单表查询的的执行方式大致分为两种
- 全表扫描
遍历表,匹配所有符合条件的记录。 - 根据索引查询
使用索引可以细分为:- 针对主键或一二级索引的等值查询
- 针对普通二级索引的等值查询
- 针对索引列的范围查询
- 直接扫描整个索引
实验表结构
mysql> CREATE TABLE single_table (-> id INT NOT NULL AUTO_INCREMENT,-> key1 VARCHAR(100),-> key2 INT,-> key3 VARCHAR(100),-> key_part1 VARCHAR(100),-> key_part2 VARCHAR(100),-> key_part3 VARCHAR(100),-> common_field VARCHAR(100),-> PRIMARY KEY (id),-> KEY idx_key1 (key1),-> UNIQUE KEY idx_key2 (key2),-> KEY idx_key3 (key3),-> KEY idx_key_part(key_part1, key_part2, key_part3)-> ) Engine=InnoDB CHARSET=utf8;Query OK, 0 rows affected (0.11 sec)
上述表定义了 1 个聚簇索引,4个二级索引
- 聚簇索引:id
- idx_key1 二级索引:key1
- idx_key2 唯一二级索引:key2
- idx_key3 二级索引:key3
- idx_key_part 联合索引:key_part1、key_part2、key_part3
