redis诞生历程
redis的作者是antirez,为什么叫redis?是远程字典服务的缩写(Remote Dictionary Service)。
redis支持的数据类型
redis支持5种简单数据类型,分别是string,list,hash,set,zset
此外还有几种复杂类型:geo,hyperloglog,streams
string
string即字符串类型,在redis中是通过一种叫做SDS的数据结构实现(Simple Dynamic String)。
其可用来存储int(64位),float(单精度浮点型),string(sds)
示例:string类型存储不同类型及其编码格式
int类型(带符号)不超过最大值时按int类型存储,超过是按embstr存储
127.0.0.1:6379> set key1 1OK127.0.0.1:6379> object encoding key1"int"127.0.0.1:6379> set key1 9223372036854775807OK127.0.0.1:6379> object encoding key1"int"127.0.0.1:6379> set key1 9223372036854775808OK127.0.0.1:6379> object encoding key1"embstr"
float,直接按embstr格式存储
127.0.0.1:6379> set key2 1.5
OK
127.0.0.1:6379> object encoding key2
"embstr"
普通小字符串存储格式按embstr格式,若对字符串进行append操作则会升级为raw
127.0.0.1:6379> set key3 abcdefg
OK
127.0.0.1:6379> object encoding key3
"embstr"
127.0.0.1:6379> append key3 h
(integer) 8
127.0.0.1:6379> object encoding key3
"raw"
针对string类型的value长度超过embstr的阈值则按raw格式存储,value长度超过44个字节。
127.0.0.1:6379> set bigkey 12345678901234567890123456789012345678901234
OK
127.0.0.1:6379> object encoding bigkey
