ClickHouse实践
ClickHouse在字节跳动的实时场景的应用和优化
视频地址:技术沙龙:ClickHouse 在实时场景的应用和优化
早期实践
流程
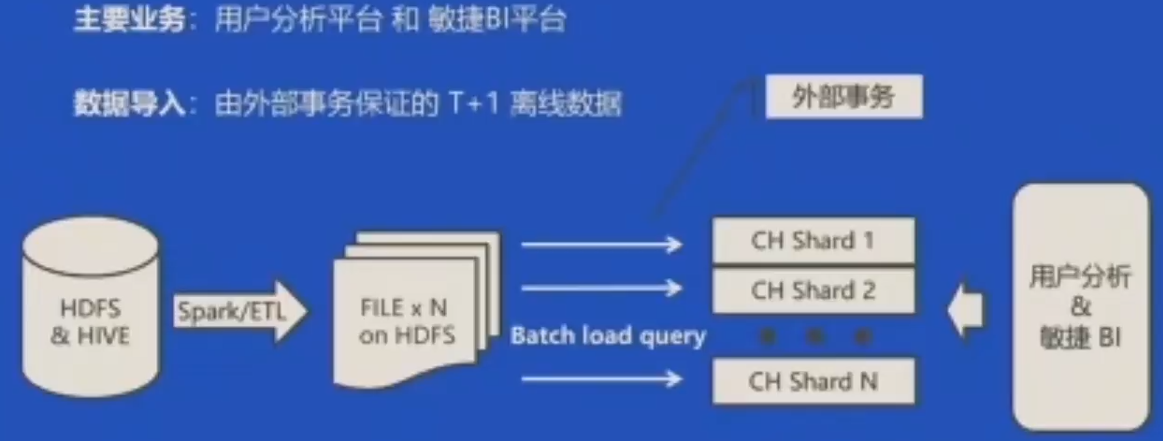
- 数据存储到HDFS或者hive中
- 由Spark或ETL工具,切割数据并进行预处理,然后再存储在HDFS上;
- 通过外部应用调用将文件导入到ClickHouse的Shard中;