模拟1000条数据 Java 代码:DemoTest.java
const(等值比较-查询一条记录)
const 意味着查询是常数级别的,代价可以忽略不计。
SQL 语句如:
## key2 为唯一二级索引
mysql> EXPLAIN SELECT * FROM single_table WHERE key2 = 1\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: single_table
partitions: NULL
type: const
possible_keys: idx_key2
key: idx_key2
key_len: 5
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
通过主键或者唯一二级索引与常数的等值对比 定位一条数据,该查询代价就是常数级别的(const)。
示意图如下,级索引定位然后回表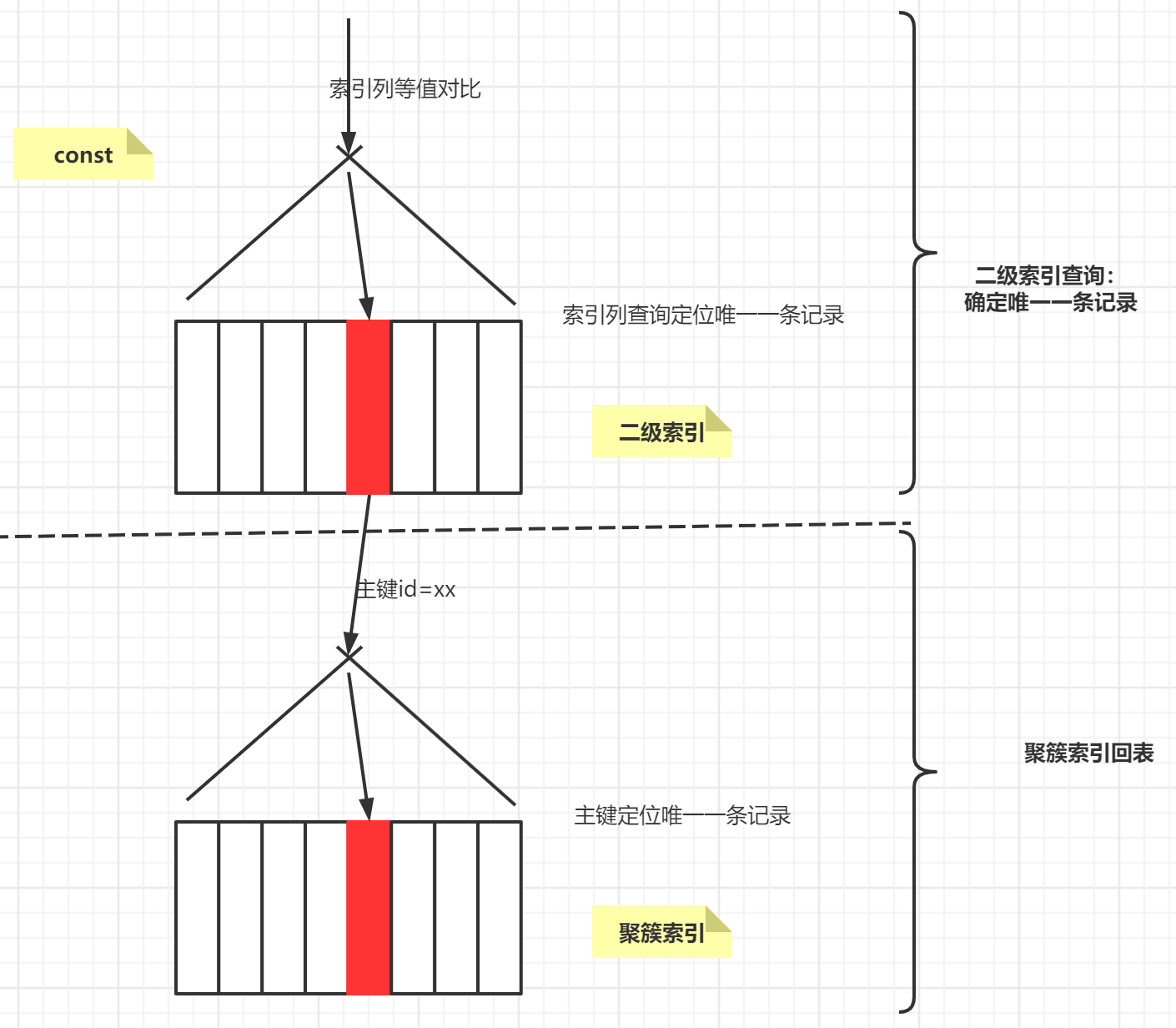
ref(等值比较-查询多条记录)
ref 查询效率比 const 差一点。ref 效率取决于回表的数据量大小。
ref:二级索引所有列一个或者多个采用等值对比(不能有范围查询都需要等值),得到多个查询记录的,查询效率级别为 ref。
SQL语句如:
示意图如下: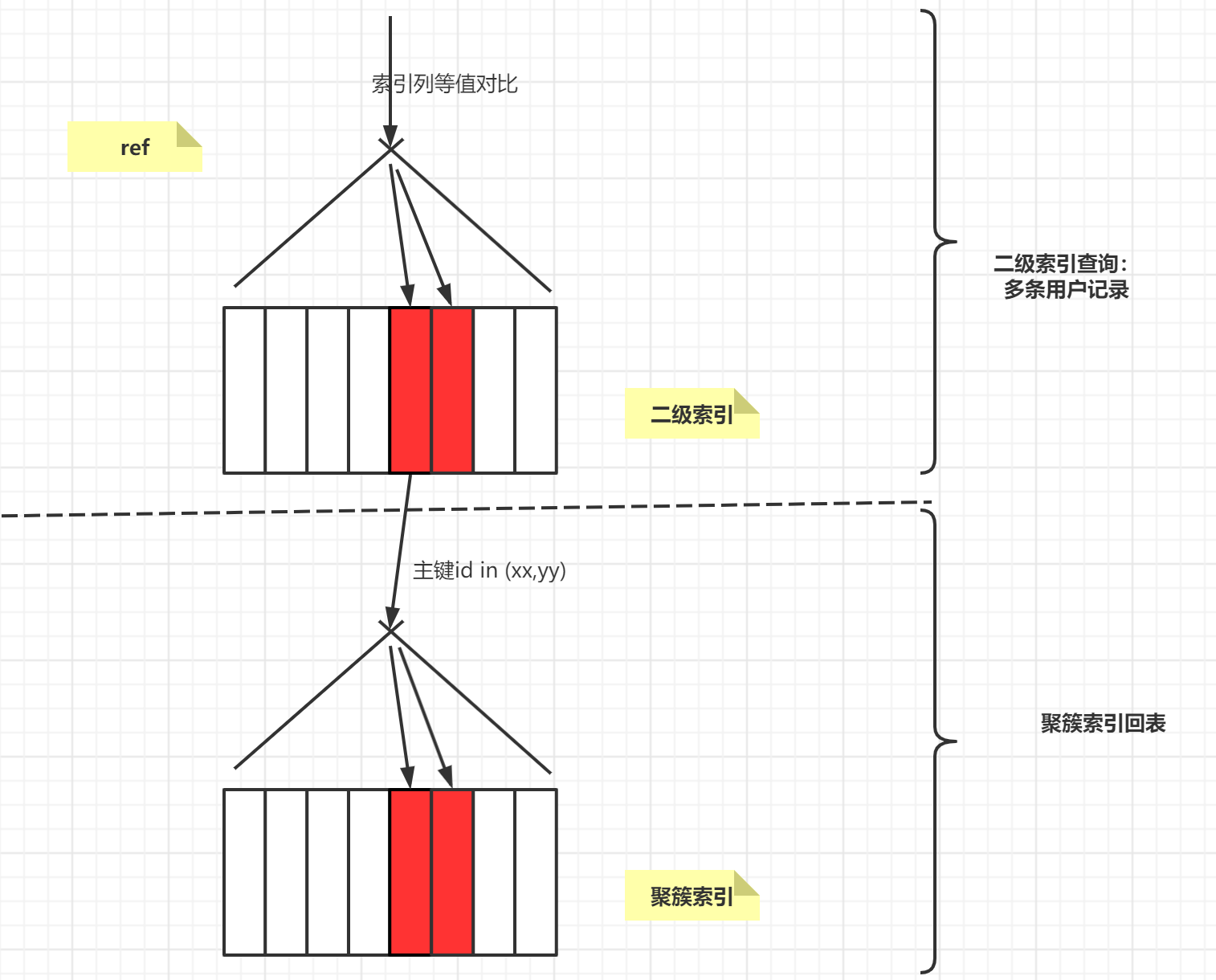
ref_or_null(等值比较+索引列为NULL - 查询多条件记录)
ref_or_null 在 ref 的基础上多出了列为空的查询,同样也是多个查询结果集。效率取决于回表的次数。
SQL语句案例:
