目标检测也能用神经架构搜索,这是一个自动搜索的特征金字塔网络。
神经架构搜索已经在图像识别上展现出很强的能力,不论是可微架构搜索的速度,还是基于强化学习搜索的准确度,很多时候自动架构搜索已经超越了我们手动设计的版本。与此同时,学习视觉的特征表示是计算机视觉中的一个基本问题。不论是图像分类还是目标检测,抽取图像特征才是最首要的。<br />NAS是一种有很大灵活性的框架,与各种骨干模型配合的更好,如mobilenet等。在移动端模型和高准确率模型在速度和准确率方面都取得了更好的权衡。<br />在相同的推理时间下,与 RetinaNet 框架中的 MobileNetV2 骨干模型相结合,它的性能超过当前最佳的移动检测模型(与 MobilenetV2 结合的 SSDLite)2 个 AP。与强大的 AmoebaNet-D 骨干模型结合,NASFPN 在单个测试规模中达到了 48.3 的 AP 单模型准确率。其检测准确率超过了 Mask RCNN,同时使用的推理时间更少。几种模型的具体结果如图 1 所示。<br />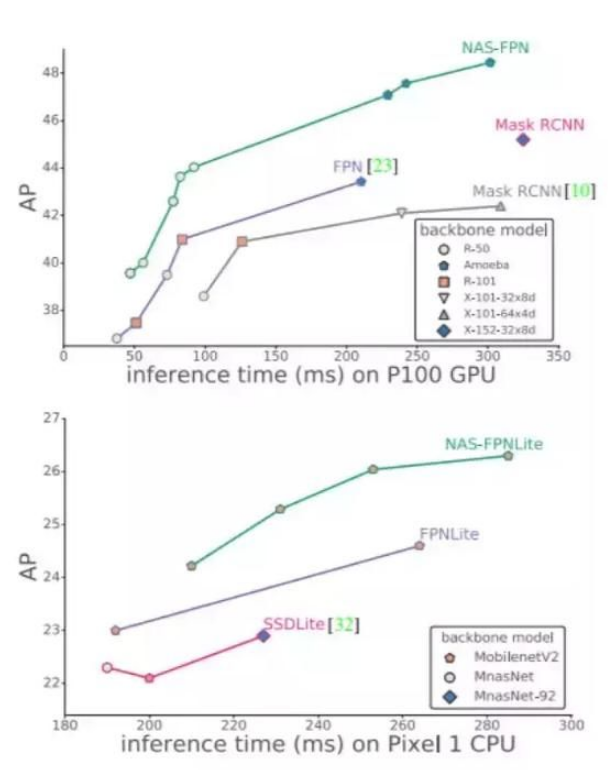<br />摘要:当前最先进的目标检测卷积架构都是人工设计的。在这项工作中,我们的目标是学习更好的目标检测特征金字塔网络架构。我们采用了神经架构搜索,在一个包含所有跨尺度连接的新的可扩展搜索空间中发现了一个新的特征金字塔架构。这个名为 NAS-FPN 的架构包含自上而下和自下而上的连接,以融合各种尺度的特征。NAS-FPN 与 RetinaNet 框架中的若干骨干模型相结合,实现了优于当前最佳目标检测模型的准确率和延迟权衡。该架构将移动检测准确率提高了 2 AP,优于 [32] 中的当前最佳模型——与 MobileNetV2 相结合的 SSDLite,达到了 48.3 AP,超越了 Mask R-CNN [10] 的检测准确率,且计算时间更少。
方法
本文中的方法基于 RetinaNet 框架 [23],因为该框架简单、高效。RetinaNet 框架有两个主要的组成部分:一个骨架网络(通常是当前最优的图像分类网络)和一个特征金字塔网络(FPN)。本文算法的目标是为 RetinaNet 框架发现更好的 FPN 架构。图 2 所示为 RetinaNet 架构。