"embstr"
127.0.0.1:6379> set bigkey 123456789012345678901234567890123456789012345
OK
127.0.0.1:6379> object encoding bigkey
"raw"
为什么是44?
首先RedisObject对象头结构体,其占用了(4+4+24+48+88= 16[bytes]),占用16字节。
struct RedisObject {
int4 type; // 4bits 不同对象有不同的类型
int4 encoding; // 4bits 同一个类型会有不同的存储形式
int24 lru; // 24bits 记录LRU信息
int32 refcount; // 4bytes 当对象引用计数为0时,对象被销毁
void *ptr; // 8bytes,64-bit system 指向对象内容的具体存储位置
} robj;
对于*ptr指向的SDS对象,属性占用3个字节
struct SDS {
int8 capacity; // 1byte
int8 len; // 1byte
int8 flags; // 1byte
byte[] content; // 内联数组,长度为 capacity
}
以上可知:分配一个字符串的最小空间占用(对象头属性信息)为16bytes+3bytes=19bytes。
在内存分配器 jemalloc/tcmalloc 中,分配内存大小的单位都是 2、4、8、16、32、64 字节等,为了容纳一个完整的embstr对象,则至少分配32字节的空间。
如果总体超过了64字节的空间,那么我们认为就是一个大的字符串了,就使用raw来存储了。
SDS结构体中的字符串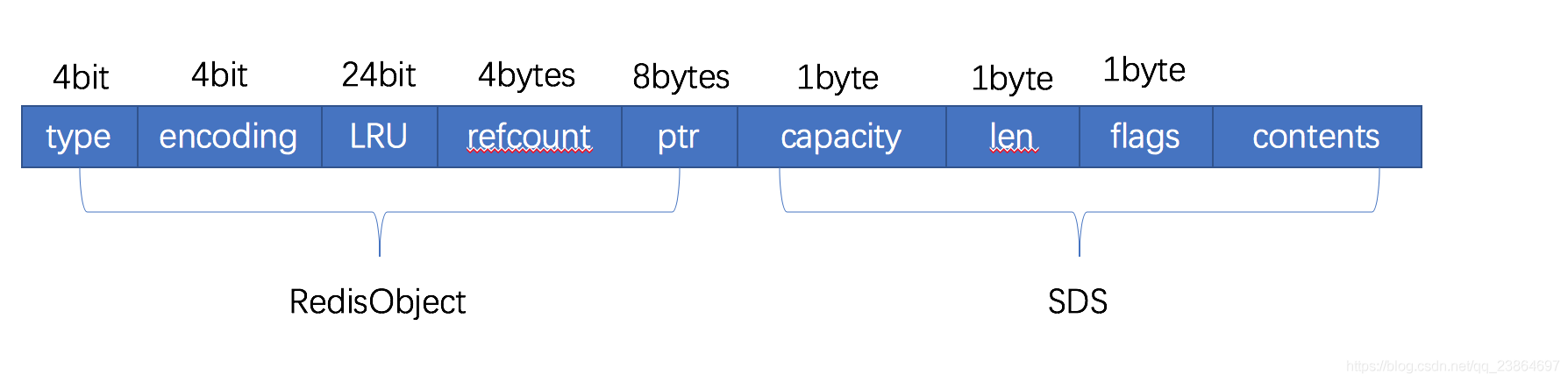
又因为字符串以\0结尾,所以embstr最大能容纳的字符创长度为64 - 19 - 1 = 44bytes。
embstr和raw存储的异同
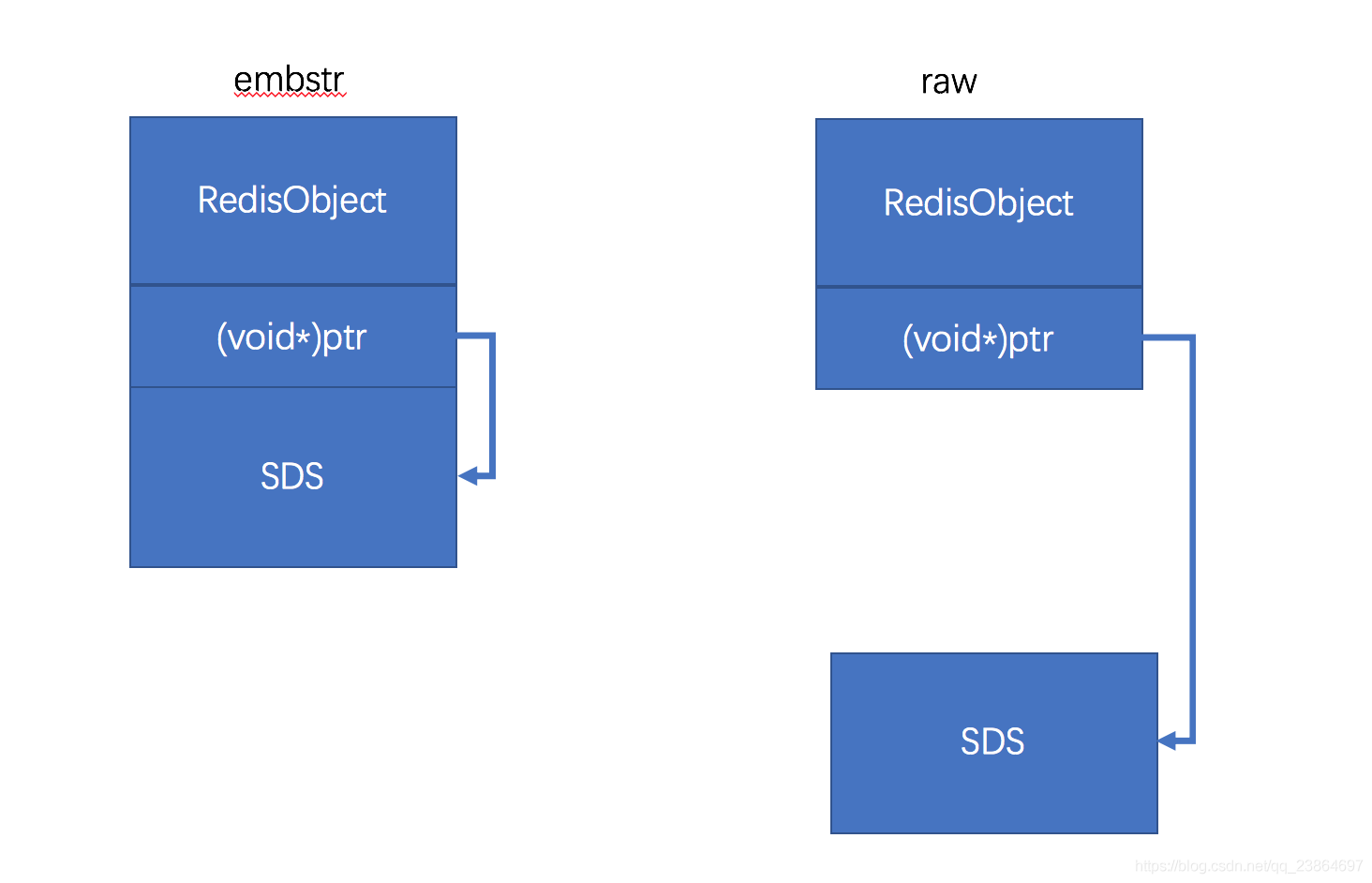
可见区别在于embstr是对象头和SDS是紧凑存储,raw是松散存储。
特点:
- embstr将对象头和SDS对象连续存储在一起,使用malloc方法一次分配。
raw的对象头和SDS对象需要两次malloc分配,两个对象头在内存地址上一般是不连续的。
hash
