我们知道,Hadoop主要有分布式文件系统HDFS、分布式计算框架MapReduce、和分布式集群资源管理框架 Yarn构成。那么什么是Yarn 呢?
Yarn 的发展
学习MapReduce架构,我们知道,在MapReduce应用程序启动过程中,最重要的是把MapReduce程序分发到大数据集群的服务器上,在Hadoop 1中,这个过程主要通过TaskTrack 和JobTrack 通信来完成。
那么,这种方案的缺点也是显然的,服务器集群资源调度管理和 MapReduce 执行过程耦合在一起,如果想在当前集群中运行其他计算任务,比如 Spark 或者 Storm,就无法统一使用集群中的资源了。所以随着大数据的发展
各种新的计算框架不断出现,我们不可能为每一种计算框架部署一个服务器集群,而且就算能部署新集群,数据还是在原来集群的 HDFS 上。所以我们需要把 MapReduce 的资源管理和计算框架分开,这也是 Hadoop 2 最主要的变化,就是将 Yarn 从 MapReduce 中分离出来,成为一个独立的资源调度框架。
Yarn 是“Yet Another Resource Negotiator”的缩写,字面意思就是“另一种资源调度器”。事实上,在 Hadoop 社区决定将资源管理从 Hadoop 1 中分离出来,独立开发 Yarn 的时候,业界已经有一些大数据资源管理产品了,比如 Mesos 等,所以 Yarn 的开发者索性管自己的产品叫“另一种资源调度器”。这种命名方法并不鲜见,曾经名噪一时的 Java 项目编译工具 Ant 就是“Another Neat Tool”的缩写,意思是“另一种整理工具”。
Yarn 的架构
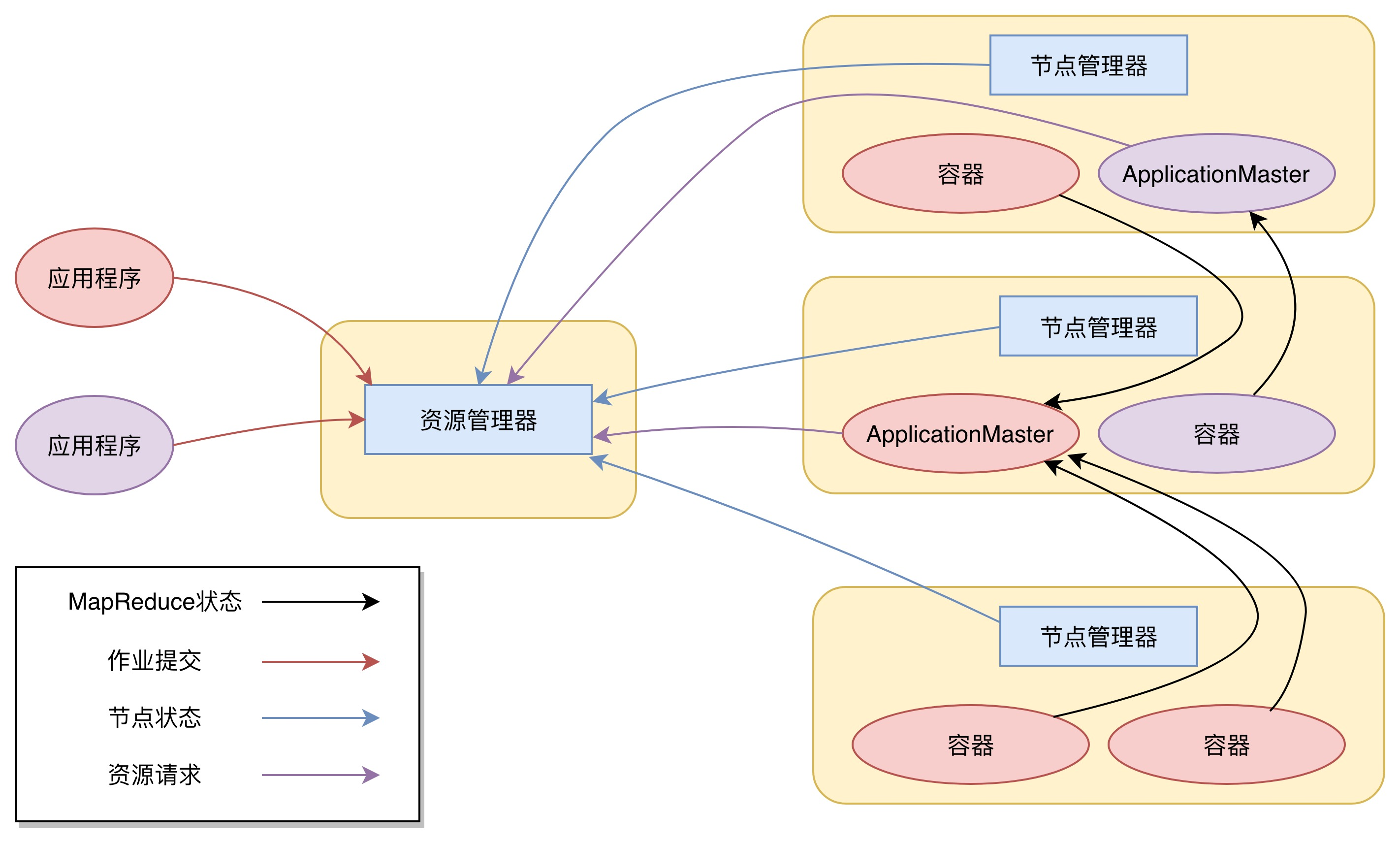
Yarn 包括两个部分:
- 一个是资源管理器(Resource Manager),ResourceManager 进程负责整个集群的资源调度管理,通常部署在独立的服务器上
- 一个是节点管理器(Node Manager,NodeManager 进程负责具体服务器上的资源和任务管理,在集群的每一台计算服务器上都会启动,基本上跟 HDFS 的 DataNode 进程一起出现。