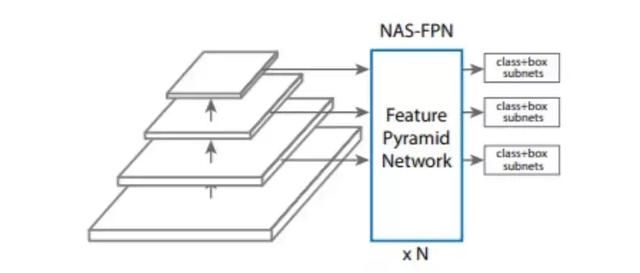
图 2:带有 NAS-FPN 的 RetinaNet。在本文中,特征金字塔网络将由神经架构搜索算法来搜索。骨干网络和用于类和框预测的子网络遵循 RetinaNet [23] 中的原始设计。FPN 的架构可以堆叠多次,以获得更高的准确率。
为了找到更好的 FPN,研究者利用 Quoc Le 等人在「Neural architecture search with reinforcement learning」中提出的神经架构搜索(NAS)框架。NAS 利用强化学习训练控制器在给定的搜索空间中选择最优的模型架构。控制器利用子模型在搜索空间中的准确度作为奖励信号来更新其参数。因此,通过反复试验,控制器逐渐学会了如何生成更好的架构。
研究者还为 FPN 设计了一个搜索空间来生成特征金字塔表征。为了实现 FPN 的可扩展性,研究者强制 FPN 在搜索过程中重复 N 次,然后连接到一个大型架构中。他们将这一特征金字塔架构命名为 NAS-FPN。
实验
这一部分描述了学习一个 RNN 控制器来发现 NAS-FPN 架构的神经架构搜索实验。然后,研究者证明了他们发现的 NAS-FPN 在不同的骨干模型和图像大小下都能很好地工作。在金字塔网络中,通过改变叠加层数和特征维数,可以很容易地调整 NAS-FPN 的容量。此外,作者还在实验中展示了如何构建准确、快速的架构。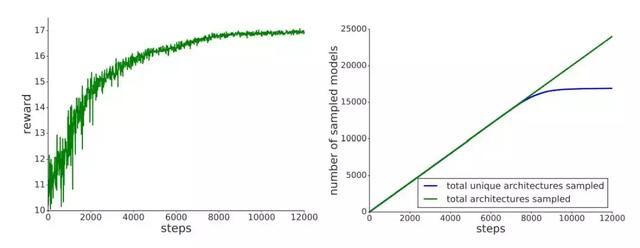
图 5:左:强化学习训练的奖励。计算奖励的方法为在代理任务上采样架构的 AP。右:采样的独特架构数与架构总数。随着控制器逐渐收敛,控制器会采样到越来越多的相同架构。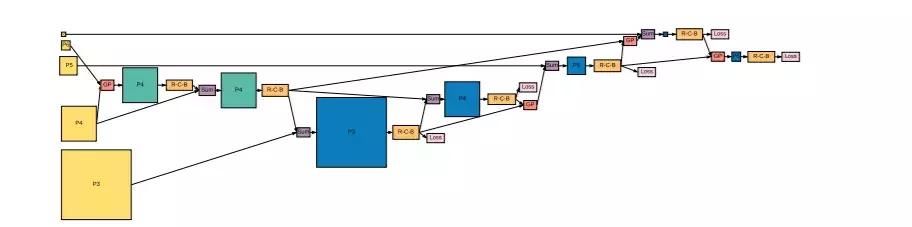
图 6:5 个输入层(黄色)和 5 个输出特征层(蓝色)的 NAS-FPN 中发现的 7-merging-cell 金字塔网络架构。GP:全局池化;R-C-B:ReLU-Conv-BatchNorm。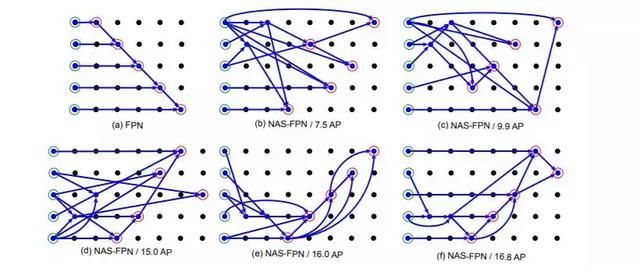