- 由外部事务调用是否整个集群的数据完全写入到ClickHouse Shard中,如果失败,一般会需要回滚;
-
出现的问题
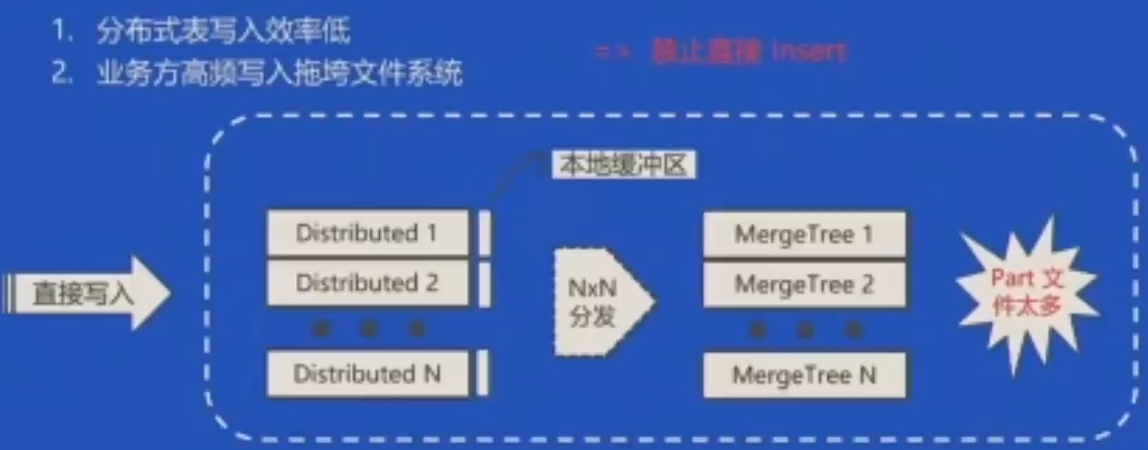
分布式表有缓存区,如果中途宕机,可能出现数据的重复写入,导致数据膨胀;
- 如果由业务方直接写入,可能会由于业务方的频繁操作,导致压力过大,拖垮系统;
典型案例
推荐系统实时指标

- AB指标:指的是AB实验

