发送后,文档并没有真的被删除,而是在.del文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并(我们将在本系列接下来的文章中讲到)时,在.del文件中被标记为删除的文档将不会被写入新段。
- 接下来我们看更新是如何工作的。在新的文档被创建时,Elasticsearch会为该文档指定一个版本号。当执行更新时,旧版本的文档在.del文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
- 物理删除索引:当索引数据不断增长时,对应的segment也会不断的增多,查询性能可能就会下降。因此,Elasticsearch会触发segment合并的线程,把很多小的segment合并成更大的segment,然后删除小的segment,当这些标记为删除的segment不会被复制到新的索引段中。
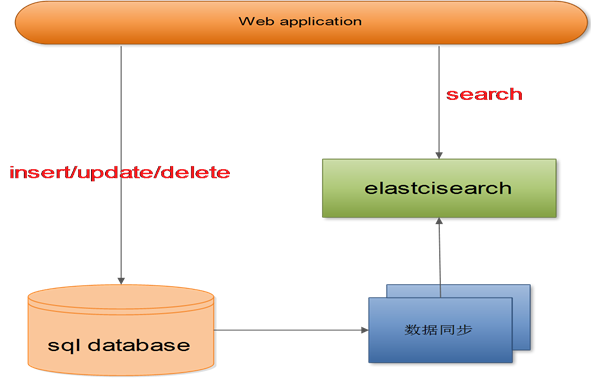
三种使用方式


若有收获,就点个赞吧
0 人点赞