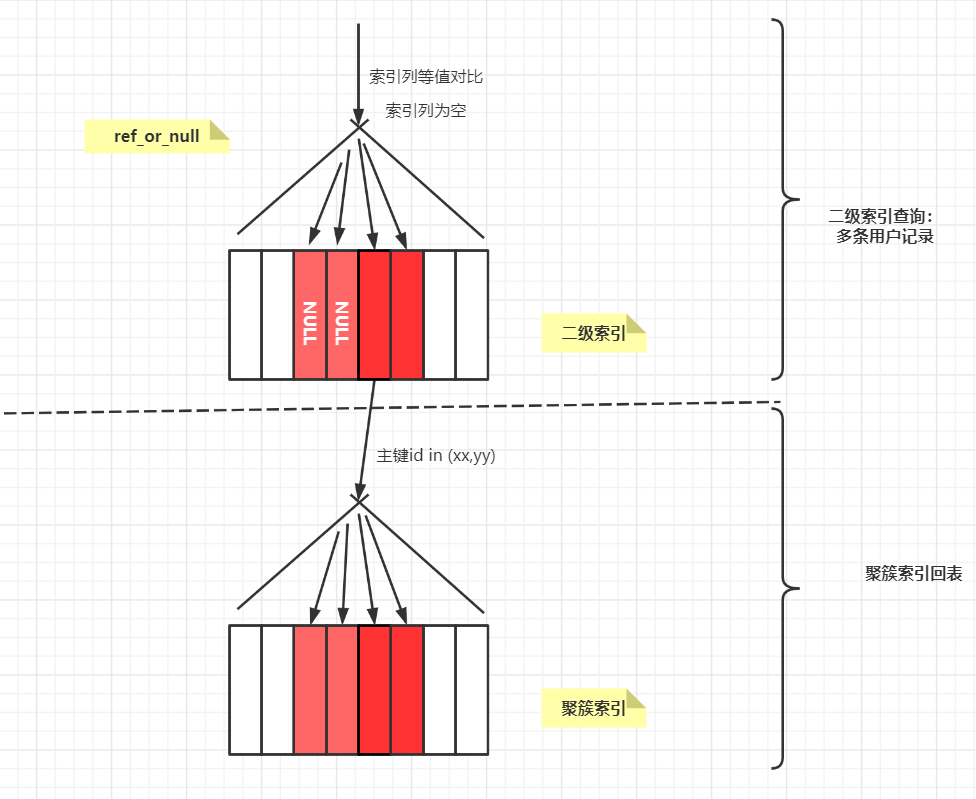
range(范围匹配-查询多条记录)
案例 SQL
mysql> EXPLAIN SELECT * FROM single_table WHERE key2 in (1,3) OR (key2 >= 68 AND key2 <= 86)\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: single_table
partitions: NULL
type: range
possible_keys: idx_key2
key: idx_key2
key_len: 5
ref: NULL
rows: 21
filtered: 100.00
Extra: Using index condition
1 row in set, 1 warning (0.00 sec)
两种范围查询:
- 单节点区间
如案例SQL中的:1,3 - 连续范围区间
如案例SQL中的 [68,86]index(遍历二级索引)
案例 SQL如下
联合索引(二级索引):key_part1,key_part2,key_part3 。mysql> EXPLAIN SELECT key_part1,key_part2,key_part3 FROM single_table WHERE key_part2 = 'abc'\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: single_table partitions: NULL type: index possible_keys: NULL key: idx_key_part key_len: 909 ref: NULL rows: 1001 filtered: 10.00 Extra: Using where; Using index 1 row in set, 1 warning (0.00 sec)
上述 SQL 查询结果:key_part1,key_part2,key_part3 三个字段都是联合索引字段
上述 SQL 查询条件:key_part = ‘abc’ 无法命中联合索引。
上述查询案例的结果集可以直接从联合索引(二级索引)中遍历获取到。因为二级索引的记录比聚簇索引的记录小得多,直接通过遍历二级索引查询得到结果。该方式叫做:index
all(直接扫描聚簇索引)
直接全表扫描,扫描聚簇索引。
索引合并
通常情况下,执行一次查询最多用到单个二级索引。
不过某些特殊场景下会使用到多个索引进行查询,这种查询方式叫做:index_merge (索引合并)。
索引合并算法有三种
- Intersection (交集)合并【AND】
优化器只有在单独根据条件从某个二级索引中获取的记录数太多,导致回表的开销太大,而通过 Intersection 索引合并后的需要回表的记录数大大减小时才会使用 Intersection 索引合并。
可能会使用到 Intercetion 合并的两种情况:
- 情况一:二级索引列是等值匹配(联合索引需要所有列都等匹配)
案例 SQL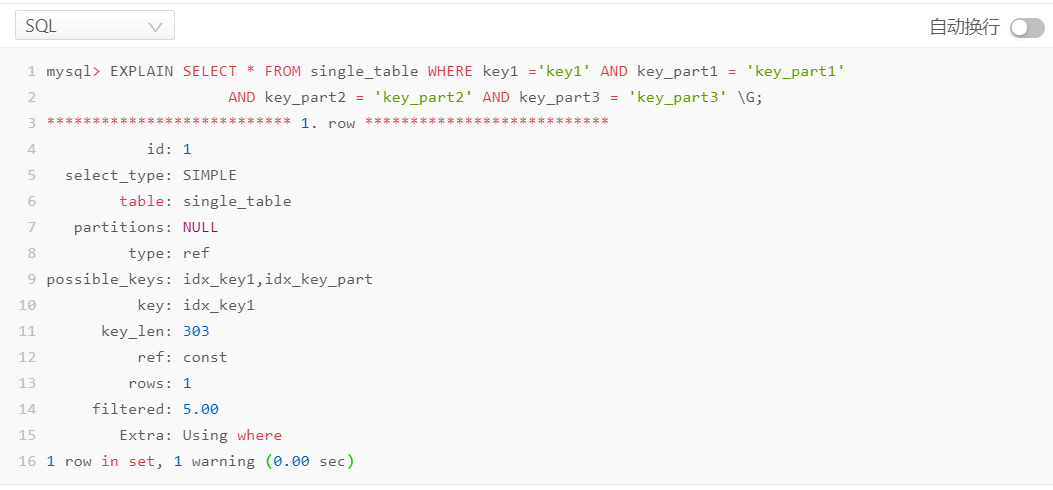
- 情况二:主键列可以是范围匹配
案例SQL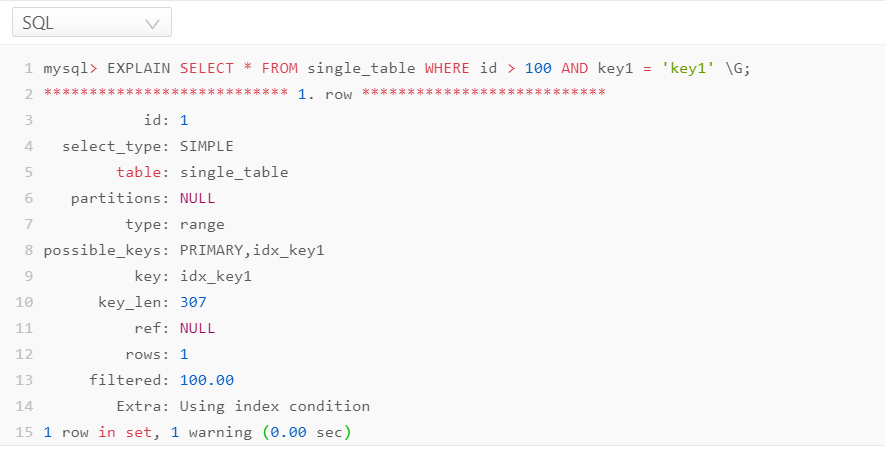