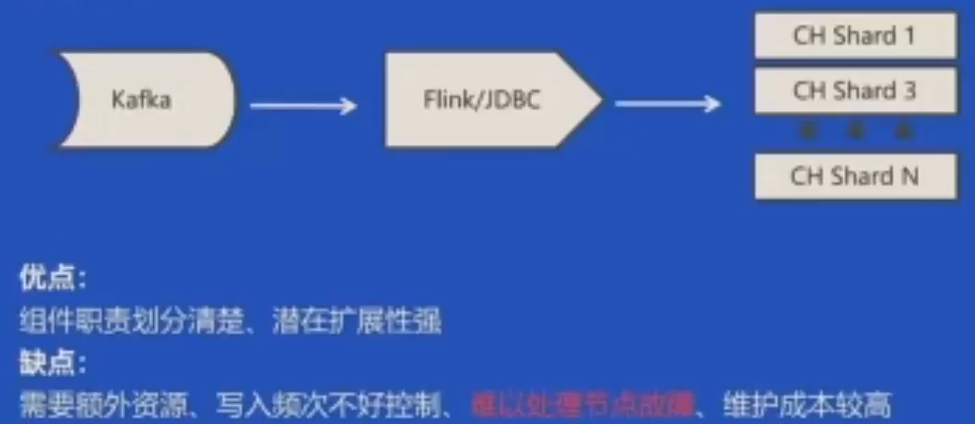
常规方案
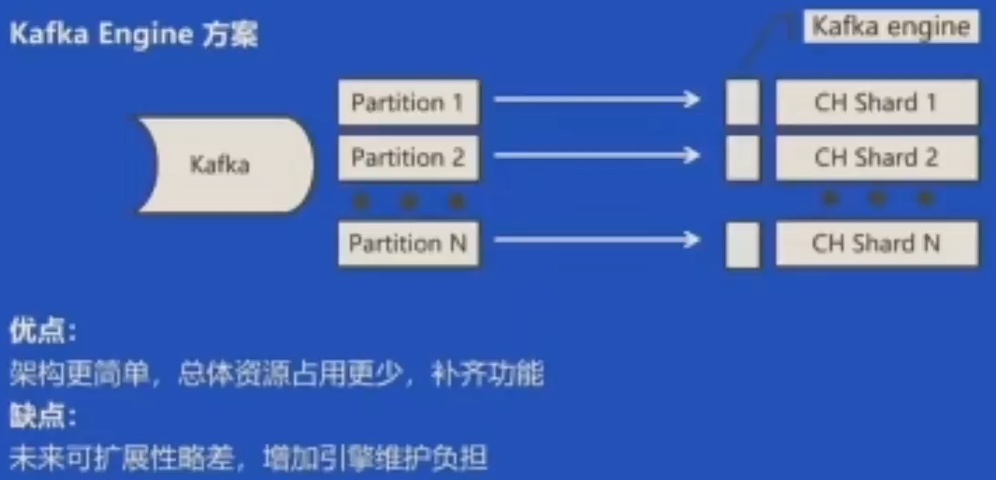
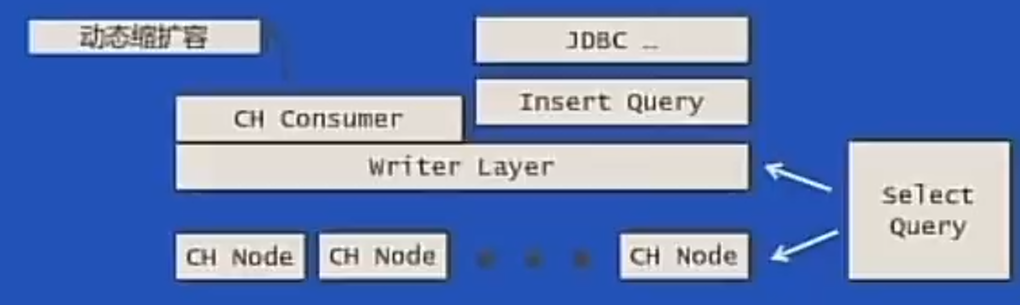
Kafka Engine方案

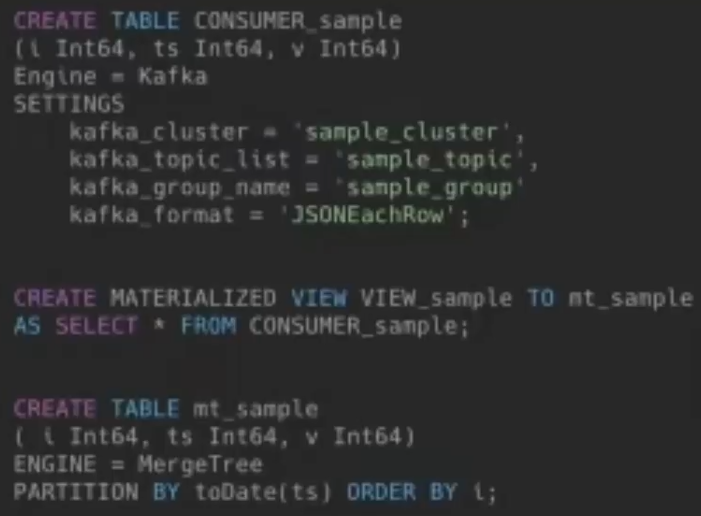
最终方案
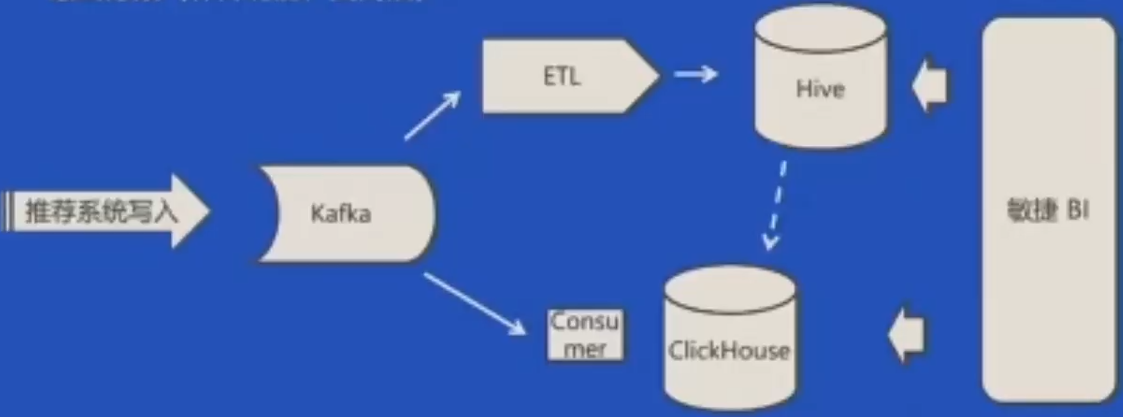