hash是用来存储多个无序的键值对。hash的value只能存储字符串(也能存储数字,并累加)
使用hash注意的点:1. **field不能单独设置过期时间** 1. **单个key的field很多时无法分布到多个节点**
hash底层原理数据结构可以又两种类型实现
1.ziplist OBJ_ENCODING_ZIPLIST — 压缩列表
2.hashtable OBJ_ENCODING_HT — 哈希表
ziplist
ziplist是经过特殊编码的,由连续内存块组成的双向链表。
- lbytes: ziplist的长度(单位: 字节),是一个32位无符号整数
- zltail: ziplist最后一个节点的偏移量,反向遍历ziplist或者pop尾部节点的时候有用。
- zllen: ziplist的节点(entry)个数
- entry: 节点
zlend: 值为0xFF,用于标记ziplist的结尾
typedef struct ziplist{ /*ziplist分配的内存大小*/ uint32_t bytes; /*达到尾部的偏移量*/ uint32_t tail_offset; /*存储元素实体个数*/ uint16_t length; /*存储内容实体元素*/ unsigned char* content[]; /*尾部标识*/ unsigned char end; }ziplist;对于单个entry:
每个节点由三部分组成:prevlength、encoding、dataprevlengh: 记录上一个节点的长度,为了方便反向遍历ziplist
- encoding: 当前节点的编码规则,下文会详细说
- data: 当前节点的值,可以是数字或字符串
zlentry内部记录了诸多偏移量及长度,就是为了在遍历时方便查找下一个元素typedef struct zlentry { /*前一个元素长度需要空间和前一个元素长度*/ unsigned int prevrawlensize, prevrawlen; /*元素长度需要空间和元素长度*/ unsigned int lensize, len; /*头部长度即prevrawlensize + lensize*/ unsigned int headersize; /*元素内容编码*/ unsigned char encoding; /*元素实际内容*/ unsigned char *p; }zlentry;