Yarn 进行资源分配的单位是容器(Container),每个容器包含了一定量的内存、CPU 等计算资源,默认配置下,每个容器包含一个 CPU 核心。容器由 NodeManager 进程启动和管理,NodeManger 进程会监控本节点上容器的运行状况并向 ResourceManger 进程汇报。
应用程序管理器负责应用程序的提交、监控应用程序运行状态等。应用程序启动后需要在集群中运行一个 ApplicationMaster,ApplicationMaster 也需要运行在容器里面。每个应用程序启动后都会先启动自己的 ApplicationMaster,由 ApplicationMaster 根据应用程序的资源需求进一步向 ResourceManager 进程申请容器资源,得到容器以后就会分发自己的应用程序代码到容器上启动,进而开始分布式计算。
Yarn 的工作流程
我们以一个 MapReduce 程序为例,来看一下 Yarn 的整个工作流程。
- 我们向 Yarn 提交应用程序,包括 MapReduce ApplicationMaster、我们的 MapReduce 程序,以及 MapReduce Application 启动命令。
- ResourceManager 进程和 NodeManager 进程通信,根据集群资源,为用户程序分配第一个容器,并将 MapReduce ApplicationMaster 分发到这个容器上面,并在容器里面启动 MapReduce ApplicationMaster。
- MapReduce ApplicationMaster 启动后立即向 ResourceManager 进程注册,并为自己的应用程序申请容器资源。
- MapReduce ApplicationMaster 申请到需要的容器后,立即和相应的 NodeManager 进程通信,将用户 MapReduce 程序分发到 NodeManager 进程所在服务器,并在容器中运行,运行的就是 Map 或者 Reduce 任务。
- Map 或者 Reduce 任务在运行期和 MapReduce ApplicationMaster 通信,汇报自己的运行状态,如果运行结束,MapReduce ApplicationMaster 向 ResourceManager 进程注销并释放所有的容器资源。

若有收获,就点个赞吧
0 人点赞