改进1:异步辅助索引

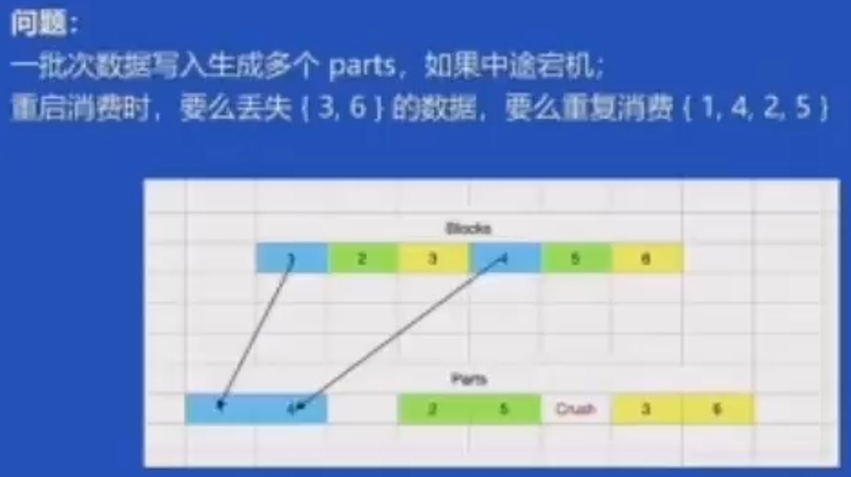
问题:多消费性能不及预期
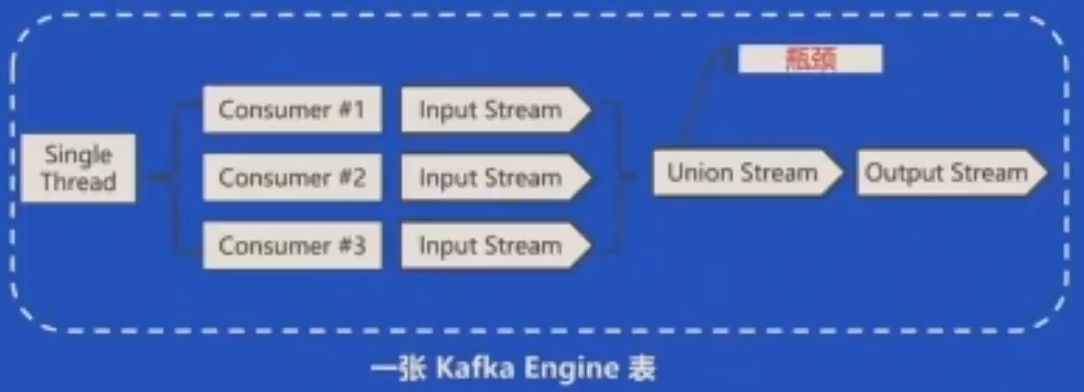
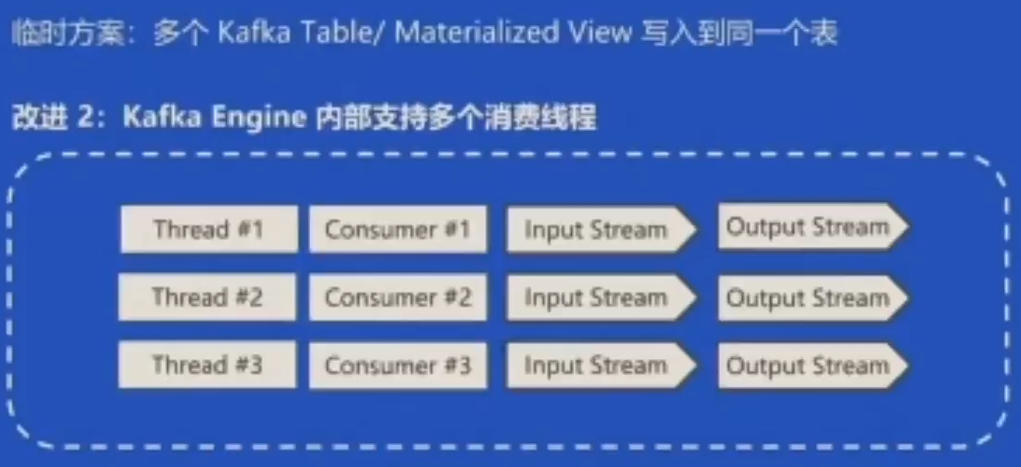
改进2:Kafka Engine内部支持多个消费线程
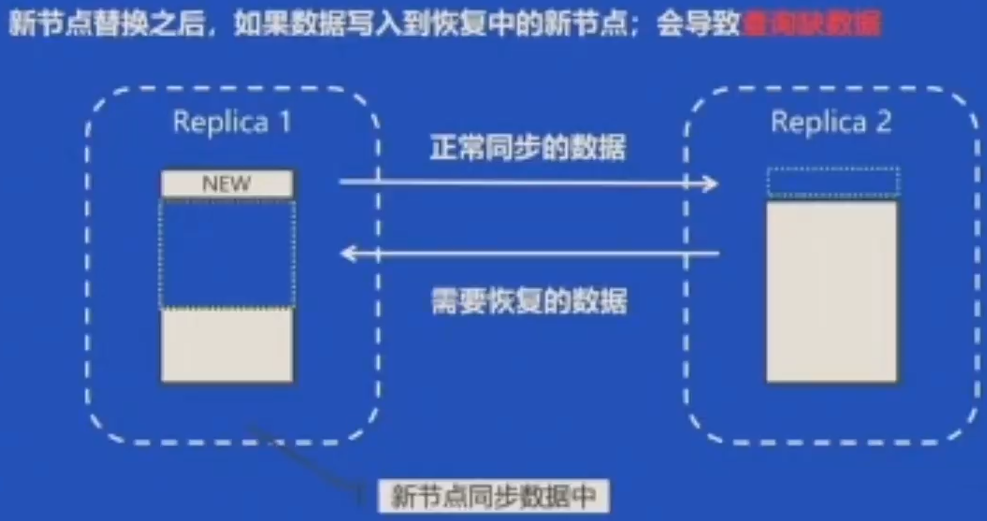