图 7:NAS-FPN 的架构图。每个点代表一个特征层,同一行的特征层具有相同的分辨率,分辨率由下往上递减。箭头表示内层之间的连接,该图的结构是输入层位于左侧。金字塔网络的输入用绿色圆圈标记,输出用红色圆圈标记。(a)基线 FPN 架构。(b~f)在 RNN 控制器的训练中通过神经架构搜索发现的 7-cell NAS-FPN 架构。(f)实验中最后收敛得出的 NAS-FPN。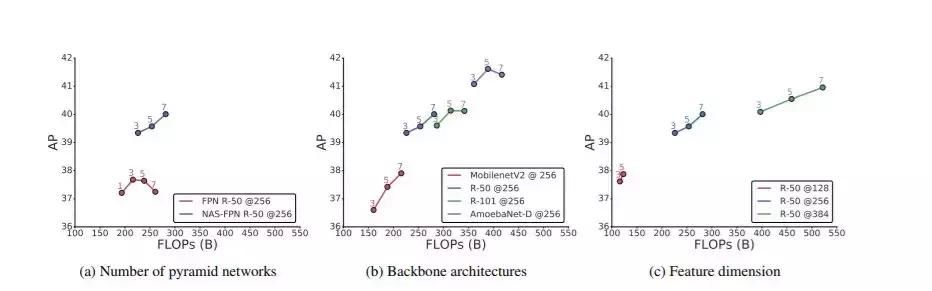
图 8:NAS-FPN 的模型容量。(a)叠加金字塔网络,(b)改变骨干架构,(c)增加金字塔网络中的特征维度。所有的模型都是在 640x640 的图像大小上训练/测试的。标记上方的数字表示在 NAS-FPN 中金字塔网络的数量。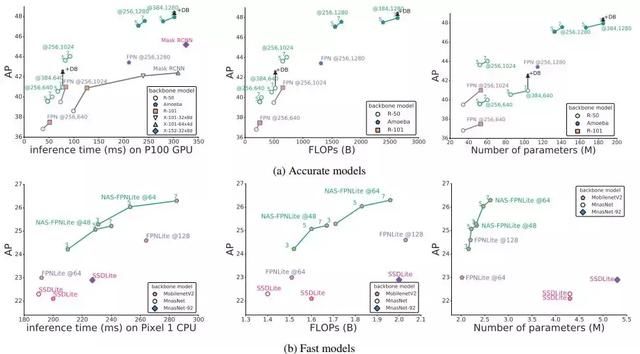
图 9:检测准确率和推理时间的折衷(左)、浮点数(中)、参数(右)。(a)研究者将其与其他高准确率模型进行了对比。所有模型的推理时间都是在一个搭载 P100 GPU 的设备上计算出来的。绿色折线显示的是拥有不同骨干架构的 NAS-FPN 结果。该标记上的数字表示在 NAS-FPN 中金字塔网络的重复次数。在每个数据点旁边都表明了 NAS-FPN/FPN 的特征维数和输入图像大小。(b)研究者将自己的模型与其他快速模型进行了对比,其中所有模型的输入图像大小为 320x320,推理时间是在 Pixel 1 CPU 上计算的。本文中的模型是用 MobileNetV2 的轻型模型训练的。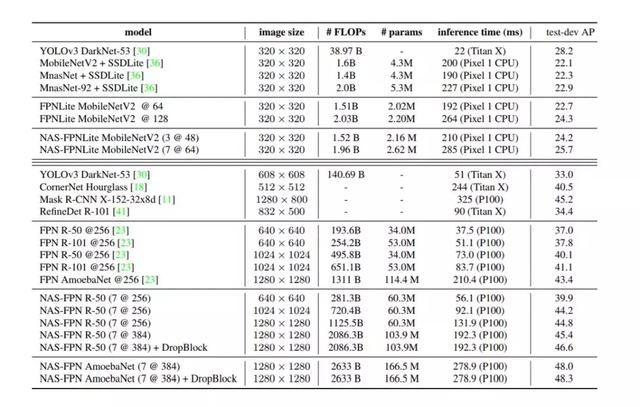
表 1:NAS-FPN 和其他当前最优检测器在 COCO 测试数据集上的性能表现。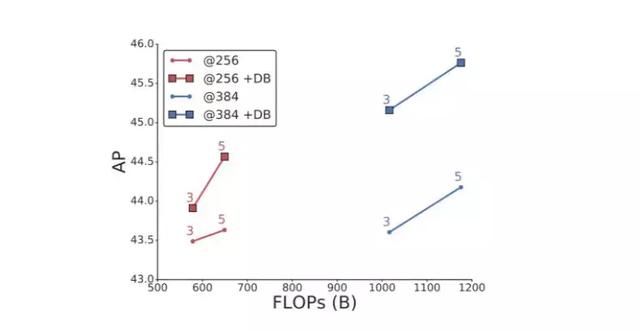
图 10:特征维数为 256 或 384 的 NAS-FPN 在训练时有无 DropBlock (DB) 的性能对比。模型和 ResNet-50 骨干模型在大小为 1024x1024 的图像上训练。当我们在金字塔网络中增加特征维数时,添加 DropBlock 变得更重要。

若有收获,就点个赞吧
0 人点赞