- Union(并集) 合并【or】
优化器只有在单独根据条件从某个二级索引中获取的记录数太多,导致回表的开销太大,而通过 Union索引合并后的需要回表的记录数大大减小时才会使用 Union索引合并。
- Union(并集) 合并【or】
可能使用到 Union 索引合并的三种情况
- 情况一:二级索引列是等值匹配(联合索引需要所有列都等匹配)
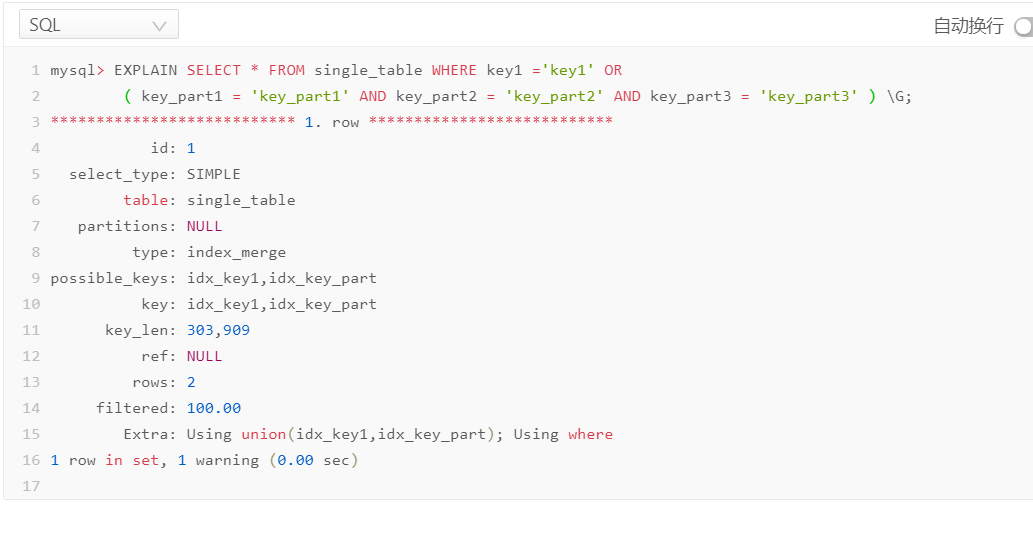
- 情况二:主键列可以是范围匹配
- 情况三:使用 Intersection 索引合并的搜索条件

key_part1,key_part2,key_part3 为联合索引,根据联合索引获取主键id
key1 和 key3 都是二级索引,根据 Intersection 合并获取主键id
将上述两个步骤获取到的主键id集合,通过 Union 合并的方式,获取主键id 然后回表获取查询数据
- Sort-Union 合并
Union 索引合并的使用必须保证各个索引列在进行等值排序的情况下才可能被用到。
不过在某些场景我们有想用到 Union 合并,如下 SQL
SELECT * FROM single_table WHERE key1 > ‘a’ OR key3 > ‘z’
上述查询的结果是我们想要的,但是希望使用 Union 合并的方式提高效率,这时就可以使用 Sort-Union 合并的方式,促使上述的SQL尽可能被用到 Union 合并。
修改:将上述的 key1 > ‘a’ 查询后的结果根据主键进行排序。将上述 key3 >’z’ 查询后的记过根据主键进行排序。

若有收获,就点个赞吧
0 人点赞