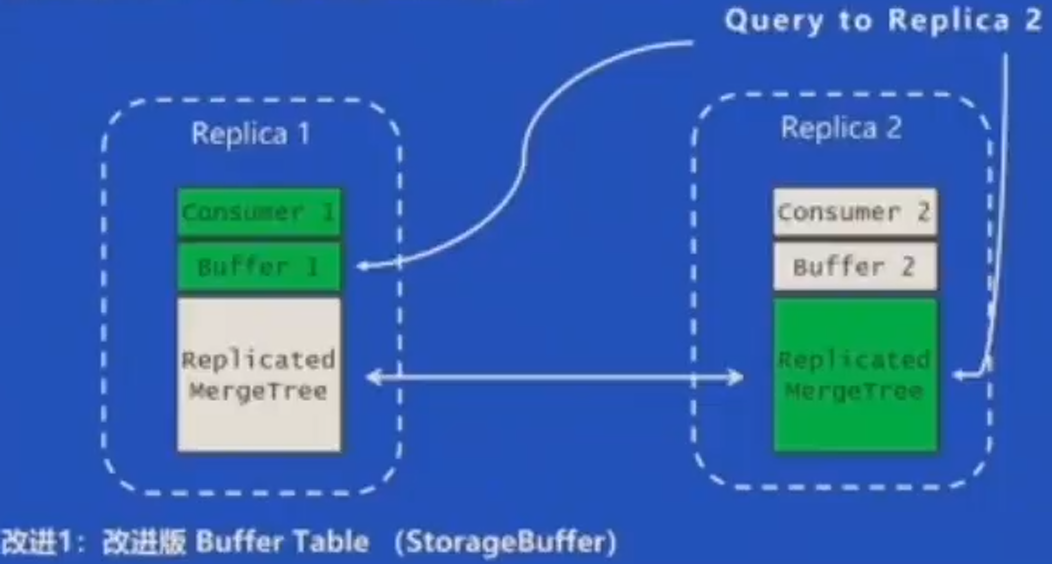
问题:主备节点是否都应该写入数据

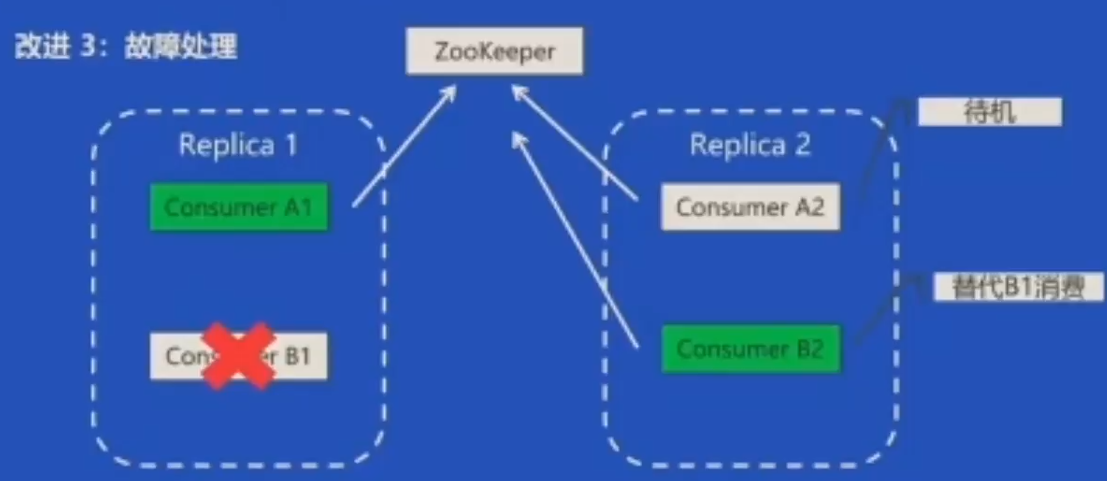
改进3:故障处理
 改进3:主动切换到正常节点消费
改进3:主动切换到正常节点消费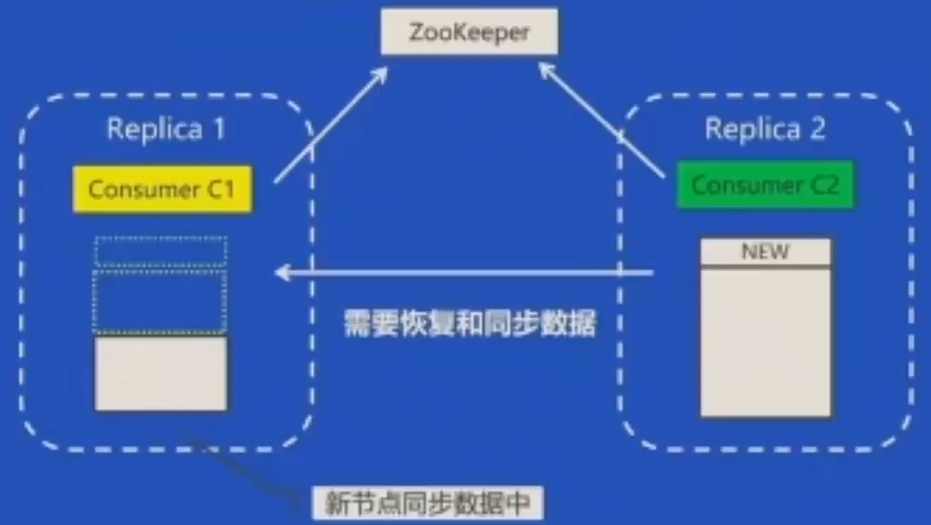

广告投放实时数据