为了节省空间,ziplist结构是采用了遍历计算等时间换空间的策略。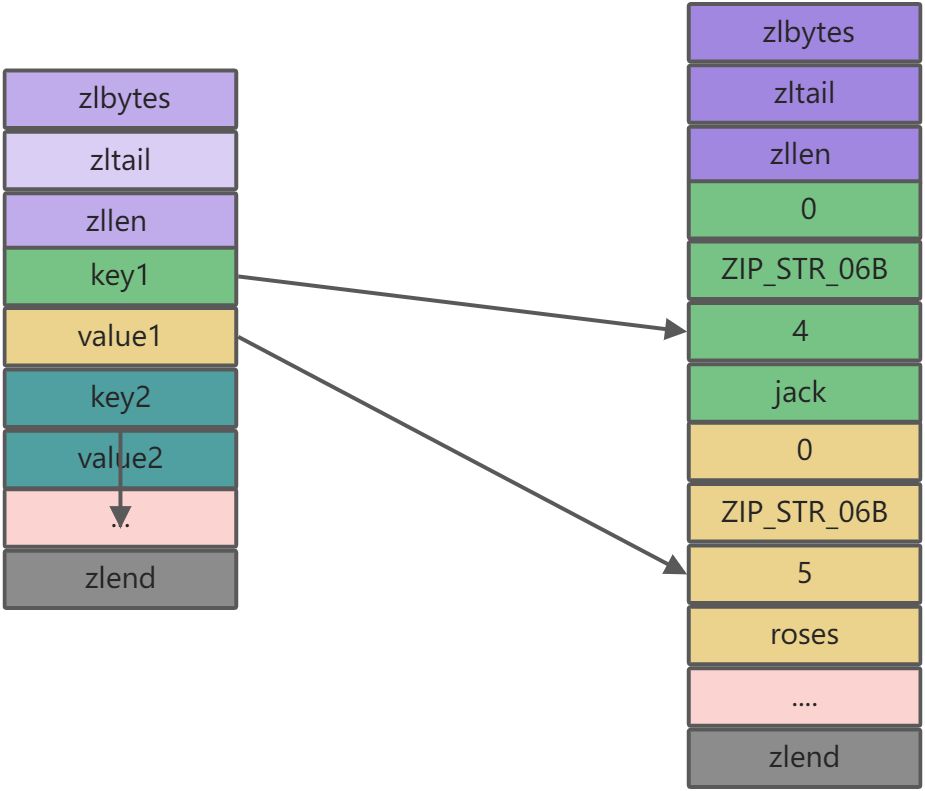
什么时候使用ziplist?
在元素个数较少,并且各个键值对的key和value的长度都小于一定的阈值时使用ziplist
即:元素个数小于512,并且各个兼职对的k,v长度都小于64时127.0.0.1:6379> config get hash* 1) "hash-max-ziplist-entries" 2) "512" 3) "hash-max-ziplist-value" 4) "64"
示例:
可见,当我们设置127.0.0.1:6379> config set hash-max-ziplist-value 10 OK 127.0.0.1:6379> hmset ht a 1 b 2 c 3 OK 127.0.0.1:6379> object encoding ht "ziplist" 127.0.0.1:6379> hmset ht d 1234567890 OK 127.0.0.1:6379> object encoding ht "ziplist" 127.0.0.1:6379> hmset ht e 12345678901 OK 127.0.0.1:6379> object encoding ht "hashtable" 127.0.0.1:6379> hset ht e 1234 (integer) 0 127.0.0.1:6379> object encoding ht "hashtable"hash-max-ziplist-value=10时,hash结构中有value长度超过10时转换为了hash表,且不可逆。list
redis中的lists在底层实现上并不是数组,而是链表,也就是说对于一个具有上百万个元素的lists来说,在头部和尾部插入一个新元素,其时间复杂度是常数级别的,比如用LPUSH在10个元素的lists头部插入新元素,和在上千万元素的lists头部插入新元素的速度应该是相同的。但是,也就意味着遍历时比较慢。
在早期版本中,list根据元素的个数分别用ziplist和linkedlist实现,但是在3.2版本之后统一使用quicklist实现,quicklist内部的每个节点是通过ziplist实现,然后每个节点再连接双向连接起来,形成双向链表。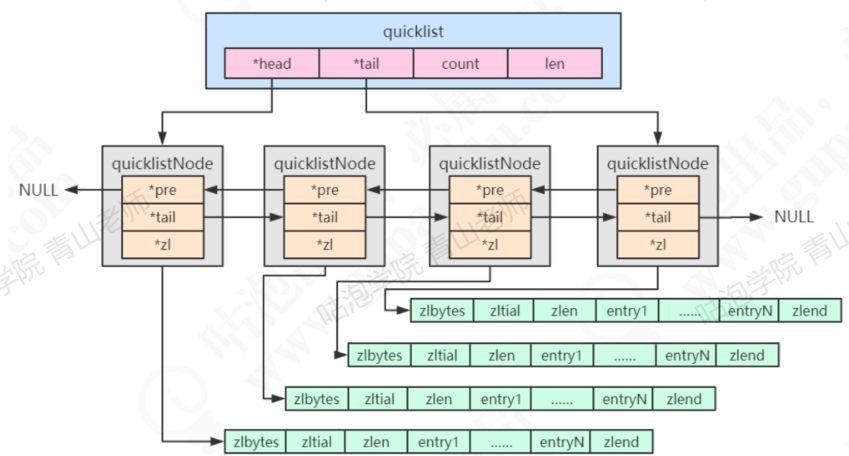
链表和ziplist的取舍及优缺点?