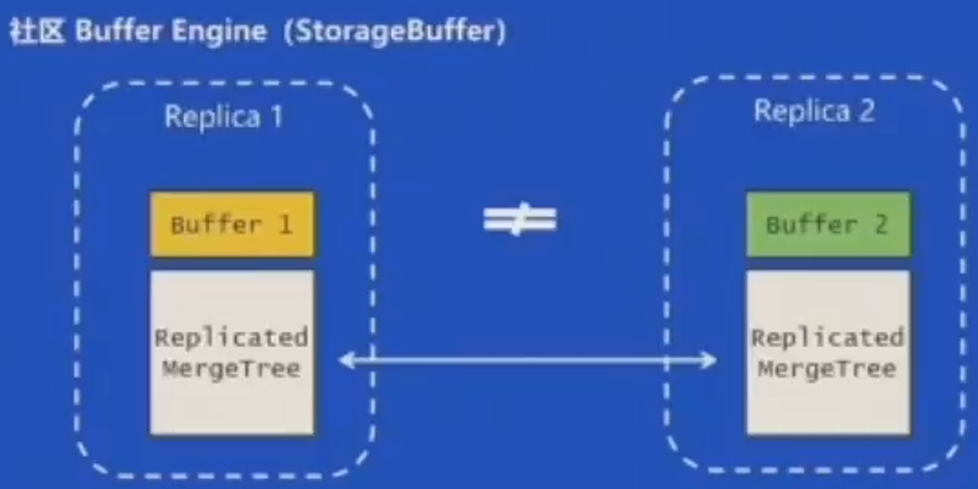



实践 & 经验
1、搭建kafka -> ClickHouse接入平台



2、敏捷BI平台直接支持将Kafka作为数据集
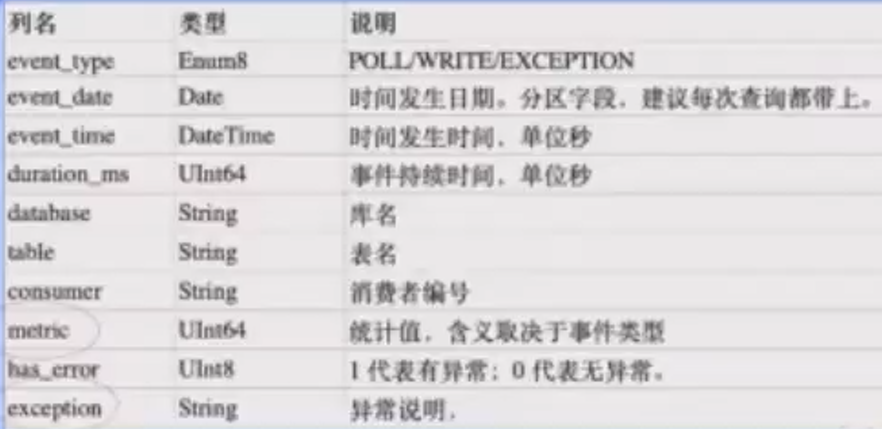
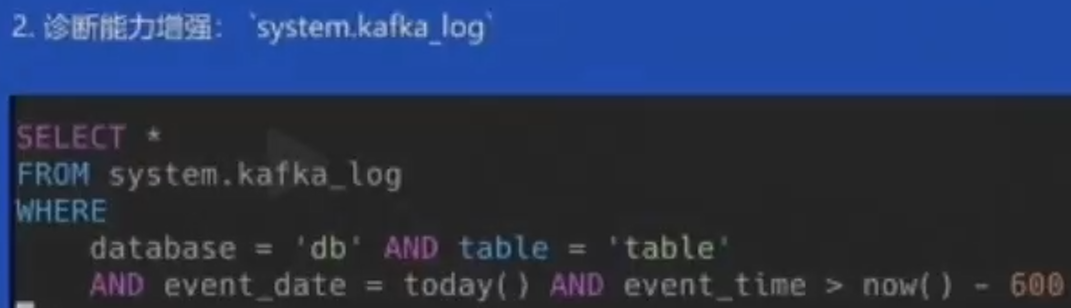
3、诊断能力增强
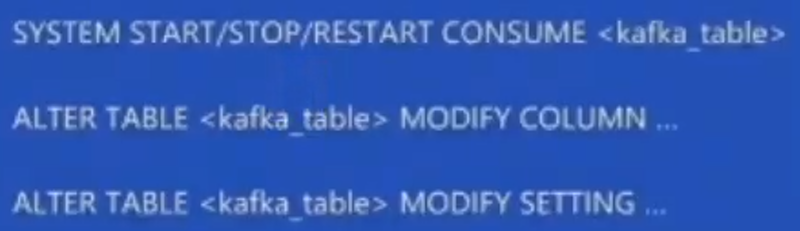
4、实用的运维SQL
总结

未来展望和计划


Q & A
- 将一下实时场景ES和ClickHouse的对比
- ES适应于点查,ClickHouse适应大批量查询
- 如何提高消费Kafka的速度?
- 提高消费者的数量
- kafka的消费和刷盘的监控
- 监控节点的内存,如果占用过多,强制刷盘
- 如何处理Kafka中的脏数据
- 通知业务方,让业务方解决处理(丢弃)

若有收获,就点个赞吧
0 人点赞