- 双向链表便于在表的两端进行push和pop操作,但是它的内存开销很大。开销如下
a. 每个节点上除了要保存数据之外,还要额外的保存两个指针。
b. 各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。 - ziplist是一块连续的内存,所以存储效率很高。但是,它不利于修改操作,每次数据变动都会引发内存的realloc。一次realloc可能会导致大量的数据拷贝,进一步降低性能。
quicklist结合了双向链表和ziplist的优点,但是同样也存在一个问题,一个quicklist包含多长的ziplist合适呢?需要找到一个平衡点
redis提供了配置参数
127.0.0.1:6379> config get list*
1) "list-max-ziplist-size"
2) "-2"
3) "list-compress-depth"
4) "0"
list-max-ziplist-size :
取正值时表示quicklist节点ziplist包含的数据项。取负值表示按照占用字节来限定quicklist节点ziplist的长度。
-5: 每个quicklist节点上的ziplist大小不能超过64 Kb。
-4: 每个quicklist节点上的ziplist大小不能超过32 Kb。
-3: 每个quicklist节点上的ziplist大小不能超过16 Kb。
-2: 每个quicklist节点上的ziplist大小不能超过8 Kb。(默认值)
-1: 每个quicklist节点上的ziplist大小不能超过4 Kb。
list-compress-depth
取值含义:<br /> 0: 是个特殊值,表示都不压缩。这是Redis的默认值。<br /> 1: 表示quicklist两端各有1个节点不压缩,中间的节点压缩。<br /> 2: 表示quicklist两端各有2个节点不压缩,中间的节点压缩。<br /> 以此类推
Set
set是存储的无序的String集合,redis使用intset或者hashtable来存储set,如果元素都是整数就用intset存储。
如果整数的元素个数超过一定数量也会采用hashtable存储
127.0.0.1:6379> config get set*
1) "set-max-intset-entries"
2) "512"
Zset
ZSet数据结构类似于Set结构,只是ZSet结构中,每个元素都会有一个分值,然后所有元素按照分值的大小进行排列,相当于是一个进行了排序的链表。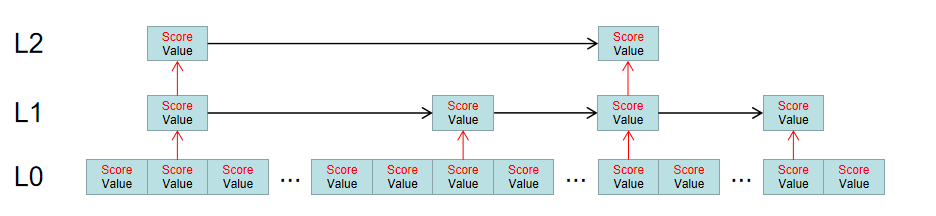
如存在以下分值的元素(未注明元素):
这种跳跃表的实现,其实和二分查找的思路有点接近,只是一方面因为二分查找只能适用于数组,而无法适用于链表,所以为了让链表有二分查找类似的效率,就以空间换时间来达到目的。
跳跃表因为是一个根据分数权重进行排序的列表,可以再很多场景中进行应用,比如排行榜,搜索排序等等。

若有收获,就点个赞吧
0 人点赞
